爬虫 | Python自动化批量爬取抖音视频
- 2026-06-30 08:39:12
前言 📌
郑重说明:本爬虫仅限个人学习研究,非商业、非盈利,请合规使用爬虫,否则违规爬取由此产生的一切后果,请自行承担,与本人无关
halo,各位小伙伴~我是亮娃儿👋!
最近世界杯踢得热火朝天,刷抖音总能刷到好多做足球内容的博主,视频剪得那叫一个精彩,想存下来没事就翻出来回味,结果好多视频都不让直接下载。这能难住咱?直接用 Python 把它们爬下来不就完事了!
今天就手把手教大家,用最简单的方法,把抖音博主主页的所有视频一键下载到自己电脑里,全程没什么晦涩术语,新手也能跟着做。
一、数据来源分析 🕵️♂️
1.明确需求 🎯
咱们这次拿网页版抖音练手,就用这个做足球内容的博主主页当例子,大家也可以换成自己喜欢的博主。
目标网址:https://www.douyin.com/user/MS4wLjABAAAAbA5jsJ2taLI5Am2gj_31MkvATTRlZpQ5LdZg1P1Y6co?from_tab_name=main
2.网页抓包分析 🔍
操作就几步,超简单:
1.打开博主主页,按 F12 调出开发者工具,咱们用 谷歌浏览器 演示
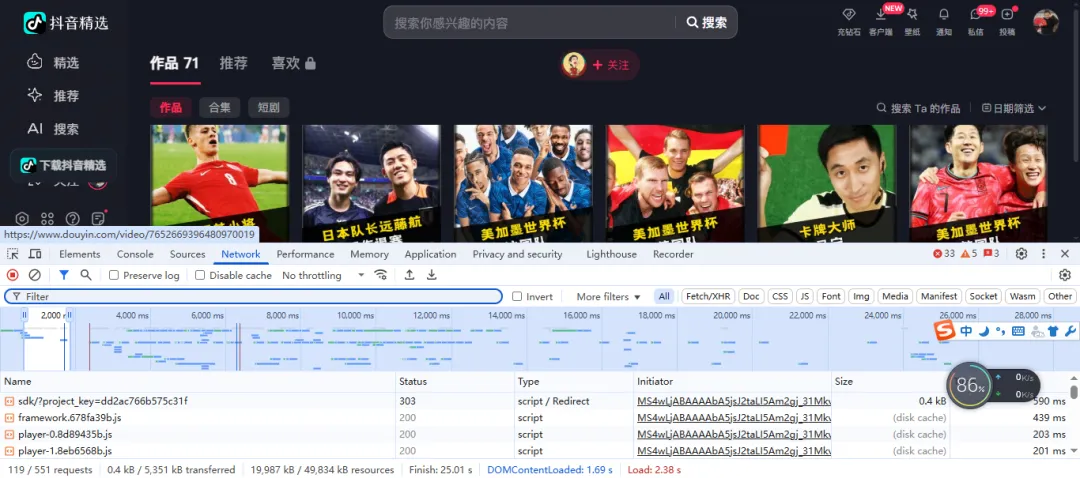
2.按 Ctrl+R 刷新一下页面,让工具记录下所有网络请求
3.在下面的筛选搜索框里输入aweme/post/,搜出来的第一条结果,就是装着所有视频信息的数据包
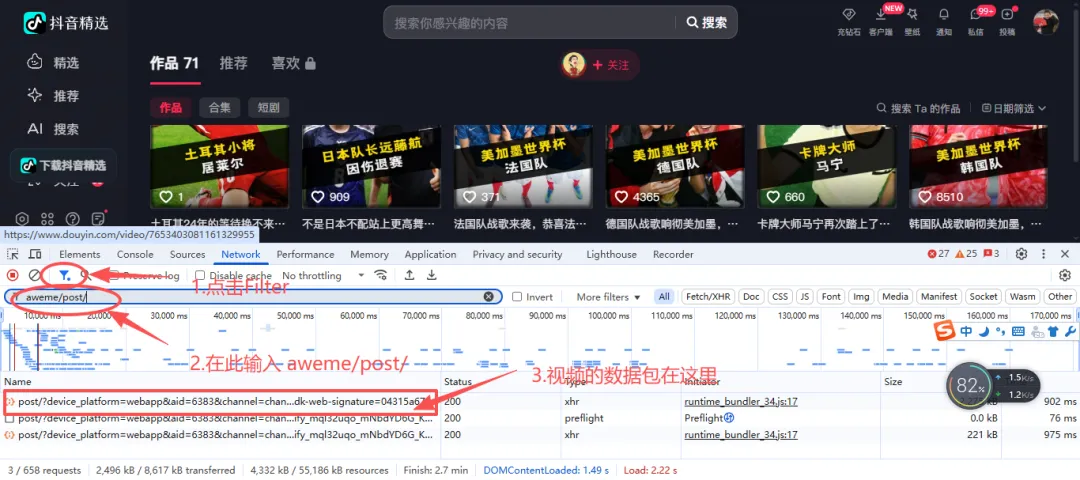
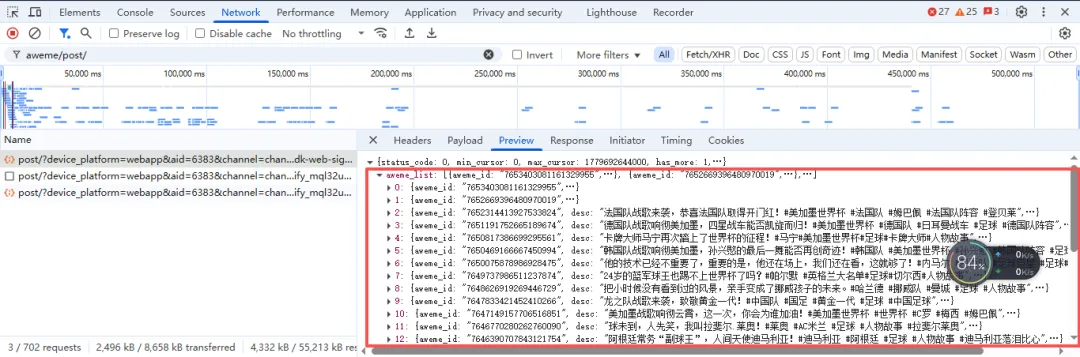
点进去就能看到,咱们需要的视频标题、下载链接,全都在里面 👇
二、代码实现步骤 💻
1.启动浏览器 & 开启监听 🌐
本次使用 DrissionPage 自动化模块,无需复杂配置,语法简洁、适配性强,完美适配静态网页爬取。
# 导入自动化模块from DrissionPage import ChromiumPage# 实例化浏览器对象dp = ChromiumPage()# 监听数据包dp.listen.start('aweme/post/')# 访问网站dp.get('https://www.douyin.com/user/MS4wLjABAAAAbA5jsJ2taLI5Am2gj_31MkvATTRlZpQ5LdZg1P1Y6co?from_tab_name=main')💡 小提示:不熟悉 DrissionPage 模块的小伙伴,可以参考我的往期实战文章:(《用Python抓取《疯狂动物城2》豆瓣影评》)
2.解析数据 & 提取字段 📝
等页面加载出来,数据包就到手了。咱们不用管里面乱七八糟的其他信息,只拿两个最有用的:视频标题 和 视频下载链接。
顺便还要筛一下:有些作品是图文笔记,只有音频没有视频,这种咱们直接跳过,只下载正经的视频文件
# 等待数据包加载,timeout=10 超时处理,超过10S没有加载新的数据(到底) resp = dp.listen.wait(timeout=10) # 获取相应数据内容 json_data = resp.response.body # print(json_data) # 字典取值:提取视频数据所在的列表 video_info_list = json_data['aweme_list'] # for循环,提取列表里的元素for index in video_info_list: # 视频标题 video_id = index['aweme_id'] # 提取标题 title = index['desc'] # 只保留#前面的内容if'#' in title: title = title.split('#')[0].strip() # 提取视频链接 video_url = index['video']['play_addr']['url_list'][0] print(video_id, title, video_url) # 判断视频链接是否为图文的if'.mp3' not in video_url: # 获取视频内容 video_content = requests.get(url=video_url).content # 替换特殊字符 new_title = re.sub(r'[\\/:*?"<>|]', '', title)3.视频保存到本地 💾
视频下载下来之后,咱们统一放到 D 盘的 “抖音” 文件夹 里。代码会自动创建文件夹,不用你手动新建,省心得很。
# 创建保存目录save_dir = 'D:\\抖音\\'if not os.path.exists(save_dir): os.makedirs(save_dir)# 数据保存with open(save_dir + new_title + '.mp4', 'wb') as f:# 写入数据f.write(video_content)print(f'视频下载完成: {new_title}.mp4')4.自动下滑加载更多 ⬇️
抖音主页是往下滑才加载更多视频的,总不能咱们守在电脑前一直用手滑吧?当然让代码自动干!
咱们让页面自动滑到底部,触发加载新的视频,加载出来就接着下载,循环往复,一直到把这个博主发的所有视频都下载完为止。
# 定位底部元素down = dp.ele('css:.CLHB28oG')# 下滑页面直到底部广告投放的元素可见dp.scroll.to_see(down)5.完整整合代码 🚀
# 导入自动化模块from DrissionPage import ChromiumPage# 导入数据请求模块import requests# 导入正则表达式模块import re# 导入文件系统模块import os# 打开浏览器(实例化浏览器对象)dp = ChromiumPage()# 监听数据包dp.listen.start('aweme/post/')# 访问网址dp.get("https://www.douyin.com/user/MS4wLjABAAAAbA5jsJ2taLI5Am2gj_31MkvATTRlZpQ5LdZg1P1Y6co?from_tab_name=main")page = 1# 死循环while True:try: print(f'正在采集第{page}页的数据内容') # 等待数据包加载,timeout=10 超时处理,超过10S没有加载新的数据(到底) resp = dp.listen.wait(timeout=10) # 获取相应数据内容 json_data = resp.response.body # print(json_data) # 字典取值:提取视频数据所在的列表 video_info_list = json_data['aweme_list'] # for循环,提取列表里的元素for index in video_info_list: # 视频标题 video_id = index['aweme_id'] # 提取标题 title = index['desc'] # 只保留#前面的内容if'#' in title: title = title.split('#')[0].strip() # 提取视频链接 video_url = index['video']['play_addr']['url_list'][0] print(video_id, title, video_url) # 判断视频链接是否为图文的if'.mp3' not in video_url: # 获取视频内容 video_content = requests.get(url=video_url).content # 替换特殊字符 new_title = re.sub(r'[\\/:*?"<>|]', '', title) # 创建保存目录 save_dir = 'D:\\抖音\\'if not os.path.exists(save_dir): os.makedirs(save_dir) # 数据保存with open(save_dir + new_title + '.mp4', 'wb') as f: # 写入数据 f.write(video_content)print(f'视频下载完成: {new_title}.mp4') # 定位底部元素 down = dp.ele('css:.CLHB28oG') # 下滑页面直到底部广告投放的元素可见 dp.scroll.to_see(down) page += 1 except Exception as e: print(str(e))ifstr(e)== "'bool' object has no attribute 'response'": exit()📊 运行效果展示
程序跑完之后,你打开 D 盘的 “抖音” 文件夹,这个博主发的所有视频就都下载好了,文件名就是视频标题,直接双击就能打开看。
给大家看一眼我下载好的效果:
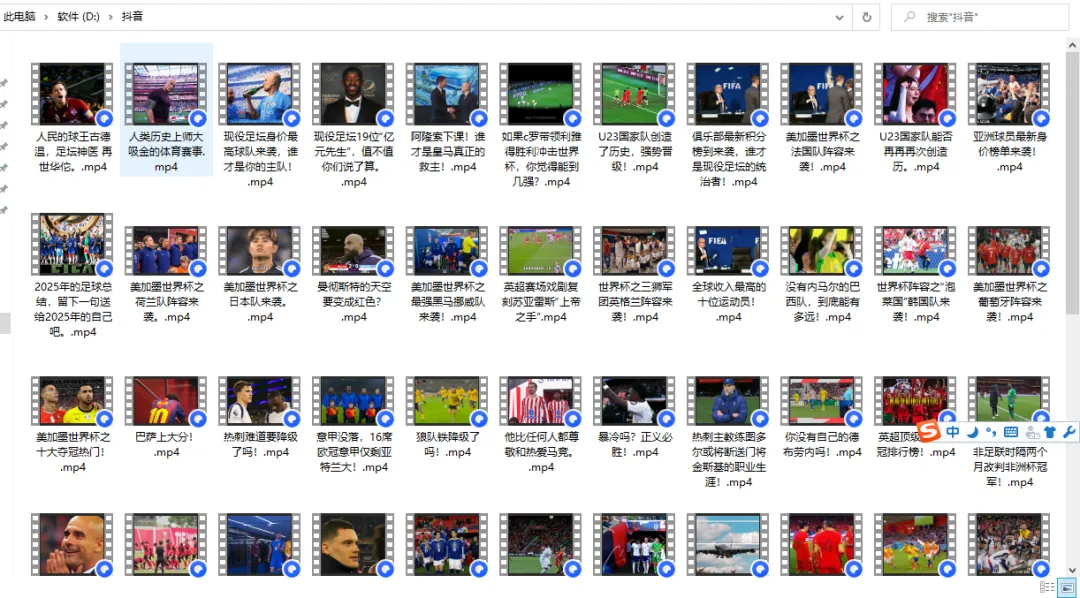
实测效果:
数据&完整代码获取方式 🎁
关注公众号,后台留言我,即可获取相关代码,我的微信:shangliang87
历史推荐 📚
✅ - 《夜神模拟器自动化爬取抖音用户信息数据实战:uiautomator2+Fiddler+Mitmproxy完美组合》
✅ - 《Python自动化爬虫|批量采集链家二手房数据(含验证码破解+多页采集)》
✅ - 《Pandas+Pyecharts | 成都成华区二手房数据分析可视化)》
交流群 💬
QQ:892186377,随时互动、提建议。另有交流群(内含资料),欢迎加入!

未完待续,欢迎关注!🥰动动您发财的小手点个赞吧 👍 !欢迎转发!🔁
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 《Python 从入门到精通》090|模块与标准库实战:写出更像“正式项目”的代码
- 进了python的大门 ,我已经无心工作
- 为什么我把日常桌面换成Alpine Linux?
- Python 潮流周刊#155:Python 3.14 垃圾回收风波
- Java/Go/Python/前端/云原生/算法,算力赛道薪资翻倍指南
- Linux 基础实战课 ⑥装完了 Nginx,怎么把它跑起来
- 计算机网络超级实用的20个Linux脚本!
- tar 不是压缩工具:一篇讲透 Linux 归档与压缩的设计哲学
- linux 调度器全景图:从 CPU 占用率说起--基于kernel6.19
- Linux通知链
