CFS 核心思想:虚拟运行时间 vruntime
Linux 调度子系统技术文档系列 · 第 4 篇
你是否有过这样的经历:在 Linux 上用 renice 把一个编译任务的 nice 值调到 -10,期待它跑得更快,结果发现 CPU 占用率几乎没变化?或者把一个备份任务的 nice 值拉到 +19,却发现它依然在疯狂抢占 CPU?这不是 renice 命令失灵,而是 Linux 调度器中一个精妙的设计——虚拟运行时间 vruntime——在幕后起着决定性的作用。
要理解为什么"调了 nice 值感觉不明显",我们必须深入 CFS 的核心度量衡。就像餐厅里按"实际吃了多少"来分配蛋糕并不公平(有人吃得快、有人吃得慢),CFS 也不使用实际运行时间来衡量"谁该让出 CPU"。它发明了一个全新的尺度:vruntime。
CFS 为什么引入虚拟运行时间?有哪些设计动机?
如果调度器只用实际运行时间来决定下一个运行谁,会发生什么?假设有两个进程 A 和 B,A 的 nice 值为 -10(优先级高),B 的 nice 值为 +10(优先级低)。调度器每次挑选"已运行时间最短"的进程。结果就是 A 和 B 得到完全相同的 CPU 时间。
这显然违背了用户设置 nice 值的初衷。用户期望高优先级进程获得更多 CPU 时间,低优先级进程让出资源。为了解决这个矛盾,CFS 引入了虚拟运行时间(virtual runtime,简称 vruntime)的概念。
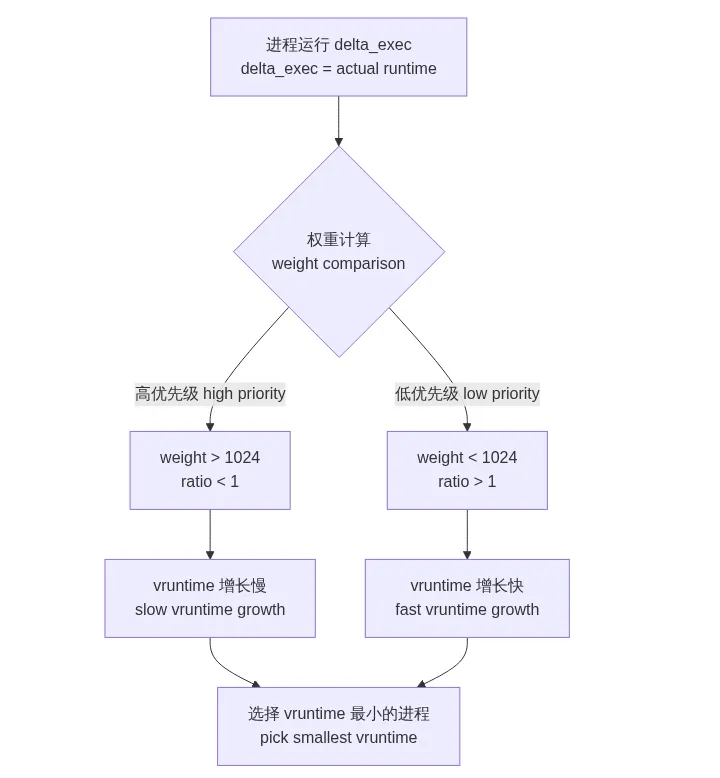
核心思想可以用一句话概括:把不同优先级进程的实际运行时间,映射到一个统一的虚拟时间尺度上。 高优先级进程的实际运行时间在映射后增长较慢,低优先级进程的增长较快。调度器只需要比较所有进程的 vruntime,选择最小的那个——它就是"饿得最久、最该吃蛋糕"的进程。
这种设计巧妙地分离了两个问题:
就像赛跑时给不同体力的选手设置不同的"虚拟距离",跑得快的选手每步算 1.5 米,跑得慢的选手每步只算 0.8 米。最终看谁的虚拟距离最短,谁就领先。
上图展示了 vruntime 的核心逻辑:实际运行时间经过权重换算后,不同优先级的进程以不同的速度积累虚拟时间,调度器始终选择 vruntime 最小者。
sched_entity 中的 vruntime 是什么?有哪些关键字段?
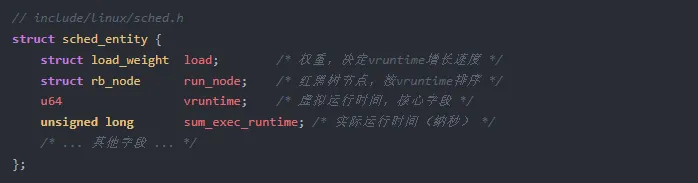
在 Linux 内核中,每个调度实体(sched_entity)都携带一个 vruntime 字段。它位于 include/linux/sched.h 定义的 sched_entity 结构中,是一个 64 位有符号整数,单位是纳秒——但这里说的是"虚拟纳秒"。
这里有两个容易混淆的时间概念:
sum_exec_runtime:进程从创建以来实际占用的 CPU 时间总和,是物理世界的真实时间vruntime
两者之间的关系由权重决定。权重越高,同样的实际运行时间对应的 vruntime 增量越小。
权重与 nice 值的映射关系是什么?
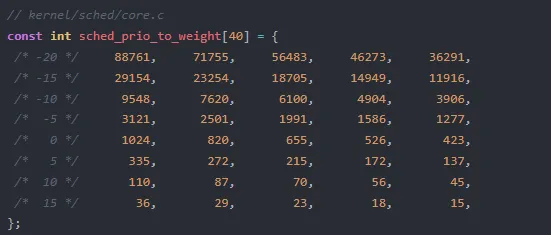
nice 值从 -20(最高优先级)到 +19(最低优先级),共 40 个级别。内核通过 sched_prio_to_weight 数组将 nice 值映射为权重。这个数组定义在 kernel/sched/core.c 中:
这里有两个关键问题值得深入理解。
为什么用 1024 作为基准?
nice 值为 0 的进程,其权重恰好是 1024,即 2 的 10 次方。这不是巧合。在后续的 vruntime 计算中,需要做除法运算 NICE_0_LOAD / weight。选择 2 的幂次作为基准值,可以让编译器在某些情况下将除法优化为位移操作。虽然现代编译器对除法优化已经很成熟,但 1024 这个数字在二进制世界中天然具有计算上的便利性。
更重要的是,1024 作为一个中间值,向上有足够的扩展空间到 88761(约 86 倍),向下有合理的压缩空间到 15(约 68 分之一)。这保证了不同优先级之间的权重差异既不会太大导致极端不公平,也不会太小导致差异化不明显。
相邻 nice 级之间的差异为什么是约 10%?
内核注释中写得很清楚:每个 nice 级别的变化带来约 10% 的 CPU 时间差异。当进程从 nice 0 变为 nice 1,它的权重从 1024 降到 820,约为原来的 80%。但相对的,如果另一个进程保持 nice 0 不变,两者之间的权重差距大约是 1024/820 ≈ 1.25,即 25% 的相对差异。
这就是注释中所说的"10% effect"——当你把自己的优先级提高一级,你获得的 CPU 时间减少约 10%;降低一级则增加约 10%。但因为调度是相对的,两个进程之间的实际差距是约 25%。
这也解释了为什么调一个 nice 值"感觉不明显":nice 从 0 调到 -10,权重从 1024 变为 9548,大约 9.3 倍的差异。但在多任务环境中,一个进程获得的 CPU 时间比例不仅取决于自身权重,还取决于所有其他就绪进程的权重之和。如果系统中同时运行着 20 个 nice 0 的进程,即使你把其中一个调到 nice -10,它获得的 CPU 时间增量也会被稀释。
上图展示了 nice 值如何通过权重映射,最终影响 vruntime 的增长速度。权重是连接用户空间 nice 设置和内核调度行为的桥梁。
vruntime 更新路径是怎样的?
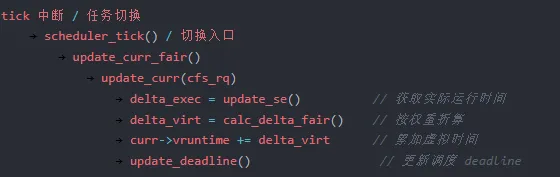
理解了权重映射后,我们来看 vruntime 的具体计算和更新过程。vruntime 的更新发生在 update_curr 函数中,这是 CFS 调度器在每个调度时钟 tick 或任务切换时都会执行的关键路径。
update_curr 函数
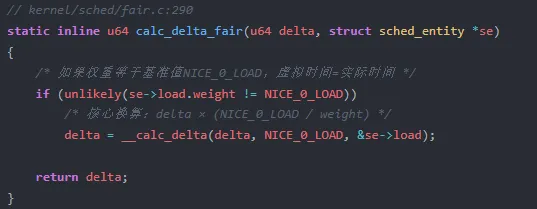
update_curr 的逻辑非常清晰:先拿到当前进程的实际运行时间增量 delta_exec,然后通过 calc_delta_fair 将其折算为虚拟时间增量,最后累加到 curr->vruntime 上。
calc_delta_fair 函数
这里有一个重要的边界情况:当进程的权重恰好等于 NICE_0_LOAD(即 nice 值为 0)时,calc_delta_fair 不做任何处理,直接返回 delta。也就是说,nice 0 的进程,其 vruntime 增长速度和实际运行时间完全一致。它是整个系统的"基准尺"。
当权重不等于 NICE_0_LOAD 时,调用 __calc_delta 执行实际的换算。这个函数内部使用了 prio_to_wmult 数组(权重的倒数预计算值),将除法转为乘法,再通过位移操作完成精度控制。这是一种常见的内核性能优化技巧——把频繁的除法运算提前为乘法逆元查表。
完整的更新链路
这条链路在每次时钟 tick(通常 1ms 间隔)或任务切换时都会执行。对于一台每秒执行 1000 次 tick 的机器,这段代码每秒被调用数千次。因此,calc_delta_fair 中的性能优化(除法转乘法查表)就显得尤为重要。
用户空间体验:为什么 renice 感觉不明显?
回到文章开头的问题。当你执行 renice -10 -p 后,进程的 nice 值确实变了,权重从 1024 变成了 9548。但在实际使用中,你可能感觉不到显著的性能提升。原因有三:
第一,相对性效应。 调度的公平性是在所有就绪进程之间分配的。假设系统中有 8 个 nice 0 的进程,你把其中一个调到 nice -10。虽然单个 nice -10 进程的权重是 nice 0 进程的 9.3 倍,但其他 7 个进程的权重加起来仍然很大。最终,nice -10 进程获得的 CPU 比例大约是 9.3 / (9.3 + 7) ≈ 57%,而不是你期望的"独占 CPU"。
第二,I/O 密集型任务的影响。 如果一个任务大量时间在等待 I/O,它的实际 CPU 占用率本来就不高。即使降低 nice 值让它在每次获得 CPU 时运行更久,由于 I/O 等待时间占主导,整体完成时间的改善仍然有限。
第三,CPU 绑定的竞争环境。 只有当两个 CPU 绑定的任务同时竞争时,nice 值的差异才会充分体现。如果系统中只有一个 CPU 密集型任务,它本来就能跑满 CPU,调 nice 值没有任何意义。
什么时候 renice 真正有效?
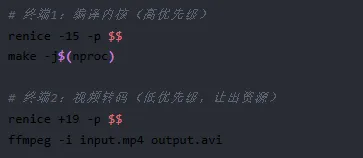
renice 最典型的适用场景是两个或多个 CPU 密集型任务同时运行。例如:
在这个场景中,ffmpeg 的权重仅为 15,而编译进程的权重为 29154。两者的权重比约为 1944:1。这意味着编译进程将获得几乎全部的 CPU 时间,而视频转码只能在编译空闲时"捡漏"。
总结:vruntime 架构要点
虚拟运行时间 vruntime 是 CFS 调度器的核心创新。它用一个简洁的公式 vruntime += delta_exec × (NICE_0_LOAD / weight) 解决了"不同优先级如何统一比较"的难题。
回顾全文,我们梳理了以下关键架构点:
- 为什么不用实际运行时间:因为不同优先级进程需要差异化的 CPU 配额,实际时间无法体现权重差异
- 为什么用 1024 作为基准
- 相邻 nice 级差约 10% 的设计
- 更新路径的简洁性:
update_curr → calc_delta_fair → vruntime += delta,一条清晰的数据流 - 用户空间的感知:renice 的效果取决于就绪队列中的竞争环境,不是孤立生效的
互动问题
如果系统中只有一个进程在运行,它的 vruntime 会无限增长吗?这会导致什么问题?
假设两个进程 A 和 B,A 的 nice 值为 -5(权重 2501),B 的 nice 值为 +5(权重 335)。它们同时竞争 CPU,各自大约能获得多少比例的 CPU 时间?试着用手算验证你的答案。
欢迎在评论区分享你的思考和计算过程。
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
