大家好,我是木木。
今天给大家分享一个高速的 Python 库,orjson。
orjson
orjson 是一个高性能 JSON 序列化库,核心目标是快、正确、输出紧凑。它的 dumps 返回 bytes,而不是 str,这一点和标准库 json 不一样。它对 datetime、dataclass、numpy 等常见工程对象提供了实用选项,也严格处理很多 JSON 边界问题。对 API 服务、日志系统、缓存层和数据管道来说,orjson 常常能在不改变数据模型的前提下减少序列化耗时。
项目地址:https://github.com/ijl/orjson
官方文档:https://github.com/ijl/orjson
三大特点
速度很快
底层实现追求高性能,适合热点 API 和高频序列化路径。
选项实用
支持 dataclass、datetime、numpy 等工程里常见对象。
输出严格
返回 bytes,边界行为明确,适合服务端响应和缓存写入。
最佳实践
安装方式:pip install orjson。
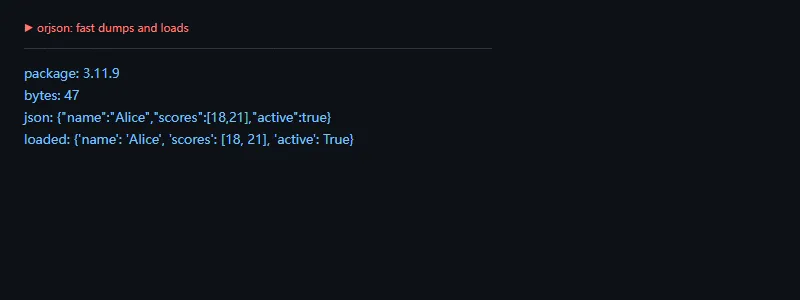
第一段代码解决的问题是:把 dict 序列化成紧凑 JSON bytes,再反序列化回来。
importorjsonfromimportlib.metadataimportversionpayload={"name":"Alice","scores":[18,21],"active":True}data=orjson.dumps(payload)print("package:",version("orjson"))print("bytes:",len(data))print("json:",data.decode())print("loaded:",orjson.loads(data))
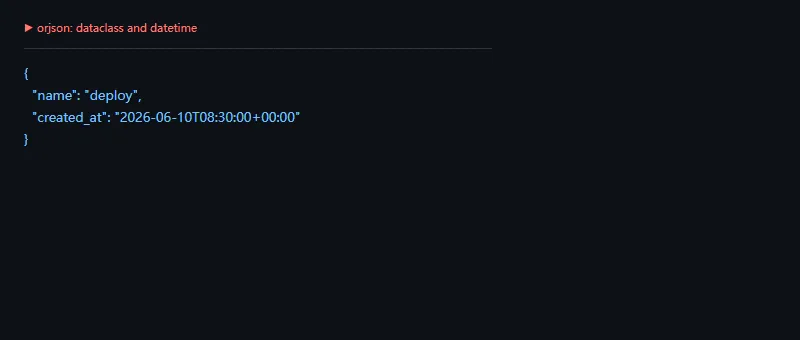
第二段代码解决的问题是:直接序列化 dataclass 和带时区 datetime,并用缩进选项输出便于调试的 JSON。
importorjsonfromdataclassesimportdataclassfromdatetimeimportdatetime,timezone@dataclassclassEvent:name:strcreated_at:datetimeobj=Event("deploy",datetime(2026,6,10,8,30,tzinfo=timezone.utc))data=orjson.dumps(obj,option=orjson.OPT_INDENT_2)print(data.decode())
环境与版本信息
本文示例使用 Python 3.11.0,orjson 3.11.9,numpy 2.2.4。示例只做本地 JSON 序列化,不访问外部服务。
高级功能
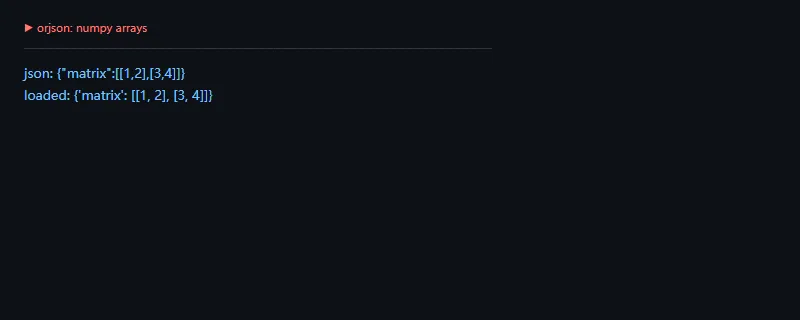
进阶一点看 numpy。标准库 json 不能直接处理 ndarray,orjson 可以通过 OPT_SERIALIZE_NUMPY 把数组转成 JSON 友好的嵌套列表。这个能力适合轻量数据 API,但大数组仍然应该评估体积和传输成本。
importorjsonimportnumpyasnparr=np.array([[1,2],[3,4]])data=orjson.dumps({"matrix":arr},option=orjson.OPT_SERIALIZE_NUMPY)print("json:",data.decode())print("loaded:",orjson.loads(data))
适用场景
适合高频 API 响应、日志序列化、缓存值、数据管道、需要 datetime 或 numpy 支持的 JSON 输出。
不适用场景
不适合必须返回 str 的旧接口、需要高度自定义编码流程,或对额外二进制依赖有严格限制的环境。
上线检查
- 注意
dumps 返回 bytes,Web 框架适配时不要重复 encode。 - 对 datetime、NaN、numpy 等边界值写回归测试。
总结
orjson 是很适合服务端的 JSON 工具。它快,但更重要的是边界清楚;把选项用对,能少踩很多序列化坑。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
