网络交响序曲——Linux 网络栈全景透视
eBPF 的艺术(二十六)· 第二部开篇
如果要让 eBPF 程序在网络数据流中"精准下刀",你得先知道每一刀该切在哪里。本章不是教科书式的"从上到下讲一遍协议栈"——而是用一个丢包事故,带你走完一段"网卡到 socket"的完整旅程,沿途标出 eBPF 能插手的每一个位置。
一、一台服务器,五种客户端,三种不通
2024年8月,调度中心。一台部署了 SM4 加密隧道的网关服务器出现了一个诡异的现象:
• 调度中心(同一网段)发起的连接——正常
• 从监控节点(同一网段)发起的连接——正常
• 从备用中心(跨 VLAN,但路由可达)发起的连接——不通
• 从防火墙测试机(直连同一交换机)发起的连接——有时通有时不通
• 从数据中心(经 IPSec VPN 隧道)发起的连接——不通
五个客户端,网络拓扑各不相同,但目标 IP 是同一台服务器。TCP 握手报文能到达服务器网卡(我们在交换机上做了端口镜像确认),但服务器就像没收到一样——没有任何 SYN-ACK 回复。
这不像防火墙拦截(所有五条流都经过同一组 iptables 规则),也不像路由问题(ip route get 显示路由正确)。最诡异的是"有时通有时不通"的防火墙测试机。
排查花了 4 个小时。根因是 rp_filter——一个默认开启、几乎没人注意、不会记日志的内核参数。
服务器有两块网卡:eth0(192.168.1.0/24,内网)和 eth1(10.0.0.0/8,管理网)。防火墙测试机的流量从 eth0 进来,但它的源 IP 恰好在 eth1 的路由表里有回程路由。Linux 内核在做 rp_filter 检查时发现:"这个包的源 IP 的最佳回程路径不是从 eth0 出去",于是静默丢弃——在 Netfilter 碰都没碰到之前。
这次事故让我意识到:大部分工程师对 Linux 网络栈的理解停留在"应用层 → socket → 网卡"的线性模型上。但实际上,一个包从网卡走到你的程序,中间要经过 9 个不同的处理阶段,每个阶段都可能在不打日志的情况下把包丢掉。二、一张图看懂九个阶段
这不是"从上到下"的图,而是时间顺序的图——一个从外面进来的包,在内核里按什么顺序被处理:
| ① XDP — 最早的门卫(比SKB分配还早) DROP / TX / REDIRECT / PASS | | ② 内核 SKB 分配 | ③ TC Ingress — 流量控制入向 ★ 在 Netfilter 之前!能看到DNAT前的原始IP | | ④ Netfilter PREROUTING | ⑤ 路由决策 — FIB 查找 本地投递?还是转发(forward)? | ⑥ rp_filter — ★ 看不见的墙 静默丢弃,不触发任何Netfilter hook | | ⑦ Netfilter INPUT | | ⑧ 传输层 — tcp_v4_rcv→TCP状态机→socket缓冲区 | | ⑨ 用户态 — read() / recv() |
|
最重要的反直觉点:大部分人以为 iptables 是包处理的第一关,但实际上 XDP、TC Ingress、甚至内核的 rp_filter 都排在 Netfilter 前面。你加的 iptables 规则可能根本就没机会被执行。三、四个关键阶段的源码透视
3.1 XDP:最早的门卫
XDP 挂钩在网卡驱动的 NAPI poll 函数里,以 Intel i40e 驱动为例:
// drivers/net/ethernet/intel/i40e/i40e_txrx.c // XDP 程序在 SKB 提交给内核栈之前被调用 if (xdp_prog) { act = bpf_prog_run_xdp(xdp_prog, xdp); switch (act) { case XDP_PASS: break; // 正常继续 case XDP_DROP: goto next_desc; // ★ 跳过,无日志 case XDP_TX: i40e_xmit_xdp_ring(xdp, rx_ring); goto next_desc; } } |
关键信息:XDP_DROP 不会触发任何计数器(除了 eBPF map 自己记的)。netstat -s 看不到,/proc/net/dev 看不到。如果机器上有 XDP 程序在跑而你不知道——排查丢包会非常痛苦。3.2 TC Ingress 与 Netfilter 的顺序
__netif_receive_skb_core 是包进入协议栈的统一入口:
// net/core/dev.c
// ① 先处理 tcpdump (ptype_all)
list_for_each_entry_rcu(ptype, &ptype_all, list) {
deliver_skb(skb, pt_prev, orig_dev);
}
// ② 然后 TC Ingress ★在 Netfilter 之前
if (static_branch_unlikely(&ingress_needed_key)) {
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev);
}
// ③ 然后才到 Netfilter PREROUTING
// (通过 NF_HOOK 宏在 ip_rcv 中调用)
3.3 DNAT 分水岭:PREROUTING 之后的路由
// net/ipv4/ip_input.c intip_rcv(struct sk_buff *skb, ...) { // ★ NF_HOOK PREROUTING → 如果有DNAT, // skb里的目标IP已经变了 return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, NULL, skb, dev, NULL, ip_rcv_finish); } // ip_rcv_finish 紧接着做路由决策—— // 此时用的是 DNAT 后的目标IP |
3.4 rp_filter:最隐蔽的杀手
// net/ipv4/fib_frontend.c // ★ rp_filter 检查——路由决策之后、INPUT之前 intfib_validate_source(struct sk_buff *skb, ...) { // "回复这个包的源IP,会走哪个接口出去?" // "如果出口 != 接收接口 → 丢弃" if (rp_filter == 1 && res.fi->fib_dev != dev) goto e_inval; // ★ 静默丢弃 e_inval: __IP_INC_STATS(net, IPSTATS_MIB_IPRPFILTER); return -EINVAL; // 只更新一个很少有人看的计数器 } |
四、eBPF 能在哪九个位置插手
| | |
|---|
| | |
| | |
| | |
| BPF_PROG_TYPE_NETFILTER(6.4+) | |
| | |
| | 追踪 fib_validate_source 返回值 |
| | |
| BPF_PROG_TYPE_SOCK_OPS / CGROUP_SOCK | |
| | |
核心规律:eBPF 越靠近网卡(XDP),能处理的包越多(跳过了内核开销),但上下文越少(没有 socket、没有连接追踪)。越靠近用户态(sock_ops),上下文越丰富,但吞吐量越低。五、同一件事在不同位置做,效果差多少
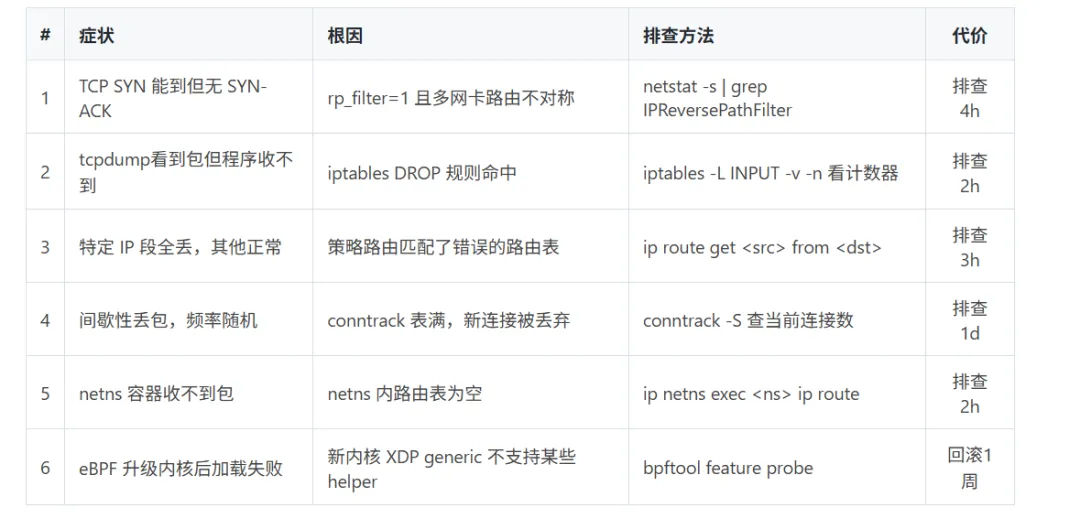
以"丢弃来自 IP 1.2.3.4 的包"为例,同机实测:六、踩坑表:六个"包去哪了"的血泪教训
七、本章小结
这一章没有写 eBPF 代码——因为在你写第一行 SEC("xdp") 之前,你得先知道 XDP 在网卡驱动的哪个位置、TC Ingress 在 Netfilter 的哪个位置、以及 rp_filter 为什么能让你怀疑人生。
Linux 网络栈不是一条直线,而是一棵树——每个阶段都可能让包消失,每个阶段都可能改写包的内容。eBPF 给你的能力,就是在这棵树的任意节点插入你的逻辑。但前提是,你知道每个节点在哪。
下一章,我们正式进入 XDP 的世界——站在网卡驱动的最前沿,用不到 14ns 的延迟处理每一个包。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
