







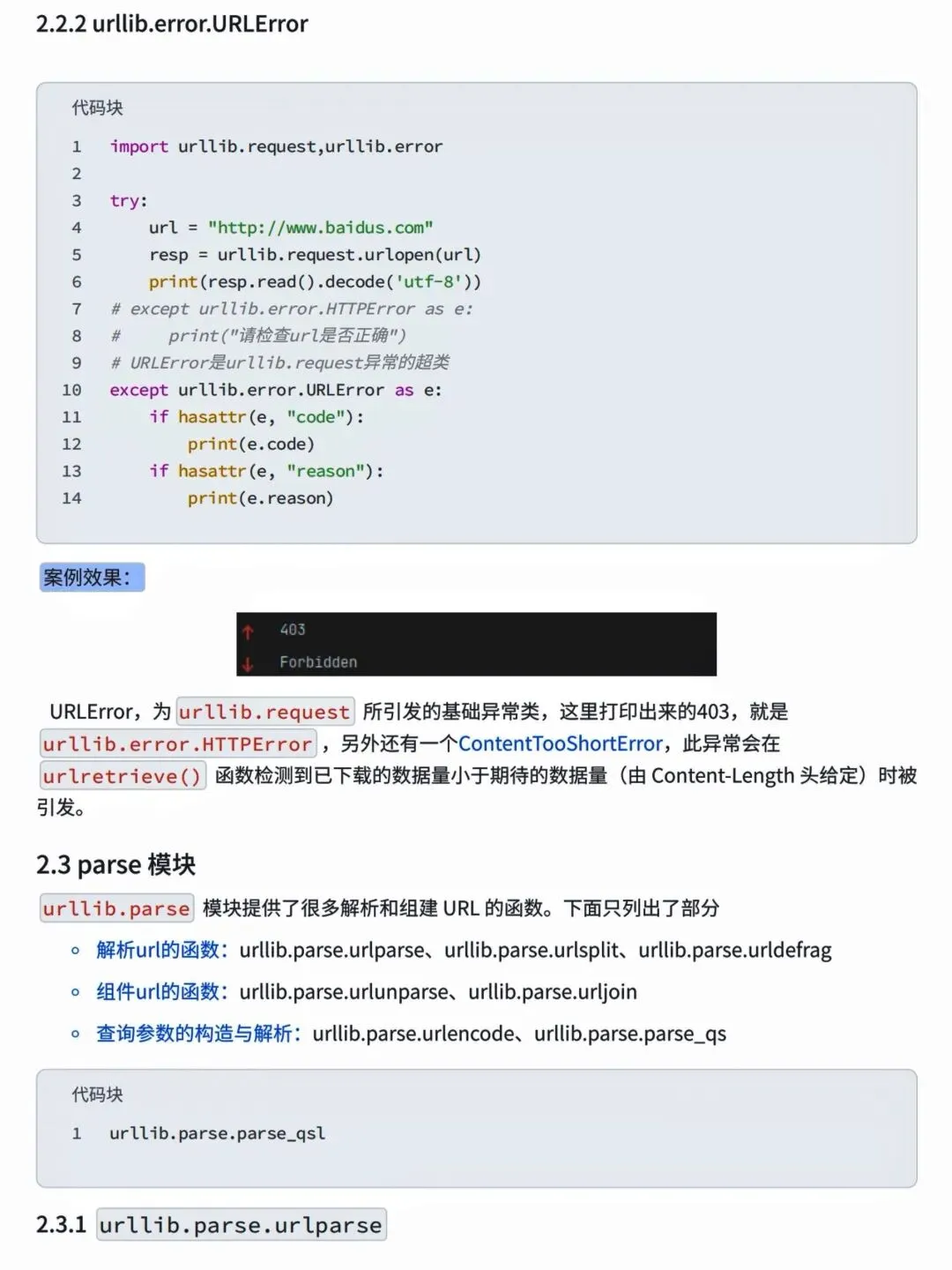
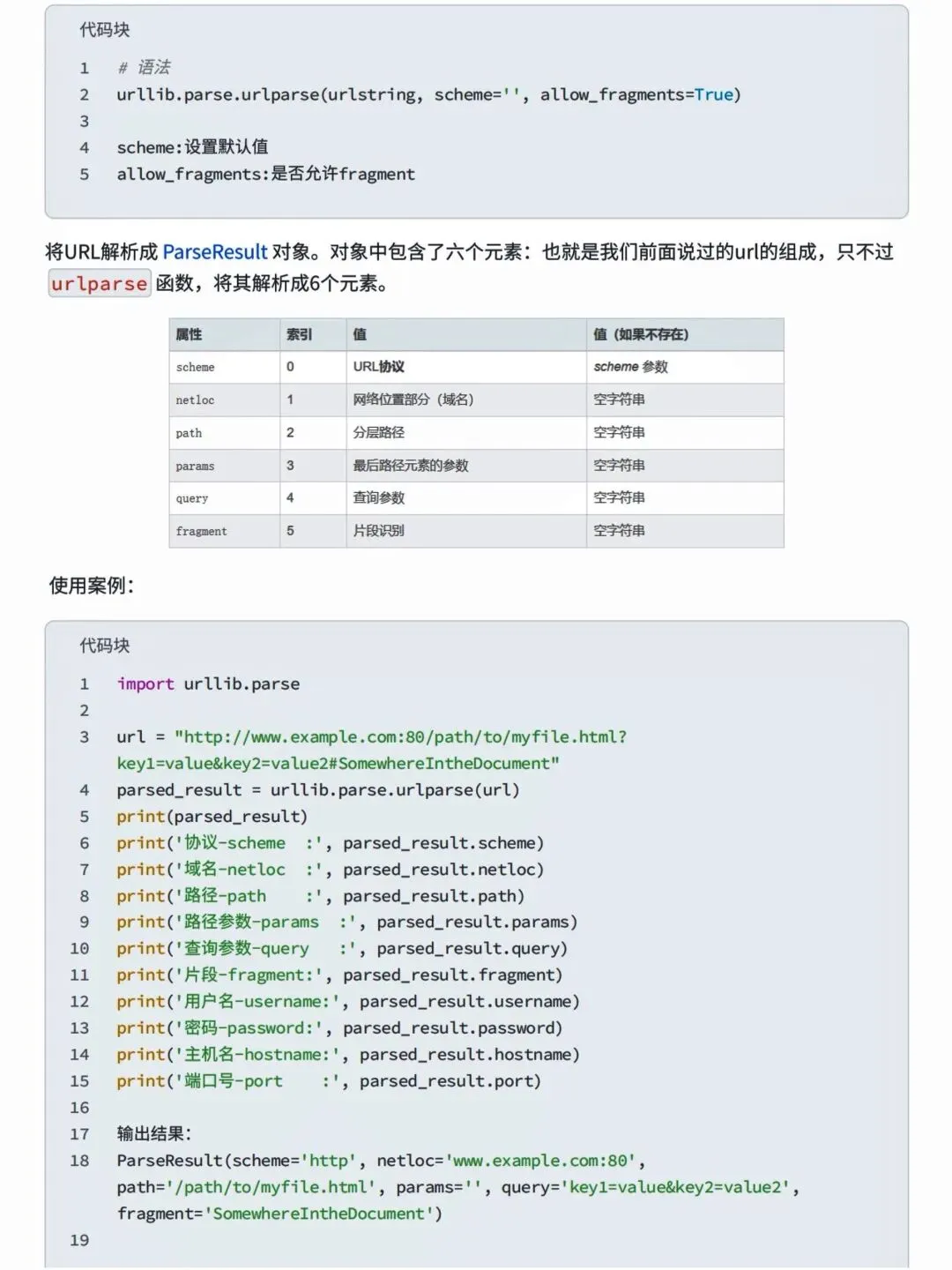
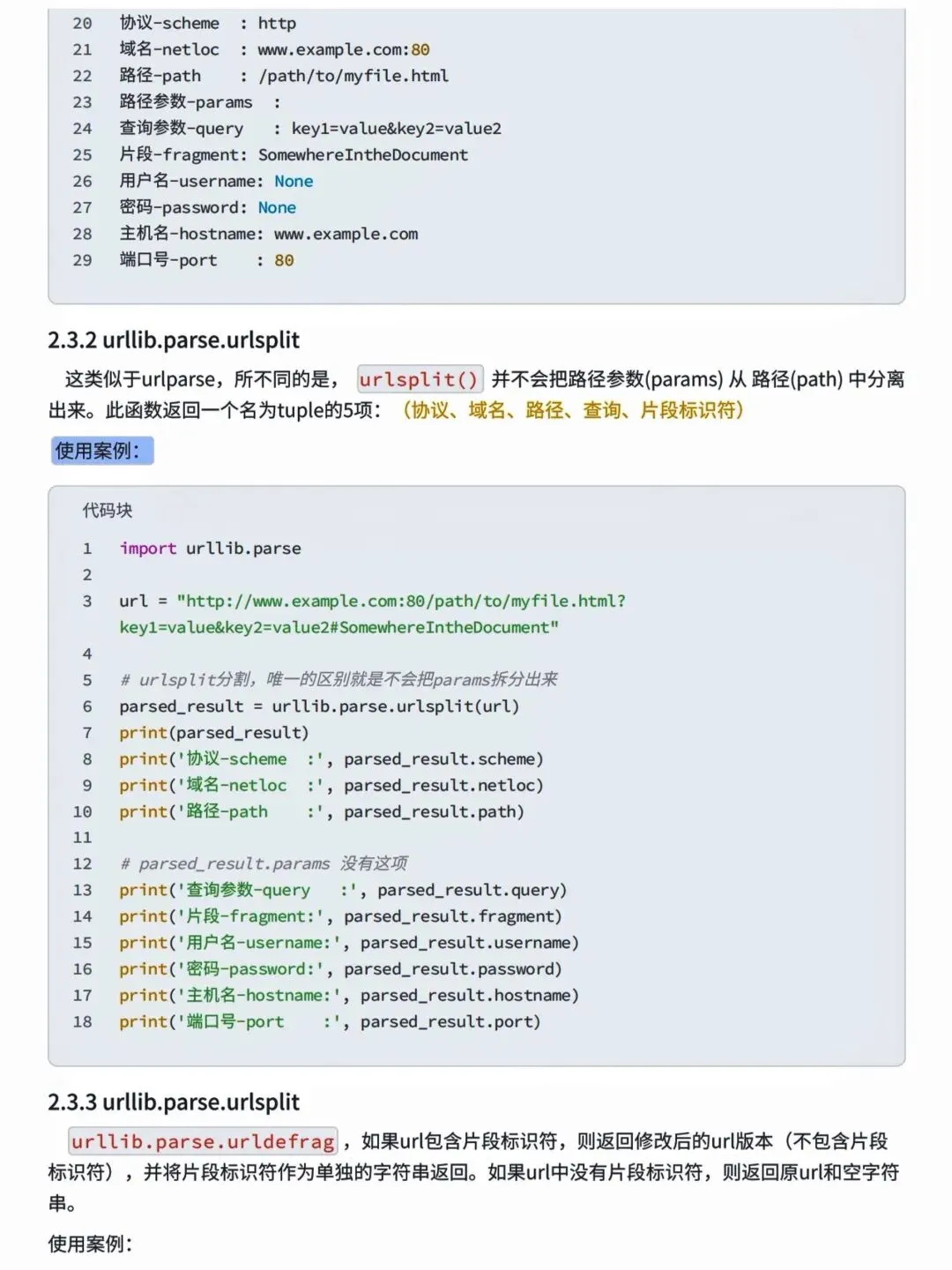
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- python: speech to text offline
- 一天一个职位讲解|全能黑马岗 Python开发(互联网_AI通用)
- 100个Python数据分析常用算法|超全解析!
- Python的pygame游戏库入门
- 【编程教程课程】Python基础+高级课程咕泡学院带你轻松掌握编程技能
- Python自动化,必学的第三方库!1行代码搞定 80% 重复工作
- Python入门第一步,先背熟这些词汇!
- 2026信息素养大赛复赛python备赛不可少99道经典题,不容错过!
- Python初学者完全指南
- 我用Python爬了5000条猫粮评价,发现最值得买的5款(附数据)
