自学编程第51课:爬虫入门——让Python帮你从网页“拿”数据
- 2026-07-01 07:59:10


学习完上一课打包,Tyree坐在电脑前发了一会儿呆,然后问我:
“互联网上有很多数据,那它们是怎么到我电脑里来的?我打开一个网页,它就在我屏幕上了。如果我想要网页上的某个信息,比如每天的温度,难道要每天手动复制粘贴吗?”
我说:“这就是爬虫要做的事。你写一段代码,让电脑自动打开网页、读取内容、提取你想要的信息,然后保存下来。你每天只需要运行这段代码,数据就自己来了。”
Tyree:“那我要学!”
今天的课程内容,我们先学爬虫的第一步:用 `requests` 库把网页内容“搬”到Python里。先学会“拿”,下一课再学“挑”。
01. 什么是爬虫?它合法吗?
爬虫,简单说就是“让电脑自动访问网页并提取信息的程序”。
你平时打开浏览器看网页,是“人”在操作;爬虫就是“程序”在模拟这个操作——向服务器发请求、接收网页内容。
合法性很重要:
✅ 可以爬取公开的、允许访问的网页数据(如天气、新闻、公开文章)。
❌ 不要爬取需要登录的页面、涉及隐私的数据。
❌ 不要频繁请求同一网站,建议每次请求间隔1秒以上。
❌ 不要用于商业用途或侵权用途。
总的来说:爬虫就像去图书馆看书,你可以摘抄公开的信息,但不能把整本书撕下来带走。
02. 安装 requests
同样在在命令行执行:
pip install requests
`requests` 是Python里最常用的HTTP请求库,它的作用就是“模拟浏览器向服务器要数据”。
03. 第一个爬虫:获取网页内容
我们先做最简单的:用`requests` 获取一个网页的HTML内容。
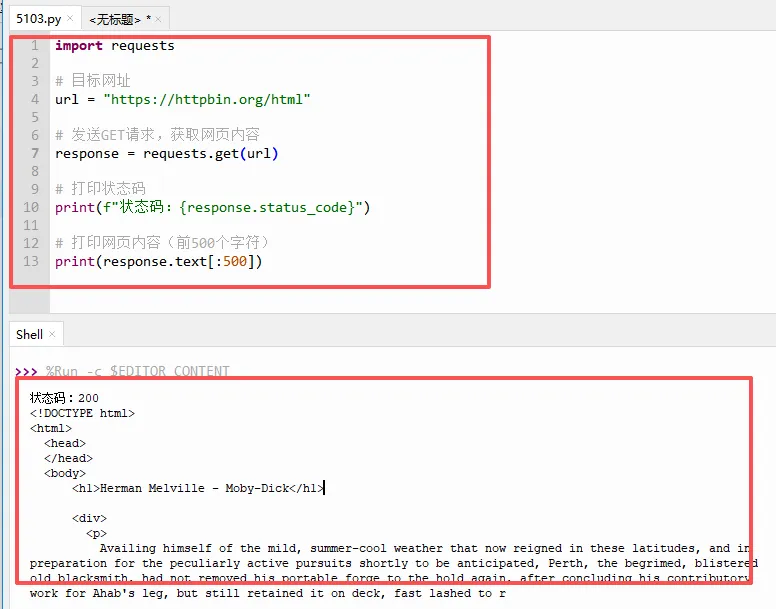
下面一起来看看代码解释:
`import requests`:导入requests库。
`requests.get(url)`:向指定的网址发送一个“GET”请求。浏览器打开网页时发的就是GET请求,告诉服务器“我想要这个页面的内容”。服务器收到后会把网页的HTML代码返回给你。
`response.status_code`:HTTP状态码。`200` 表示请求成功,`404` 表示页面不存在,`403` 表示没有权限访问,`500` 表示服务器出错了。
这是判断请求是否成功的第一道关卡。
`response.text`:服务器返回的HTML内容,也就是网页的源代码。你在浏览器里右键点击“查看网页源代码”看到的东西,就是它。
运行结果:你会看到一串HTML代码,如上图,那就是httpbin返回的测试页面。
Tyree看到打印出来的一大堆带尖括号的文字,说:“原来网页背后长这样啊!”
04. 设置编码,防止乱码
有些网页包含中文,如果不设置编码,打印出来可能是一堆乱码。
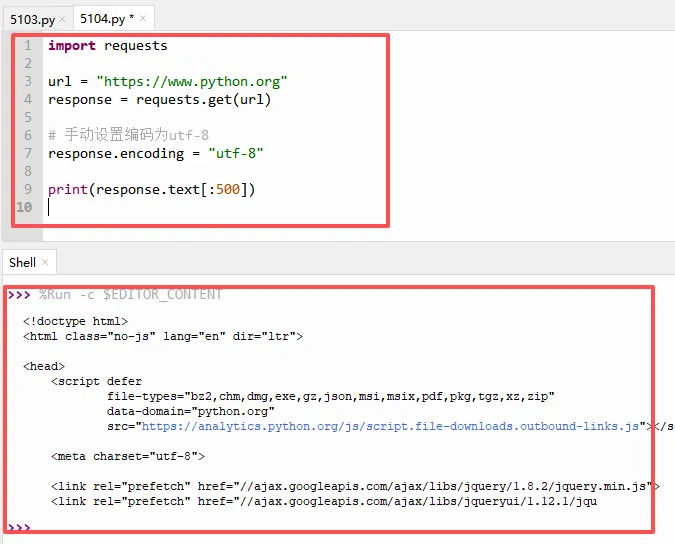
解释:`response.encoding = "utf-8"` 告诉Python用UTF-8解码网页内容。大多数中文网页都使用UTF-8编码,设置后中文就能正常显示了。
05. 处理请求失败的情况
有时候网络请求可能会失败(网站挂了、网断了、超时了),我们需要处理这些情况。
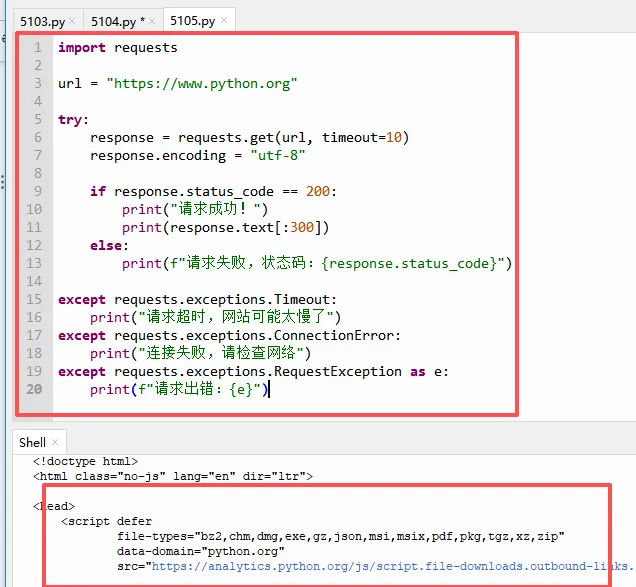
我们一起来看看代码解释:
`timeout=10`:设置超时时间为10秒。如果10秒内服务器没有响应,程序就会抛出 `Timeout` 异常,而不是卡住不动。
`try...except`:捕获并处理各种异常,让程序在出错时给出友好提示,而不是直接崩溃。
`requests.exceptions.Timeout`:请求超时时触发的异常。
`requests.exceptions.ConnectionError`:网络连接失败时触发的异常(比如没联网、网址不存在)。
`requests.exceptions.RequestException`:所有requests异常的父类,可以捕获上面所有子类以外的其他异常。
所以写爬虫时,养成加
`try...except` 和 `timeout` 的习惯,你的程序会稳很多。
06. 今天学到了什么
爬虫:让Python自动访问网页并获取数据。
`requests.get(url)`:向服务器发送请求,获取网页内容。
`response.status_code`:检查请求是否成功(200=成功)。
`response.text`:获取网页的HTML源代码。
`response.encoding = "utf-8"`:避免中文乱码。
`timeout`:防止程序卡死。
`try...except`:优雅地处理网络错误。
好了,第51课完成!
明天第51课:解析网页内容——用
BeautifulSoup从网页里“挑”出你想要的信息。
————热门推荐————
自学编程第7课:turtle画图入门(画正方形五角形三角形)
自学编程第一步:安装Python和Thonny(零基础图文教程)
(本系列教程每天更新,欢迎关注收藏)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python笔记15
- 第47天:深入 Linux 文件 I/O 基础——解锁 open/read/write 系统调用的底层奥秘
- Linux 实战:sed 命令 — 批量改文件不用打开编辑器
- Linux 用户管理运维的未来趋势——零信任架构、AI 智能治理与边缘计算实践
- Linux服务器跑Selenium报错?大概率是这个原因
- 用于开发的最佳 Linux 发行版
- CTF比赛入门第十二期:Linux基础与赛场提权入门
- 我见过太多服务器被黑,这份Linux安全加固脚本建议你直接抄走
- 容器新玩法 在Mac上原生运行Linux容器
- Python入门,10天就够了!这份笔记帮你把基础语法一次性焊在脑子里!
