python爬虫篇
今天来讲一下python的爬虫篇,所谓爬虫就是从网站爬数据。
废话不多说,直接上案例
爬取漫客栈的漫画,并将漫画中的免费章节的漫画下载到本地文件夹
我下载的是都市之逆天仙尊
期望效果
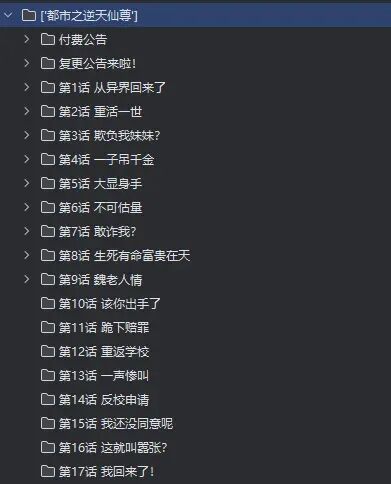
1.首先,请输入想要爬的漫画id,id从地址栏获取
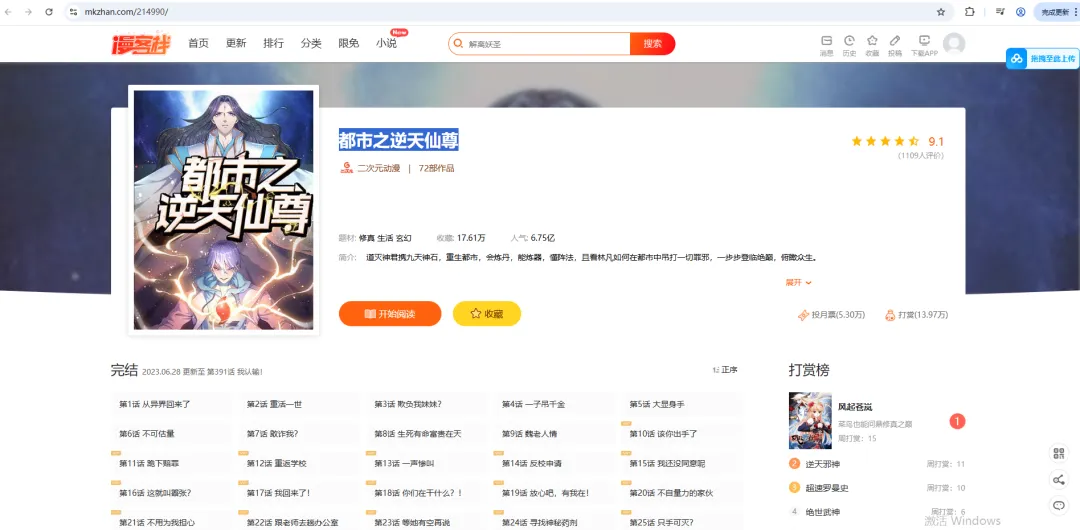
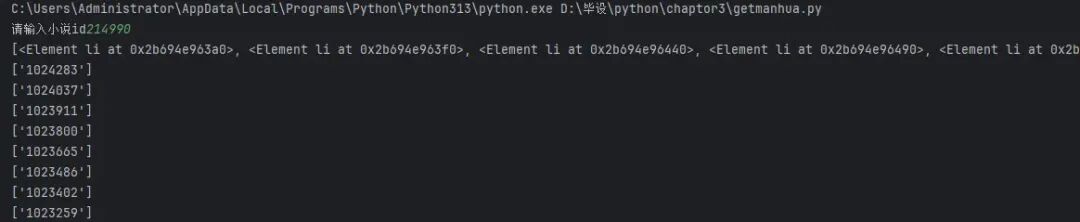
2.让用户输入漫画id
textid = input("请输入小说id")
3.输入以后获取页面所在地址,这里需要用到两个插件,一个是request,一个是lxml
import requestsfrom lxml import html
重点代码
1.获取网站的响应
response = requests.get(base_url + f'/{textid}/')
2.获取页面整体的document
document = html.fromstring(response.text)
3.因为章节都是在页面上,所以我们通过f12获取章节所在的div
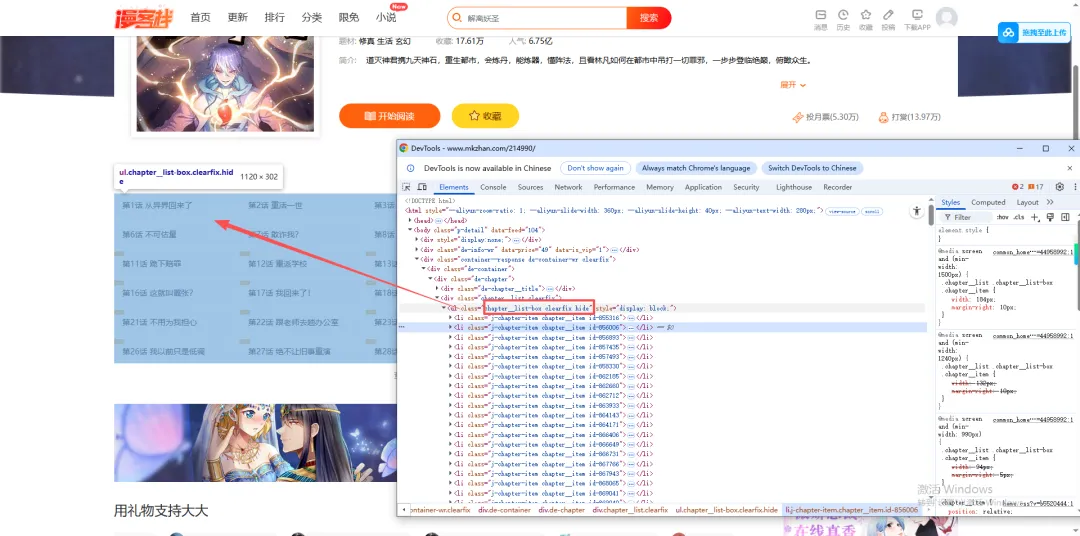
list = document.xpath("//ul[@class='chapter__list-box clearfix hide']/li")
4.将li进行遍历,取出所有的章节名称和章节id,放进一个数组
for item in list: name = item.xpath("./a/text()")if (len(name) == 2): textlist.append( name[1].replace(" ", "").replace(" ", ""))else: textlist.append(name[0].replace('\n ','').replace(" ", "")) href = item.xpath("./a/@data-chapterid")print(href) hreflist.append(href[0]) hreflist.reverse() textlist.reverse()
5.获取漫画名称
title=document.xpath("//p[@class='comic-title j-comic-title']/text()")
6.判断文件夹是否存在,不存在则新建
result = os.path.exists(f'{title}')if (result == False): os.mkdir(f"{title}")
7.对两个数组textlist,hreflist,进行循环,建出每个章节对应的文件夹
for text, href in zip(textlist, hreflist):print(text, href) result = os.path.exists(f'{title}/' + text)print(result)if (result == False): os.mkdir(f'{title}/' + text)
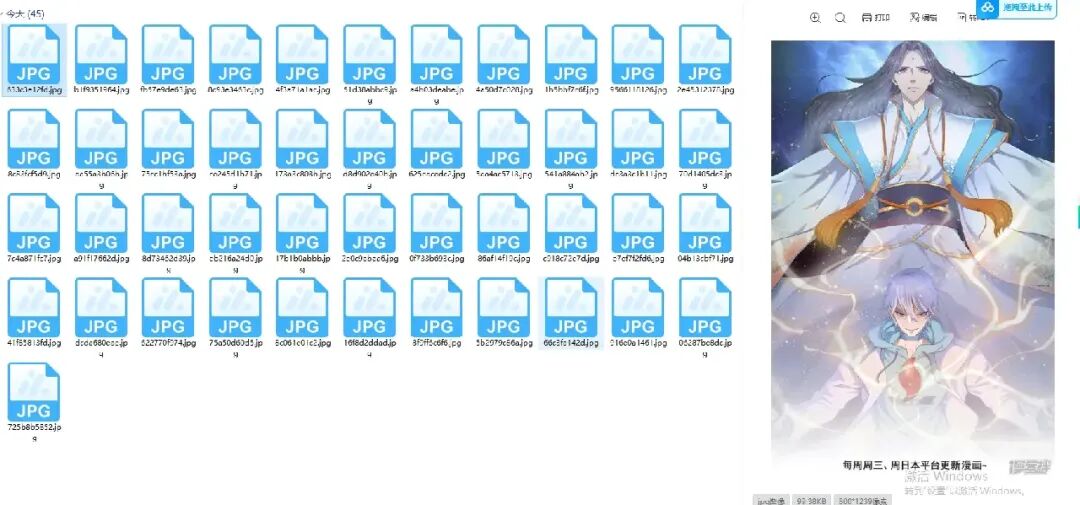
8.下载图片,因为漫画图片是pdf,所以我们通过接口下载就可以了。302说明用户没有登录,所以我们不下载vip的章节
def addimage(textid,text,href,title):print(text) response = requests.get(f"https://comic.mkzcdn.com/chapter/content/v1/?chapter_id={href}&comic_id={textid}&format=1&quality=1&type=1") obj = json.loads(response.text)print(obj)if (obj['code'] != "302"): list = obj['data']['page']for image in list: url = image['image']print(url) responses = requests.get(url) with open(f"{title}/" + text + '/' + url[-10:] + ".jpg", 'wb') as file: file.write(responses.content)
结果
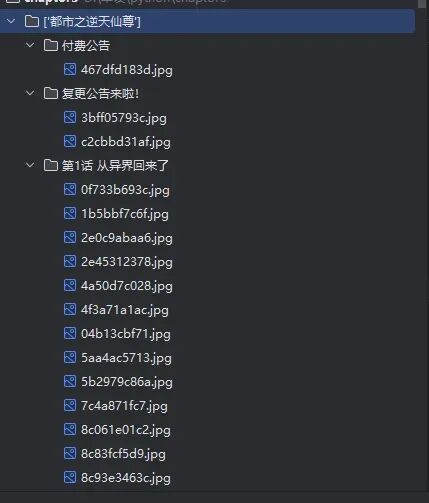
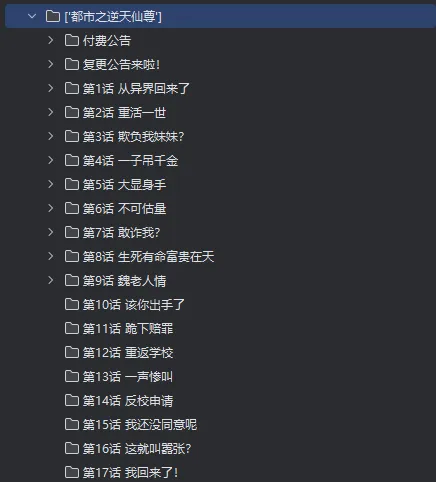
总结一下,这个案例用的知识点是文件操作,代码不算复杂,只要掌握了基础就能做出来
接下来会继续更新爬虫案例
需要了解服务器和域名的购买以及返佣政策的可以找我,我有朋友做这方面对这些比较了解。第一个群:只讨论java+vue的项目,学历提升和卖服务器的就别进了,进了也会被踢。第二个群:只讨论python项目,以后python的代码和教程会在群里开源,学历提升和卖服务器的就别进了,进了也会被踢。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
