前言
这篇博客就是专门写给零基础小白的入门干货,全程踩坑预警+实操演示,帮你跨过数据分析的最高门槛。我们会先带你搞懂Python数据分析到底能做什么、适合哪些应用场景,再一步步教你搭建最省心的开发环境,避开版本冲突、依赖缺失等90%的新手常见问题,最后聚焦所有数据分析库的底层基石——Numpy,从核心概念到高频内置函数、典型运算逻辑全部配可运行代码示例,哪怕你之前从来没有接触过编程,跟着走也能快速上手。
Python数据分析简介
使用Python进行数据分析的优势
Python作为当下最为流行的编程语言之一
与Excel,PowerBI,Tableau等软件比较
- PowerBI ,Tableau在处理大数据的时候速度相对较慢
- Excel,Power BI 和Tableau 需要付费购买授权
- Python功能远比Excel,PowerBI,Tableau等软件强大
- Python跨平台,Windows,MacOS,Linux都可以运行
与R语言比较
- Python的工程化能力更强,R专注于统计与数据分析领域
- Python在非结构化数据(文本,图像)和深度学习领域比R更有优势
- 在数据分析相关开源社区,python相关的内容远多于R语言
常用Python数据分析开源库介绍
Numpy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库。 是一个运行速度非常快的数学库,主要用于数组计算 包含:
Pandas
Pandas是一个强大的分析结构化数据的工具集 它的使用基础是Numpy(提供高性能的矩阵运算) 用于数据挖掘和数据分析,同时也提供数据清洗功能 Pandas利器之 Series,是一种类似于一维数组的对象 Pandas利器之 DataFrame,是Pandas中的一个表格型的数据结构
Matplotlib
Matplotlib 是一个功能强大的数据可视化开源Python库 Python中使用最多的图形绘图库 可以创建静态, 动态和交互式的图表
Seaborn
Seaborn是一个Python数据可视化开源库
- 建立在matplotlib之上,并集成了pandas的数据结构
- Seaborn通过更简洁的API来绘制信息更丰富,更具吸引力的图像
- 面向数据集的API,与Pandas配合使用起来比直接使用Matplotlib更方便
Sklearn
Sklearn scikit-learn 是基于 Python 语言的机器学习工具 简单高效的数据挖掘和数据分析工具 可供大家在各种环境中重复使用 建立在 NumPy ,SciPy 和 matplotlib 上
Jupyter Notebook/Jupyter Lab
Jupyter Notebook是一个开源Web应用程序 可以创建和共享代码、公式、可视化图表、笔记文档 是数据分析学习和开发的首选开发环境 用途
- 机器学习等

Python数据分析环境搭建
开发环境搭建
Anaconda简介
Anaconda 是最流行的数据分析平台,全球两千多万人在使用
- Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的
Anaconda安装
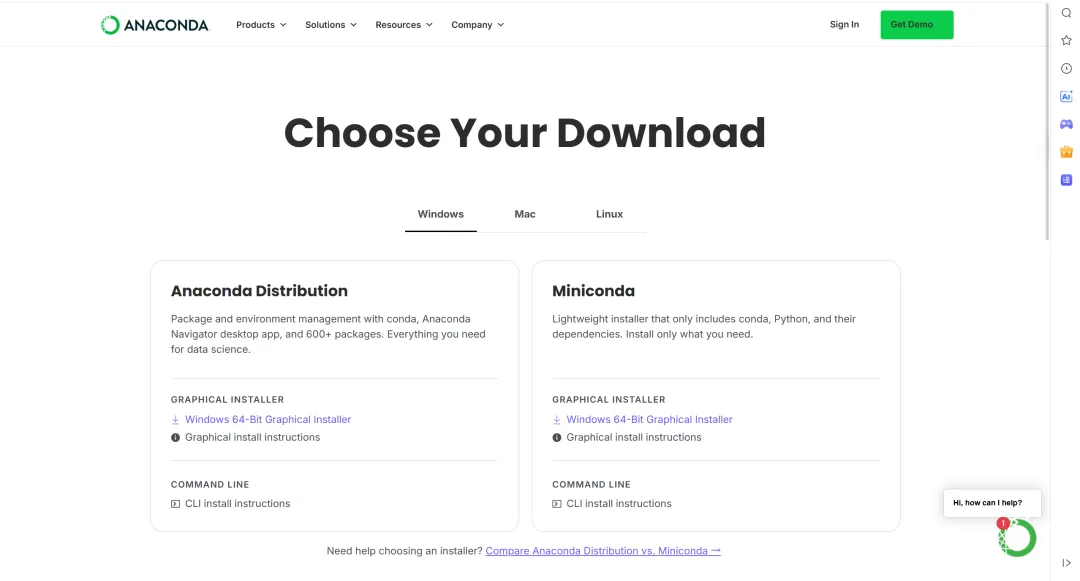
Anaconda 可用于多个平台( Windows、Mac OS X 和 Linux)
- 如果计算机上已经安装了 Python,安装不会对你有任何影响
- https://www.anaconda.com/products/individual
 也可以通过清华镜像源下载
也可以通过清华镜像源下载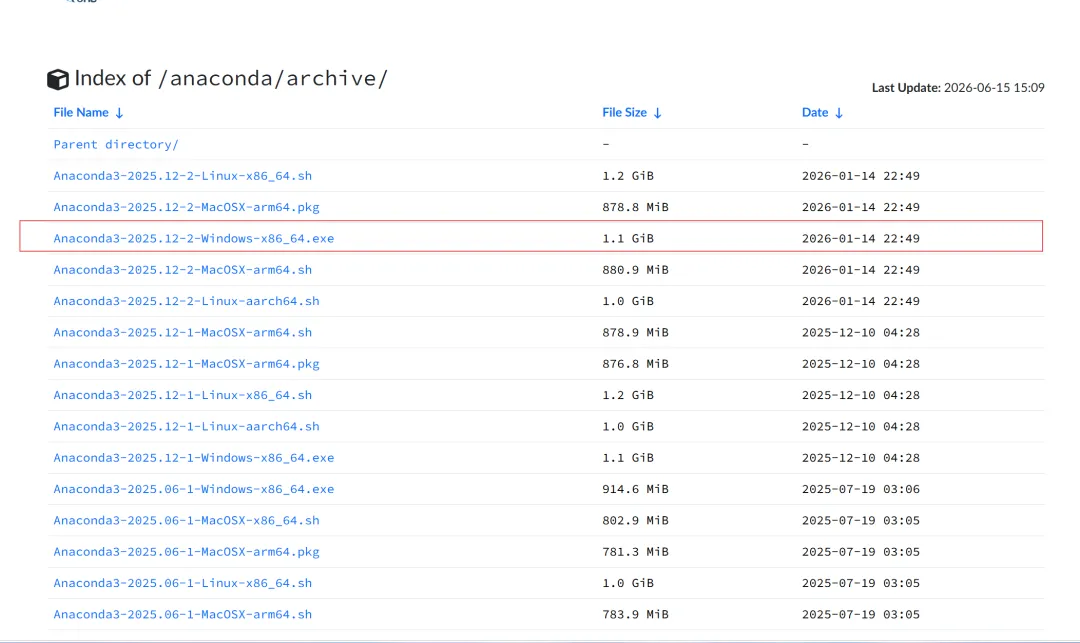
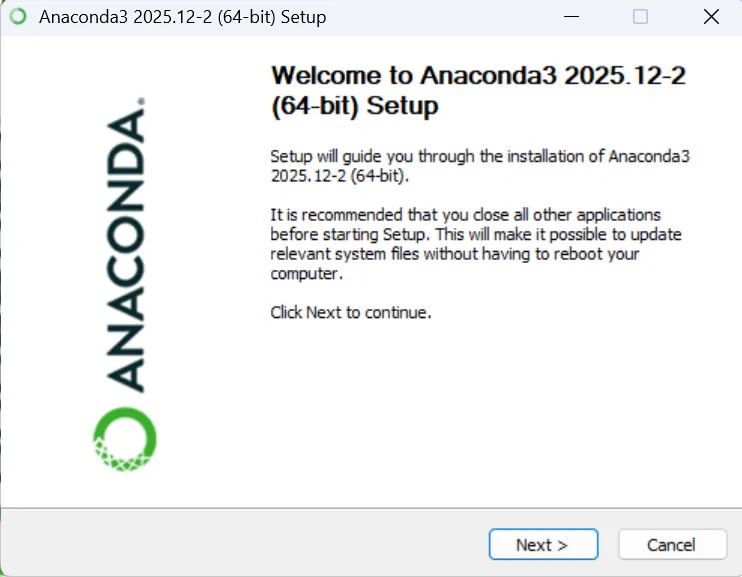
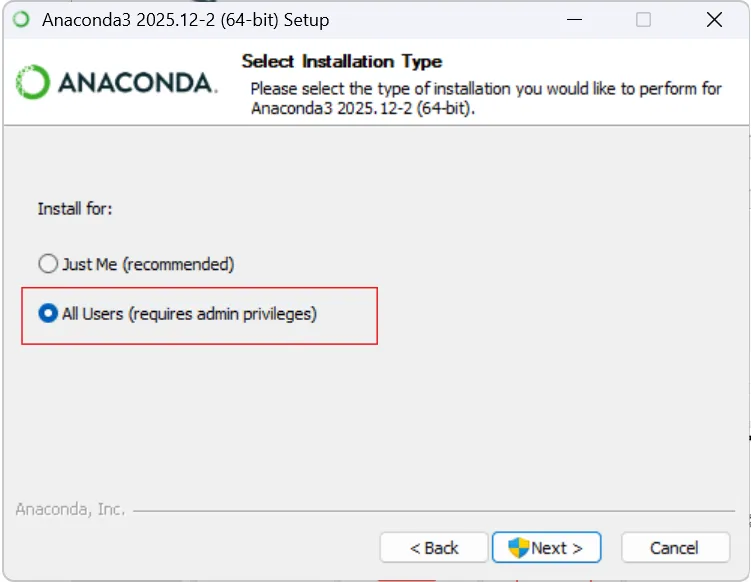
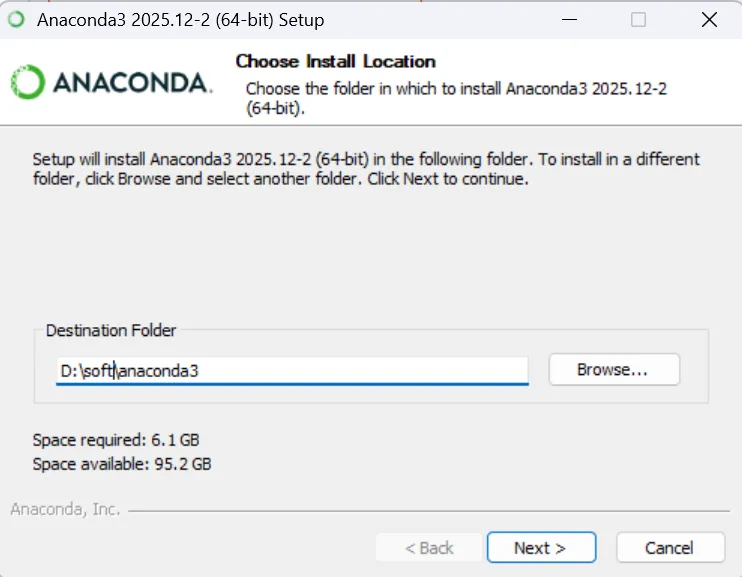
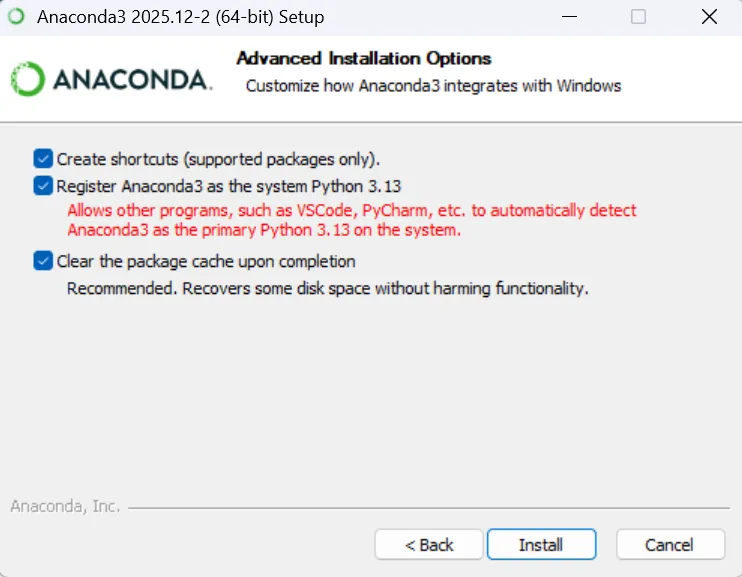
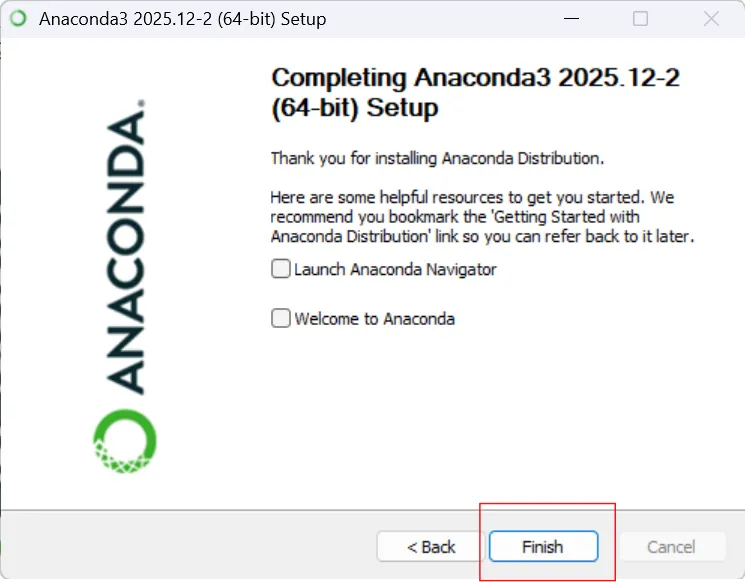 打开anaconda prompt,输入
打开anaconda prompt,输入
 修改默认环境保存路径和下载源修改,输入
修改默认环境保存路径和下载源修改,输入
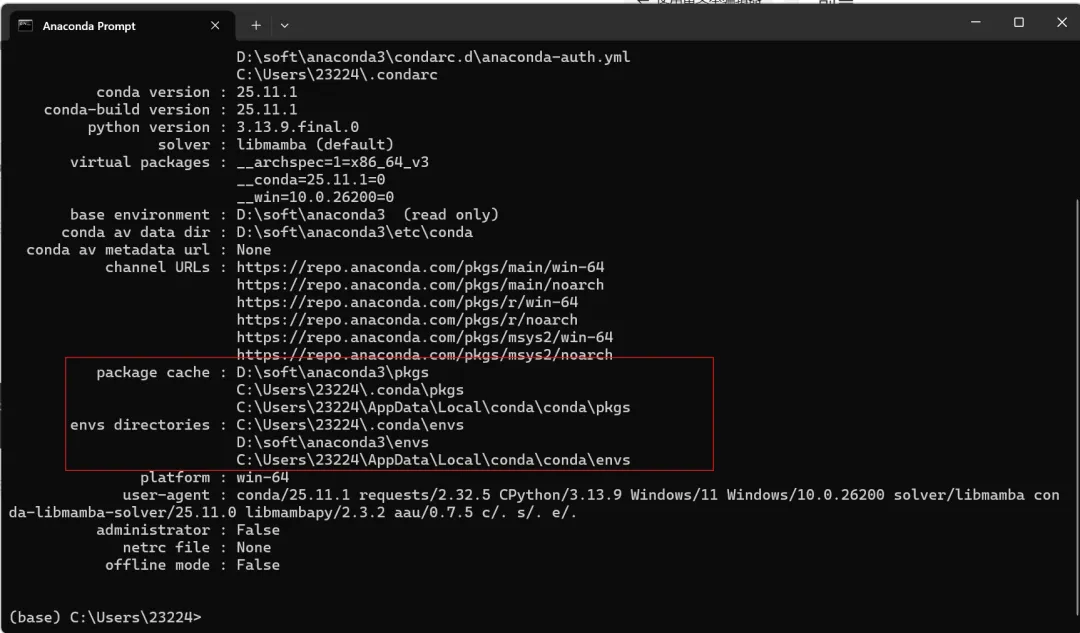 环境和包在电脑中的目录
环境和包在电脑中的目录
Anaconda的使用
Anaconda的界面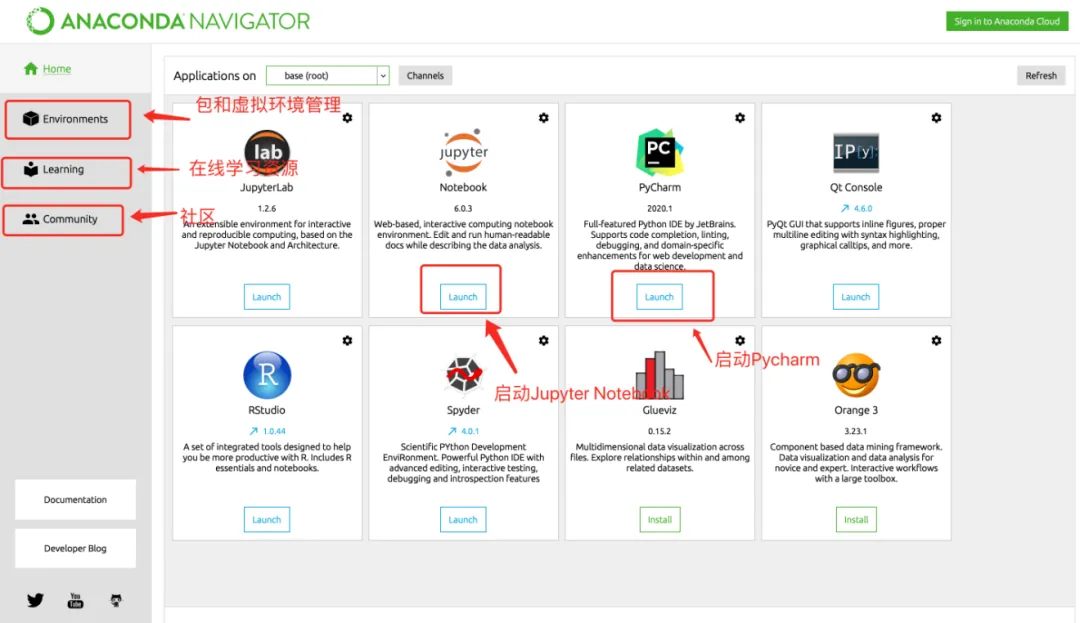 Anaconda的包管理功能-可以通过管理界面安装
Anaconda的包管理功能-可以通过管理界面安装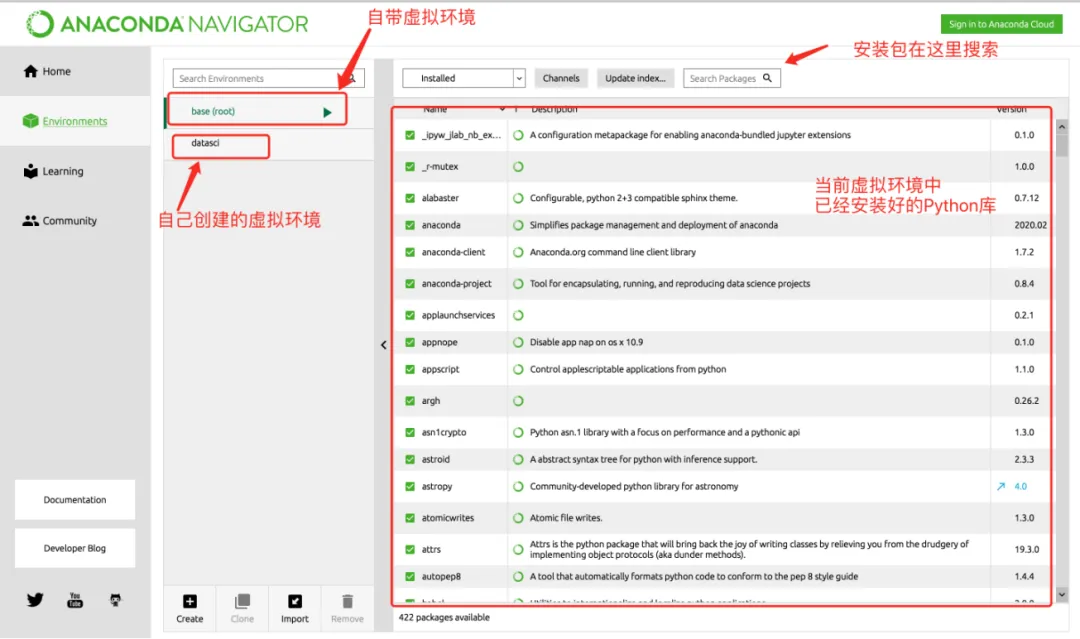
Anaconda的包管理功能-可以通过命令安装
conda install 包名字pip install 包名字
注意,使用pip时最好指定安装源: 阿里云:https://mirrors.aliyun.com/pypi/simple/ 豆瓣:https://pypi.douban.com/simple/ 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
pip install 包名 -i https://mirrors.aliyun.com/pypi/simple/ #通过阿里云镜像安装
Anaconda的虚拟环境管理
虚拟环境的作用
- 很多开源库版本升级后API有变化,老版本的代码不能在新版本中运行
创建自己的虚拟环境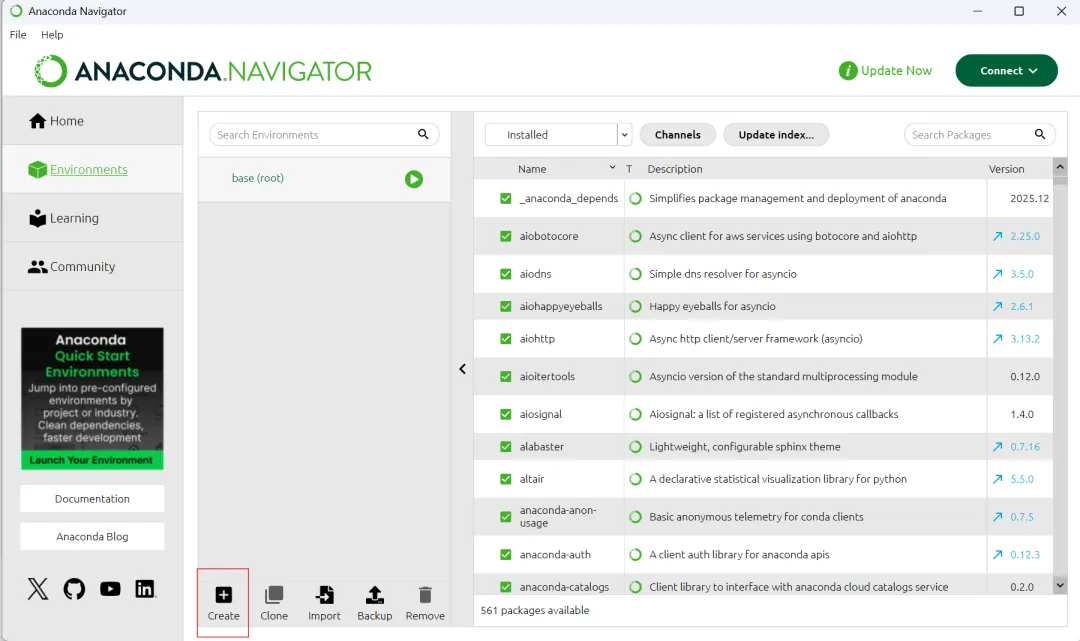 填写虚拟环境名字,选择python的版本
填写虚拟环境名字,选择python的版本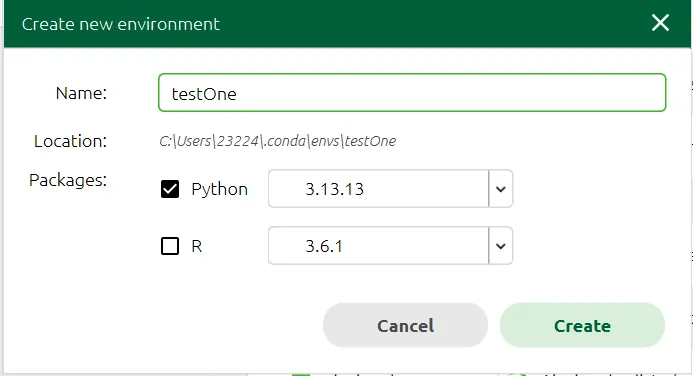 通过命令行创建虚拟环境 conda create -n 虚拟环境名字 python=python版本 #创建虚拟环境 conda activate 虚拟环境名字 #进入虚拟环境 conda deactivate 虚拟环境名字 #退出虚拟环境 conda remove -n 虚拟环境名字 --all #删除虚拟环境
通过命令行创建虚拟环境 conda create -n 虚拟环境名字 python=python版本 #创建虚拟环境 conda activate 虚拟环境名字 #进入虚拟环境 conda deactivate 虚拟环境名字 #退出虚拟环境 conda remove -n 虚拟环境名字 --all #删除虚拟环境
Jupyter Notebook的使用
选择虚拟环境

通过终端启动
Jupyter Notebookconda activate 虚拟环境名字jupyter notebook
新建notebook文档 新建文件之后会打开Notebook界面 Jupyter Notebook的cell(单元格),代码的输入框和输出显示的结果就是cell
新建文件之后会打开Notebook界面 Jupyter Notebook的cell(单元格),代码的输入框和输出显示的结果就是cell
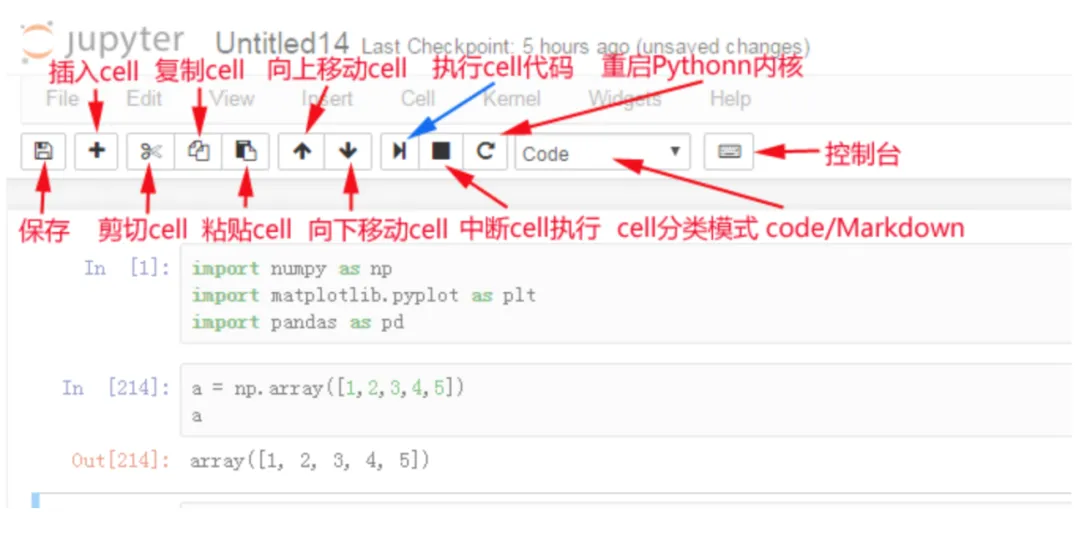 常用快捷键 命令模式,按ESC进入
常用快捷键 命令模式,按ESC进入
用快捷键 编辑模式,按Enter进入
- 多光标操作:Ctrl键点击鼠标(Mac:CMD+点击鼠标)回退:Ctrl+Z(Mac:CMD+Z)
- 为一行或多行代码添加/取消注释:Ctrl+/(Mac:CMD+/)
常用快捷键 两种模式通用快捷键
- Shift+Enter,执行本单元代码,并跳转到下一单元
Jupyter notebook的功能扩展 安装jupyter_contrib_nbextensions库
#进入到虚拟环境中conda activate 虚拟环境名字
在命令模式中,按M即可进入到Markdown编辑模式 使用Markdown语法可以在代码间穿插格式化的文本作为说明文字或笔记
Pycharm集合Jupyter
conda的执行文件的路径为:D:\soft\anaconda3\Scripts\conda.exe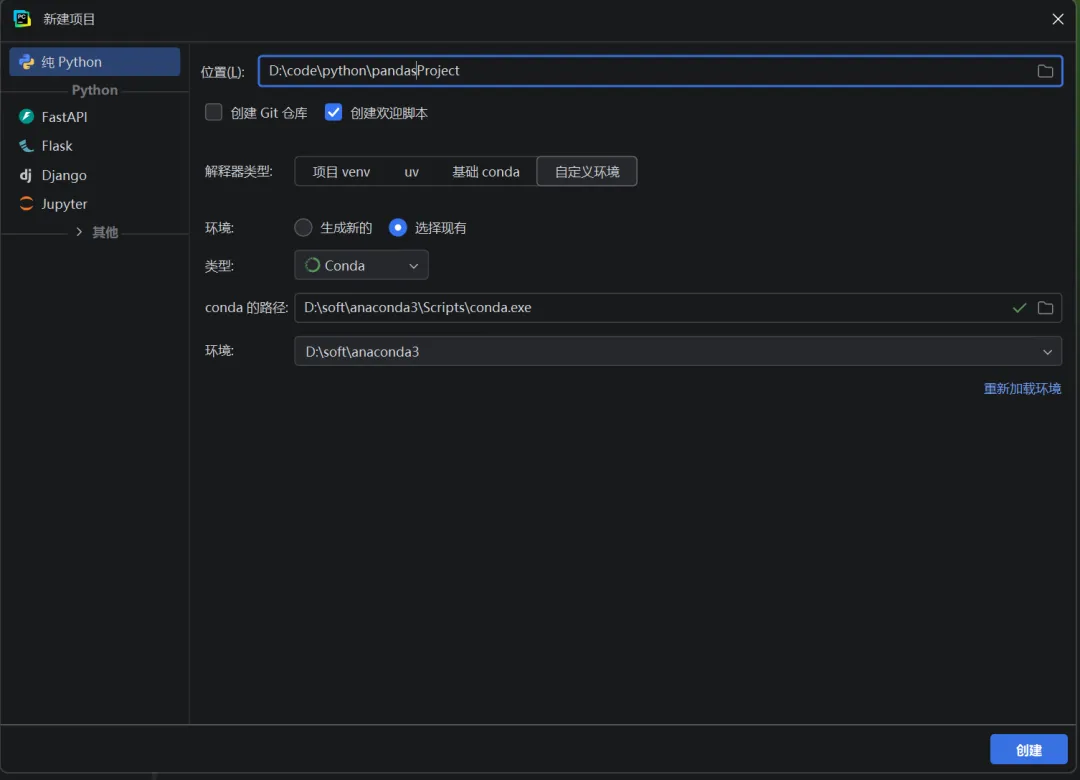
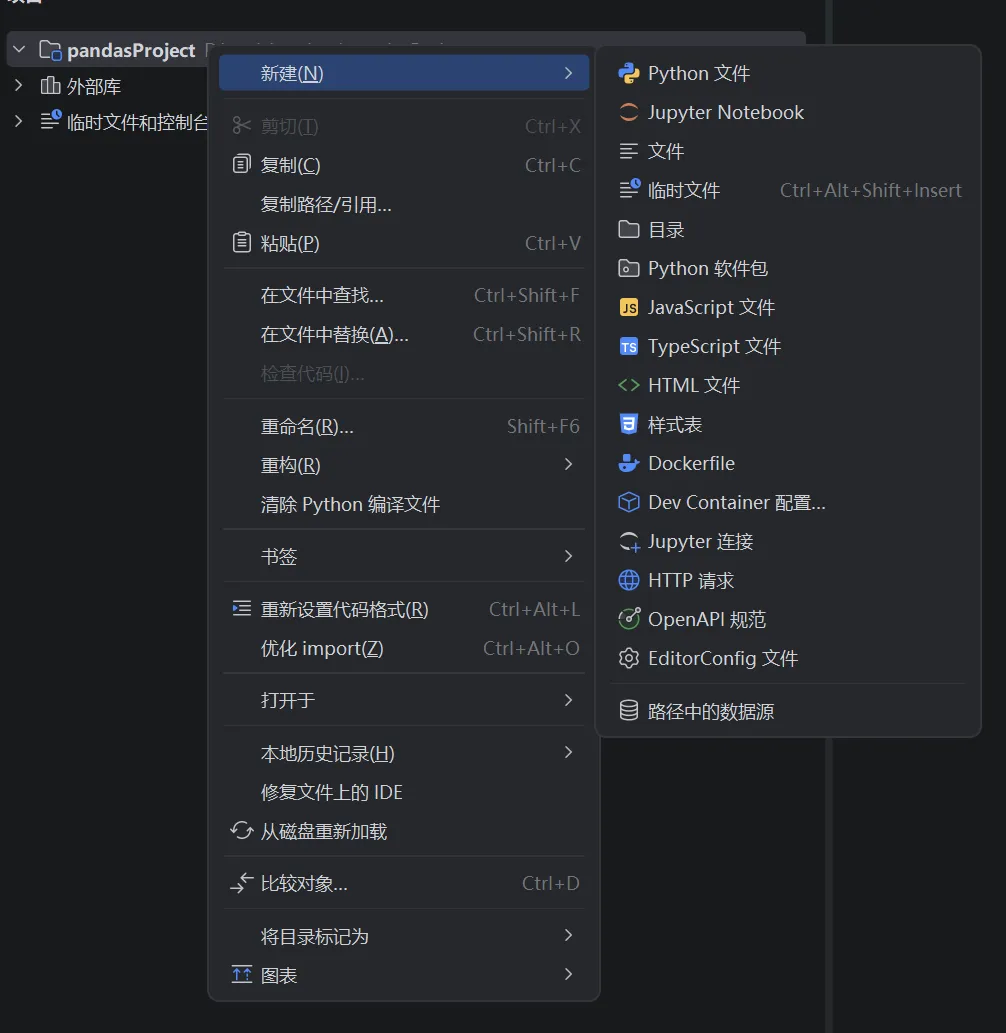
Numpy简介
NumPy(Numerical Python)是Python数据分析必不可少的第三方库 NumPy的出现一定程度上解决了Python运算性能不佳的问题,同时提供了更加精确的数据类型,使其具备了构造复杂数据类型的能力。 本身是由C语言开发,是个很基础的扩展,NumPy被Python其它科学计算包作为基础包,因此理解np的数据类型对python数据分析十分重要。 NumPy重在数值计算,主要用于多维数组(矩阵)处理的库。用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多
NumPy重要功能如下:
高性能科学计算和数据分析的基础包
ndarray,多维数组,具有矢量运算能力,快速、节省空间
矩阵运算,无需循环,可完成类似Matlab中的矢量运算
用于读写磁盘数据的工具以及用于操作内存映射文件的工具
NumPy的数组类被称作ndarray,通常被称作数组。 ndarray对象属性有:
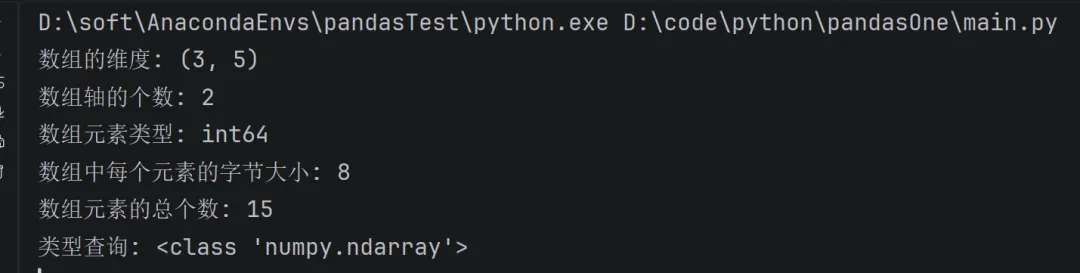
- 数组的维度。这是一个指示数组在每个维度上大小的整数元组。例如一个n排m列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性。
import numpy as npresult = np.arange(15).reshape(3, 5) # 生成 0~14 的一维数组,长度为 15。print ("数组的维度:", result.shape) # 输出 (3, 5)print ("数组轴的个数:", result.ndim) # 输出 2(二维数组)print ("数组元素类型:", result.dtype) # 输出 int64(取决于平台,也可能是 int32)print ("数组中每个元素的字节大小:", result.itemsize) # int64 为 8 字节print ("数组元素的总个数:", result.size) # 输出 15(3*5)print ("类型查询:", type(result)) # 输出 <class 'numpy.ndarray'>
创建ndarray
NumPy数组是一个多维的数组对象(矩阵),称为ndarray,具有矢量算术运算能力和复杂的广播能力,并具有执行速度快和节省空间的特点。注意:ndarray的下标从0开始,且数组里的所有元素必须是相同类型。
arange ()
arange() 类似 python 的 range() ,创建一个一维 ndarray 数组。
import numpy as npnp_arange = np.arange(11, 22, 6, dtype=int)print ("arange创建np_arange:", np_arange)print("arange创建np_arange的元素类型:", np_arange.dtype)print("arange创建np_arange的类型:", type(np_arange))
np.arange(start, stop, step, dtype):生成从 start 开始,到 stop 结束(不包含 stop),步长为 step 的等差数列。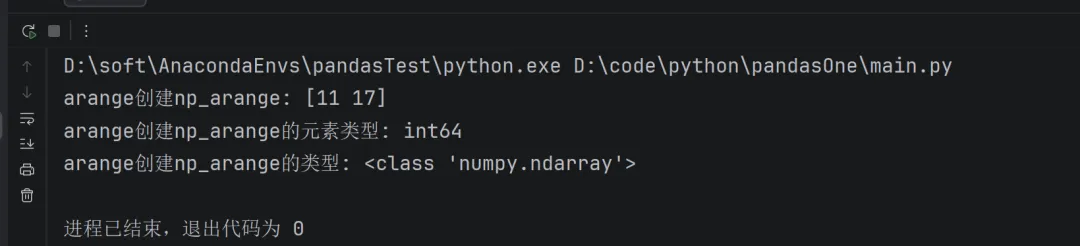
创建随机数矩阵
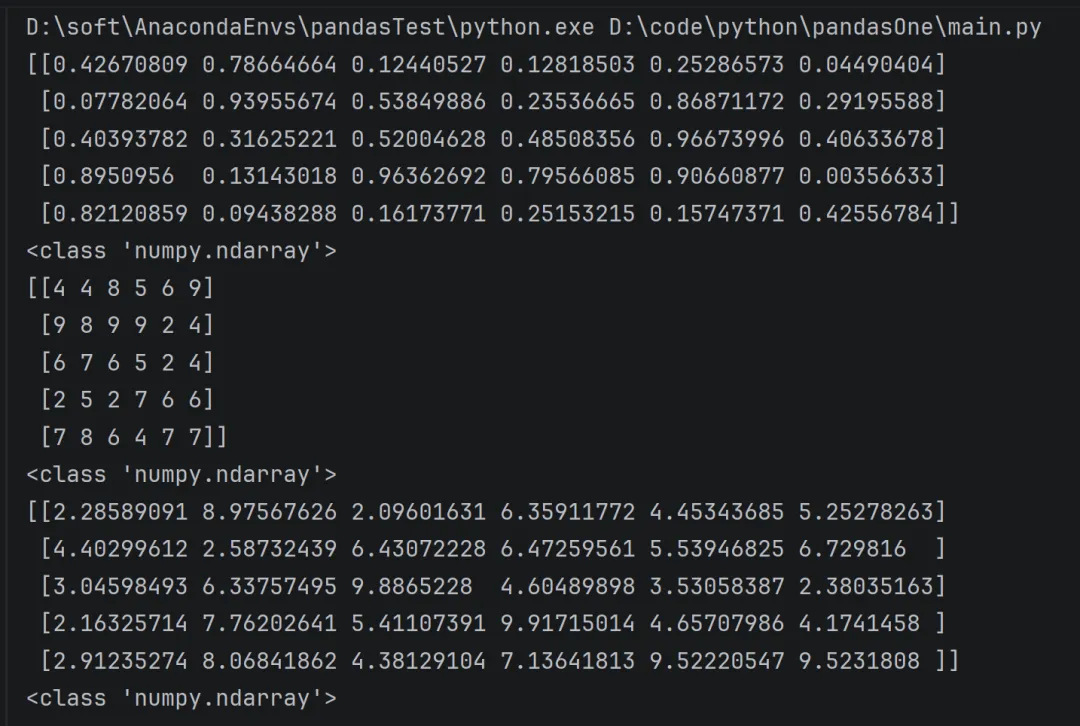
import numpy as np# 生成一个形状为 (5, 6) 的数组,元素是 [0, 1) 区间内均匀分布的随机浮点数(包含 0,不包含 1)arry = np.random.rand(5,6)print(arry)print(type(arry))# 生成一个形状为 (5, 6) 的数组,元素是 从 2 到 10 之间的随机整数(包含 2,不包含 10)arry = np.random.randint(2,10,size=(5,6))print(arry)print(type(arry))# 生成一个形状为 (5, 6) 的数组,元素是 从 2 到 10 之间的连续均匀分布随机浮点数(包含 2,不包含 10,但边界可能包含)arry = np.random.uniform(2,10,size=(5,6))print(arry)print(type(arry))
ndarray的数据类型
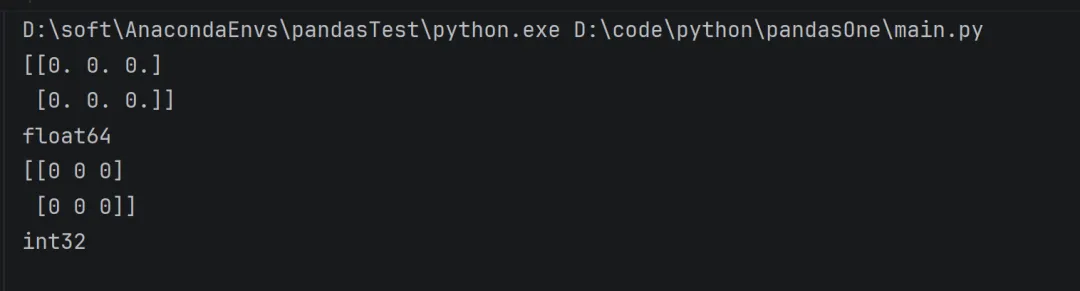
dtype参数,指定数组的数据类型,类型名+位数,如float64, int32 astype方法,转换数组的数据类型
import numpy as npfloat_arr = np.zeros((2,3),dtype=np.float64)print(float_arr)print(float_arr.dtype)int_arr = float_arr.astype(dtype=np.int32)print(int_arr)print(int_arr.dtype)
等比/等差数列
np.logspace等比数列
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
- start:起始值的指数(即 base**start)
- stop:结束值的指数(即 base**stop)
- base:对数的底数(默认为 10,可改为 2、e 等)
- endpoint:是否包含结束值(默认为 True
arr = np.logspace(1,3,3)print(arr)
arr = np.logspace(1,3,3,base=3)print(arr)
 np.linspace等差数列
np.linspace等差数列
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
- endpoint:是否包含终点(True则包含,False则不包含)。
- retstep:设为 True 时,除了返回数组,还会返回公差 d。
arr = np.linspace(0,10,5)print(arr)
 linspace创建的数组元素是浮点型
linspace创建的数组元素是浮点型
Numpy内置函数
基本函数
np.ceil(): 向上最接近的整数,参数是 number 或 array np.floor(): 向下最接近的整数,参数是 number 或 array np.rint(): 四舍五入,参数是 number 或 array np.isnan(): 判断元素是否为 NaN(Not a Number),参数是 number 或 array np.multiply(): 元素相乘,参数是 number 或 array np.divide(): 元素相除,参数是 number 或 array np.abs():元素的绝对值,参数是 number 或 array np.where(condition, x, y): 三元运算符,x if condition else y
mport numpy as nparr = np.random.randn(2, 3) # 生成 2x3 的标准正态分布随机数组(均值为0,方差为1)print(arr) # 打印原始数组print(np.ceil(arr)) # 向上取整(进一法)print(np.floor(arr)) # 向下取整(去尾法)print(np.rint(arr)) # 四舍五入到最近的整数(.5 时取偶数,即“银行家舍入”)print(np.isnan(arr)) # 检测每个元素是否为 NaN(此处全为 False,因为 randn 不会产生 NaN)print(np.multiply(arr, arr)) # 逐元素相乘(等价于 arr * arr 或 arr**2)print(np.divide(arr, arr)) # 逐元素相除(等价于 arr / arr),除自身得 1.0(但 0/0 会得到 NaN 或 inf?注意:这里 arr 可能包含 0,但标准正态连续分布,精确为0的概率极低,几乎不会出现)print(np.where(arr > 0, 1, -1)) # 条件判断:正数→1,非正数(0或负数)→ -1
统计函数
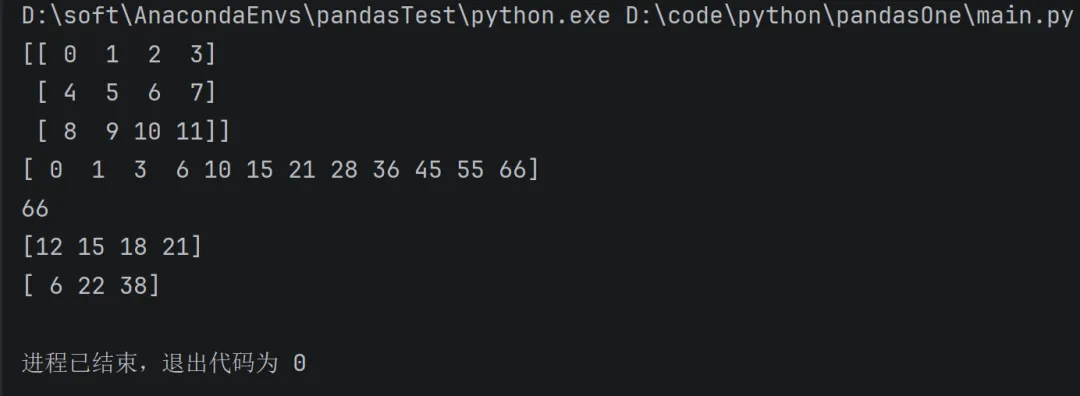
np.mean(), np.sum():所有元素的平均值,所有元素的和,参数是 number 或 array np.max(), np.min():所有元素的最大值,所有元素的最小值,参数是 number 或 array np.std(), np.var():所有元素的标准差,所有元素的方差,参数是 number 或 array np.argmax(), np.argmin():最大值的下标索引值,最小值的下标索引值,参数是 number 或 array np.cumsum(), np.cumprod():返回一个一维数组,每个元素都是之前所有元素的 累加和 和 累乘积,参数是 number 或 array 多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
import numpy as nparr = np.arange(12).reshape(3, 4)print(arr)# 输出:# [[ 0 1 2 3]# [ 4 5 6 7]# [ 8 9 10 11]]print(np.cumsum(arr))# 输出:[ 0 1 3 6 10 15 21 28 36 45 55 66]# (默认展平成一维后的逐项累加)print(np.sum(arr))# 输出:66# (所有元素总和 = 0+1+...+11)print(np.sum(arr, axis=0))# 输出:[12 15 18 21]# (按列求和:第1列0+4+8=12,第2列1+5+9=15...)print(np.sum(arr, axis=1))# 输出:[ 6 22 38]# (按行求和:第1行0+1+2+3=6,第2行4+5+6+7=22...)
去重函数
np.unique():找到唯一值并返回排序结果,类似于Python的set集合
import numpy as nparr = np.array([[1, 5, 8], [8, 5, 2]])values, counts = np.unique(arr, return_counts=True)print(values)print(counts) print(np.sum(arr, axis=1)) #按行计算 1+5+8=14 8+5+2 = 15
排序函数
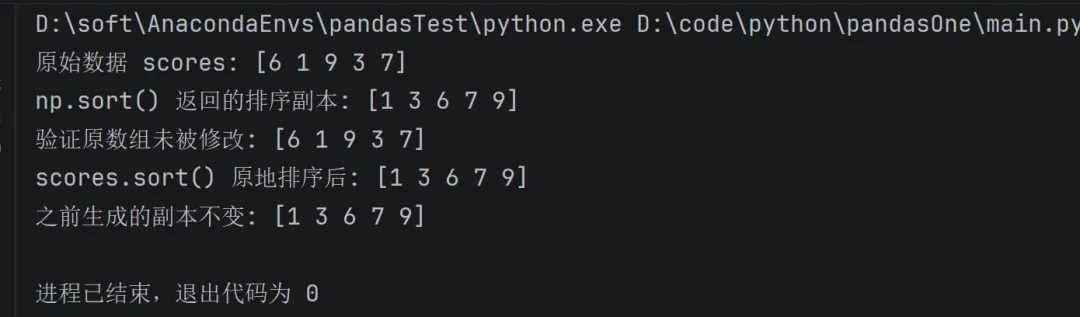
对数组元素进行排序
import numpy as np# 1. 定义原始数据(修改了数据内容和变量名)scores = np.array([6, 1, 9, 3, 7])print("原始数据 scores:", scores)# 2. 方式一:np.sort() —— 返回排序后的新数组,原数组不变sorted_scores = np.sort(scores)print("np.sort() 返回的排序副本:", sorted_scores)print("验证原数组未被修改:", scores) # 原数组顺序依旧是 [6 1 9 3 7]# 3. 方式二:ndarray.sort() —— 直接在原数组上修改(原地排序)scores.sort()print("scores.sort() 原地排序后:", scores)# 4. 额外验证:之前生成的副本不受原地排序影响print("之前生成的副本不变:", sorted_scores)
Numpy运算
基本运算
数组的算数运算是按照元素的。新的数组被创建并且被结果填充
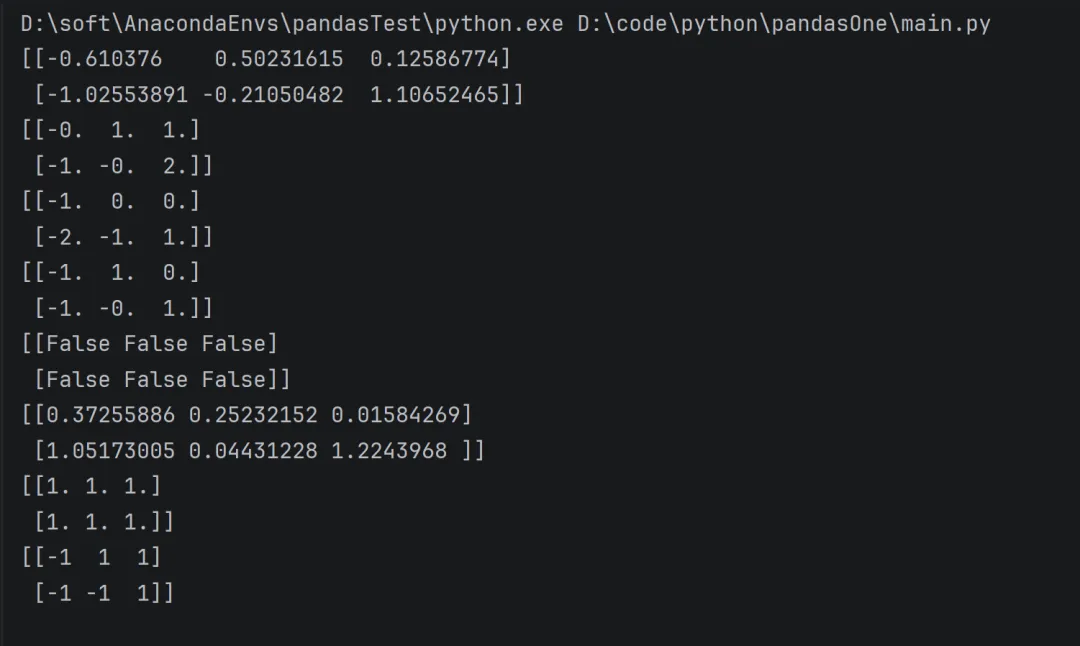
import numpy as np# 原始数据(改用不同的数值和变量名)x = np.array([5, 15, 25, 35])y = np.arange(4) # 生成 [0, 1, 2, 3]# 执行减法运算(与原来相同,但数据变了)z = x - y# 打印结果(变量名和描述都改了)print("数组 x:", x)print("数组 y:", y)print("x - y 的结果:", z)
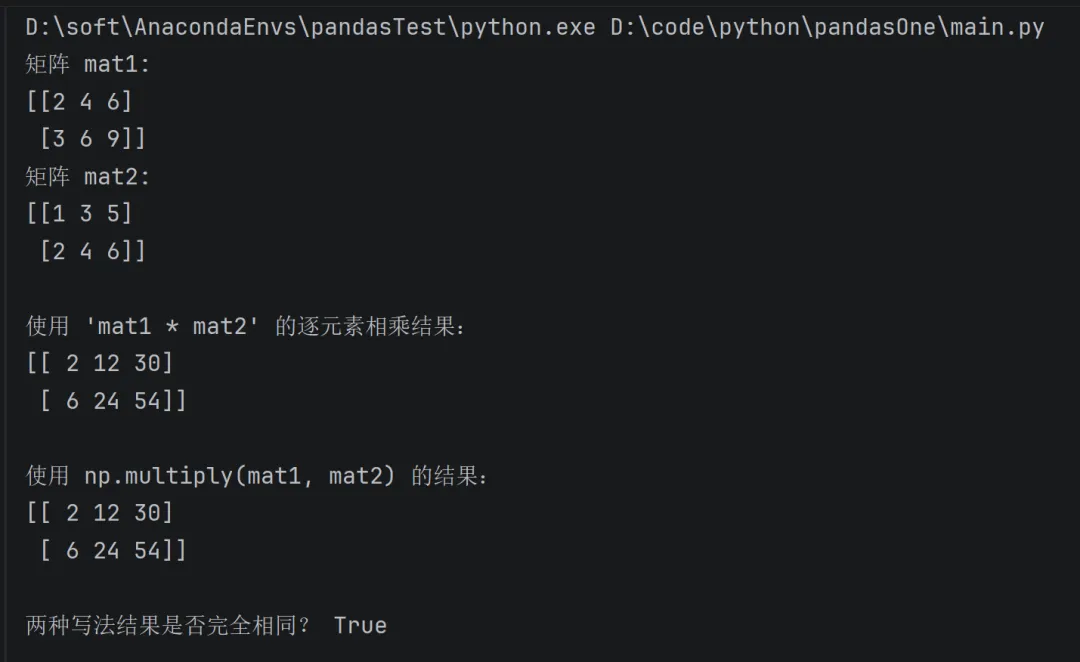
 矩阵乘法 矩阵对应元素的乘法(multiplication by element-wise)
矩阵乘法 矩阵对应元素的乘法(multiplication by element-wise)
import numpy as np# 定义两个用于演示“逐元素相乘”的矩阵(对应位置相乘,不是线性代数里的点积!)mat1 = np.array([[2, 4, 6], [3, 6, 9]])mat2 = np.array([[1, 3, 5], [2, 4, 6]])print("矩阵 mat1:")print(mat1)print("矩阵 mat2:")print(mat2)# 方式一:使用 '*' 运算符(最简洁的写法)result_star = mat1 * mat2print("\n使用 'mat1 * mat2' 的逐元素相乘结果:")print(result_star)# 方式二:使用 np.multiply() 函数(功能与 '*' 完全等价)result_multiply = np.multiply(mat1, mat2)print("\n使用 np.multiply(mat1, mat2) 的结果:")print(result_multiply)# 验证两种写法是否完全一致(纠正原图可能出现的“结果不同”的误导)print("\n两种写法结果是否完全相同?", np.array_equal(result_star, result_multiply))

总结
最后想和大家说:入门数据分析从来不需要你一开始就精通高数、统计学,先把基础工具用熟,能解决哪怕很小的问题,慢慢积累经验就能越走越远。遇到报错别慌,每个成熟的数据分析师都是从修无数个bug里成长起来的~






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
