哈希-Linux找文件为什么这么快?
- 2026-06-29 13:44:55
哈希-Linux找文件为什么这么快?
数据结构与算法 · 哈希表 · 第 04 篇
标签:#哈希表 #Linux内核 #dentry缓存 #文件系统
预计阅读时间:10分钟
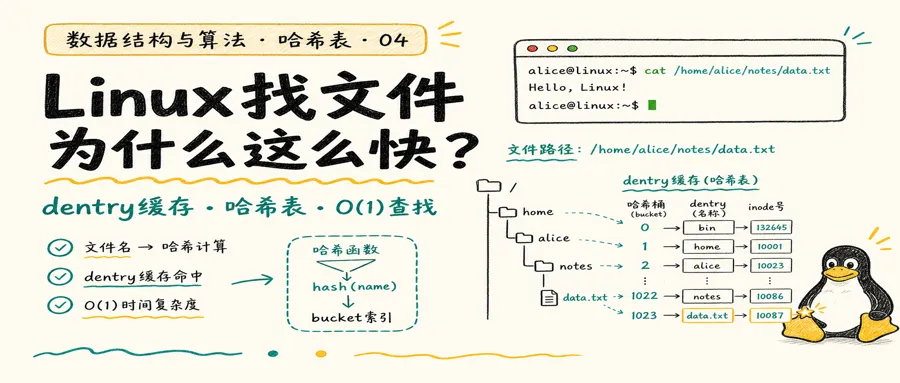
开篇-从根目录找一个文件要多久
你打开终端,输入:
cat /home/alice/projects/demo/src/main.py回车。文件内容瞬间显示在屏幕上。
但你有没有想过:从你敲下回车,到屏幕上出现内容,操作系统内部发生了什么?
这个文件藏在磁盘深处,路径是 /home/alice/projects/demo/src/main.py。操作系统要先找到 home 目录,再找到 alice,再找到 projects,一层一层往下翻,最后定位到 main.py。
如果磁盘上有十万个文件,操作系统一个一个翻,会不会很慢?
不会。Linux 找文件的速度快到让你感觉不到延迟。秘密武器之一就是哈希表。
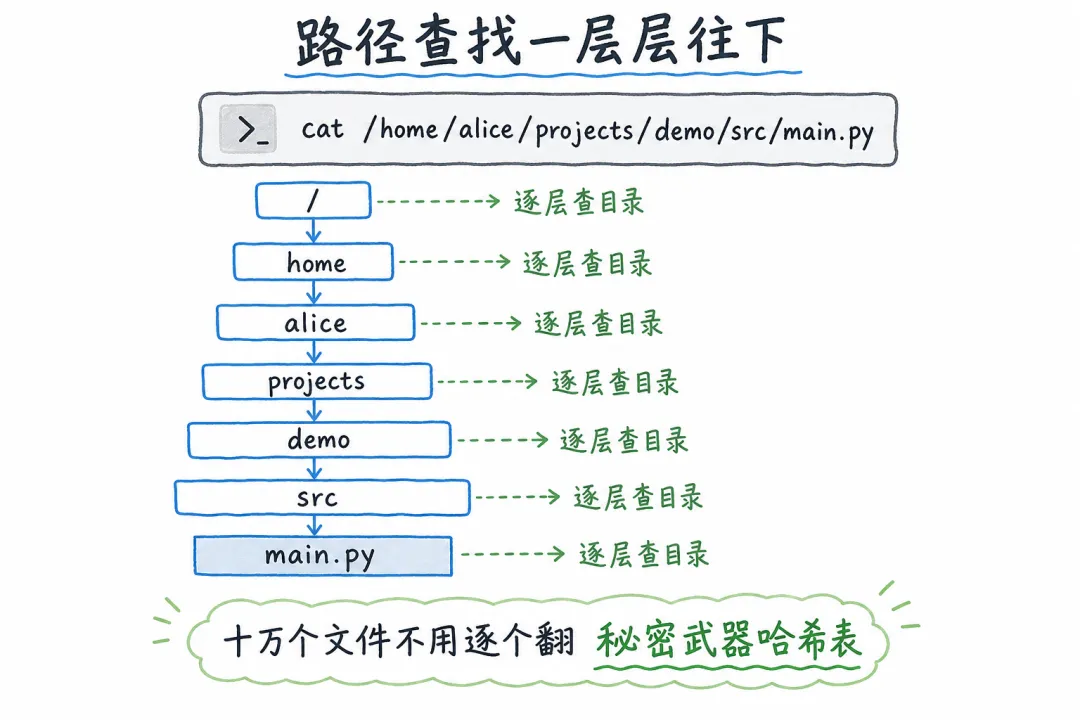
文件在磁盘上是怎么存的
在 Linux 的 ext4 文件系统里,一个目录本质上就是一个表格:
当你访问 /home 时,系统去根目录的表格里查 home 这一项。找到 home 对应的 inode 号,再去磁盘上读取 home 目录的内容。
然后 home 目录里也有自己的表格:
一层一层查下去,直到找到最终的文件。
问题来了:这个表格怎么查?
最笨的方法:从头到尾线性扫描。目录里有 100 个文件,就逐个比对文件名。你找 main.py,它可能排在第 99 个。平均要找 50 次才能命中。
目录里有几千个文件呢?几万次比对,CPU 都要哭了。
dentry 缓存:目录项的"快递柜"
Linux 的解决方案是 dentry cache(目录项缓存)。
dentry 的全称是 directory entry,就是目录里的每一项(文件名 + inode 号)。dentry cache 把这些目录项缓存在内存里,下次查找时直接从内存取,不用再去读磁盘。
但缓存在一起也不够快——如果目录里有几千个文件,在内存里线性扫描依然很慢。所以 Linux 在 dentry cache 内部用了一个哈希表来组织数据。
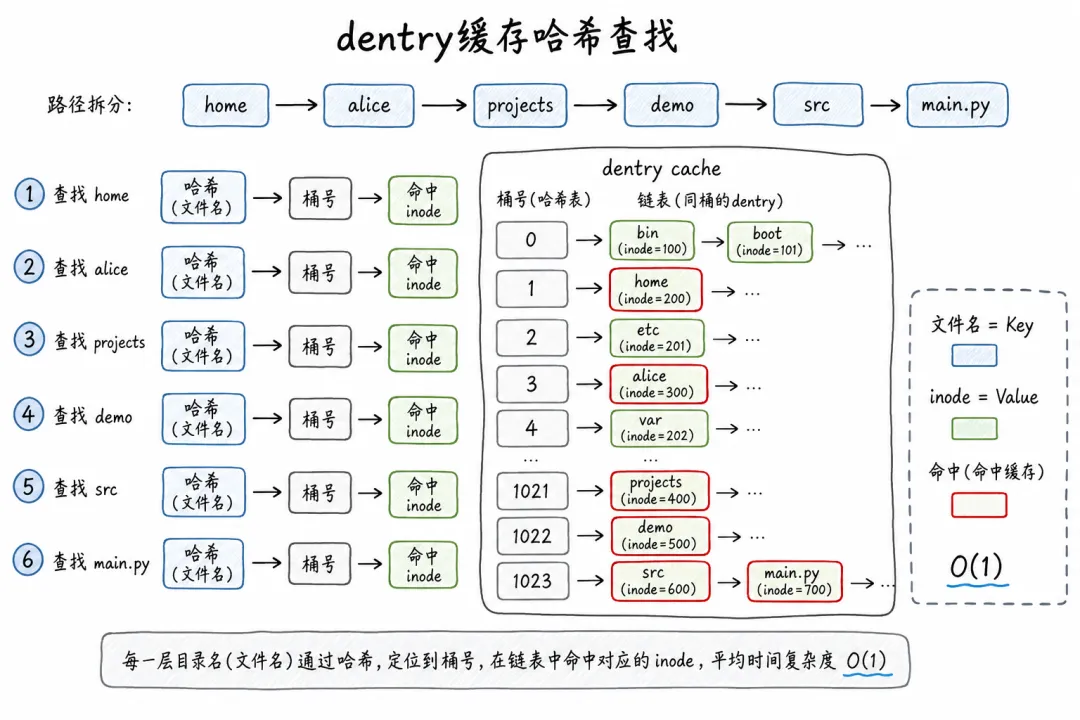
每个目录在 dentry cache 里都有自己的一张哈希表。文件名是键(Key),inode 号是值(Value)。查的时候用哈希函数算出桶的位置,O(1) 时间直接命中。
对比线性扫描:
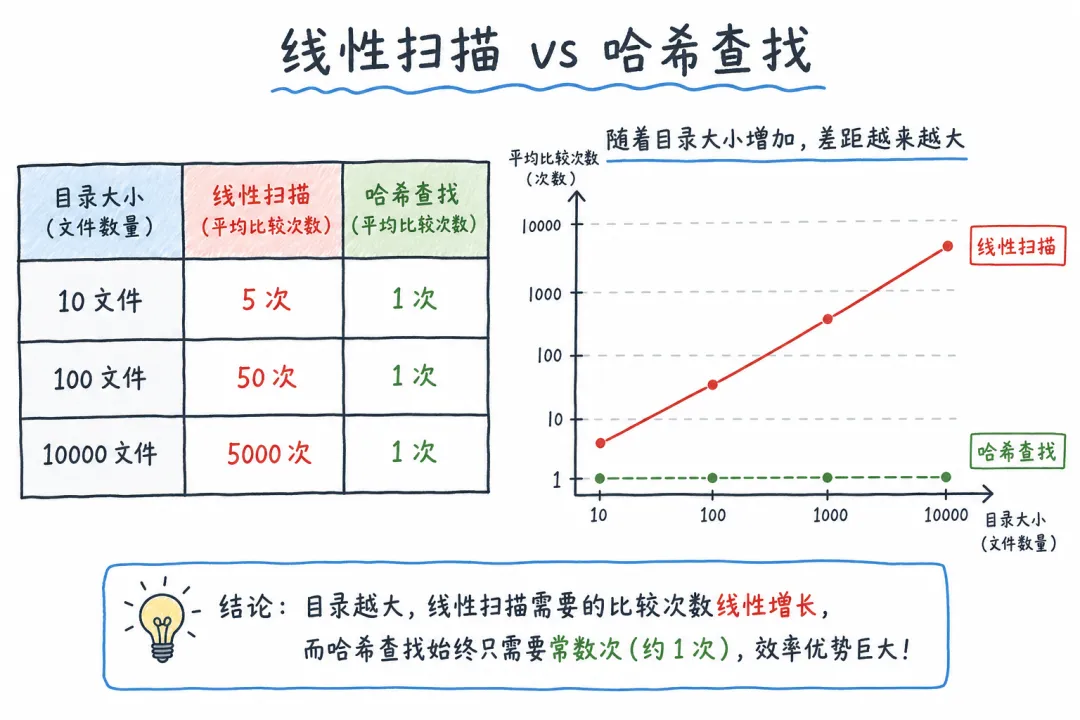
目录越大,哈希的优势越明显。
哈希函数的秘密:文件名怎么变成桶号
Linux 内核里用的是一种简单的哈希函数,把文件名转换成整数,再对桶的数量取模。这个哈希函数不需要特别复杂,它的目标是让文件名均匀分布在各个桶里,避免冲突。 "main.py" 和 "test.py" 应该落到不同的桶里,这样查找时才不会撞车。
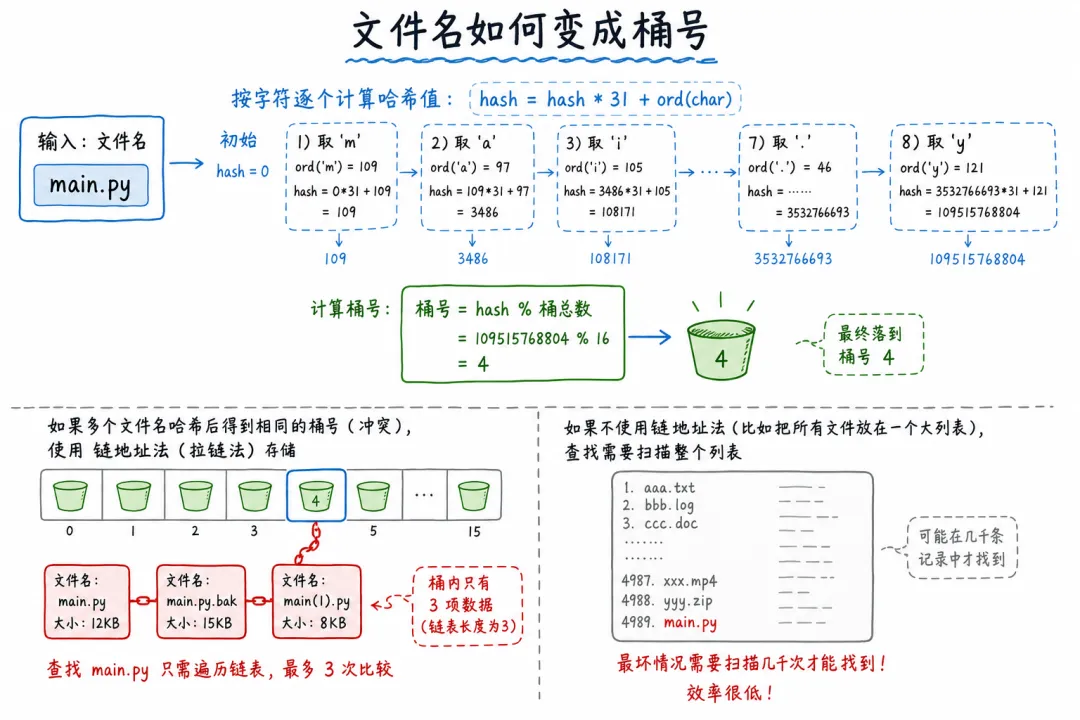
当然,冲突不可避免。两个不同的文件名可能算出同一个桶号。Linux 的做法是链地址法——每个桶里挂一个链表,冲突的目录项串在一起。查找时先定位桶,再在链表里逐个比对。
但你想想:一个桶里挂 3 个目录项的链表,比对 3 次;线性扫描要比对几千次。差距还是巨大的。
缓存失效:文件被删了怎么办
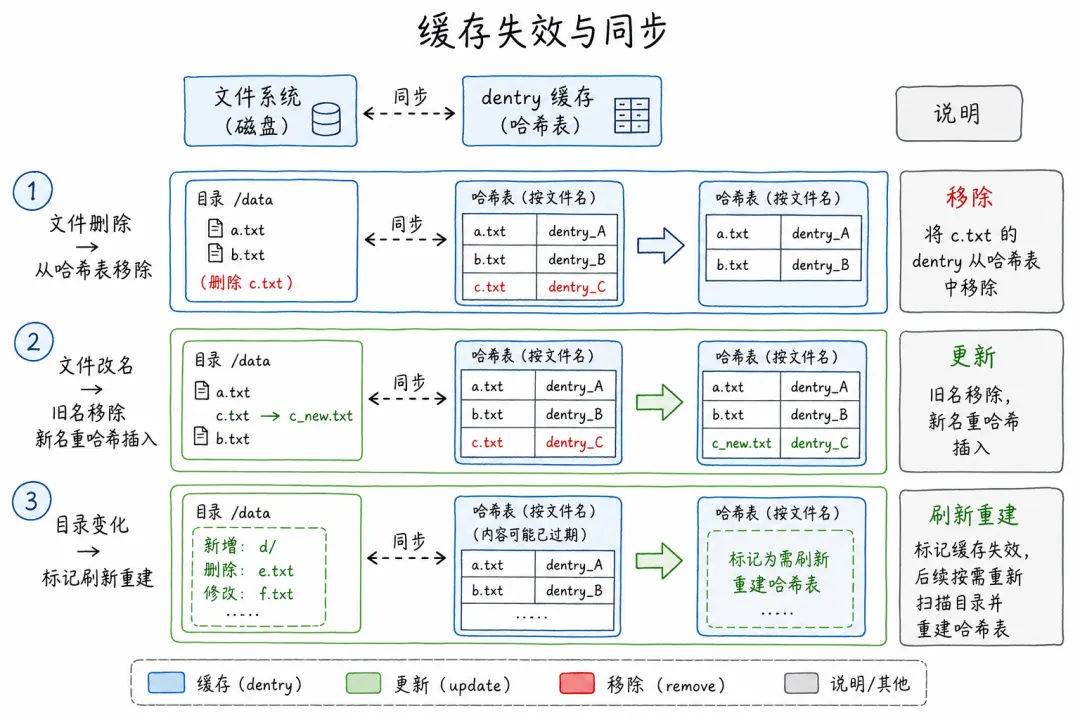
哈希缓存虽然快,但有一个问题:磁盘上的文件可能被创建、删除、改名。内存里的哈希表必须同步更新,否则查到的就是过期信息。
Linux 的做法很干脆:
文件被删除:从 dentry cache 的哈希表里移除对应的条目 文件被改名:旧名字移除,新名字重新哈希插入 目录内容变化:标记该目录的缓存需要刷新,下次访问时重新构建哈希表
这些操作的时间复杂度都是 O(1)(定位桶)+ O(k)(链表长度 k,通常很小)。所以即使频繁修改文件,dentry cache 的性能也不会退化。
现实影响:为什么 Linux 比某些系统快
你有没有过这种体验:在 Windows 上打开一个有几万个文件的目录,资源管理器会卡好几秒。但在 Linux 上,ls 一个几万个文件的目录几乎是瞬间的。
差异之一就是 dentry cache 的设计。Linux 把所有目录项缓存在内存里,并用哈希表组织,查找是 O(1)。某些系统在设计上没有这么激进的缓存策略,或者用了更低效的数据结构,导致大目录下的性能急剧下降。
你可以自己验证一下:
# 创建一个有几万个文件的目录mkdir /tmp/lots_of_filescd /tmp/lots_of_filesfor i in $(seq 1 30000); dotouch"file_${i}.txt"; done# 第一次 ls,需要构建缓存,可能稍慢ls | wc -l# 第二次 ls,直接从缓存读,瞬间完成ls | wc -l第一次 ls 要去磁盘读目录内容,构建 dentry cache。第二次 ls 直接从内存里的哈希表取数据,速度快到飞起。
复杂度
这里有几个坑
哈希冲突导致退化。如果所有文件名哈希到同一个桶,链表变成 O(n) 的线性查找。Linux 通过动态调整桶数量和选择好的哈希函数来避免这种情况。
缓存过期问题。如果 dentry cache 没及时更新(比如硬件故障、网络文件系统延迟),可能返回过期的 inode 号。Linux 通过版本号(d_seq)机制来检测过期条目。
内存占用。dentry cache 存在内存里,目录越多占用越大。Linux 会在内存紧张时自动回收不常用的 dentry 条目,腾出内存给其他用途。
这道题和快递柜的联系
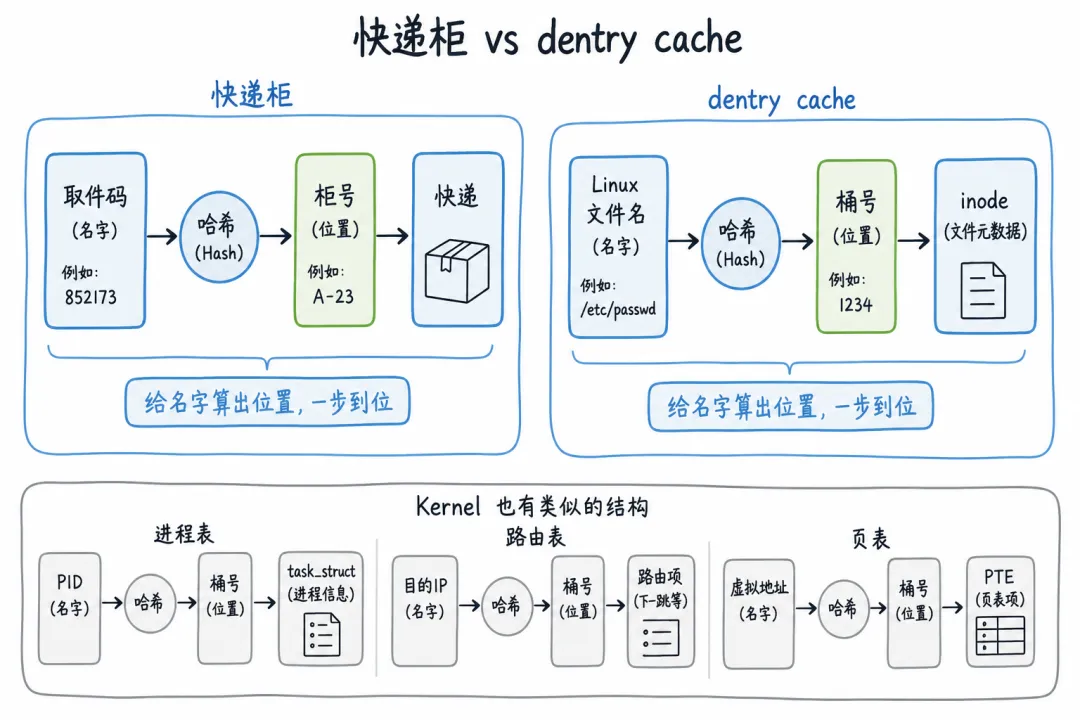
Linux 的 dentry cache 和我们之前聊的快递柜,底层逻辑一模一样:
快递柜:取件码 → 哈希函数 → 柜号 → 取出快递 dentry cache:文件名 → 哈希函数 → 桶号 → 取出 inode
都是"给名字 → 算出位置 → 一步到位取东西"的模式。哈希表的 O(1) 查找,让 Linux 能在几万个文件的目录里瞬间定位到你要的文件。
当你理解了这一点,你就理解了为什么哈希表是操作系统内核里使用最广泛的数据结构之一。进程调度表、路由表、内存页表……背后都有哈希表在默默工作。
总结
ls 的响应速度,Linux vs 其他系统的差异 | |
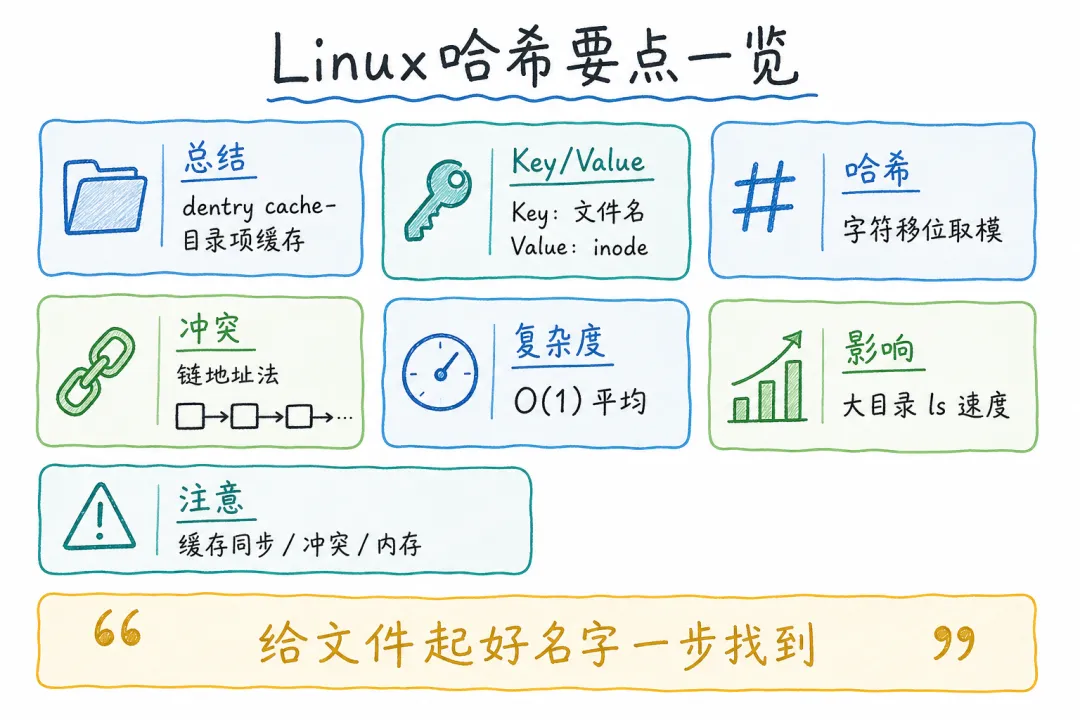
金句:Linux 找文件快如闪电的秘密,藏在每一张哈希表里——给文件起个好名字,系统就能一步找到它。
觉得有收获?转发给你的技术伙伴。
你遇到过打开大目录特别卡的场景吗?是在什么系统上?评论区聊聊。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Oracle 11g RAC集群安装_linux7
- 有了这 5 个自动化运维场景,让你用 Python 写脚本更爽!
- Linux运维必学:tar压缩解压全教程,脚本_数据归档保命方案.docx
- Linux 最新资讯 20260617——Mozilla Firefox 采用 zlib-rs 提升安全性与性能
- Linux BSP开发构建:构建基础的busybox系统
- 在windows中使用Linux命令太舒适了
- 21张让你代码能力突飞猛进Python速查表(神经网络、线性代数、可视化等)(有中文版)
- Python环境到底怎么选?我被venv、conda、uv折磨半年后,终于想明白了
- AI Agent 开发到底该学 Python 还是 TypeScript?很多人一开始就选错了
- 【python3.11.3】python3.11.3setup完整版下载安装,python附激活教程与常见问题解答
