Python学习【189】:定时任务在项目中的核心作用
在复杂的业务系统中,定时任务扮演着“隐形运维工程师”的角色。它的核心作用主要体现在以下三个方面:- 解耦与自动化:将人为手动触发的操作(如点击“刷新”按钮)转化为系统后台的自动化例行程序,极大解放人力。
- 数据最终一致性保障:在无法使用消息队列(MQ)或Webhook实时回调的情况下,定时轮询是保证系统间数据最终一致性的“兜底”方案。正如你提到的网盘场景,别人何时更新是不可控的,程序通过定时扫描,将外部不可控的被动更新转化为系统内部可控的主动拉取。
- 系统健康自愈与维护:常用于缓存刷新、过期会话清理、日志归档、数据库备份等基础设施级维护操作。
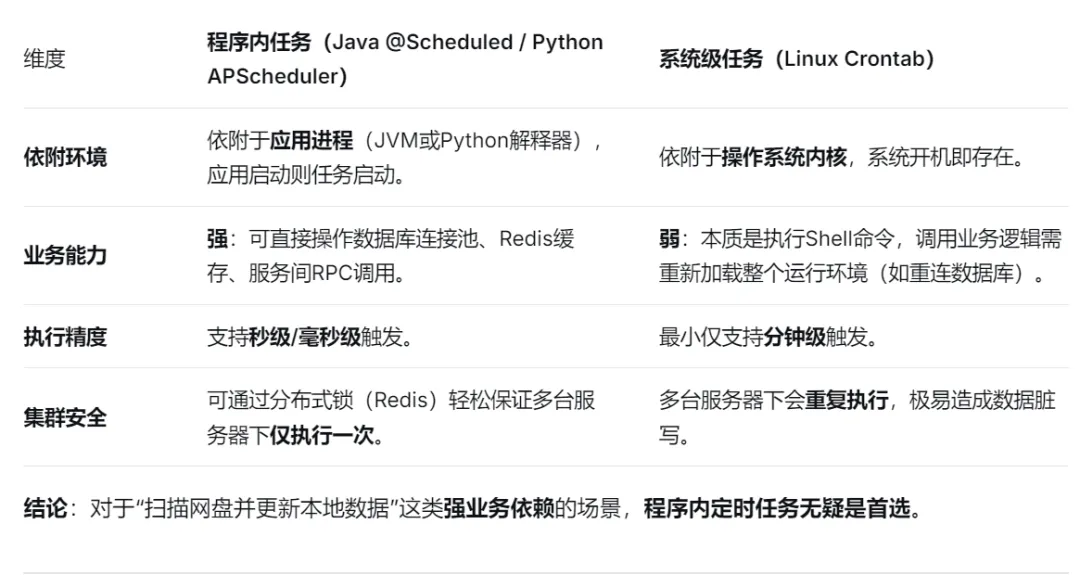
编程内定时任务 vs Linux Crontab:异同速览在具体编码前,我们先快速回顾两者本质区别,以便确认选型:结论:对于“扫描网盘并更新本地数据”这类强业务依赖的场景,程序内定时任务无疑是首选。下面我们用 Python + APScheduler 库来实现一个完整的定时任务示例。该程序启动后会每隔 60 秒扫描指定文件夹,获取最新的文件列表,并将变更记录“更新”到内存缓存(实际项目中可替换为写入数据库)。- 环境准备
首先安装依赖库:
- 完整代码实现
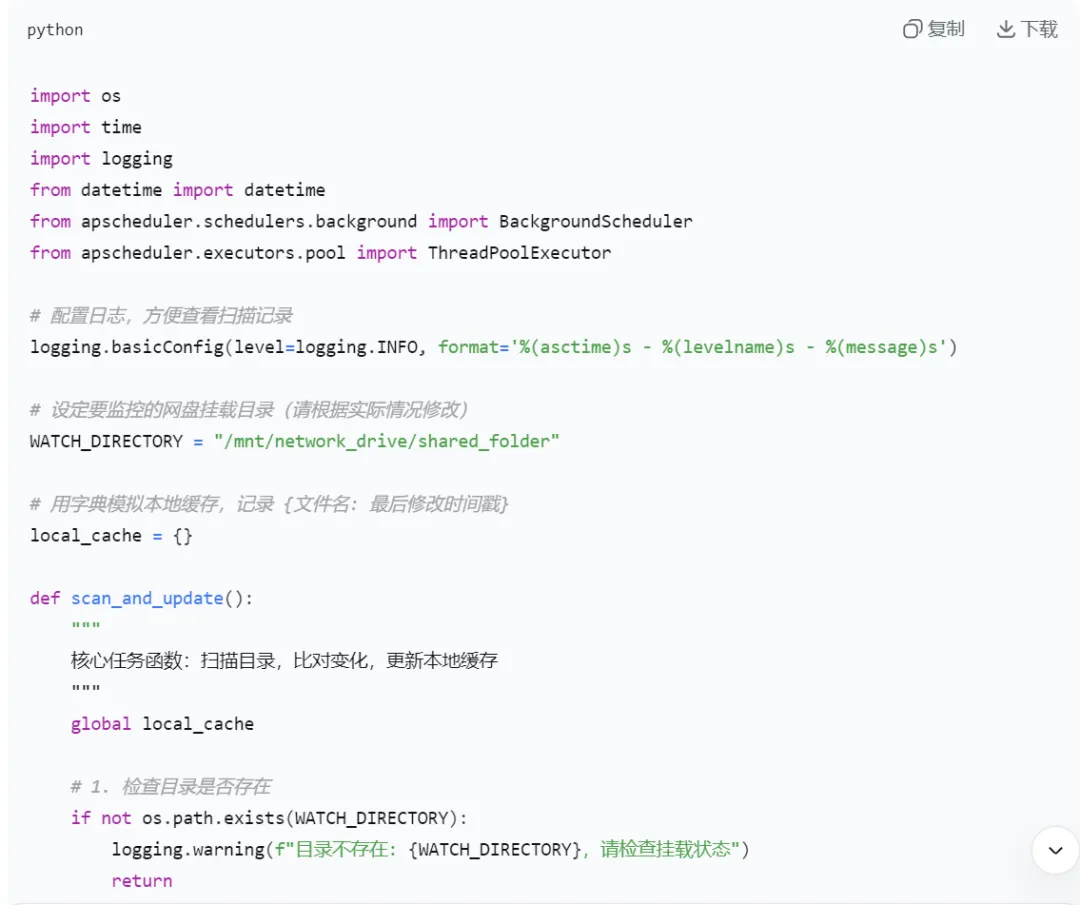



程序执行结果: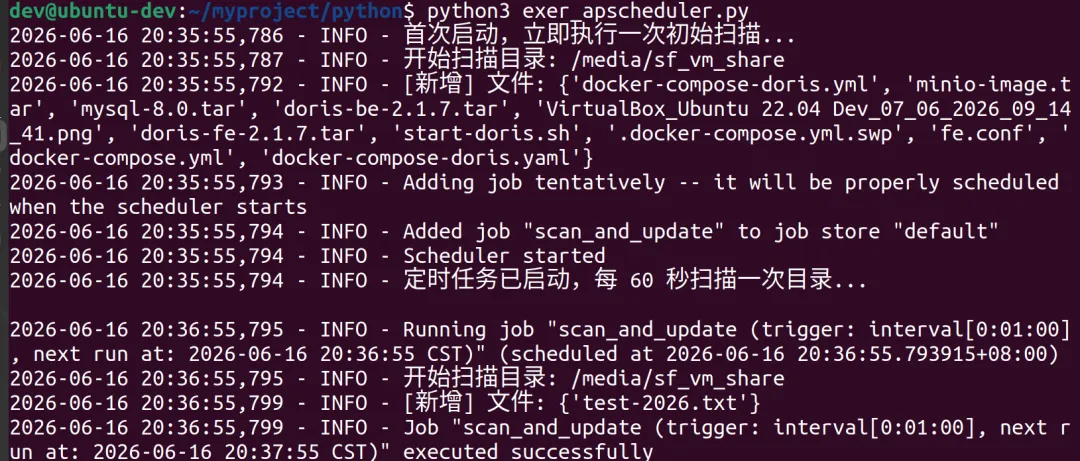
上面结果看出,当网盘文件夹中增加新文件test-2026.txt的时候,程序马上获得增量结果。验证了该程序的可行性。
- 防重叠机制:ThreadPoolExecutor(max_workers=1) 确保了就算扫描时间超过 60 秒,下一个任务也不会强行挤进来,防止多线程并发操作本地缓存导致脏数据。
- 状态持久化(扩展点):代码中的 localcache 是内存字典,如果程序重启,缓存会丢失。若需持久化,可将 localcache 替换为 SQLite 或 Redis。
- 增量处理:通过比对文件修改时间戳(mtime),精准区分新增、删除和修改,避免每次全量更新数据库,极大提高性能。
- 选型策略总结:
在“业务内嵌任务”与“系统Crontab”之间,不存在绝对的优劣,只有是否合适。当任务需要读写数据库、调用微服务、使用缓存且部署在集群环境时,请毫不犹豫选择 Java / Python 程序内定时任务,它能提供更细的粒度控制和业务亲和力。当任务仅是简单的 Shell 脚本(如清理日志、备份文件)、且业务逻辑极轻量、应用处于单机部署时,Linux Crontab 依旧是最轻便、稳定且无需维护应用进程的选择。
务必使用上述 Python(或 Java)的内嵌调度方案。同时,请将interval间隔设置为一个合理值(如 300 秒),避免因扫描过于频繁导致网盘服务器触发访问频率限制(Rate Limit)。如果未来网盘服务商提供了 Webhook 回调接口,应优先使用回调,将定时轮询降级为“兜底补偿机制”,这是最优雅的架构设计。将上述 Python 脚本与 supervisor 或 systemd 结合,可以让 Python 程序在意外崩溃时自动重启,从而弥补“程序内任务依附于应用进程”的脆弱性,达到媲美 Crontab 的稳定性。让我们保持学习的热情,2026年一马当先、马到成功!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
