大家好,我是蟹老板~
每次我写长篇文章的时候,都有人留言“你搞那么底层干嘛,又用不上”。其实很多技术——不是大家用不上,是很多人压根不知道自己用上了。就好比 Linux 系统调用,你天天 open、read、write、fork,但背后到底发生了什么?glibc 帮你做了多少脏活?为什么有时候用 syscall() 直接调号会更快?什么时候又该用 mmap 代替 read?
所以就有了今天这篇东西,内容有点多。
但别慌,系统调用看起来吓人,本质就一句话。
用户程序有些事不能自己干,只能请内核代劳。
一、系统调用是什么?
咱们先把那些教科书上的定义扔一边。
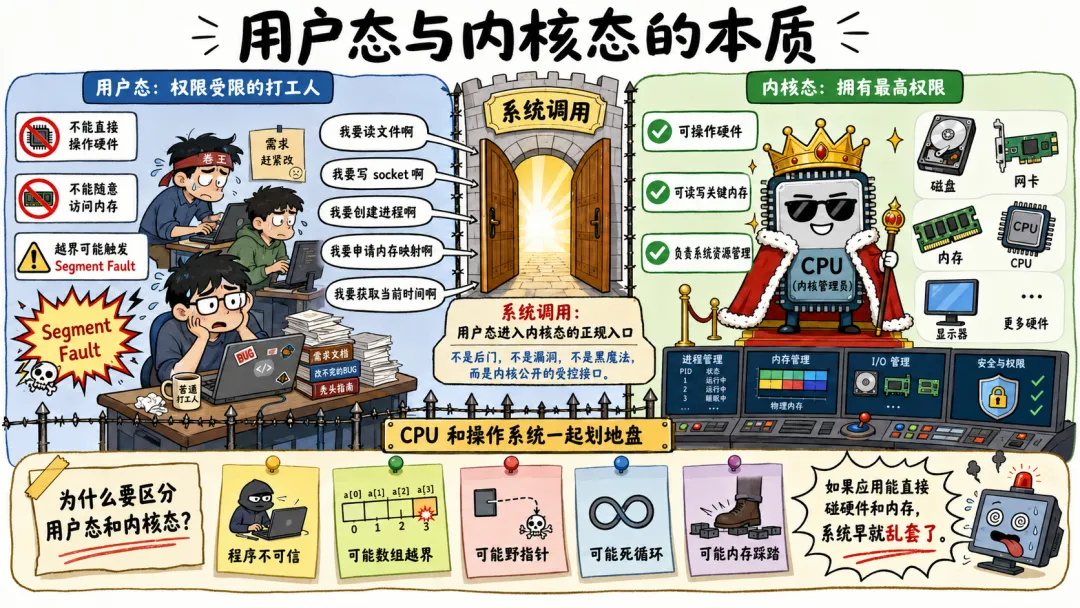
1.1 用户态与内核态的本质
你要明白一件事,CPU 这哥们儿其实挺势利的。它把世界分成了两半:一半是特权阶级,叫内核态,想干嘛干嘛,能操作硬件,能读写任意内存;另一半是咱们这些苦逼的打工人,叫用户态,干啥都受限,稍微越界一点,CPU 反手就是一个 Segment Fault 教做人。
Linux 为什么要区分用户态和内核态?
因为程序不可信,这话不好听,但是真的。你写的程序不可信,我写的也不可信。别说业务程序了,很多年薪很高的人写出来的 C 代码,一样可能数组越界、野指针、死循环、内存踩踏。要是这些程序能直接访问硬件、直接改内存映射、直接操作磁盘,那操作系统基本就是纸糊的。
所以 CPU 和操作系统一起做了一件事——划地盘。
那问题来了。
用户程序确实没资格直接摸硬件,可用户程序又必须做很多需要内核权限的事。
我要读文件啊。
我要写 socket 啊。
我要创建进程啊。
我要申请内存映射啊。
我要获取当前时间啊。
怎么办?
系统调用就出来了。
它是用户态进入内核态的正规入口,不是后门,不是漏洞,不是黑魔法。它就是内核公开给用户程序的一组受控接口。
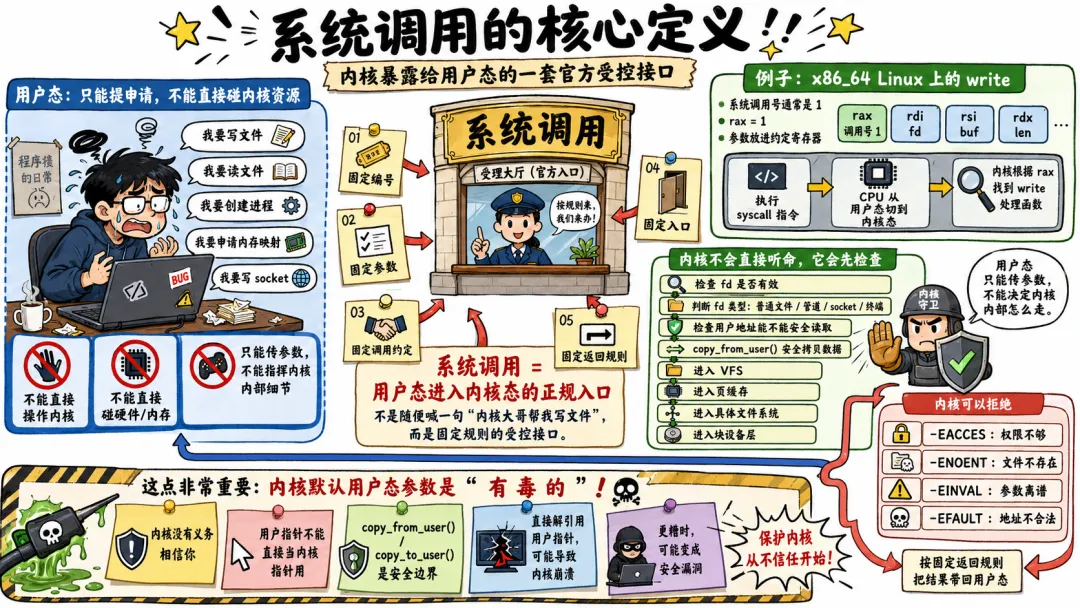
1.2 系统调用的核心定义
讲白了,系统调用就是内核暴露给用户态的一套官方受控接口,就是你不能直接操作内核资源,但你可以向内核发申请。
这个申请不是随便喊一句“内核大哥帮我写文件”。它有固定编号,有固定参数,有固定调用约定,有固定入口,还有固定返回规则。
比如 x86_64 Linux 上,write 的系统调用号通常是 1。用户态把调用号放进 rax,把文件描述符、缓冲区地址、长度放进约定好的寄存器,然后执行 syscall 指令。CPU 从用户态切到内核态,内核根据 rax 找到 write 对应的处理函数,开始办事。
以内核写文件为例,它要判断 fd 是否有效,要看这个 fd 指向普通文件、管道、socket 还是终端,要检查用户态传进来的地址能不能读,要把用户空间数据安全拷到内核能处理的位置,后面还可能进入 VFS、页缓存、具体文件系统、块设备层。
用户态只能传参数,不能指挥内核内部细节。内核可以拒绝。权限不够,返回 -EACCES。文件不存在,返回 -ENOENT。参数离谱,返回 -EINVAL。内存地址不合法,返回 -EFAULT。
很多人写应用写久了,会下意识觉得函数参数是可信的,内核开发不是,内核面对用户态参数,默认它就是有毒的,内核没有义务相信你,这一点很重要。
这也是为什么内核里有 copy_from_user()、copy_to_user() 这一类函数,用户传进来的指针不能直接当普通内核指针用,你敢直接解引用,可能就是一次内核崩溃,或者更糟,一次安全漏洞。
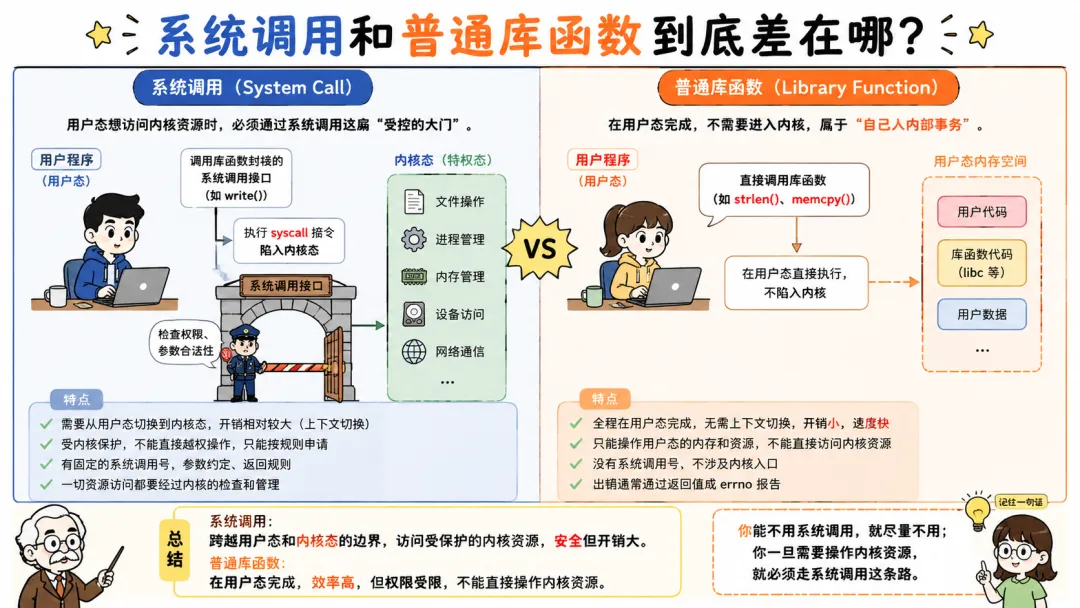
1.3 系统调用和普通库函数到底差在哪
系统调用和普通库函数特别容易混,因为我们平时写代码,很少直接写系统调用。我们写的是库函数。
比如:
printf("hello\n");fopen("a.txt", "r");malloc(1024);pthread_create(...);write(fd, buf, len);
它们看起来都像函数调用。于是很多人会误以为 write() 和自己写的 add() 没什么区别。都是函数嘛,参数进去,结果出来。
实际上差远了,普通库函数本质上就是用户态代码。它运行在当前进程的用户态地址空间里,调用成本跟普通函数差不多。比如你写一个:
int add(int a, int b) { return a + b;}
编译后可能就是几条指令,不会进入内核,不会切换权限级,不会查系统调用表。
但系统调用不一样,它会触发用户态到内核态的切换。
更准确点说,很多“看起来像系统调用”的函数,其实是 C 库封装。write() 这个名字在用户代码里是 glibc 提供的函数。它内部会按照平台 ABI 准备系统调用号和参数,然后通过 syscall 指令进入内核。
所以关系大概是这样:
你的业务代码 ↓glibc 里的 write() ↓架构相关的 syscall 封装 ↓CPU 执行 syscall 指令 ↓Linux 内核 sys_write / ksys_write / vfs_write 等路径
是不是有点绕了。
write() 既是你调用的库函数名,又对应一个内核系统调用能力。你在用户态看到的是 glibc 封装,内核里处理的是系统调用服务例程。
再看 printf()。
printf() 本身不是系统调用。它是 C 标准库函数。它会做格式化,把 %d、%s 这些东西展开成字符流。等需要真正输出到终端或文件时,它可能最终调用 write()。而且由于 stdio 有缓冲,printf() 不一定马上触发系统调用。
这也是很多人被坑的地方。
printf("hello");while (1) {}
你可能以为肯定输出 hello。结果不一定。因为没有换行,缓冲区可能没刷新。你以为你跟终端说话,其实你只是把内容塞进了用户态缓冲区。真的绝了。
malloc() 也不是每次都系统调用。小块内存通常由用户态内存分配器管理。只有堆不够、需要向内核申请更多虚拟内存时,才可能用 brk() 或 mmap()。
所以别看到函数名就喊系统调用。
判断一个操作是不是系统调用,关键看它有没有进入内核态,请内核提供受保护资源服务。
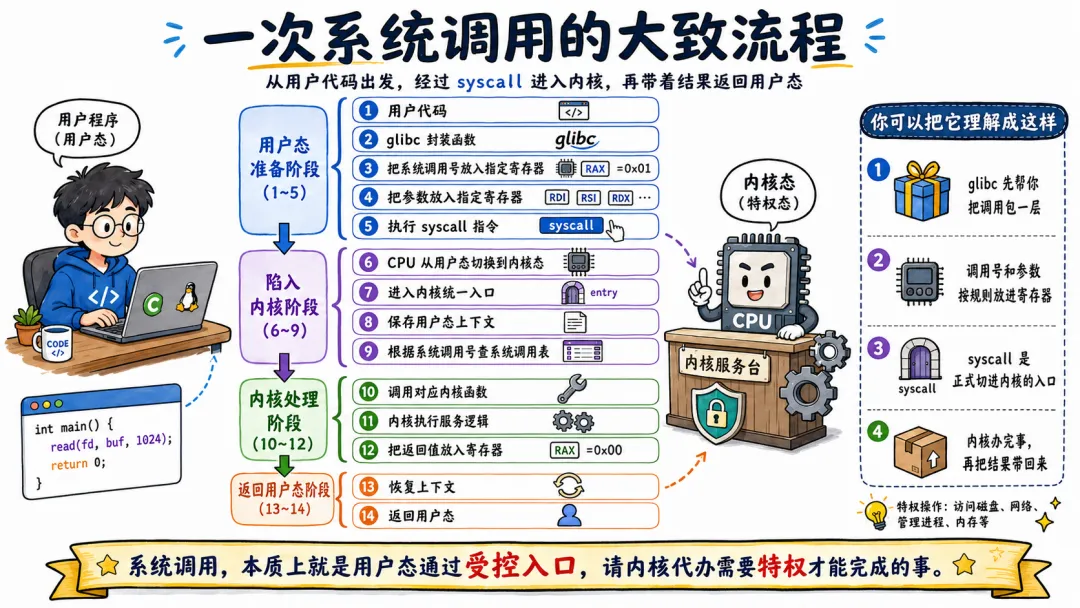
1.4 一次系统调用的大致流程
不管怎么封装,一次完整的系统调用大概都是这么个流程:
用户代码 ↓glibc 封装函数 ↓把系统调用号放入指定寄存器 ↓把参数放入指定寄存器 ↓执行 syscall 指令 ↓CPU 从用户态切换到内核态 ↓进入内核统一入口 ↓保存用户态上下文 ↓根据系统调用号查系统调用表 ↓调用对应内核函数 ↓内核执行服务逻辑 ↓把返回值放入寄存器 ↓恢复上下文 ↓返回用户态
看起来很清晰对吧?但你细想,中间的步骤每一步都可能出岔子:参数没传递好,调用号不存在,内核函数执行半路被信号打断,返回时检查是否有任务需要调度……这些都是细节,后面会说到。
二、系统调用核心原理
这部分内容是全文的核心,也是面试最高频、性能调优最关键的部分。
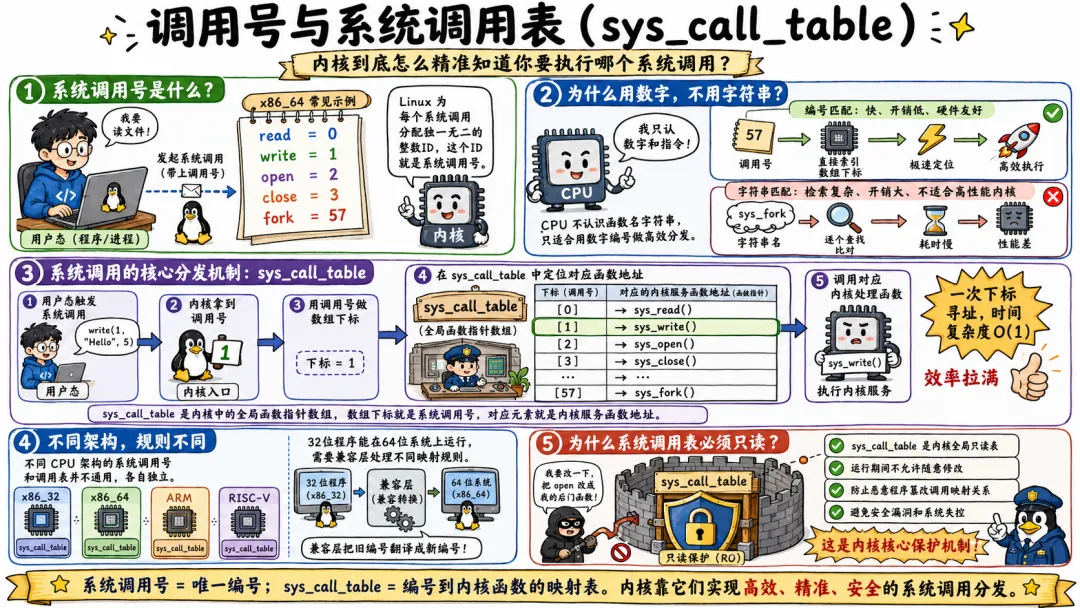
2.1 调用号与系统调用表(sys_call_table)
不知道大家有没有好奇过。内核有上百个系统调用,进程触发切换后,内核怎么精准知道用户要执行哪个操作?凭什么调用号1就执行 write,2就执行 open?
核心答案就是系统调用号和系统调用表。这是 Linux 内核实现系统调用分发的核心机制,没有这两个东西,所有系统调用都会彻底失效。
Linux 内核为每一个合法的系统调用,分配了一个独一无二的整数 ID,这就是系统调用号。x86_64 架构下,常用的系统调用号都是固定的,内核源码中通过宏定义统一管理,比如 read 是 0、write 是 1、open 是 2、close 是 3、fork 是 57。
为什么要用数字编号,不用字符串名称? 因为 CPU 只认识数字和指令,不认识字符串。用数字编号,匹配速度最快、开销最低、硬件适配最简单。如果用函数名匹配,内核的检索开销会成倍增加,完全不符合高性能的设计初衷。
有了调用号,还需要一张映射表,这就是 sys_call_table 系统调用表。
它是内核中一个全局的函数指针数组,数组的下标就是系统调用号,数组对应的元素,就是该调用号对应的内核服务函数地址。
也就是说,内核拿到调用号之后,只需要做一次数组下标寻址,就能瞬间找到对应的内核函数,时间复杂度是 O(1),效率拉满。
这里提醒一个很多人不知道的知识点。不同 CPU 架构的系统调用号、调用表是完全不一样的。x86_32、x86_64、ARM、RISC-V 架构,各自有一套独立的调用号定义和调用表。这也是为什么 32 位程序能在 64 位系统上运行,需要内核兼容层的核心原因,两者的调用映射规则完全不同。
系统调用表是内核全局只读表,运行期间不允许修改。这是内核的核心保护机制,防止恶意程序篡改调用映射关系,造成系统安全漏洞。
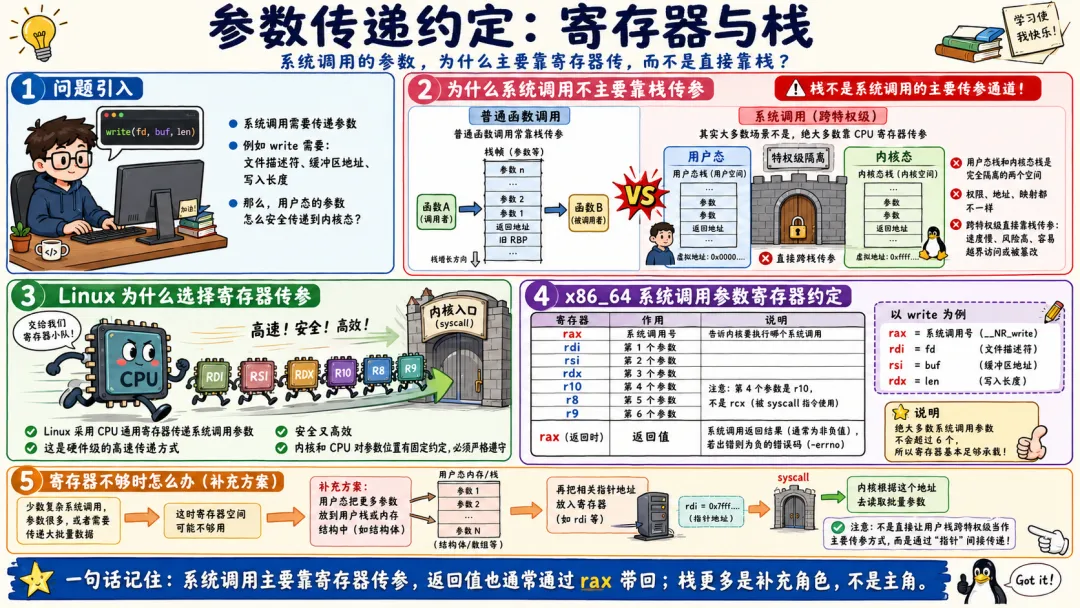
2.2 参数传递约定:寄存器与栈
系统调用需要传递参数,比如 write 需要文件描述符、缓冲区地址、写入长度。那用户态的参数,是怎么安全传递到内核态的呢?
很多人以为是通过栈传递,其实不是的,普通函数调用靠栈传参,系统调用绝大多数场景靠 CPU 寄存器传参。
为什么不用栈呢?因为用户态栈和内核态栈是完全隔离的两个空间,权限、地址、映射都不一样。跨特权级通过栈传参,不仅速度慢,还存在极大的安全风险,容易出现越界访问、数据篡改问题。
所以 Linux 采用了最优方案,用 CPU 通用寄存器传递系统调用参数,这是硬件级的高速传递方式,安全又高效。
x86_64 架构下,系统调用的参数传递有固定的寄存器约定,这是内核和 CPU 约定好的规则,必须严格遵守。
系统调用号固定存入 rax 寄存器,第一个参数存入 rdi 寄存器,第二个参数存入 rsi 寄存器,第三个参数存入 rdx 寄存器,第四个参数存入 r10 寄存器,第五个参数存入 r8 寄存器,第六个参数存入 r9 寄存器。
绝大多数系统调用的参数都不会超过 6 个,完全可以用寄存器承载。执行完成后,内核的返回结果,会统一放回 rax 寄存器,传回用户态。
那有没有寄存器装不下的情况?
当然有。部分复杂的系统调用参数极多,或者需要传递大批量数据,寄存器空间不够用。这时候就会采用栈传参的补充方案,用户态把参数压入用户栈,将栈指针作为参数传入寄存器,内核通过栈指针读取批量参数。
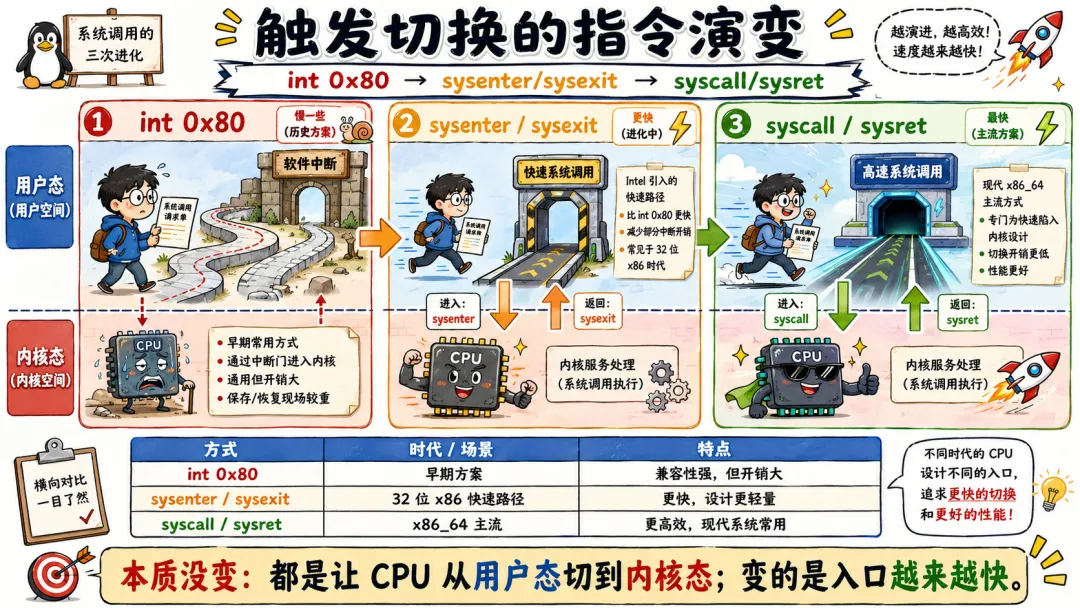
2.3 触发切换的指令演变:int 0x80 → sysenter/sysexit → syscall/sysret
用户态想要进入内核态,必须依靠 CPU 的特权切换指令。没有专属指令,再怎么写代码都无法突破权限隔离。
实 Linux 系统调用的切换指令,经历了三次迭代,每一次迭代都是为了提速、减开销。搞懂这个演变,你就能明白为什么现代服务器性能越来越强。
第一代是 int 0x80 中断指令。这是 32 位 Linux 最古老的系统调用触发方式,通过软件中断实现特权级切换。
int 0x80 的逻辑很简单,用户态触发 0x80 号中断,CPU 暂停当前用户代码,触发中断处理流程,跳转到内核中断服务函数,完成权限切换。
但它的缺点特别明显。中断处理流程繁琐,需要保存全套硬件上下文、遍历中断向量表、处理各种中断兼容逻辑,开销极大。在高并发场景下,海量 int 0x80 指令会严重拖累系统性能,效率特别拉胯。
于是英特尔推出了第二代优化指令 sysenter/sysexit。这组指令是专门为系统调用场景设计的快速切换指令,剥离了中断的冗余逻辑,专门用于用户态和内核态的双向切换。
sysenter 负责快速进入内核态,sysexit 负责快速返回用户态。相比 int 0x80,它的切换开销降低了近一半,性能提升十分明显。
不过这组指令有兼容性问题,早期 AMD CPU 不支持,所以 Linux 内核做了兼容适配,一段时间内双指令并存,根据 CPU 架构自动选择切换方式。
第三代就是现在 x86_64 架构的标准指令 syscall/sysret,也是目前所有线上服务器默认使用的切换指令。
这组指令是 AMD 主导设计、英特尔兼容适配的通用快速系统调用指令,彻底解决了兼容性问题,同时进一步精简了上下文切换逻辑,减少了 CPU 时钟周期占用。
它是目前效率最高的特权级切换方式,也是我们现在写代码、跑服务,底层真正在执行的指令。
很多人疑惑,既然指令一直在优化,为什么我们写代码不用改?因为 glibc 已经帮我们做了全部兼容适配。glibc 会根据当前 CPU 架构、内核版本,自动选择最优的切换指令,完全无感知,这就是封装的魅力。
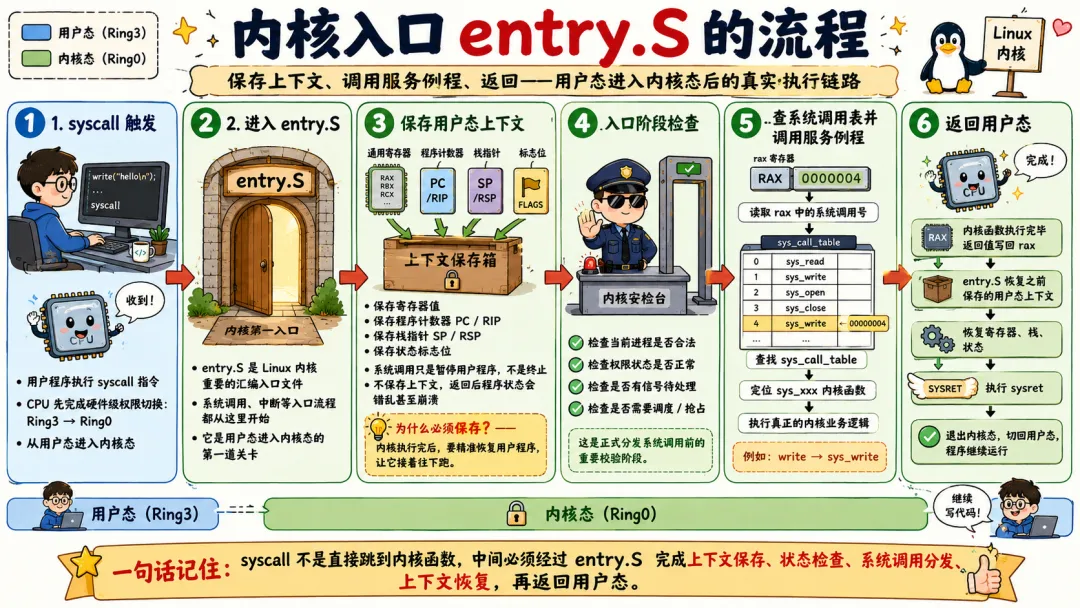
2.4 内核入口 entry.S 的流程:保存上下文、调用服务例程、返回
entry.S 其实它主要干脏活累活。
系统调用进入内核后,不能直接开干。因为用户态现场还在那儿。寄存器里有用户程序的数据,栈是用户栈,CPU 状态也要保存。内核要保证干完活之后,用户程序能像什么都没发生一样继续执行。
这就要保存上下文。
内核入口代码要处理的事情包括:
从用户态切到内核态切换到内核栈保存必要寄存器处理安全检查和追踪钩子根据系统调用号分派调用具体系统调用函数处理返回值检查是否需要调度或处理信号恢复寄存器返回用户态
真实路径会因为架构、内核版本、配置项变得更复杂。比如开启 seccomp、ptrace、audit、ftrace、kprobes、eBPF 跟踪时,系统调用入口和出口可能会多一些检查和钩子。
这就解释了一个现象,为什么同一个系统调用,在不同环境里性能可能差不少?
因为你以为只是 syscall,实际上入口出口上可能挂了一堆东西。
容器环境里可能有 seccomp 过滤。调试时可能有 ptrace。安全审计可能记录系统调用。性能分析工具可能插桩。某些内核安全缓解机制也会影响路径。
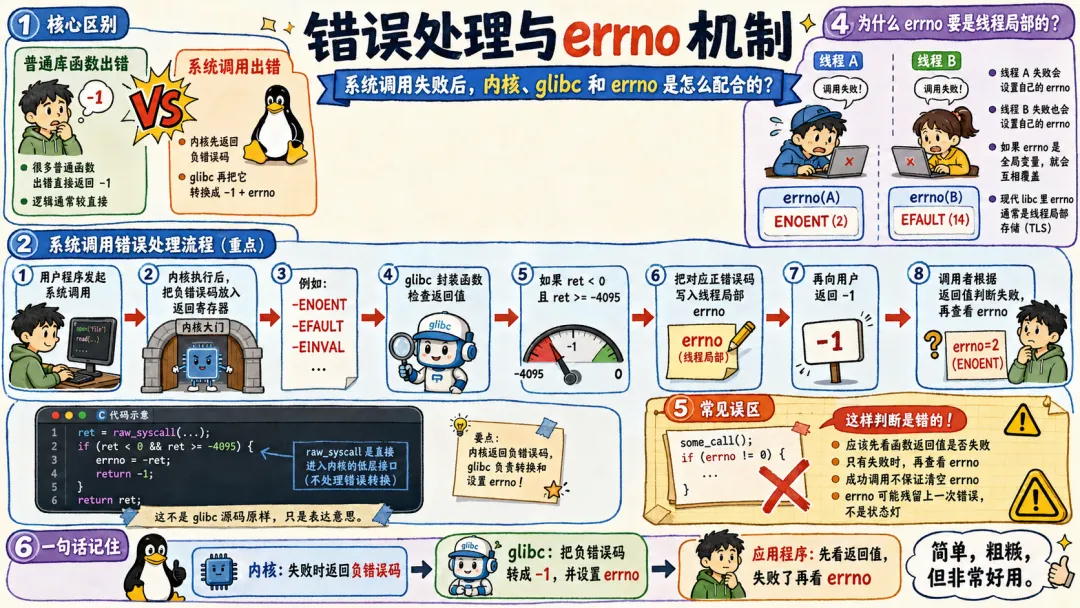
2.5 错误处理与 errno 机制
系统调用的错误处理,和普通库函数完全不一样。普通函数出错直接返回 -1 即可,系统调用的错误逻辑更严谨、更特殊。
内核通常把负错误码放在返回寄存器里。比如返回 -ENOENT、-EFAULT、-EINVAL。glibc 封装函数看到返回值落在错误范围内,就把对应正错误码写入线程局部的 errno,再给你返回 -1。
大概像这样:
ret = raw_syscall(...);if (ret < 0 && ret >= -4095) { errno = -ret; return -1;}return ret;
这不是 glibc 源码原样,只是表达意思。
为什么 errno 要是线程局部的?
因为多线程啊。线程 A 调用失败设置 errno,线程 B 同时也调用失败。如果 errno 是一个普通全局变量,那两个线程互相覆盖,错误处理会变成玄学。现代 libc 里 errno 通常是线程局部存储。
还有一点就是成功调用不保证清空 errno。
很多人写:
some_call();if (errno != 0) { ...}
这是错的。你应该根据函数返回值判断是否失败,再看 errno。因为 errno 可能残留上一次错误。它不是状态灯,不会每次成功自动归零。
系统调用的错误码设计非常朴素,也非常 Linux。
它不抛异常,不返回对象,不搞复杂层次。一个整数,失败就负错误码。到了 libc,再转换成 -1 + errno。简单,粗粝,但好用。
三、系统调用面面观——分类速览
Linux 内核提供的系统调用有三百多个,全部记下来根本不现实,也没必要,我们日常开发用到的,也就几十种核心调用。这里我把常见的大致分几类,每类挑几个典型聊聊。
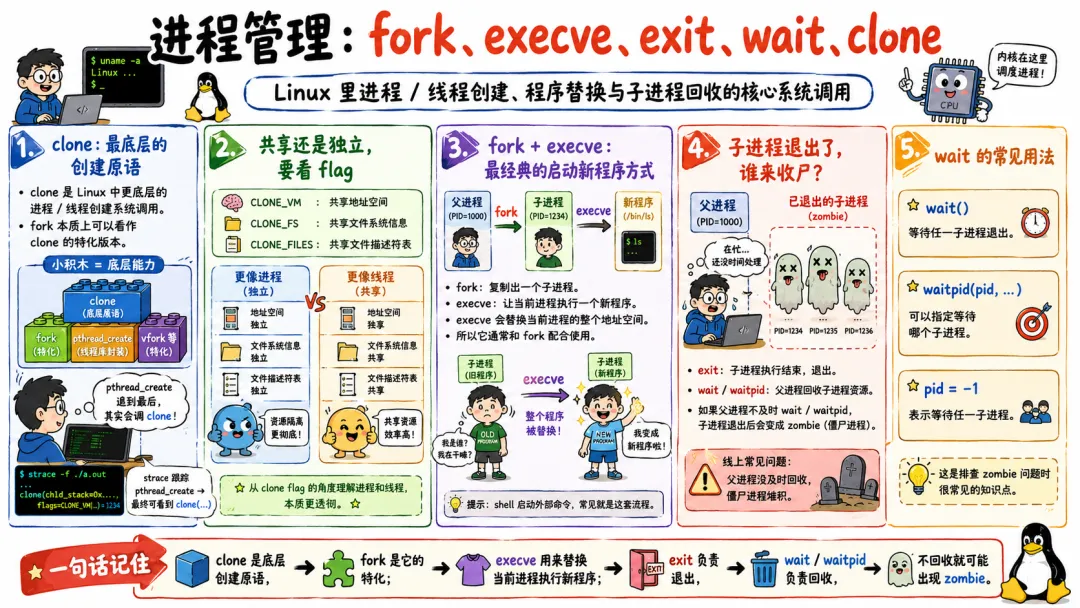
3.1 进程管理:fork、execve、exit、wait、clone
进程管理类系统调用,是 Linux 生命循环的基础。
常见有:
forkexecveexitwaitclone
fork() 负责创建子进程。它不是简单复制一份内存那么粗暴。现代 Linux 用写时复制。父子进程一开始共享物理页,只要不写,就不真的复制。写的时候触发 page fault,再复制对应页。这个设计非常有点东西。
execve() 负责把当前进程的程序映像替换成另一个程序。注意,它不是创建新进程。它是在当前进程里“换壳”。原来的代码、数据、堆栈基本被新程序替代。
看一个经典的 shell 执行命令流程:
shell 进程 fork 出子进程子进程 execve 执行目标程序父进程 wait 等子进程结束
exit() 退出当前进程。
wait() 等待子进程,顺便回收僵尸进程。僵尸进程不是鬼故事,就是子进程已经死了,但父进程还没读取它的退出状态,所以内核保留一小点信息。
clone() 更底层。Linux 的线程本质上也是通过 clone 创建的。它可以选择共享地址空间、文件描述符表、信号处理等资源。pthread_create() 底下就和它有关系。
你看,进程和线程在用户态概念里分得挺清楚。到了 Linux 内核里,很多时候都是 task,只是共享资源的组合不同。这个设计第一次看会有点别扭,看久了又觉得挺合理。
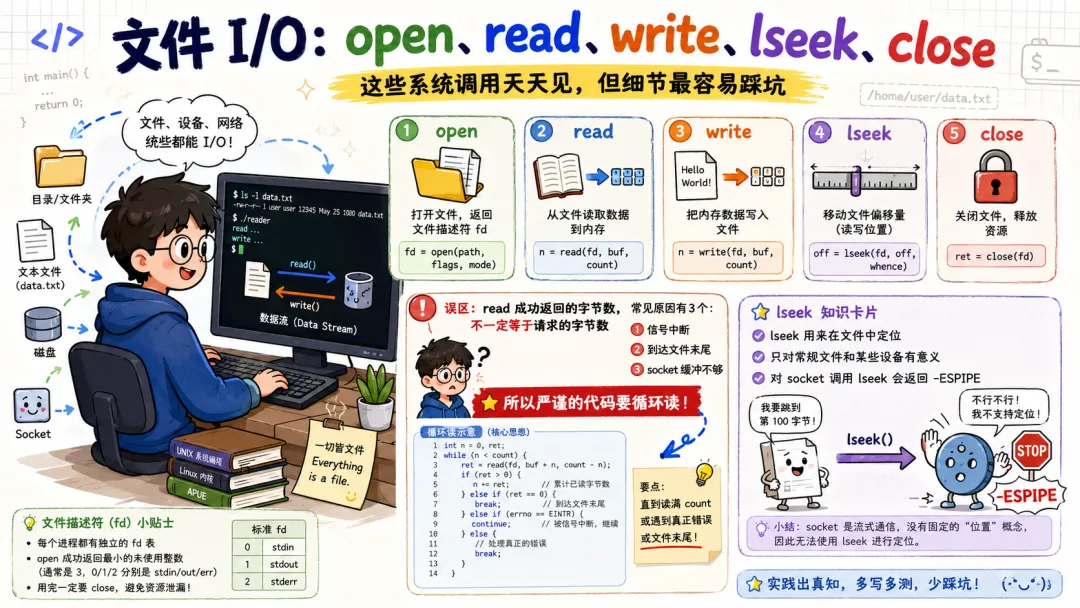
3.2 文件 I/O:open、read、write、lseek、close
这几个就不用多说了,每天见面,Linux 里文件 I/O 太核心了。
常见调用:
openreadwritelseekclose
不过现代程序里你经常会看到 openat,因为它比传统 open 更适合相对目录 fd、安全路径操作和一些沙箱场景。
文件描述符 fd 是用户态和内核之间的一个小整数句柄。它不是文件本身。它是当前进程文件描述符表里的索引,指向内核里的打开文件对象。
int fd = open("hello.txt", O_RDONLY);
这里 fd 可能是 3。为什么常常是 3?因为 0、1、2 通常已经给了标准输入、标准输出、标准错误。
0 stdin1 stdout2 stderr
read(fd, buf, len) 从 fd 指向的对象读数据。
write(fd, buf, len) 向它写数据。
lseek(fd, offset, whence) 调整文件偏移。
close(fd) 关闭文件描述符,释放当前进程对打开文件对象的引用。
Linux 的漂亮之处在于,fd 不只代表普通磁盘文件。它也可以代表管道、socket、eventfd、timerfd、signalfd、设备文件。很多对象都能被抽象成“可读可写可等待”的东西。
这也是 epoll 能统一管理各种 fd 的基础。
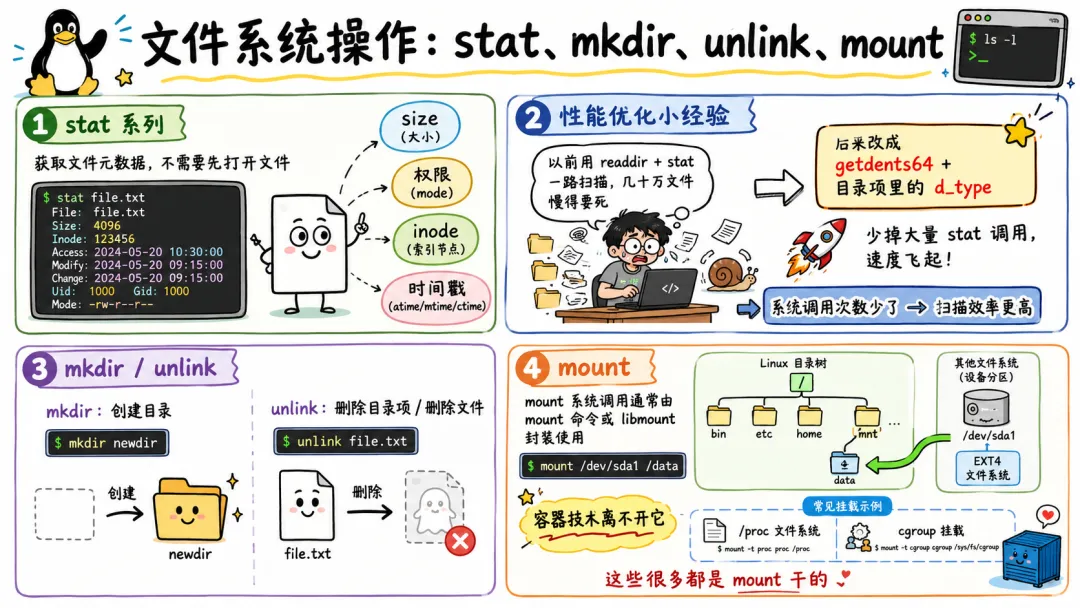
3.3 文件系统操作:stat、mkdir、unlink、mount
文件系统相关调用包括:
statmkdirunlinkmountrenamechmodchowngetdents
stat() 获取文件元信息,比如大小、权限、时间戳、inode 号。
mkdir() 创建目录。
unlink() 删除目录项。这个名字挺劝退。很多人以为删除文件就应该叫 delete,Linux 偏不。因为 Unix 文件系统里,文件名和 inode 是链接关系。unlink 删除的是一个名字到 inode 的链接。当链接计数变为 0,并且没有进程打开它时,文件数据才会真正释放。
这就是为什么有时候你 rm 掉一个大日志文件,磁盘空间却没回来。因为某个进程还打开着它。目录项没了,fd 还在,数据还不能释放。
线上遇到这个问题时,你会看到 df 说磁盘满,du 又找不到大文件。第一次碰到很吓人,第二次就淡定了:
lsof | grep deleted
mount() 则是把一个文件系统挂载到目录树上。Linux 的目录树不是每块磁盘各玩各的,而是统一挂到一棵树里。这也是容器、namespace、chroot、overlayfs 很多能力的基础。
文件系统系统调用看起来普通,但里面有大量安全细节。路径解析、权限检查、符号链接、防止 TOCTOU 竞态,每一项都够写一篇长文。
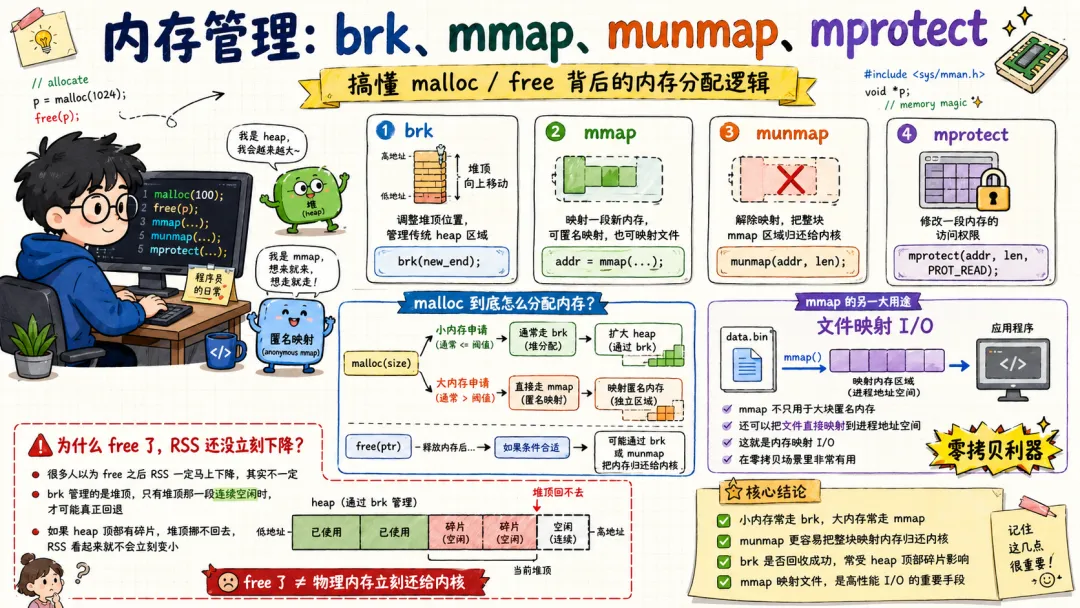
3.4 内存管理:brk、mmap、munmap、mprotect
内存相关系统调用常见有:
brkmmapmunmapmprotectmadvisemlock
brk() 调整进程堆顶。传统堆分配器会用它扩展 heap。
mmap() 更强。它可以做匿名内存映射,也可以把文件映射到进程地址空间。动态库加载、共享内存、大文件读写、JIT、内存分配器,都可能用它。
比如匿名映射:
void *p = mmap(NULL, 4096, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
这相当于向内核申请一段虚拟内存区域。
注意,是虚拟内存区域。物理页不一定马上分配。很多时候 Linux 会懒分配。你真正读写时触发缺页异常,内核才分配物理页并建立映射。
munmap() 解除映射。
mprotect() 修改内存页权限,比如从可写改成只读,或者让 JIT 生成代码时先写后执行。安全系统里经常提 W^X,也就是一段内存不要同时可写又可执行。
madvise() 很有意思。它像你给内核递小纸条:“这段内存我马上要顺序访问”“这段不用了”“这段可能随机访问”。内核不一定照做,但会参考。
很多应用层性能优化,最后都会碰到内存系统调用。你以为你在调业务,其实是在跟虚拟内存子系统谈判。
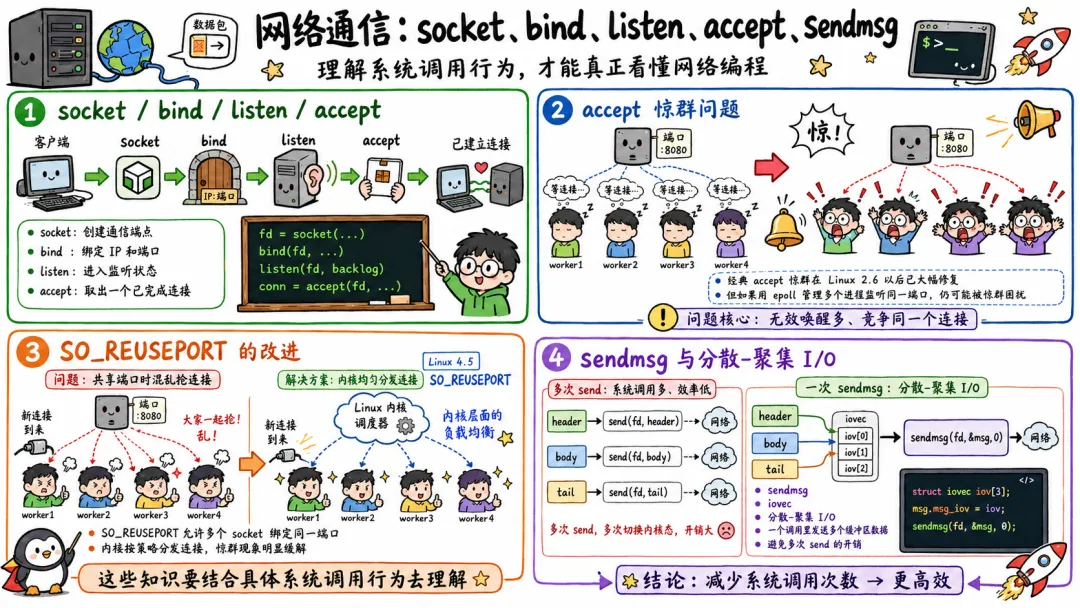
3.5 网络通信:socket、bind、listen、accept、sendmsg
网络相关系统调用大家也熟:
socketbindlistenacceptconnectsendmsgrecvmsgsetsockopt
服务端常见流程:
int fd = socket(AF_INET, SOCK_STREAM, 0);bind(fd, ...);listen(fd, backlog);int cfd = accept(fd, ...);read(cfd, buf, len);write(cfd, buf, len);
socket() 创建一个 socket fd。
bind() 绑定本地地址和端口。
listen() 让 TCP socket 进入监听状态。
accept() 从已完成连接队列里取出一个新连接。
sendmsg()、recvmsg() 比 send、recv 更通用,可以处理 scatter-gather I/O、控制消息、Unix 域 socket 传 fd 等高级操作。
网络系统调用的需要避的坑也多。
比如 send() 成功返回,不代表对方应用已经收到。它只表示数据被成功交给本机协议栈,或者写入了发送缓冲区。
write() 写 socket 也可能只写了一部分。非阻塞模式下可能返回 EAGAIN。你要配合 epoll。要处理半包、粘包。要处理连接关闭。要处理 SIGPIPE。要处理各种你不想处理但线上一定会出现的破事。
网络编程最折磨人的地方就在这。API 看起来很少,状态空间巨大。
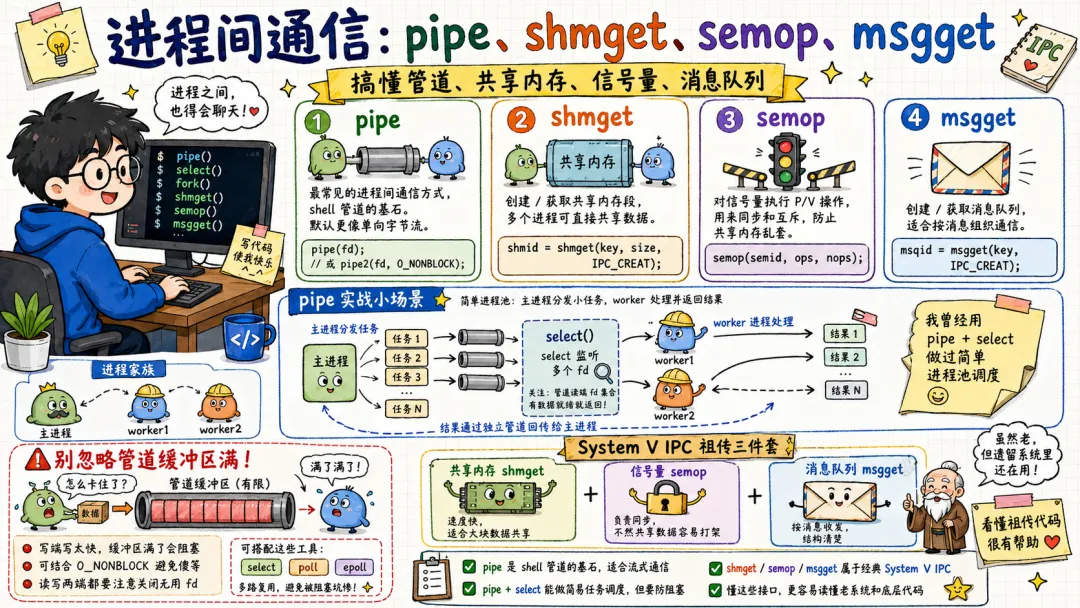
3.6 进程间通信:pipe、shmget、semop、msgget
IPC 类系统调用包括:
pipeshmgetsemopmsggeteventfdfutex
pipe() 创建管道。一个读端,一个写端。shell 里的 | 就靠它支撑。
cat access.log | grep 500 | wc -l
这背后会创建多个进程,用 pipe 把前一个进程的 stdout 接到后一个进程的 stdin。
System V IPC 里有共享内存、信号量、消息队列,也就是 shmget、semop、msgget 那些老伙计。现在很多程序更偏向 POSIX shm、mmap、Unix domain socket、eventfd、futex 这类方式。
futex 重点说一下。核心思想是:无竞争时尽量在用户态解决,不进内核;有竞争需要睡眠唤醒时才走系统调用。
这真的很重要,因为锁太高频。如果每次加锁解锁都进内核,性能会非常难看。现代线程库的 mutex、condition variable,底层都离不开 futex 的影子。
系统调用不是越多越好。能不进内核,就别进。 这是 futex 给我的最大启发。
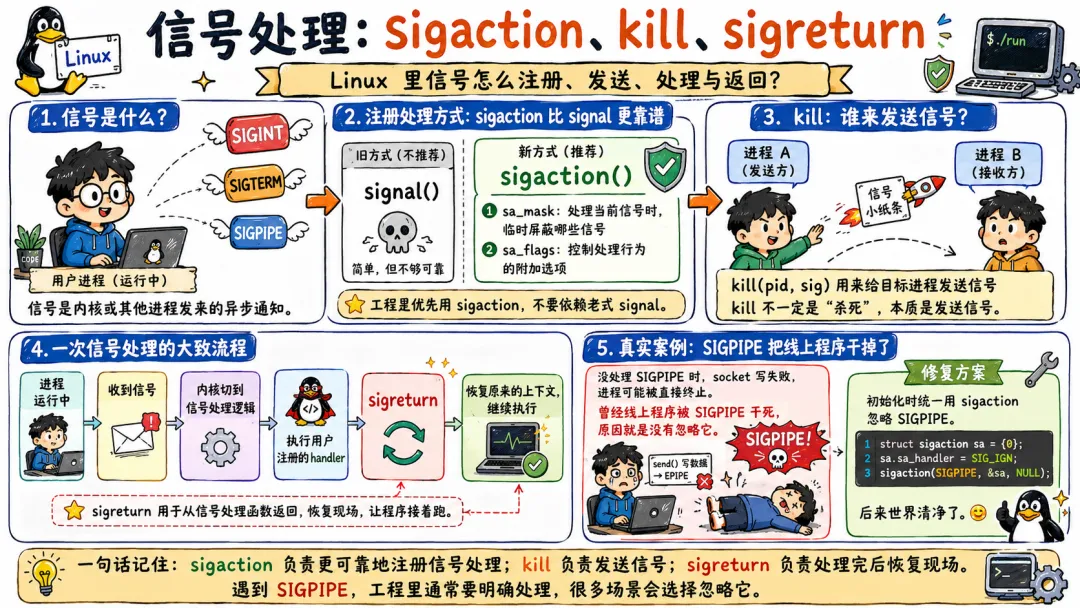
3.7 信号处理:sigaction、kill、sigreturn
信号相关调用包括:
sigactionkillsigprocmasksigreturn
信号是 Unix 世界里的老机制。你按 Ctrl+C,终端给前台进程发 SIGINT。你 kill -9 pid,发的是 SIGKILL。子进程退出,父进程可能收到 SIGCHLD。
sigaction() 用来注册信号处理函数。比老的 signal() 更可靠。
kill() 名字吓人,其实它只是发送信号,发什么信号看参数。并不是每次都杀死进程。
信号有点像门缝里突然塞进来的纸条,程序正常执行着,内核在合适时机打断它,跳到信号处理函数。处理完再回来。
这机制很强,也很危险。因为信号处理函数能安全调用的函数非常有限。你在信号处理函数里乱用 printf()、malloc(),可能引发重入问题。很多线上诡异 bug 就藏在信号里。
sigreturn 更底层,它用于信号处理结束后恢复原来的用户态上下文。一般应用程序不会直接碰它,但理解它能帮助你明白信号为什么能“打断又回来”。
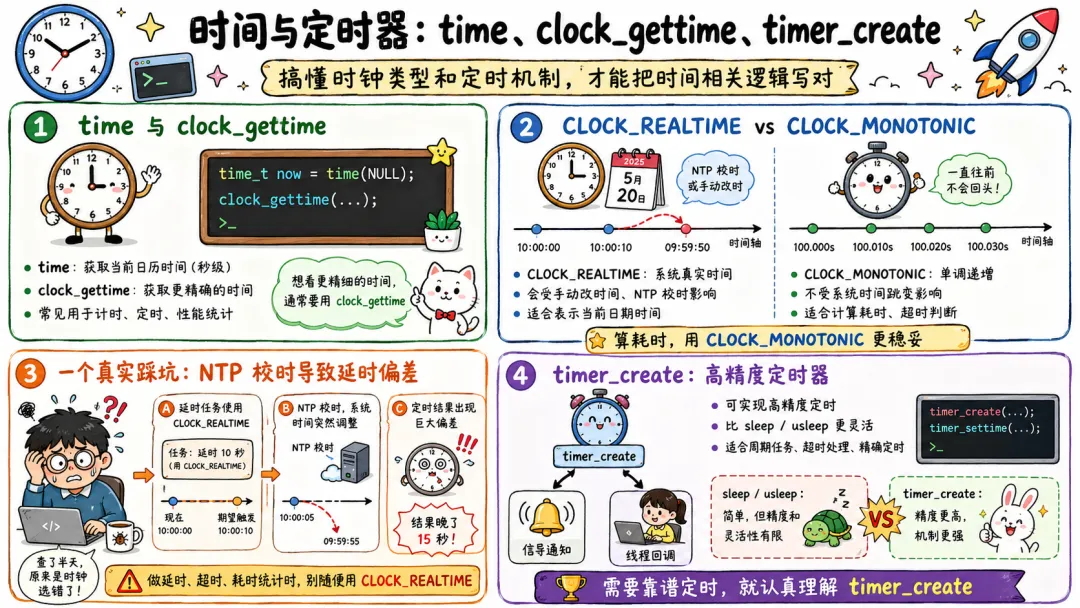
3.8 时间与定时器:time、clock_gettime、timer_create
时间相关调用有:
timegettimeofdayclock_gettimetimer_createtimerfd_createnanosleep
获取时间看起来简单,实际上很讲究。
早年获取时间可能真的要进内核。后来为了性能,Linux 提供了 vDSO。像 clock_gettime() 这种高频调用,在某些时钟类型下可以通过 vDSO 在用户态完成,不必每次系统调用。
这很香。
因为很多程序获取时间频率极高。日志打点、超时判断、性能统计、事件循环,全都要时间。如果每次都陷入内核,那成本不低。
定时器也有很多种。传统 setitimer,POSIX timer,timerfd,还有用户态事件循环里基于 epoll 的定时管理。
timerfd 很符合 Linux “一切皆 fd”的审美。定时器到期后 fd 可读,可以塞进 epoll 里统一管理。写事件循环的人会很喜欢它。
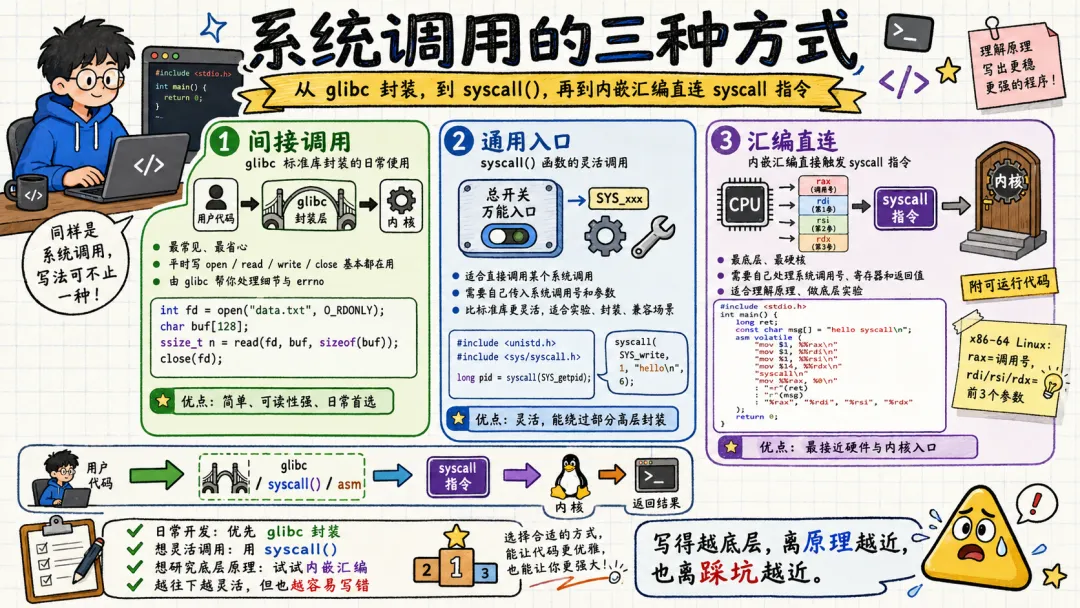
四、系统调用的三种方式
很多人以为系统调用只有一种写法,就是调用库函数。其实 Linux 提供了三种完全不同的系统调用方式,适配不同的开发场景。
日常业务开发用第一种,特殊场景开发用第二种,底层调试、内核研究用第三种。三种方式本质都是触发内核调用,只是封装层级不同。
4.1 间接调用:glibc 标准库封装的日常使用
这是我们 99% 的开发场景都会用到的方式,也是最安全、最便捷、兼容性最好的调用方式。
所谓间接调用,就是不直接触发系统调用指令,而是调用 glibc 封装的标准库函数,由 glibc 帮我们完成参数处理、指令触发、错误处理、版本兼容。
比如我们写一行最简单的文件写入代码:
#include <unistd.h>#include <fcntl.h>int main() { int fd = open("test.txt", O_RDWR | O_CREAT, 0644); write(fd, "hello syscall\n", 14); close(fd); return 0;}
这里的 open、write、close,全部是 glibc 封装的间接调用函数。
开发者不需要关心当前 CPU 架构是哪种、该用 syscall 还是 int 0x80、寄存器该填什么参数。glibc 全部帮我们屏蔽了底层细节,只需要传入业务参数即可。
这种方式的优点极其明显:开发效率高、代码可读性强、兼容性极好、出错率低。
唯一的缺点就是多了一层封装,会产生极其微小的性能损耗。不过绝大多数业务场景,这点损耗完全可以忽略不计,根本没必要优化。只有极致高性能场景,才需要考虑替换调用方式。
4.2 通用入口:syscall() 函数的灵活调用
很多人不知道,glibc 还提供了一个通用的系统调用入口函数 syscall()。它可以直接通过系统调用号,触发任意内核系统调用,跳过部分封装逻辑。
这是一种半直接的调用方式,比库函数更底层,比纯汇编更简单灵活
syscall 函数的原型特别简单,第一个参数是系统调用号,后面依次跟上对应系统调用的参数。
我们可以用 syscall 直接实现 write 功能,代码如下:
#include <unistd.h>#include <sys/syscall.h>#include <stdio.h>int main() { char buf[] = "hello syscall func\n"; // __NR_write 为x86_64架构write调用号 1 long ret = syscall(__NR_write, 1, buf, sizeof(buf)); if (ret < 0) { perror("syscall write failed"); } return 0;}
这段代码没有调用 write 库函数,直接通过通用入口触发内核 write 系统调用,运行效果和原生 write 完全一致。
这种调用方式的适用场景很特殊。一些新版本内核新增的系统调用,glibc 还没来得及封装库函数,这时候就可以用 syscall 直接调用。还有一些跨平台兼容、特殊权限调用的场景,也会用到它。
它比间接调用性能稍好,封装更薄,自由度更高,但缺点也很明显。需要手动记忆系统调用号、手动处理参数、兼容性差,架构切换后调用号会失效,代码可维护性变低。
4.3 汇编直连:内嵌汇编直接触发 syscall 指令(附可运行代码)
这是最底层、性能最高、自由度最强的调用方式,也是完全绕过 glibc 封装的原生调用方式。直接通过内嵌汇编,手动填充寄存器、触发 syscall 指令,完成系统调用。
这种方式一般不用在业务开发中,多用于内核调试、底层逆向、性能极致优化、漏洞研究场景。我做底层调试的时候,经常用这种方式测试原生系统调用逻辑。
我给大家写一段可直接编译运行的内嵌汇编代码,纯手动实现 write 系统调用,没有依赖任何 glibc 库函数,全程原生指令调用。
#include <stdio.h>// x86_64 内嵌汇编直接调用 write 系统调用int main() { char buf[] = "hello asm syscall\n"; long ret; int len = sizeof(buf); // 手动填充寄存器,触发syscall指令 __asm__ volatile ( "mov $1, %%rax\n" // write系统调用号存入rax "mov $1, %%rdi\n" // 第一个参数:stdout文件描述符1 "mov %[buf], %%rsi\n"// 第二个参数:缓冲区地址 "mov %[len], %%rdx\n"// 第三个参数:写入长度 "syscall\n" // 触发系统调用 : "=a"(ret) // 接收返回值 : [buf]"r"(buf), [len]"r"(len) : "memory" ); if (ret < 0) { printf("asm syscall failed\n"); } return 0;}
这段代码可以直接 gcc 编译运行,完美输出字符串。全程没有调用任何库函数,所有逻辑都是手动复刻系统调用的底层流程。
看完这段代码,你应该彻底明白系统调用的最底层形态了吧?所谓的系统调用,本质就是填寄存器、发指令、等内核返回。所有的库函数,都是在帮我们做这堆重复工作。
这种方式的性能是三种方式里最高的,没有任何封装开销。但开发成本极高、可读性极差、完全不兼容跨架构场景,业务开发绝对不推荐使用。
五、解剖一个系统调用:以 write() 为例
理论讲再多,不如实战拆解一个完整案例,以最常用的 write 系统调用为例。
5.1 用户态视角:C 库中的 write() 函数
站在我们开发者的用户态视角,write 函数极其简单,入参只有三个,文件描述符、数据缓冲区、写入长度。
函数原型如下:
ssize_t write(int fd, const void *buf, size_t count);
我们只需要打开文件得到 fd,传入数据和长度,就能完成写入。成功返回实际写入的字节数,失败返回 -1,通过 errno 获取错误信息。
在用户态看来,这就是一个普通的 IO 函数。完全感知不到内核切换、感知不到寄存器填充、感知不到复杂的内核处理逻辑。glibc 的封装,把所有复杂底层细节全部隐藏了。
5.2 Glibc 封装与 syscall 指令的落地
用户代码调用 write(),链接到 glibc 里的符号。
glibc 的 write 函数内部,先会做简单的参数合法性校验,判断 fd 是否合法、buf 指针是否为空、count 是否合规。参数异常直接返回错误,无需进入内核。
参数校验通过后,glibc 按照架构约定,将 __NR_write 调用号和三个参数,分别写入对应 CPU 寄存器,然后执行 syscall 指令,触发用户态到内核态的切换。
内核执行完毕返回后,glibc 读取 rax 寄存器的返回值。如果返回值大于等于 0,直接返回给上层业务。如果是负数,说明调用失败,赋值 errno 并返回 -1。
整个 glibc 封装流程,耗时极短,几乎可以忽略。这也是为什么 write 函数效率极高的原因,封装层几乎没有冗余逻辑。
5.3 内核视角:从 sys_write 到 VFS 再到文件系统的完整链路
syscall 指令触发后,内核通过调用号匹配到 sys_write 内核函数,正式进入内核处理链路。这是整个写入流程的核心环节,也是绝大多数人完全不了解的底层逻辑。
sys_write 函数不会直接操作磁盘,它会先通过文件描述符 fd,查找当前进程的文件结构体数组,拿到对应的 file 结构体。file 结构体中记录了文件的类型、操作函数集、inode 节点、挂载信息等核心数据。
然后内核会调用 VFS 虚拟文件系统的通用写入接口。Linux 万物皆文件的核心,就是 VFS 的抽象能力。VFS 屏蔽了不同文件系统的差异,不管是 ext4、xfs、tmpfs,还是管道、socket、设备文件,都可以通过统一的 write 接口写入。
VFS 会根据文件对应的 inode 类型,匹配到具体的文件系统写入函数。如果是普通 ext4 文件,就调用 ext4 的写入逻辑;如果是 socket 文件,就调用网络写入逻辑;如果是管道文件,就调用管道写入逻辑。
确定具体文件系统后,内核会执行页缓存管理、缓冲区写入、脏页标记、磁盘刷盘等一系列逻辑。Linux 为了优化 IO 性能,不会每次 write 都直接写磁盘,而是先写入内核页缓存,标记为脏页,后续由内核线程异步刷盘。
5.4 数据拷贝与返回,如何在用户空间感受不到切换
很多人疑惑,一次 write 调用涉及用户态内核态切换、多次数据拷贝、内核多层逻辑处理,为什么上层代码感知这么顺畅,完全感受不到底层的复杂操作?
核心原因有两个,一是内核的极致性能优化,二是操作系统的同步阻塞设计。
用户态传入的 buf 数据,会被内核安全拷贝到内核页缓存中。内核采用高效的内存拷贝指令,结合 CPU 缓存优化,拷贝速度极快。同时内核会做权限校验,保证数据安全。
所有内核逻辑都是同步串行执行的,在系统调用执行期间,用户进程会被内核挂起,暂停用户态代码执行,等待内核处理完成。
内核处理完毕后,立刻恢复用户态上下文,返回执行结果。整个切换、处理、恢复流程,耗时极短,加上 CPU 的高速运算能力,上层业务代码几乎感知不到阻塞和切换。
说白了,操作系统帮我们屏蔽了所有底层的卡顿、切换、复杂逻辑,给开发者提供了简洁、同步、可靠的调用体验。
5.5 动手实验:用 gdb 或 perf 追踪一次 write 的完整路径
单纯用 gdb 追 glibc 到内核不太直接,因为系统调用一进去就是内核态,普通用户态 gdb 不会像调自己函数那样单步进内核。除非你搭内核调试环境,比如 qemu + gdb 调 kernel,那是另一套玩法。
日常更实用的是 strace 和 perf。
先写程序:
#include <unistd.h>#include <string.h>int main() { const char *msg = "trace me\n"; write(1, msg, strlen(msg)); return 0;}
编译:
gcc -g trace_write.c -o trace_write
用 strace:
strace -e write ./trace_write
输出类似:
write(1, "trace me\n", 9) = 9
加耗时:
strace -T -e write ./trace_write
可能看到:
write(1, "trace me\n", 9) = 9 <0.000023>
-T 会显示系统调用耗时。这个值不要迷信,strace 自己也会带来开销,但排查方向很好用。
再用 perf trace:
perf trace -e syscalls:sys_enter_write,syscalls:sys_exit_write ./trace_write
你会看到进入和退出 write 的事件。
如果你想看调用栈,可以尝试:
perf record -g ./trace_writeperf report
不过这么短的程序可能采不到什么。对于真实服务,perf 更有价值。
还有一个很香的工具是 bpftrace。比如追 write:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_write { printf("pid=%d fd=%d count=%d\n", pid, args->fd, args->count); }'
然后另一个终端运行程序,就能看到系统调用进入事件。
这类工具用熟以后,排查 Linux 问题会非常爽。以前靠猜,现在能看证据。
六、系统调用的性能代价与优化
6.1 上下文切换的测量方法及开销量化
很多文章喜欢说系统调用慢,这话对,但也不完整。
系统调用比普通函数调用慢,这是肯定的。因为它涉及用户态和内核态切换,保存恢复上下文,执行内核入口出口逻辑,还可能受到 CPU 安全缓解机制影响。
但一次简单系统调用到底多慢?
这取决于 CPU、内核版本、配置、安全特性、虚拟化环境、调用类型。一个简单的 getpid() 可能几十到几百纳秒级别,也可能更高。真正 I/O 系统调用可能因为磁盘、网络、锁等待,直接到微秒、毫秒甚至更久。
所以不要问“系统调用慢不慢”。
要问:
这个系统调用在我的热路径里每秒发生多少次?
它有没有阻塞?
它有没有拷贝大量数据?
它有没有触发锁竞争?
它有没有导致调度?
它能不能批量化?
测量系统调用开销,可以写个小程序循环调用。
#define _GNU_SOURCE#include <unistd.h>#include <sys/syscall.h>#include <time.h>#include <stdio.h>static long nsec_diff(struct timespec a, struct timespec b) { return (b.tv_sec - a.tv_sec) * 1000000000L + (b.tv_nsec - a.tv_nsec);}int main() { const long n = 1000000;struct timespec s, e; clock_gettime(CLOCK_MONOTONIC, &s); for (long i = 0; i < n; i++) { syscall(SYS_getpid); } clock_gettime(CLOCK_MONOTONIC, &e); long ns = nsec_diff(s, e); printf("total: %ld ns\n", ns); printf("avg: %.2f ns\n", (double)ns / n); return 0;}
编译:
gcc bench_getpid.c -O2 -o bench_getpid./bench_getpid
这个程序不是严谨基准测试。它会受 CPU 频率、调度、vDSO、编译器优化、环境噪音影响。但它能给你一个直觉。
真正做性能分析,别只写 micro benchmark。还要看真实业务火焰图、系统调用频率、延迟分布。
你可以用:
strace -c ./your_program
它会统计系统调用次数和耗时。
示例输出大概长这样:
% time seconds usecs/call calls errors syscall------ ----------- ----------- --------- --------- ---------------- 60.00 0.012000 12 1000 read 25.00 0.005000 5 1000 write 10.00 0.002000 2 1000 futex
这类统计很适合发现“调用次数离谱”的问题。
我见过有人每处理一条消息都 clock_gettime 好几次,每打一行日志都查一次配置文件,每次请求都读 /proc。单次都不大,累计起来吓人。你问他为什么这么写,他说“这样比较直观”。我也不知道这么说对不对,但机器不会因为你直观就免费。
6.2 加速调用的特殊通道:vDSO(虚拟动态共享对象)
有些系统调用太高频,但又不一定非要进入内核。
获取时间就是典型。
如果每次 clock_gettime() 都要切进内核,很多程序会被时间调用拖累。于是 Linux 提供了 vDSO,virtual dynamic shared object,虚拟动态共享对象。
它是什么?
可以理解为内核映射到用户进程地址空间里的一小段只读代码和数据。用户态调用某些函数时,可以直接在用户态读取内核维护的时间相关数据,避免真正系统调用。
你可以看进程映射:
cat /proc/self/maps | grep vdso
可能看到:
7ffd5d1f9000-7ffd5d1fb000 r-xp 00000000 00:00 0 [vdso]
也可以用:
ldd /bin/ls
看到类似:
linux-vdso.so.1
这不是磁盘上的普通 .so 文件,而是内核提供的特殊映射。
glibc 调用 clock_gettime() 时,会尽量走 vDSO 里的 __vdso_clock_gettime。如果不支持,或者某些时钟类型不能走 vDSO,再退回真实系统调用。
这设计很聪明。
它保留了系统调用语义,又避免了高频场景下的切换成本。
但 vDSO 不是万能的。不是所有系统调用都能这么搞。像读文件、写 socket 这种涉及内核对象状态和权限检查的操作,不可能纯用户态解决。
vDSO 适合那些内核可以安全暴露只读数据、用户态可计算结果的场景。
6.3 减少调用频率:批量 I/O、readv/writev、io_uring 初探
系统调用优化的第一原则,不是把 syscall 指令写得更帅。
是少调用。
比如 I/O。
你一次写 1 字节,写一百万次。和一次写 1MB,差别巨大。前者要进入内核一百万次,后者可能一次就够。
这也是为什么 stdio 有缓冲。
fprintf(fp, "hello");
它不一定立刻 write。它可能先写入用户态缓冲区,攒到一定程度再刷新。这样减少系统调用次数。
网络服务里也一样。小包太多会放大系统调用和协议栈开销。可以用批量读写、缓冲、聚合、减少 flush 次数。
readv 和 writev 是 scatter-gather I/O。
假设你有多个 buffer:
#include <sys/uio.h>#include <unistd.h>#include <string.h>int main() {struct iovec iov[3]; iov[0].iov_base = "hello "; iov[0].iov_len = 6; iov[1].iov_base = "writev "; iov[1].iov_len = 7; iov[2].iov_base = "world\n"; iov[2].iov_len = 6; writev(1, iov, 3); return 0;}
一次系统调用写多个不连续缓冲区。你不用先把它们 memcpy 到一个大 buffer。
这就是减少系统调用次数,也减少用户态拷贝。
再往前走,就是 io_uring。
io_uring 的目标之一,是减少传统异步 I/O 的系统调用和上下文切换开销。它通过共享的提交队列 SQ 和完成队列 CQ,让用户态和内核态用环形队列交换请求与结果。用户态批量提交,内核批量处理,完成后再通知。
它不是银弹。
用得好,性能很漂亮。用不好,复杂度直接反咬你一口。尤其是业务本来没那么高 I/O 压力时,上 io_uring 可能只是把简单问题变成复杂问题。技术人有时候会犯这个毛病:看见新武器就想往项目里塞。像我年轻时看见 mmap 一样,啥都想 mmap,后来被一致性和生命周期教育了。
io_uring 适合高性能存储、网络、代理、数据库这类场景。普通业务服务要不要用,先量化瓶颈。
别为了炫技。
线上机器不吃这一套。
6.4 零拷贝不是没有拷贝
传统文件发送到 socket,大概可能这样:
磁盘 ↓内核页缓存 ↓用户态缓冲区 ↓内核 socket 缓冲区 ↓网卡
用户态读一次,写一次。数据从内核到用户,再从用户回内核。你业务代码可能根本不看内容,只是转发。那这两次拷贝就很亏。
sendfile() 就是典型优化。
它可以把文件内容直接从文件 fd 发送到 socket fd,减少用户态参与。
#include <sys/sendfile.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>#include <stdio.h>int main() { int in = open("hello.txt", O_RDONLY); if (in < 0) { perror("open"); return 1; }struct stat st; fstat(in, &st); off_t offset = 0; ssize_t n = sendfile(STDOUT_FILENO, in, &offset, st.st_size); if (n < 0) { perror("sendfile"); } close(in); return 0;}
这里为了演示,把文件发到标准输出。真实场景里常见是发到 socket。
splice() 更灵活。它可以在 pipe 和 fd 之间移动数据。常见搭配是文件、pipe、socket。它的接口比较硬核,用起来没 sendfile 那么亲民。
零拷贝这个词容易误导。
很多时候不是绝对零拷贝,而是减少 CPU 拷贝、减少用户态和内核态之间的数据搬运,让数据更多在内核内部或 DMA 路径里流动。
高性能网络里还有 mmap、AF_XDP、DPDK 等更激进方案。那些更靠近网卡和用户态驱动,复杂度也更高。不是所有服务都值得碰。
对大部分应用来说,先做到这些就很有效:
别频繁小块 read/write善用缓冲能批量就批量能 writev 就别多次 write大文件传输考虑 sendfile高并发 I/O 再评估 io_uring
这个顺序挺朴素,但管用。
最后说几句不太鸡汤的话
系统调用这个主题,往浅了说,就是用户态请求内核服务。
往深了说,它连接了 CPU 特权级、进程模型、虚拟内存、文件系统、网络协议栈、调度器、安全机制和性能优化。
你平时写业务代码,看不到它。
但它一直在。
open 在。
read 在。
write 在。
mmap 在。
futex 在。
epoll_wait 在。
程序跑得顺时,它们像空气。出了问题,它们就变成线索。