上一章我们讲了 lambda,已经知道它最常见的价值,不是拿来替代普通函数,而是在一些很短、很临时的场景里,快速提供一个小函数逻辑。那这一章,就轮到 lambda 最经典的一组搭档登场了:
mapfilterreduce
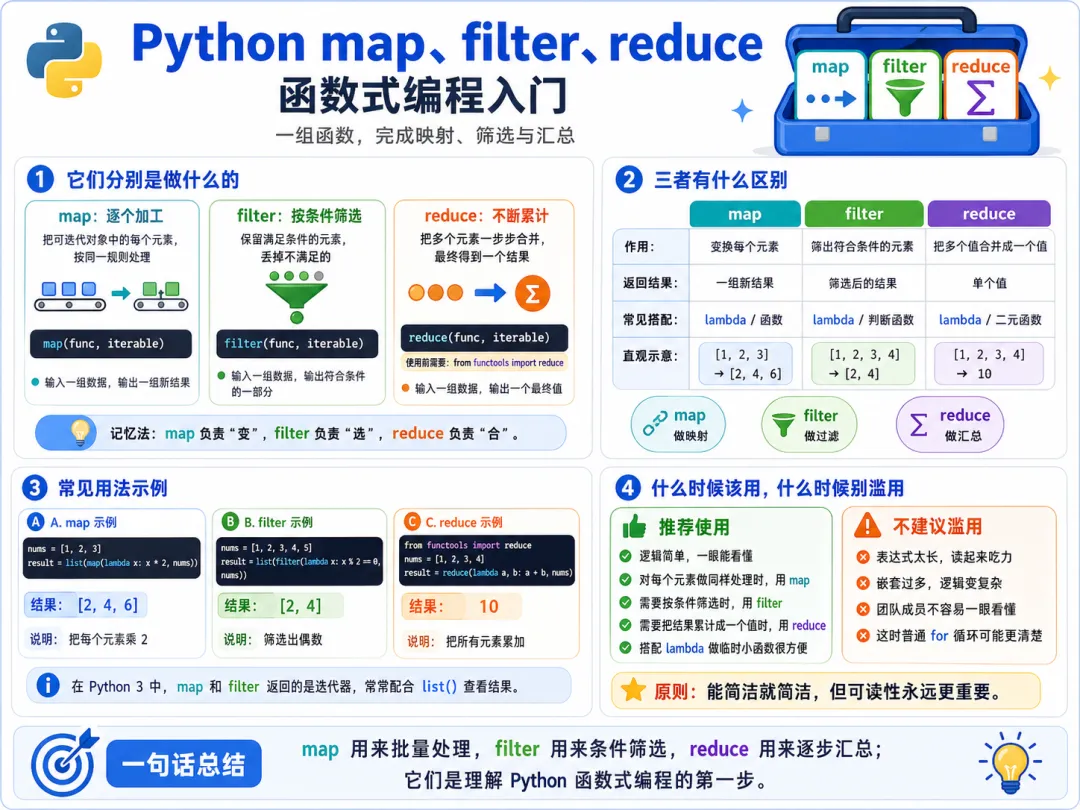
很多人第一次看到这三个名字,会有点发虚。总觉得这是不是特别函数式、特别抽象、特别像面试题。其实不用先给自己加难度。你先把它们翻译成人话,就会发现并不玄。
map 更像批量加工filter 更像条件筛选reduce 更像逐步合并成一个结果
这一章,我们就把这三个东西彻底讲清,而且会告诉你一个特别重要的现实判断:
它们确实有用,但不是所有场景都比普通循环或推导式更好。
所以你要学的,不只是语法,更是边界感。
一、先说一个总感觉:它们都在处理一组数据
这三个函数虽然长得不一样,但有一个共同点:
它们都不是在处理单个值,而是在处理一组数据。
比如你有一个列表:
nums = [1, 2, 3, 4, 5]
你可能会做下面这些事:
把每个数字都乘 2 只保留其中的偶数 把它们全部加起来
你会发现,这三类需求特别常见。
第一类,是对每个元素都做同一种处理。 第二类,是按条件留下符合要求的元素。 第三类,是把一组元素一步步合成一个最终结果。
而这三类事,正好分别对应:
mapfilterreduce
所以你现在先别急着背函数名,先把这三类动作分清。
二、先讲 map:它本质上是在批量加工
先给最直接的理解:
map 的作用,就是把同一个处理规则,批量作用到一组数据上。
比如你现在有一组数字,想让每个数字都乘 2。
普通写法你已经很熟了:
nums = [1, 2, 3, 4]result = []for n in nums: result.append(n * 2)print(result)
输出结果:
[2, 4, 6, 8]
如果用 map,可以写成这样:
nums = [1, 2, 3, 4]result = map(lambda x: x * 2, nums)print(list(result))
输出结果还是:
[2, 4, 6, 8]
这说明什么?
说明 map 的思路就是:
给我一个处理函数 再给我一组数据 我把这个函数一个个作用到每个元素上 最后得到一组新结果
这就是它最本质的动作。
三、map 的基本结构长什么样
你现在先记住这个模板:
map(函数, 可迭代对象)
比如:
map(lambda x: x * 2, nums)
意思就是:
遍历 nums每次取一个元素 交给 lambda x: x * 2 去处理 得到一组处理后的结果
你会发现,它和列表推导式有点像。 本质上都是在做批量转换。
所以你一定要建立一个很重要的认知:
map 不是凭空创造新能力,它只是另一种批量处理数据的表达方式。
四、为什么 map 的结果打印出来常常怪怪的
很多新手第一次写:
result = map(lambda x: x * 2, [1, 2, 3])print(result)
会发现输出的不是列表,而是一种看起来不太直观的对象表示。
这是因为在 Python 3 里,map() 返回的不是直接展开好的列表,而是一个可迭代对象。 所以如果你想真正看到里面的结果,最常见的做法是:
print(list(result))
也就是说,map() 先给你的是一个“可继续迭代的结果流”,而不是立刻摊平的列表。
你现在先不用把底层机制想太深。 先记一个实用结论就够了:
入门阶段想直接看结果时,经常会配合 list() 一起用。
五、再看几个特别典型的 map 例子
例子 1,把字符串转成大写:
words = ['python', 'java', 'go']result = map(str.upper, words)print(list(result))
输出:
['PYTHON', 'JAVA', 'GO']
这里很有意思,因为连 lambda 都不用。 直接把 str.upper 这个处理规则传进去就行了。
例子 2,把数字转成字符串:
nums = [10, 20, 30]result = map(str, nums)print(list(result))
输出:
['10', '20', '30']
例子 3,把每个数字平方:
nums = [1, 2, 3, 4]result = map(lambda x: x * x, nums)print(list(result))
输出:
[1, 4, 9, 16]
你会发现,这类需求特别统一:
一组数据 同一种处理 批量得到新结果
这就是 map 最舒服的地方。
六、不过你应该马上想到一个问题:这和列表推导式不是很像吗
没错,这就是你这一章必须建立的判断力。
比如上一章我们已经写过:
nums = [1, 2, 3, 4]result = [x * 2for x in nums]print(result)
它和:
result = list(map(lambda x: x * 2, nums))
效果几乎一样。
那到底该用哪个?
对新手来说,甚至对很多日常项目来说,列表推导式通常更直观。
因为它更贴近你前面已经建立起来的阅读习惯:
遍历 处理 生成列表
而 map 更偏函数式表达。
所以你现在先别急着把所有批量处理都改成 map。 真正更成熟的结论是:
你要会 map,但也要知道很多简单场景下,列表推导式往往更清楚。
这句话特别重要。
七、现在转到 filter:它本质上是在筛选
先给最直白的理解:
filter 的作用,就是从一组数据里,筛出符合条件的元素。
比如你现在有:
nums = [1, 2, 3, 4, 5, 6]
你只想保留偶数。
普通写法:
nums = [1, 2, 3, 4, 5, 6]result = []for n in nums:if n % 2 == 0: result.append(n)print(result)
输出:
[2, 4, 6]
如果用 filter,可以写成:
nums = [1, 2, 3, 4, 5, 6]result = filter(lambda x: x % 2 == 0, nums)print(list(result))
输出还是:
[2, 4, 6]
所以你现在可以先把 filter 理解成:
给我一个判断规则 再给我一组数据 我只留下那些判断结果为真的元素
这就是它的核心动作。
八、filter 的基本结构长什么样
模板很简单:
filter(函数, 可迭代对象)
这里这个函数有点特别。
在 map 里,函数返回的是“加工后的结果”。 而在 filter 里,函数返回的更像是“要不要保留”。
比如:
filter(lambda x: x % 2 == 0, nums)
这句话的意思就是:
遍历 nums每次取出一个 x判断 x % 2 == 0 是否成立 成立就留下 不成立就丢掉
所以 filter 和 map 表面上很像,但作用不一样:
map 是改造每个元素filter 是决定哪些元素留下
这一点必须分清。
九、再看几个特别典型的 filter 例子
例子 1,筛出正数:
nums = [-3, -1, 0, 2, 5, -7, 8]result = filter(lambda x: x > 0, nums)print(list(result))
输出:
[2, 5, 8]
例子 2,筛出长度大于 4 的单词:
words = ['cat', 'python', 'book', 'banana', 'go']result = filter(lambda x: len(x) > 4, words)print(list(result))
输出:
['python', 'banana']
例子 3,筛出包含字母 a 的单词:
words = ['apple', 'dog', 'banana', 'cat']result = filter(lambda x: 'a'in x, words)print(list(result))
输出:
['apple', 'banana', 'cat']
你会发现,filter 天然适合做那种:
保留 剔除 筛选 清洗
这类动作。
十、但这里你也应该想到:这不就是带 if 的列表推导式吗
没错,又接上了。
比如上一章我们写过:
nums = [1, 2, 3, 4, 5, 6]result = [x for x in nums if x % 2 == 0]print(result)
这和:
result = list(filter(lambda x: x % 2 == 0, nums))
效果一样。
那到底谁更好?
和 map 一样,很多简单筛选场景下,列表推导式通常更符合直觉。
因为它把数据来源、筛选条件、结果生成全放在一个你已经熟悉的结构里。
所以对当前阶段来说,最正确的理解不是:
我以后该全部换成 filter
而是:
我要会 filter,但也要知道很多时候,带条件的列表推导式会更清晰。
这就是边界感。
十一、现在终于轮到 reduce:它最容易让人发懵,但其实也能讲得很直白
先给最简单的人话解释:
reduce 的作用,是把一组数据一步步合并,最后压缩成一个结果。
比如:
把一组数字全部加起来 把一组数字全部乘起来 把一组字符串一步步拼接起来
这些都属于“逐步合并”的动作。
和前两个不同的是:
map 输出一组新结果filter 输出筛选后的那组元素reduce 最终通常输出一个单独的结果
这是它最大的区别。
十二、先注意一个细节:reduce 不在内置里,而在 functools 里
这一点你要先记住。
如果要用 reduce,通常要这样导入:
from functools import reduce
为什么不是直接 import reduce?
因为它属于标准库 functools 模块里的一个函数。
你现在不用深究历史原因。 先记住用法就够了:
用 reduce 前,通常先从 functools 导入。
十三、reduce 的最基础例子:把数字全部加起来
from functools import reducenums = [1, 2, 3, 4]result = reduce(lambda x, y: x + y, nums)print(result)
输出结果:
10
这里它是怎么工作的?
你可以先粗略理解成这样:
先拿前两个数:1 和 2,算出 3 再拿这个结果 3,和下一个数 3,算出 6 再拿 6 和下一个数 4,算出 10
最后就得到一个总结果。
这就是“逐步归并”的味道。
十四、reduce 的基本结构长什么样
模板可以先记成这样:
reduce(函数, 可迭代对象)
这里这个函数和前面的 map、filter 又不一样。
在 reduce 里,这个函数通常接收两个参数,表示:
当前累计结果 当前新元素
比如:
lambda x, y: x + y
意思就是:
把当前累计值 x 和当前元素 y 相加 返回新的累计值
所以 reduce 的本质不是遍历后保留每一步结果, 而是每一步都把结果继续往下传,直到最后只剩一个最终值。
十五、再看几个典型的 reduce 例子
例子 1,全部相乘:
from functools import reducenums = [1, 2, 3, 4]result = reduce(lambda x, y: x * y, nums)print(result)
输出:
24
例子 2,把字符串拼接起来:
from functools import reducewords = ['I', 'Love', 'Python']result = reduce(lambda x, y: x + ' ' + y, words)print(result)
输出:
I Love Python
这些例子会帮助你建立一个感觉:
reduce 特别适合那种“把一组元素压缩成一个值”的场景。
十六、但你现在必须知道一个非常现实的判断:reduce 经常没有循环和内置函数直观
比如求和这个动作,用 reduce 写:
from functools import reducenums = [1, 2, 3, 4]result = reduce(lambda x, y: x + y, nums)print(result)
当然可以。
但你前面早就学过更自然的写法:
nums = [1, 2, 3, 4]print(sum(nums))
后者是不是明显更直观?
这就是为什么很多人学到 reduce 时,会有点疑惑:
它明明能做事,但为什么现实里没前两个那么顺手?
答案很简单:
因为很多 reduce 能干的事,Python 往往已经有更直接的内置函数。
比如求和有 sum()。 求最大值有 max()。 求最小值有 min()。
所以 reduce 你当然要会,但也要知道:
很多常见场景里,它并不是第一选择。
十七、现在把这三者放在一起,区别就特别清楚了
你可以这样记:
map是一批元素进去,一批加工后的结果出来
filter是一批元素进去,留下符合条件的那批出来
reduce是一批元素进去,最后压成一个结果出来
比如对同一个列表:
nums = [1, 2, 3, 4]
map 可能变成:
[2, 4, 6, 8]
filter 可能变成:
[2, 4]
reduce 可能变成:
10
这组对比你一旦记住,后面就很不容易混。
十八、它们和 lambda 为什么总是绑定出现
因为这三个函数通常都需要你传入一个“处理规则”。
而这个规则往往又很短、很临时。
比如:
乘 2 判断偶数 两两相加
如果每次都专门写一个正式 def,当然也可以,但有时显得有点重。
所以大家就很自然会写成:
lambda x: x * 2lambda x: x % 2 == 0lambda x, y: x + y
这也是为什么上一章讲 lambda 之后,这一章紧跟着就讲 map、filter、reduce。 它们本来就是非常经典的一组搭档。
十九、不过你一定要建立一个更成熟的结论
这一章最重要的,不是会不会写三行语法,而是建立下面这组判断。
map、filter、reduce 你都要会。 但并不代表写代码时一定优先用它们。
很多简单场景下:
列表推导式可能比 map 更清楚 带条件的列表推导式可能比 filter 更直观sum()、max() 这类内置函数可能比 reduce 更合适
所以真正成熟的目标不是:
我要强行函数式
而是:
我知道这些工具的存在,并且能在合适场景下选更清楚的那个。
这才是最值钱的能力。
二十、做一个综合小案例:处理成绩数据
比如现在有一组成绩:
scores = [58, 76, 90, 43, 67, 81]
用 map 把每个成绩都转成字符串:
result1 = list(map(lambda x: f'成绩:{x}', scores))print(result1)
用 filter 筛出及格成绩:
result2 = list(filter(lambda x: x >= 60, scores))print(result2)
用 reduce 把所有成绩加起来:
from functools import reduceresult3 = reduce(lambda x, y: x + y, scores)print(result3)
这三个例子一放在一起,你就会特别清楚它们各自干什么。
一个在加工 一个在筛选 一个在归并
这就是本章最核心的结构感。
二十一、本章小练习
你可以做三个特别适合巩固的练习。
练习 1 用 map 把下面的数字列表全部乘以 10:
nums = [1, 2, 3, 4, 5]
练习 2 用 filter 筛出下面列表里所有大于 5 的数字:
nums = [2, 8, 1, 6, 9, 3, 5]
练习 3 用 reduce 把下面的数字全部相乘:
nums = [2, 3, 4]
参考答案:
from functools import reducenums = [1, 2, 3, 4, 5]result1 = list(map(lambda x: x * 10, nums))print(result1)nums = [2, 8, 1, 6, 9, 3, 5]result2 = list(filter(lambda x: x > 5, nums))print(result2)nums = [2, 3, 4]result3 = reduce(lambda x, y: x * y, nums)print(result3)
你把这三个练习亲手写一遍,这一章的主干就会非常稳。
二十二、本章总结
这一章最重要的,不是把三种函数写法背下来,而是分清它们各自处理数据的方式。
map 适合批量加工数据。filter 适合按条件筛选数据。reduce 适合把一组数据逐步归并成一个结果。 它们经常和 lambda 一起出现,因为都需要一个短小的处理规则。 但在很多简单场景下,列表推导式和内置函数往往更直观。 所以真正成熟的做法,不是盲目追求函数式,而是根据可读性和场景选择更合适的表达方式。
下一章我们继续往前走,进入一个很多人写过、却不一定真正理解的核心机制:095|迭代器是什么:for 循环背后的运行机制。