Python:AI 写代码时代,为什么还要懂一点?
- 2026-06-30 07:58:15
👇 连享会 · 推文导航 |www.lianxh.cn
距离开课还有5天,近期的不同专题一起报名可优惠
🍓 连享会 · 2026 AI 实证研究
嘉宾:司继春(上海对外经贸大学)
时间:2026 年 6 月 27-28 日
咨询:王老师 18903405450(微信)

连享会:2026暑期班 · 线上
时间:7月21-31日
嘉宾:连玉君(初级班) || 茅家铭(高级班) || 范馨月(论文班)
咨询:王老师 18903405450(微信)


作者: 刘悦 (兰州财经大学)
邮箱:joy_liuyue@163.com[1]
• Title: Python:AI 写代码时代,为什么还要懂一点? • Keywords: Python, AI 编程, Stata, R, Pandas, NumPy, Matplotlib, Jupyter Notebook, 数据科学, 实证研究, QuantEcon
🍎 系列推文:AI 写代码时代,为什么还要懂一点?[2]
编者按: 现在学 Python,和几年前已经不一样了。过去我们学 Python,往往是为了从零开始写代码;现在有了 ChatGPT、Claude、Kimi、DeepSeek、Copilot 等工具,很多代码都可以由 AI 生成。问题是:AI 会写代码,并不意味着研究者可以完全不懂代码。相反,懂一点 Python 基础,反而更重要。因为我们需要把 AI 生成的代码跑起来、改得动、看得懂,也需要判断它写得是不是太慢、太长、太旧,甚至是错的。本文不是一份要求读者背诵的 Python 教程,而是一份面向 AI 协作场景的 Python 速查手册。写作过程中,主要参考了 Thomas J. Sargent 等学者推动建设的 QuantEcon 开源材料,并结合经管社科研究中的数据处理、绘图和代码审查场景重新整理。
参考资料:
• Python cheatsheet[3] • Statistics cheatsheet[4] • Python Programming for Economics and Finance[5]
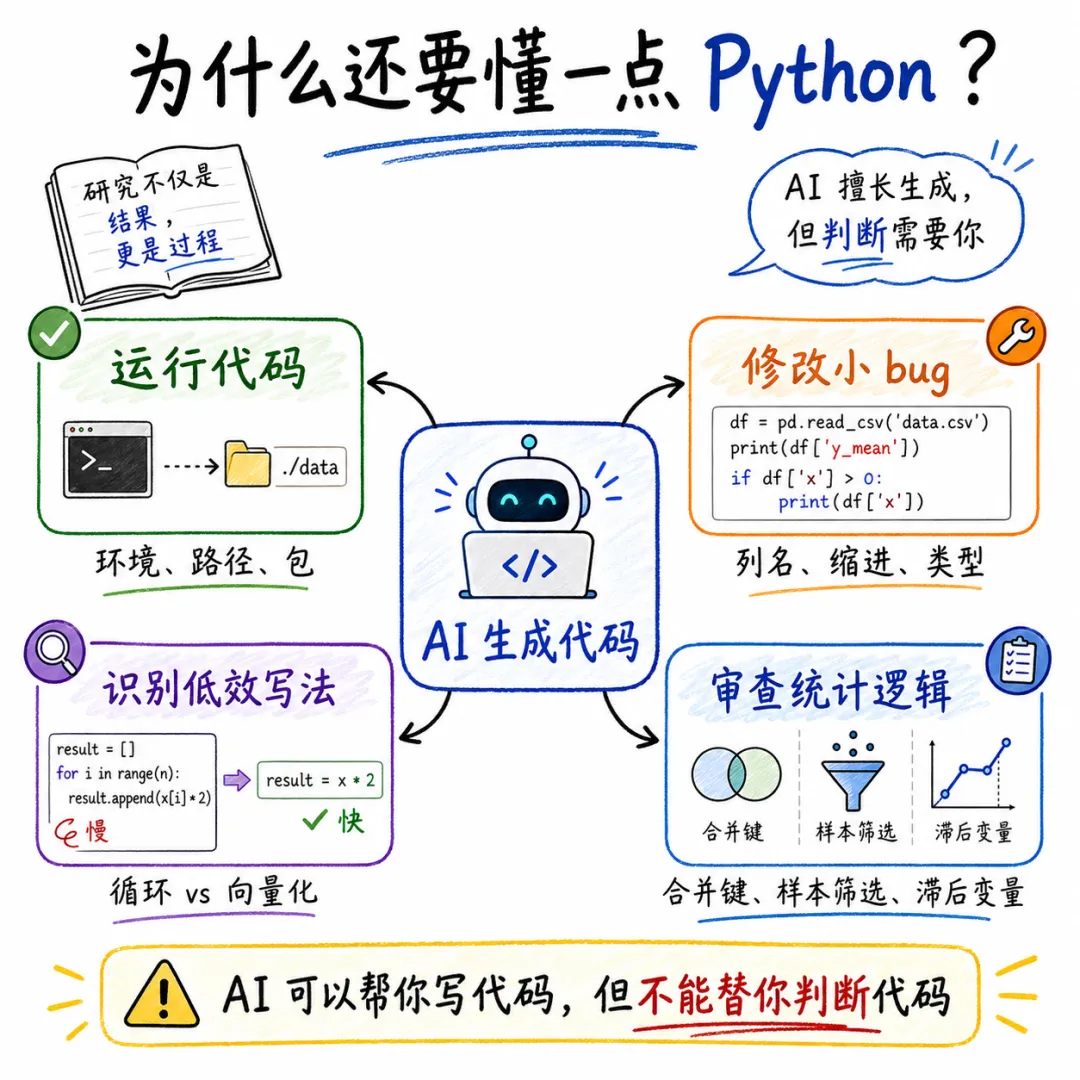
1. AI 写代码之后,研究者还需要判断代码
很多经管社科研究者已经熟悉 Stata 或 R。也有不少读者完全没有编程基础,但现在可以让 AI 生成代码。于是一个自然的问题出现了:既然 AI 可以写 Python,我为什么还要学 Python?
简单的回答是:学 Python 基础,不是为了和 AI 比谁写代码更快,而是为了不把判断权完全交给 AI。
现在的学习方式已经发生变化。过去我们可能要从变量、循环、函数一步一步学起,写很多小练习,才能慢慢进入数据分析。现在,AI 可以很快生成一整段 Python 代码,帮我们读取数据、清洗变量、画图,甚至跑回归。很多时候,研究者真正要掌握的,不是从零手写每一行代码,而是下面四种能力:
• 能把 AI 生成的代码安装好、跑起来; • 能修改路径、变量名、筛选条件和图形参数; • 能看懂常见报错,自己修掉小 bug; • 能判断 AI 代码是否低效、过时,或存在统计逻辑问题。
这就是本文存在的理由。
如果你一点 Python 基础都没有,那么遇到最普通的问题也要反复问 AI。例如,文件路径写错、变量名拼错、DataFrame 里没有某一列、括号没有配对、缩进不一致、字符串和数字混在一起运算。这些问题本身并不难,但如果每次都要把报错复制给 AI,再解释你的数据结构和分析目标,沟通成本会很高。
更麻烦的是,AI 生成代码时经常倾向于使用最基础的写法。它可能用几十行 for 循环完成一个 Pandas 一行即可解决的任务,也可能手写一个低效函数,而不是调用 NumPy、Pandas、statsmodels、scikit-learn 或其他成熟 package。代码能跑,不代表代码好;结果能出来,也不代表处理过程可靠。
还有一种情况更危险:AI 生成的代码本身就错了。它可能把合并键写错,把面板数据排序漏掉,把缺失值处理得过于粗糙,把字符串变量当成数值变量,或者把回归设定写成了另一个模型。此时,如果研究者完全不懂 Python,就很难审查代码,只能被动相信 AI。
因此,AI 时代学 Python,目标不必设得过高。你不一定要成为职业程序员,也不必从一开始就掌握复杂的软件工程知识。对于多数经管社科研究者而言,比较现实的目标是:
能运行代码,能读懂基本结构,能改小错误,能发现明显不合理的写法,并知道什么时候该让 AI 改用更合适的函数或 package。
这篇速查手册就是为这个目标服务的。
2. 先跑起来:环境配置和 Notebook
学习 Python 的第一步不是理解所有语法,而是确认你能运行代码。能运行,后面才谈得上修改、调试和审查。
对初学者而言,比较省事的方式是安装 Anaconda。安装完成后,可以先从 Jupyter Notebook 或 JupyterLab 开始。后续熟悉以后,再根据需要切换到 VS Code、Miniconda、uv 或其他环境管理工具。
打开 Jupyter Notebook 后,先运行下面这段代码:
# 导入 NumPy 和 Matplotlib
# NumPy 用来生成随机数,Matplotlib 用来画图
import numpy as np
import matplotlib.pyplot as plt
# 创建随机数生成器
rng = np.random.default_rng()
# 生成 100 个标准正态随机数
data = rng.standard_normal(100)
# 画出随机数序列
plt.plot(data)
# 显示图形
plt.show()如果你看到一条上下波动的曲线,说明三件事已经完成:
• Python 能运行; • 常用包能导入; • 图形能正常显示。
这比一开始背语法更重要。因为后续无论是让 AI 生成代码,还是从 GitHub 仓库复制代码,你都要先能把它跑起来。
需要说明的是,很多 Python 报错并不是模型错了,而是环境、路径或 package 没有配置好。比如:
• 没有安装某个包; • 当前 Notebook 使用的不是你以为的 Python 环境; • 数据文件不在当前工作目录; • Windows 路径里的反斜杠没有正确处理; • 文件名中有中文、空格或特殊符号。
这些问题都很常见。解决它们的第一步,是能运行一个最小示例。上面这段代码就可以作为你的环境检测代码。
3. 读懂 AI 代码:Python 基础语法
很多 Python 教程会从完整语法体系讲起。但在 AI 协作场景中,我们更关心另一件事:哪些语法最常出现在 AI 生成的代码里?哪些语法最影响我们修改代码?
从这个角度看,下面几类内容最值得优先掌握。
3.1 变量:改参数、路径和列名的基础
Python 用 = 赋值。例如:
# 设置样本年份
start_year = 2000
end_year = 2020
# 设置文件路径
data_path = "data/raw/firm_panel.csv"
# 设置变量名
outcome_var = "roa"
treat_var = "treated"这些变量看起来简单,但在实证研究中非常重要。好的代码通常会把路径、年份、变量名、参数集中放在前面。这样修改代码时,不需要在几百行脚本里到处搜索。
不建议把参数写死在代码中。例如:
# 不建议的写法:参数散落在代码里
df = df[(df["year"] >= 2000) & (df["year"] <= 2020)]
df["y"] = df["roa"]较好的写法是:
# 较好的写法:把参数集中放在前面
start_year = 2000
end_year = 2020
outcome_var = "roa"
df = df[(df["year"] >= start_year) & (df["year"] <= end_year)]
df["y"] = df[outcome_var]这样做的好处是,后续改样本区间或替换因变量时,只需要改前面的参数。让 AI 修改代码时,也更容易说清楚:“请把样本区间改为 2005-2018,把因变量改为 tobin_q。”
3.2 数据类型:很多 bug 来自类型不一致
Python 常见的基础类型包括:
int | year = 2020 | |
float | roa = 0.123 | |
str | firm = "A001" | |
bool | treated = True | |
NoneType | x = None |
可以用 type() 查看变量类型:
year = 2020
firm = "A001"
print(type(year))
print(type(firm))很多小 bug 都是类型问题。例如,下面的代码会报错:
x = "5"
y = 1
print(x + y)原因是 "5" 是字符串,1 是整数,不能直接相加。需要先转换:
x = "5"
y = 1
x = int(x)
print(x + y)在处理数据时,类型问题更常见。例如,年份变量看起来是数字,但读入后可能是字符串;企业代码看起来是数字,但其实应该保留为字符串,否则前导零会丢失。
因此,读入数据后要经常检查:
# 查看每一列的数据类型
print(df.dtypes)
# 查看数据概况
print(df.info())如果 AI 写的代码跑不通,第一件事不要急着改模型,而要先看变量类型。
3.3 列表、字典和集合:理解代码结构的基本容器
Python 中最常见的内置数据结构有四类:
list | ["roa", "size", "lev"] | |
tuple | (2000, 2020) | |
dict | {"roa": "资产收益率"} | |
set | {"A", "B", "C"} |
列表最常用。例如,我们可以把控制变量放在一个列表中:
controls = ["size", "lev", "age", "growth"]
print(controls[0])
print(controls[-1])后续写回归公式时,就可以复用这个列表:
control_str = " + ".join(controls)
formula = f"roa ~ treated + {control_str}"
print(formula)字典也很常用,尤其适合存变量标签:
var_labels = {
"roa": "资产收益率",
"size": "企业规模",
"lev": "资产负债率"
}
print(var_labels["roa"])如果 AI 生成的代码里出现 {},你需要判断它是字典还是集合。字典有键值对,集合只有元素:
# 字典:键值对
label_map = {"roa": "资产收益率", "lev": "资产负债率"}
# 集合:只有元素
firm_set = {"A001", "A002", "A003"}这些结构并不复杂,但它们是读懂 AI 代码的基础。AI 很喜欢用列表保存变量名,用字典保存参数,用集合做去重和匹配。完全不懂这些结构,就很难判断代码在做什么。
3.4 条件筛选:样本选择的代码表达
实证研究中经常需要筛选样本。Python 基础语法中的条件判断,与 Pandas 中的样本筛选密切相关。
普通条件判断如下:
x = -5
if x < 0:
print("负数")
elif x == 0:
print("零")
else:
print("正数")在 Pandas 中,条件筛选更常见。例如:
# 保留 2000-2020 年样本
df = df[(df["year"] >= 2000) & (df["year"] <= 2020)]
# 保留非缺失样本
df = df[df["roa"].notna()]
# 保留制造业企业
df = df[df["industry"] == "制造业"]这里有一个新手经常出错的地方:Pandas 中多个条件连接时,要用 & 和 |,而不是 Python 的 and 和 or。每个条件还要加括号。
# 正确写法
df = df[(df["year"] >= 2000) & (df["year"] <= 2020)]
# 不建议写法:在 Pandas 条件筛选中容易报错
df = df[df["year"] >= 2000 and df["year"] <= 2020]如果你会 Stata,可以这样对应理解:
keep if year >= 2000 & year <= 2020 | df = df[(df["year"] >= 2000) & (df["year"] <= 2020)] | |
drop if missing(roa) | df = df[df["roa"].notna()] | |
keep if industry == "制造业" | df = df[df["industry"] == "制造业"] |
这类语法值得熟悉。因为 AI 最容易在样本筛选处写错逻辑,而样本筛选一旦错了,后面的回归结果再漂亮也没有意义。
3.5 函数:减少复制粘贴,也方便 AI 修改
函数是把一段可重复使用的逻辑封装起来。定义函数用 def,返回结果用 return。
def winsorize_series(s, lower=0.01, upper=0.99):
"""
对一个 Series 做缩尾处理。
参数:
s: 需要处理的变量
lower: 下分位点
upper: 上分位点
"""
q_low = s.quantile(lower)
q_high = s.quantile(upper)
return s.clip(q_low, q_high)使用时:
df["roa_w"] = winsorize_series(df["roa"])为什么函数重要?因为 AI 很容易重复生成大量相似代码。例如,对 10 个变量分别缩尾,它可能写成:
df["roa_w"] = df["roa"].clip(df["roa"].quantile(0.01), df["roa"].quantile(0.99))
df["lev_w"] = df["lev"].clip(df["lev"].quantile(0.01), df["lev"].quantile(0.99))
df["size_w"] = df["size"].clip(df["size"].quantile(0.01), df["size"].quantile(0.99))这段代码能跑,但不容易维护。更好的做法是:
vars_to_winsor = ["roa", "lev", "size"]
for var in vars_to_winsor:
df[f"{var}_w"] = winsorize_series(df[var])一旦你理解函数和循环,就可以要求 AI 把重复代码改短:
请把下面重复的缩尾代码封装成一个函数,并用变量列表循环执行。
这种沟通方式比“帮我优化代码”更具体,AI 的输出也更可靠。
4. 不让 AI 写笨代码:NumPy、Pandas 与 Matplotlib
上一节的目标是读懂 AI 代码,本节的目标是判断 AI 代码是否写得过长、过慢或不适合实证研究。经管社科研究中最常用的 Python 数据科学栈,主要是 NumPy、Pandas 和 Matplotlib。其中,NumPy 负责数组和矩阵运算,Pandas 负责表格数据处理,Matplotlib 负责图形输出。
4.1 NumPy:别让 AI 用长循环做数组运算
NumPy 是 Python 科学计算的基础。它的核心对象是 ndarray,可以理解为定长、同质的数组。对经管社科研究者而言,NumPy 最常见的用途包括:
• 生成随机数; • 做矩阵运算; • 做蒙特卡洛模拟; • 做向量化计算; • 为机器学习和数值优化提供底层数据结构。
AI 生成代码时,如果大量使用手写循环处理数值数组,就要警惕是否可以改成 NumPy 向量化。
A. 创建数组
创建数组的基本写法如下:
import numpy as np
# 从列表创建数组
x = np.array([1, 2, 3, 4])
# 创建全零数组和全一数组
a = np.zeros(5)
b = np.ones((2, 3))
# 创建等间距网格
grid = np.linspace(0, 1, 11)
# 创建单位矩阵
I = np.eye(3)
print(x)
print(grid)
print(I)常用创建函数如下:
np.array() | |
np.zeros() | |
np.ones() | |
np.linspace() | |
np.eye() | |
np.diag() |
B. 向量化:少写循环,代码更快
比较下面两种写法。第一种是循环写法:
import numpy as np
n = 1_000_000
x = np.random.randn(n)
y = np.random.randn(n)
z = np.empty(n)
for i in range(n):
z[i] = x[i] + y[i]第二种是向量化写法:
z = x + y两者都能得到结果,但第二种更短、更快,也更不容易写错。NumPy 的核心优势就在这里:尽量让底层高效代码完成逐元素运算,而不是让 Python 解释器一行一行执行循环。
常见向量化运算包括:
x = np.array([1, 2, 3, 4])
y = np.array([5, 6, 7, 8])
print(x + y) # 逐元素加法
print(x * y) # 逐元素乘法
print(x @ y) # 点积
print(np.log(x)) # 逐元素取对数
print(np.sqrt(x)) # 逐元素开方需要说明的是,* 是逐元素乘法,不是矩阵乘法。矩阵乘法使用 @ 或 np.dot()。
A = np.array([[1, 2],
[3, 4]])
B = np.array([[2, 0],
[1, 3]])
print(A * B) # 逐元素相乘
print(A @ B) # 矩阵乘法C. 随机数与模拟
很多实证方法教学都会用到模拟。NumPy 可以很方便地生成随机数:
rng = np.random.default_rng()
normal = rng.standard_normal(1000)
uniform = rng.uniform(0, 1, size=1000)
binom = rng.binomial(n=1, p=0.5, size=1000)
print(normal.mean())
print(uniform.mean())
print(binom.mean())用蒙特卡洛方法估算圆周率:
import numpy as np
n = 1_000_000
rng = np.random.default_rng()
# 在单位正方形中随机生成点
u = rng.uniform(size=n)
v = rng.uniform(size=n)
# 判断点是否落入四分之一单位圆
inside = (u**2 + v**2) <= 1
# 面积比例乘以 4,得到 pi 的估计
pi_hat = 4 * inside.mean()
print(pi_hat)这个例子说明,Python 中很多模拟任务都可以写得很短。让 AI 写模拟代码时,可以提醒它:
请尽量使用 NumPy 向量化,不要写逐点循环。
这句话通常能明显改善代码质量。
D. 线性代数:优先用成熟函数
NumPy 也提供线性代数工具:
A = np.array([[1, 2],
[3, 4]])
b = np.array([5, 6])
# 解线性方程组 Ax = b
x = np.linalg.solve(A, b)
print(x)
print(A @ x)很多初学者会写:
x = np.linalg.inv(A) @ b但在数值计算中,直接使用 np.linalg.solve(A, b) 通常更稳,也更清楚。这个例子也说明一个原则:知道成熟函数的存在,比自己手写算法更重要。
如果 AI 手写了矩阵求逆、特征值分解、最小二乘求解过程,通常应该要求它改用成熟函数,除非你的目的就是教学演示。
4.2 Pandas:经管社科研究者最需要掌握的一层
如果只能在 Python 数据科学栈中优先学一个库,经管社科研究者应优先学 Pandas。原因很简单:我们的多数数据都是表格数据。企业-年份面板、城市-年份面板、个体调查数据、基金持仓数据、上市公司财务数据,本质上都是二维表。
Pandas 的核心对象是 DataFrame。可以把它理解为内存中的一张数据表,接近 Stata 当前打开的数据集。
import pandas as pd
df = pd.read_csv("data/firm_panel.csv")
print(df.head())
print(df.info())
print(df.describe())A. 从 Stata 到 Pandas
熟悉 Stata 的读者,可以先建立如下对应关系:
list in 1/5 | df.head() | |
summarize | df.describe() | |
describe | df.info() | |
gen z = x + y | df["z"] = df["x"] + df["y"] | |
drop x | df = df.drop(columns=["x"]) | |
rename old new | df = df.rename(columns={"old": "new"}) | |
sort firm year | df = df.sort_values(["firm", "year"]) | |
keep if x > 0 | df = df[df["x"] > 0] | |
bysort g: summarize x | df.groupby("g")["x"].mean() | |
merge | pd.merge() | |
append | pd.concat() | |
use auto.dta, clear | pd.read_stata("auto.dta") | |
save auto.dta, replace | df.to_stata("auto.dta") |
有了这个对照表,Pandas 就不再是一套陌生语法,而是另一种表格数据处理语言。
B. 读入、浏览和保存数据
常见数据读入方式如下:
# 读取 CSV 文件
df = pd.read_csv("data/raw/firm_panel.csv")
# 读取 Excel 文件
df_excel = pd.read_excel("data/raw/firm_panel.xlsx")
# 读取 Stata 数据
df_stata = pd.read_stata("data/raw/firm_panel.dta")保存数据:
# 保存为 CSV
df.to_csv("data/processed/firm_panel_clean.csv", index=False)
# 保存为 Stata 数据
df.to_stata("data/processed/firm_panel_clean.dta", write_index=False)读入数据后,建议先做三件事:
# 看前几行
print(df.head())
# 看变量类型和缺失情况
print(df.info())
# 看数值变量的描述统计
print(df.describe())这三行代码非常重要。很多 AI 代码出错,并不是因为模型复杂,而是因为它没有正确理解数据结构。把 df.head()、df.info() 和 df.describe() 的结果发给 AI,通常能显著提高后续代码质量。
C. 选列、筛行和生成变量
选取一列:
roa = df["roa"]选取多列:
sub = df[["firm_id", "year", "roa", "size", "lev"]]条件筛选:
# 保留 2000 年及以后的样本
df = df[df["year"] >= 2000]
# 保留 roa 非缺失样本
df = df[df["roa"].notna()]
# 保留制造业企业
df = df[df["industry"] == "制造业"]多条件筛选:
df = df[
(df["year"] >= 2000) &
(df["year"] <= 2020) &
(df["roa"].notna())
]生成新变量:
# 资产负债率
df["lev"] = df["total_liability"] / df["total_asset"]
# 企业规模
df["size"] = np.log(df["total_asset"])
# 是否为政策后
df["post"] = (df["year"] >= 2015).astype(int)这里的 .astype(int) 会把 True 和 False 转为 1 和 0。这在构造处理变量、政策后变量时很常用。
D. 分组统计:groupby() 是核心工具
Stata 用户常用 bysort。在 Pandas 中,类似功能主要由 groupby() 完成。例如,按年份计算平均资产收益率:
year_mean = df.groupby("year")["roa"].mean()
print(year_mean)按行业和年份计算均值、标准差和样本量:
summary = (
df.groupby(["industry", "year"])["roa"]
.agg(["mean", "std", "count"])
.reset_index()
)
print(summary.head())这里的链式写法值得熟悉。它的含义是:
• 先按 industry和year分组;• 再对 roa做统计;• 计算均值、标准差和样本量; • 最后把分组索引恢复为普通列。
如果 AI 用很多循环逐个行业、逐个年份计算统计量,可以要求它改用 groupby()。
E. 数据合并:实证研究中最容易出错的地方
很多实证研究的问题,最后都会落到数据合并上。政策数据、企业数据、城市数据、行业数据、文本变量、专利数据、财务数据,往往来自不同来源。合并键写错,后面所有结果都会出问题。
Pandas 中横向合并使用 pd.merge():
df_main = pd.read_csv("data/firm_panel.csv")
df_policy = pd.read_csv("data/policy_city_year.csv")
df = pd.merge(
df_main,
df_policy,
on=["city", "year"],
how="left"
)这里:
• on=["city", "year"]表示按城市和年份合并;• how="left"表示保留主表中的所有观测;• 如果合并键类型不一致,例如一个是字符串、一个是整数,会导致匹配失败。
合并后要检查:
# 查看合并后数据规模
print(df.shape)
# 检查政策变量缺失情况
print(df["policy"].isna().mean())
# 检查合并键是否重复
print(df.duplicated(["firm_id", "year"]).sum())Stata 用户习惯看 _merge。Pandas 中也可以用 indicator=True 生成合并状态:
df = pd.merge(
df_main,
df_policy,
on=["city", "year"],
how="left",
indicator=True
)
print(df["_merge"].value_counts())如果你让 AI 写合并代码,建议明确告诉它:
合并后请检查样本量、合并状态、合并键重复值,以及核心变量缺失比例。
这比只说“帮我合并数据”可靠得多。
F. 宽表和长表:面板数据常见重塑
宽表中,一个年份或一个变量可能占一列;长表中,每一行通常对应一个观测单位和一个时间。面板数据分析通常需要长表。
Pandas 中可以用 melt() 将宽表转成长表:
wide = pd.DataFrame({
"firm_id": ["A", "B"],
"roa_2020": [0.10, 0.08],
"roa_2021": [0.12, 0.09]
})
long = wide.melt(
id_vars="firm_id",
var_name="year",
value_name="roa"
)
print(long)得到的 year 列中会是 roa_2020、roa_2021。可以继续清理:
long["year"] = long["year"].str.replace("roa_", "").astype(int)如果是从长表转宽表,可以使用 pivot():
wide_again = long.pivot(
index="firm_id",
columns="year",
values="roa"
)
print(wide_again)数据重塑是 AI 容易写错的地方。因为它需要理解变量名中的年份、指标和观测单位。如果你提供的数据列名不清楚,AI 经常会猜错。因此,重塑前最好先给 AI 看:
print(df.columns.tolist())
print(df.head())4.3 Matplotlib:科研绘图要清晰传达信息
Matplotlib 是 Python 中最基础、最常用的绘图库。Pandas 也可以直接绘图,但如果图形要放进论文、讲义或推文,建议使用 Matplotlib 的面向对象写法:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(df_year["year"], df_year["roa"], linewidth=2)
ax.set_xlabel("Year")
ax.set_ylabel("Mean ROA")
ax.set_title("Average ROA over Time")
fig.savefig("figures/mean_roa_by_year.png", dpi=300, bbox_inches="tight")
plt.show()这段代码体现了一个稳定模板:
• fig, ax = plt.subplots()创建画布和坐标轴;• ax.plot()画线;• ax.set_xlabel()和ax.set_ylabel()设置坐标轴标题;• ax.set_title()设置图标题;• fig.savefig()保存图形。
如果要画散点图:
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(df["size"], df["roa"], alpha=0.5)
ax.set_xlabel("Firm size")
ax.set_ylabel("ROA")
ax.set_title("Firm size and profitability")
fig.savefig("figures/size_roa_scatter.png", dpi=300, bbox_inches="tight")
plt.show()如果要画分组趋势图:
fig, ax = plt.subplots(figsize=(8, 5))
for treated, group in df.groupby("treated"):
trend = group.groupby("year")["roa"].mean()
ax.plot(trend.index, trend.values, label=f"treated = {treated}")
ax.set_xlabel("Year")
ax.set_ylabel("Mean ROA")
ax.set_title("Trends by treatment status")
ax.legend(frameon=False)
fig.savefig("figures/trends_by_treatment.png", dpi=300, bbox_inches="tight")
plt.show()科研绘图的目标不是炫技,而是表达清楚。对多数实证研究而言,一张图至少要做到:
• 横轴、纵轴含义清楚; • 分组图例清楚; • 图形能保存为高分辨率文件; • 代码可重复运行; • 数据筛选和统计口径可追踪。
如果 AI 给你生成一张图,但没有保存代码、没有说明样本、没有说明变量定义,这张图就不适合直接用于论文或推文。
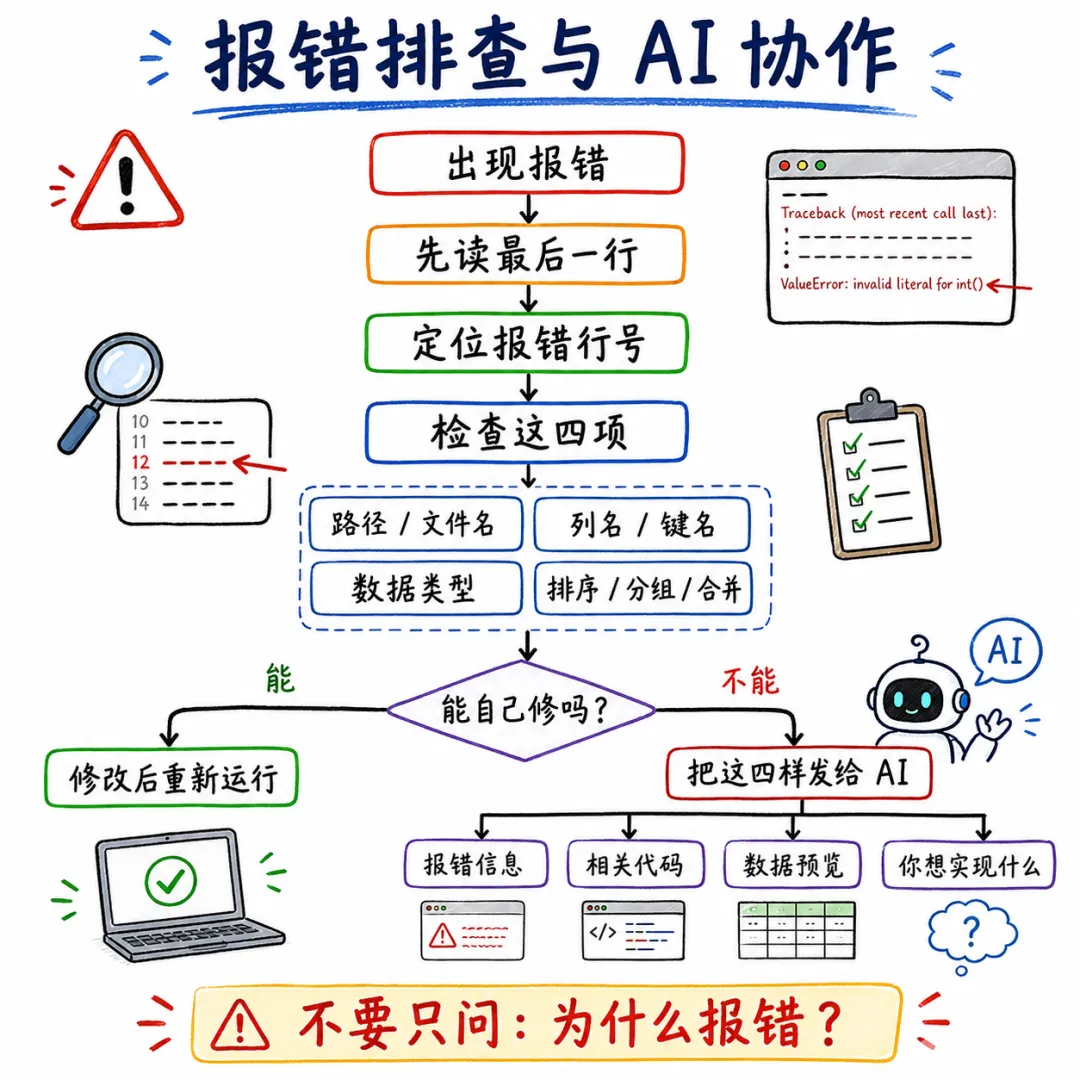
5. 报错排查:先读最后一行,再问 AI
很多人一看到 Python 报错就紧张。其实报错信息通常已经告诉你问题在哪里,只是它看起来很长。
Python 报错一般叫 Traceback。读报错时,不要从第一行开始读,而要从最后一行往前看。最后一行通常包含错误类型和具体描述。
5.1 常见错误类型
常见错误如下:
SyntaxError | ||
NameError | ||
TypeError | ||
IndexError | ||
KeyError | ||
ValueError | ||
IndentationError | ||
FileNotFoundError | ||
AttributeError |
5.2 KeyError: DataFrame 中没有这列
例如:
df["ROA"]报错:
KeyError: 'ROA'这通常说明 df 中没有名为 ROA 的列。可能真实列名是 roa、Roa、return_on_assets,也可能有隐藏空格。
检查列名:
print(df.columns.tolist())如果列名有空格,可以先清理:
df.columns = df.columns.str.strip()5.3 FileNotFoundError: 文件路径错误
例如:
df = pd.read_csv("firm_panel.csv")报错:
FileNotFoundError: [Errno 2] No such file or directory: 'firm_panel.csv'这说明 Python 在当前工作目录中没有找到这个文件。可以检查当前工作目录:
import os
print(os.getcwd())
print(os.listdir())如果文件在 data/raw/ 文件夹中,要写完整相对路径:
df = pd.read_csv("data/raw/firm_panel.csv")Windows 用户还要注意反斜杠问题。建议使用正斜杠:
df = pd.read_csv("D:/project/data/raw/firm_panel.csv")或者使用原始字符串:
df = pd.read_csv(r"D:\project\data\raw\firm_panel.csv")5.4 TypeError: 类型不匹配
例如:
df["year"] + 1如果 year 是字符串,可能出现类型错误。检查类型:
print(df["year"].dtype)转换为整数:
df["year"] = df["year"].astype(int)但转换前要确认没有异常值。例如:
print(df["year"].unique()[:20])如果里面有 "unknown"、"缺失" 或空字符串,直接转整数会失败。需要先清理。
5.5 问 AI 之前,先准备四类信息
遇到报错时,直接问“为什么报错”通常效果不好。更好的做法是把问题描述完整:
• 报错信息最后 10-20 行; • 出错代码块; • df.head()或相关数据结构;• 你本来希望代码完成什么任务。
可以这样问 AI:
下面这段 Pandas 代码想按 city-year 合并两张表,但出现 KeyError。
请帮我判断是合并键名称、变量类型,还是数据结构的问题。
请给出最小修改方案,不要重写整段代码。
[粘贴代码]
[粘贴报错最后 10-20 行]
[粘贴 df_main.head() 和 df_policy.head()]这种提问方式比“帮我 debug”更有效。因为它给了 AI 必要上下文,也限制了 AI 不要随意重写整段代码。
6. 审查 AI 代码:能运行不等于可信
使用 AI 写代码时,很多人容易陷入一种误区:只要代码能跑,就认为问题解决了。事实上,实证研究中的代码至少要过三关:
• 能否运行; • 逻辑是否正确; • 写法是否适合后续复现和修改。
下面列出几个常见场景。
6.1 AI 写了很长的循环
如果 AI 写了很多逐行循环,先判断是否可以用 Pandas 或 NumPy 改写。
例如,AI 可能生成:
df["post"] = 0
for i in range(len(df)):
if df.loc[i, "year"] >= 2015:
df.loc[i, "post"] = 1这段代码可以改成:
df["post"] = (df["year"] >= 2015).astype(int)如果处理的是百万级数据,第二种写法通常更快,也更不容易出错。
你可以直接要求 AI:
请把这段逐行循环改为 Pandas 向量化写法,并解释改写后的每一行。6.2 AI 手写了成熟 package 已经提供的功能
如果要跑 OLS,AI 有时会手写矩阵公式:
beta_hat = np.linalg.inv(X.T @ X) @ X.T @ y这对教学有用,但在实际研究中不一定合适。更稳妥的做法是使用 statsmodels:
import statsmodels.formula.api as smf
model = smf.ols(
formula="roa ~ treated + size + lev + C(year) + C(industry)",
data=df
).fit(cov_type="HC1")
print(model.summary())如果要做机器学习分类或回归,也不建议让 AI 从零手写算法。可以优先考虑 scikit-learn。如果要做数值优化,可以先看 SciPy。如果要处理较大数据,可以了解 polars、数据库或分块读取,而不是盲目让 AI 生成长循环。
6.3 AI 忽略了排序和分组
面板数据和时间序列数据中,排序很重要。比如计算滞后变量时,如果没有按企业和年份排序,结果可能完全错误。
错误风险较高的写法:
df["roa_lag"] = df["roa"].shift(1)这行代码只是把整张表向下移动一行,并没有保证同一企业内部滞后。更合适的写法是:
df = df.sort_values(["firm_id", "year"])
df["roa_lag"] = df.groupby("firm_id")["roa"].shift(1)如果 AI 给你的面板数据代码中出现 shift(),要检查它是否配合了 groupby() 和排序。
6.4 AI 没有检查合并质量
数据合并后,如果不检查合并质量,风险很高。比如政策数据按城市-年份合并到企业数据,必须检查:
# 合并状态
print(df["_merge"].value_counts())
# 核心变量缺失比例
print(df["policy"].isna().mean())
# 合并后主键是否重复
print(df.duplicated(["firm_id", "year"]).sum())如果 AI 只写了 pd.merge(),但没有任何合并质量检查,建议让它补上。
可以这样问:
请在现有 merge 代码后补充合并质量检查,包括:
1. 合并状态统计;
2. 核心政策变量缺失比例;
3. firm-year 是否重复;
4. 合并前后样本量变化。这种要求比“帮我检查一下”更明确。
7. Python 速查卡片:常用语法和函数
下面把常用语法和函数集中放在一起。读者不需要一次性记住,遇到问题时回来查即可。
7.1 Python 基础
x = 5 | |
type(x) | |
vars = ["roa", "size", "lev"] | |
labels = {"roa": "资产收益率"} | |
f"{var}_lag" | |
if x > 0: | |
for var in vars: | |
def f(x): return x + 1 | |
[x**2 for x in range(10)] | |
with open("a.txt", "r") as f: |
7.2 NumPy
import numpy as np | |
np.array([1, 2, 3]) | |
np.zeros(10) | |
np.linspace(0, 1, 11) | |
rng = np.random.default_rng() | |
rng.standard_normal(100) | |
rng.uniform(0, 1, size=100) | |
A @ B | |
np.linalg.solve(A, b) | |
np.where(x > 0, 1, 0) |
7.3 Pandas
import pandas as pd | |
pd.read_csv("file.csv") | |
pd.read_excel("file.xlsx") | |
pd.read_stata("file.dta") | |
df.head() | |
df.info() | |
df.describe() | |
df["x"] | |
df[["x", "y"]] | |
df[df["x"] > 0] | |
df[(df["x"] > 0) & (df["y"] < 1)] | |
df["z"] = df["x"] + df["y"] | |
df.rename(columns={"old": "new"}) | |
df.sort_values(["firm", "year"]) | |
df.groupby("year")["roa"].mean() | |
pd.merge(df1, df2, on=["id", "year"]) | |
pd.concat([df1, df2]) | |
df["x"].isna() | |
df.dropna(subset=["x"]) | |
df.to_csv("file.csv", index=False) | |
df.to_stata("file.dta", write_index=False) |
7.4 Matplotlib
import matplotlib.pyplot as plt | |
fig, ax = plt.subplots() | |
ax.plot(x, y) | |
ax.scatter(x, y) | |
ax.hist(x) | |
ax.set_xlabel("Year") | |
ax.set_ylabel("Outcome") | |
ax.set_title("Title") | |
ax.legend() | |
fig.savefig("fig.png", dpi=300, bbox_inches="tight") |
8. 后续学习:按任务扩展,而不是一次性学完
掌握基础语法、NumPy、Pandas 和 Matplotlib 后,就可以根据研究任务继续扩展。这里不建议把所有 package 都提前学完。更好的方式是遇到任务时知道应该去找哪类工具。
A. 计量建模:statsmodels
如果要做线性回归、Logit、Probit、时间序列模型,可以先了解 statsmodels。它的公式接口接近 R,适合经管社科研究者。
import statsmodels.formula.api as smf
model = smf.ols(
"roa ~ treated + size + lev + C(year)",
data=df
).fit(cov_type="HC1")
print(model.summary())需要说明的是,复杂面板固定效应、高维固定效应、聚类标准误等问题,在 Python 中也有对应工具,但不同 package 的语法和功能边界并不完全相同。实证研究中不要只看代码能否运行,还要确认模型设定和标准误处理是否符合论文需要。
B. 机器学习:scikit-learn
如果要做预测、分类、聚类、交叉验证,可以考虑 scikit-learn。它的接口相对统一,适合构建标准机器学习流程。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
X = df[["size", "lev", "age", "growth"]]
y = df["roa"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
print(model.score(X_test, y_test))如果 AI 手写机器学习算法,要先问:这个任务是否已有成熟 package?自己写算法通常不是实证研究中最有效的路径。
C. 数值计算:SciPy
如果要做最优化、积分、方程求根、统计分布计算,可以看 SciPy。例如:
from scipy.optimize import minimize
def objective(x):
return (x - 2)**2
res = minimize(objective, x0=0)
print(res.x)如果 AI 写了复杂的搜索循环,可能可以改用 scipy.optimize。
D. 符号计算:SymPy
如果需要公式推导、求导、积分、化简表达式,可以了解 SymPy。它更接近数学推导,而不是表格数据处理。
E. 文本和网页数据:requests、BeautifulSoup 与其他工具
如果要抓取网页数据,可以从 requests 和 BeautifulSoup 开始。需要说明的是,爬虫涉及网站规则、访问频率、版权和数据使用限制。研究中不要只关心能不能抓到数据,也要关心是否合规、是否可复现、是否能稳定更新。
F. 大数据和加速:不要盲目堆机器
代码慢时,先不要急着换电脑。可以按顺序检查:
• 是否可以用 NumPy 向量化; • 是否可以用 Pandas 的 groupby()、merge()、query();• 是否重复读取大文件; • 是否在循环中反复合并或追加 DataFrame; • 是否可以分块读取; • 是否需要使用 polars、数据库或Numba。
很多时候,慢不是 Python 的问题,而是写法不合适。
9. 一套更有效的 AI 协作提示词
下面给出几类可以直接使用的提示词。它们的共同特点是:不只让 AI 写代码,而是要求它说明逻辑、控制风险、保留可复现性。
A. 让 AI 写数据处理代码
我有一份企业-年份面板数据,DataFrame 名为 df。
核心变量包括 firm_id、year、roa、size、lev、city。
请用 Pandas 完成以下任务:
1. 保留 2000-2020 年样本;
2. 删除 roa、size、lev 缺失的观测;
3. 按 firm_id 和 year 排序;
4. 构造 roa 的一期滞后变量;
5. 输出处理前后的样本量变化。
请使用向量化写法,不要逐行循环。
每一步代码都加中文注释。B. 让 AI 检查代码
请帮我审查下面这段 Python 代码。
重点检查:
1. 是否存在样本筛选错误;
2. 是否存在合并键错误;
3. 是否存在变量类型问题;
4. 是否存在面板数据排序问题;
5. 是否可以用更简洁的 Pandas 或 NumPy 写法。
请不要直接重写全部代码。
先指出问题,再给出最小修改方案。C. 让 AI 优化代码
下面这段代码可以运行,但速度较慢。
请判断是否可以用 NumPy 向量化、Pandas groupby、merge 或其他成熟函数改写。
要求:
1. 保持输出结果不变;
2. 不改变变量含义;
3. 给出改写前后的逻辑对照;
4. 说明为什么新写法更快或更清楚。D. 让 AI 解释报错
下面是我的 Python 报错信息和相关代码。
请按以下顺序帮我分析:
1. 报错类型是什么;
2. 最可能出错的代码行是哪一行;
3. 这个错误通常由什么原因导致;
4. 如何用最小修改修复;
5. 如何避免以后再次出现类似错误。
请不要重写整段程序。这些提示词背后的原则是:你要让 AI 做具体任务,而不是把整个判断过程完全交给它。
10. 结语:学 Python,是为了更好地使用 AI
AI 已经改变了学习 Python 的方式。今天的研究者不一定要从零写出所有代码,但仍然需要掌握一些基础概念、常用函数和语法规则。
原因很现实。
小 bug 不值得每次都问 AI。常见错误自己能修,可以节省大量沟通时间。低效代码不值得照单全收。知道 NumPy、Pandas、Matplotlib、statsmodels、scikit-learn 等工具的基本功能,才能提醒 AI 不要用笨办法。错误代码更不能盲目信任。实证研究中的变量构造、样本筛选、数据合并和模型设定,都需要研究者自己承担判断责任。
所以,Python 速查表的意义不是让你回到“手写一切”的时代,而是让你在 AI 写代码的时代仍然保留判断权。
简言之:AI 可以帮你写代码,但不能替你理解代码。
11. 相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh python学习 python金融 python应用 python篇 python实现 提示词, m
安装最新版lianxh命令:ssc install lianxh, replace
• 刘潍嘉, 2025, 扎马步-常用概率分布函数详解:Python篇[6]. • 吴浩然, 2024, 数据爬取:美国证监会EDGAR系统数据获取及Python实现[7]. • 罗丹, 2025, 提示词!提示词!数据清洗、数据分析、可视化一网打尽[8]. • 董思源, 2025, 提示词!用 DeepSeek 快速生成更优代码[9]. • 赵文琦, 2025, LLM系列:ChatGPT提示词精选与实操指南[10]. • 连享会, 2021, 司继春:Python学习建议和资源[11]. • 连小白, 2025, 提示词来了!如何让 AI 翻译看起来像你写的[12]. • 连小白, 2026, 通缉令:AI 烂词——张力、楔子、稳了[13]. • 连玉君, 2026, 从张大千到《树先生》:一张 AI 插图是怎样磨出来的[14]. • 连玉君, 2026, 老连也会画画了!AI 文生图功能太强大[15]. • 连玉君, 2025, 老连买电脑:ChatGPT,DeepSeek,豆包来帮忙[16]. • 陈卓然, 2023, Python金融分析系列-1:日期和时间变量的处理和转换[17]. • 陈卓然, 2023, Python金融分析系列-2:数据可视化[18]. • 陈卓然, 2023, Python金融分析系列-3:金融时间序列[19]. • 陈卓然, 2023, Python金融分析系列-4:数学工具-近似、凸优化、积分和符号运算[20]. • 高瑜, 2025, 书籍推荐:用Python实现可复现的数据科学[21].
🍓 连享会 · 2026 社会网络分析专题
嘉宾:杨张博 (西安交通大学)
时间:2026 年 8 月 18-19 日
咨询:王老师 18903405450(微信)

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍
搜: 推文、数据分享、期刊论文、重现代码 ……
👉 安装:. ssc install lianxh. ssc install songbl
👉 使用:. lianxh DID 倍分法. songbl all

🍏 关于我们
• 连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 • 直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。

引用链接
[1] joy_liuyue@163.com: mailto:joy_liuyue@163.com[2] 系列推文:AI 写代码时代,为什么还要懂一点?: https://www.lianxh.cn/search.html?s=%E4%B8%BA%E4%BB%80%E4%B9%88%E8%BF%98%E8%A6%81%E6%87%82%E4%B8%80%E7%82%B9%EF%BC%9F[3] Python cheatsheet: https://cheatsheets.quantecon.org/python-cheatsheet.html[4] Statistics cheatsheet: https://cheatsheets.quantecon.org/stats-cheatsheet.html[5] Python Programming for Economics and Finance: https://python-programming.quantecon.org/intro.html[6] 扎马步-常用概率分布函数详解:Python篇: https://www.lianxh.cn/details/1598.html[7] 数据爬取:美国证监会EDGAR系统数据获取及Python实现: https://www.lianxh.cn/details/1329.html[8] 提示词!提示词!数据清洗、数据分析、可视化一网打尽: https://www.lianxh.cn/details/1638.html[9] 提示词!用 DeepSeek 快速生成更优代码: https://www.lianxh.cn/details/1569.html[10] LLM系列:ChatGPT提示词精选与实操指南: https://www.lianxh.cn/details/1615.html[11] 司继春:Python学习建议和资源: https://www.lianxh.cn/details/563.html[12] 提示词来了!如何让 AI 翻译看起来像你写的: https://www.lianxh.cn/details/1640.html[13] 通缉令:AI 烂词——张力、楔子、稳了: https://www.lianxh.cn/details/1786.html[14] 从张大千到《树先生》:一张 AI 插图是怎样磨出来的: https://www.lianxh.cn/details/1784.html[15] 老连也会画画了!AI 文生图功能太强大: https://www.lianxh.cn/details/1780.html[16] 老连买电脑:ChatGPT,DeepSeek,豆包来帮忙: https://www.lianxh.cn/details/1561.html[17] Python金融分析系列-1:日期和时间变量的处理和转换: https://www.lianxh.cn/details/1294.html[18] Python金融分析系列-2:数据可视化: https://www.lianxh.cn/details/1295.html[19] Python金融分析系列-3:金融时间序列: https://www.lianxh.cn/details/1298.html[20] Python金融分析系列-4:数学工具-近似、凸优化、积分和符号运算: https://www.lianxh.cn/details/1300.html[21] 书籍推荐:用Python实现可复现的数据科学: https://www.lianxh.cn/details/1551.html
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 用AI写Python后端,原来可以这么爽!(附保姆级教程)
- 转行学Python找工作,真实面试经历复盘:这些小细节让你offer翻倍
- Python全套环境安装包_新手友好_Win/Mac双系统
- 半凯利仓位可能大了 5 倍?用 Python 重新理解凯利公式
- 《Python 从入门到精通》090|模块与标准库实战:写出更像“正式项目”的代码
- 进了python的大门 ,我已经无心工作
- 为什么我把日常桌面换成Alpine Linux?
- Python 潮流周刊#155:Python 3.14 垃圾回收风波
- Java/Go/Python/前端/云原生/算法,算力赛道薪资翻倍指南
- Linux 基础实战课 ⑥装完了 Nginx,怎么把它跑起来
