负载均衡:多核调度的艺术
Linux 调度子系统技术文档系列 · 第 8 篇
引言:8 核机器的诡异性能曲线
一台 8 核服务器上,监控面板显示了一个诡异的现象:两个 CPU 利用率飙到 100%,另外六个却安静地待在 5% 以下。系统整体吞吐量只有预期的四分之一,但 top 明明看到 plenty of idle cores。这就是负载均衡失效的经典症状——任务堆积在某些 CPU 的 CFS 红黑树上,而其他 CPU 的 runqueue 空空如也。
多核时代,调度器要回答两个问题:谁下一个运行,以及在哪个 CPU 上运行。前者是 CFS 的职责,后者是负载均衡的使命。如果不做负载均衡,每个 CPU 独立调度自己的 runqueue,线程亲和性会固化在初始分配的 CPU 上,系统整体吞吐量将严重受限于最忙碌的那个核。
为什么需要分层调度域?
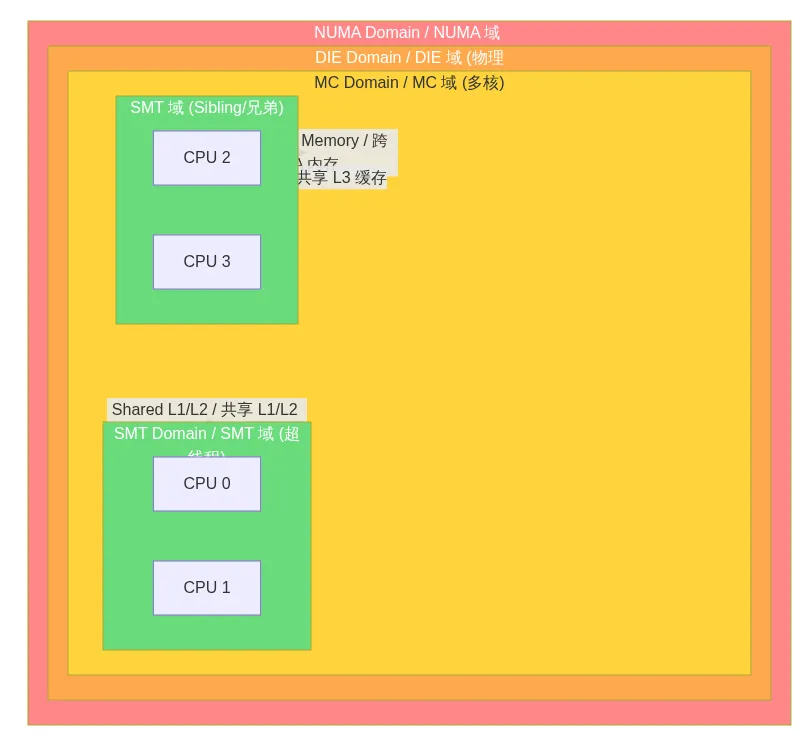
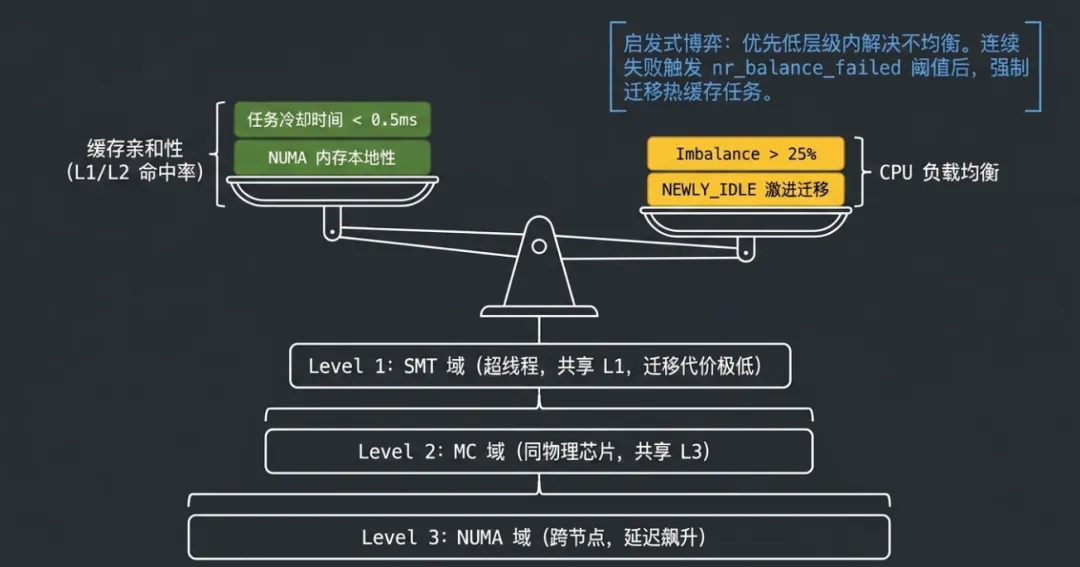
如果把所有 CPU 看作一个扁平的集合,负载均衡器每次都要遍历全局 runqueue,在数百个任务中寻找最优迁移目标。这在 64 核或 256 核系统上是不可接受的。更关键的是,扁平设计忽视了现代 CPU 的物理拓扑特征:超线程之间共享 L1/L2 缓存,同一 die 上的核心共享 L3 缓存,跨 NUMA 节点访问内存的延迟是本地节点的 2-3 倍。
调度域层级有哪些?
Linux 用 sched_domain 层次结构来映射硬件拓扑,每一层代表一个可以相互迁移任务的 CPU 集合。从低到高依次为:
- SMT 域:超线程兄弟核心,共享执行单元和 L1 缓存,迁移代价最低
- MC 域:同一物理芯片上的独立核心,共享 L2/L3 缓存
- DIE/PKG 域
- NUMA 域
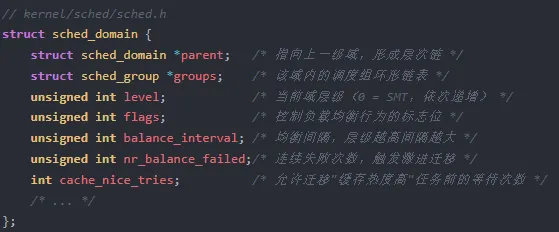
这种分层设计的核心思想是:优先在低层级均衡,只有低层级无法消化不均衡时才向高层扩散。低层级迁移代价小,高层迁移代价大。每一层维护独立的 balance_interval(均衡间隔),低层频繁均衡,高层缓慢均衡,形成自底向上的负载梯度。
核心数据结构:sched_domain 与 sched_group
struct sched_domain 是负载均衡的骨架。每个 CPU 维护一条从 SMT 到 NUMA 的 sched_domain 链,通过 parent 指针连接。域内的 CPU 被分组为 sched_group,每个组有自己的容量统计和负载信息。
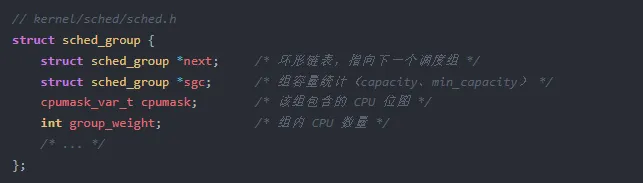
sched_group 是负载均衡的基本操作单位。一个 sched_domain 内的所有 sched_group 组成环形链表,每个组内包含一组 CPU。负载均衡时,内核以组为单位统计负载,然后在组之间迁移任务,而不是直接操作单个 CPU。这种分组方式将负载均衡的复杂度从 O(N²) 降低到 O(N),其中 N 是 CPU 数量。
sd_flag 标志位解析
flags 字段决定了每个 sched_domain 的负载均衡策略。常见的标志位包括:
- SD_LOAD_BALANCE:该域参与负载均衡,NUMA 节点初始化时可能不设置
- SD_WAKE_AFFINE:唤醒时保持亲和性,优先选择 waker 所在的调度组
- SD_SHARE_CPUCAPACITY:组内 CPU 共享容量(SMT 域),迁移代价极低
- SD_ASYM_CPUCAPACITY:组内 CPU 容量不同(大小核架构),优先向大容量核迁移
- SD_PREFER_SIBLING
- SD_NUMA
这些标志位是内核与硬件拓扑之间的桥梁。内核通过解析设备树和 ACPI 表,自动生成对应的 sched_domain 层次和标志位,无需手动配置。
PELT 负载追踪算法
负载均衡的前提是知道"哪个 CPU 更忙"。Linux 使用 PELT(Per-Entity Load Tracking)算法追踪每个调度实体的历史负载。PELT 的核心是指数衰减:最近的运行时间权重高,早期的运行时间权重低。衰减周期大约 1ms(对应 1024μs 的时间窗口)。
每个调度实体(进程或 cgroup)的 sched_avg 结构体维护 load_avg、runnable_avg 和 util_avg。负载均衡时,这些值逐层聚合到 sched_group 和 sched_domain,最终形成全局负载视图。PELT 的衰减机制使得负载变化能够快速反映到调度决策中——一个刚结束 CPU 密集计算的进程,其负载值会在几毫秒内下降到接近零。
负载均衡的触发时机
负载均衡不是持续运行的后台线程,而是在特定事件驱动下触发。内核定义了四种触发场景:
| | | |
|---|
| run_rebalance_domains() | | |
| newidle_balance() | | |
| wake_affine() | | |
| active_load_balance_cpu_stop() | | |
周期性均衡是负载均衡的主力。每个调度域维护一个 last_balance 时间戳和 balance_interval,当 jiffies - last_balance >= balance_interval 时触发。均衡成功时 balance_interval 回到最小值,连续失败时 nr_balance_failed 递增,触发更激进的迁移策略。
执行路径追踪:从时钟中断到任务迁移
负载均衡的核心路径发生在周期性时钟中断中。当 scheduler_tick() 被调用时,内核检查是否需要触发负载均衡。如果需要,则进入 run_rebalance_domains(),逐级遍历 sched_domain 链。
load_balance() 函数是整个均衡流程的核心。它接收一个 lb_env(负载均衡环境)作为上下文,包含源 CPU、目标 CPU、调度域、空闲类型等信息。执行流程分为三个阶段:
- 统计阶段:通过
update_sd_lb_stats() 遍历所有 sched_group,收集每个组的负载、利用率、空闲 CPU 数量等统计信息 - 决策阶段:
sched_balance_find_src_group() 选出最忙的调度组,计算不平衡量 imbalance - 迁移阶段:
detach_tasks() 从最忙 CPU 的 runqueue 上摘下合适的任务,通过 attach_tasks() 挂入目标 CPU
迁移决策的核心矛盾是负载均衡 vs 缓存亲和性。理想情况下,负载均衡器应该将任务均匀分配到所有 CPU。但现实中,迁移一个刚执行完的任务意味着它的 L1/L2 缓存内容在新 CPU 上全部失效,TLB 条目需要重建,NUMA 内存访问模式可能被打乱。内核用 task_hot() 来判断任务的"缓存热度":如果任务距离上次执行的时间小于 sysctl_sched_migration_cost(默认约 0.5ms),则认为它是热的,不适合迁移。
缓存亲和性与负载均衡的永恒博弈
缓存亲和性和负载均衡是一对相互矛盾的目标。追求负载均衡会频繁迁移任务,破坏缓存命中率;追求缓存亲和性又会导致负载倾斜。Linux 用一套启发式规则在两者之间找平衡:
- 缓存冷却机制
- nr_balance_failed 计数器:连续 N 次均衡失败后,降低缓存热度阈值,允许迁移热任务
- idle 类型区分:NEWLY_IDLE 均衡最激进(CPU 即将空闲,迁移收益大),BUSY 均衡最保守(当前 CPU 有任务在跑,迁移收益有限)
- imbalance_pct 阈值:只有当负载差异超过容量的 25%(默认值 125%)时才触发迁移
这套机制的本质是收益-成本分析。迁移一个任务的成本 = 缓存失效 + TLB 重建 + 可能的 NUMA 延迟增加。迁移的收益 = 减少目标 CPU 的等待时间。只有收益显著大于成本时,迁移才是值得的。
用户空间的影子:亲和性、NUMA 与容器
负载均衡虽然是内核内部的机制,但用户空间的行为会直接影响其效果。
sched_setaffinity 的双刃剑效应。当进程通过 sched_setaffinity() 将自身绑定到特定 CPU 时,负载均衡器会在 can_migrate_task() 中检查 cpus_ptr 掩码,发现目标 CPU 不在允许列表后放弃迁移。如果大量进程设置了严格的 CPU 亲和性,负载均衡器可能发现"所有任务都被钉住"(LBF_ALL_PINNED),最终只能向上层调度域报告 imbalance,等待父域来协调。这就是为什么某些将 Nginx worker 绑定到特定 CPU 的调优方案,在高负载下反而导致其他 CPU 空闲。
NUMA 架构下的性能陷阱。在 NUMA 系统上,进程分配的内存位于某个 NUMA 节点。如果负载均衡器将该进程迁移到另一个 NUMA 节点的 CPU 上,内存访问延迟会从 100ns 级别跳到 200-300ns 级别。内核的 migrate_degrades_locality() 函数专门检测这种情况:如果迁移会降低内存局部性,则拒绝迁移。这也是为什么在某些 NUMA 系统上,关闭自动 NUMA 均衡反而能获得更稳定的性能。
容器场景的多核利用。在 Kubernetes 等容器编排平台上,容器的 CPU limit 通过 cgroup 的 cpu.cfs_quota_us 实现。容器内的多个进程共享一个 CPU 配额池,但调度器不知道这些进程属于同一个容器。如果负载均衡器将容器内的所有进程分散到不同 NUMA 节点,容器整体的内存访问性能可能下降。另一方面,如果进程全部集中在少数 CPU 上,又无法充分利用多核。这是容器调度中一个尚未完全解决的难题。
总结
负载均衡是多核调度系统的核心难题,其设计哲学可以概括为三点:分层——用 sched_domain 映射硬件拓扑,减少全局决策复杂度;渐进——优先在低层级均衡,高层级兜底,避免过度迁移;保守——缓存亲和性优先,只有在收益显著大于成本时才迁移。
负载均衡的代码路径虽然长达数千行,但核心逻辑并不复杂:统计负载 → 找最忙的组 → 挑可迁移的任务 → 执行迁移。真正的难点在于各种边界情况和启发式规则,这些规则是二十多年内核社区在实际硬件上反复验证的结晶。
思考题:如果一台 64 核服务器上,16 个 CPU 绑定了 GPU 计算任务(严格亲和性),剩下的 48 个 CPU 如何处理通用负载?负载均衡器在这种情况下会如何表现?
延伸阅读:查看 kernel/sched/fair.c 中的 load_balance() 函数,重点关注 detach_tasks() 中的 loop_break 机制——为什么迁移过程要定期"喘口气"?
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处