时间片与调度粒度:为什么你的任务跑一会儿就停了?
Linux 调度子系统技术文档系列 · 第 11 篇
你是否有过这样的体验:一个编译任务跑着跑着突然停顿,接着另一个进程抢占上来;或者一个交互式应用在关键时刻卡顿了几毫秒,用户感知到了明显的延迟。你调了 nice 值、配了 cgroup 权重,但问题依然若隐若现。
问题的根源,往往藏在一个看似不起眼的参数里——时间片(time slice)。
在 EEVDF(Earliest Eligible Virtual Deadline First)调度器中,时间片是调度决策的基本原子单位。它决定了每个任务一次能运行多久、何时该让出 CPU、以及多个任务之间如何公平分配算力。Linux 内核的默认值是 0.7 毫秒——不是 1 毫秒,不是 0.1 毫秒,恰好 0.7 毫秒。这个数字背后,是十几年调度器演进留下的精确权衡。
本文将从源码层面追踪时间片的完整生命周期:从初始化赋值,到运行时递减,再到耗尽检测与重新调度。你会理解为什么你的任务"跑一会儿就停了"——这正是调度器在精确执行它的职责。
一、时间片到底是什么?有哪些核心参数?
时间片的本质是调度器分配给每个任务的一次性 CPU 使用配额。它不是绝对物理时间,而是经过权重加权后的虚拟时间(virtual time)增量。在 EEVDF 模型中,每个调度实体 sched_entity 都有自己的时间片配额,内核通过多个参数协同控制它。
核心参数一览:
| | | |
|---|
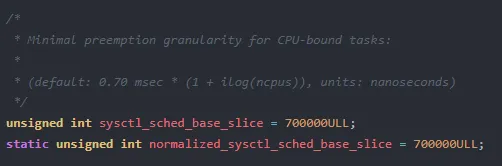
sysctl_sched_base_slice | | | |
se->slice | | | |
se->deadline | | | |
se->custom_slice | | | 是否设置了自定义时间片(sched_setattr) |
se->min_slice | | | |
cfs_rq_min_slice() | | | |
normalized_sysctl_sched_base_slice | | | |
这些参数不是孤立存在的,它们通过 EEVDF 的虚拟时间模型紧密耦合。理解它们的关系,是理解调度器行为的第一步。
为什么默认是 0.7 毫秒?
打开 fair.c:L75-80,答案写在内核注释里:
0.7 毫秒不是随意选取的。它经历了 CFS 时代的反复调优:
- 太小(0.1ms):上下文切换开销占比过高。每次切换涉及寄存器保存、TLB 刷新、缓存失效,成本约 1-3 微秒。如果时间片太短,CPU spends 大量时间在"切换"而非"执行"上,吞吐量断崖式下降。
- 太大(1ms+):交互式任务延迟显著增加。假设有 10 个任务轮流执行,每个 1ms,最后一个任务要等 9ms 才能运行。人类对 10ms 以上的延迟有感知,GUI 应用对 16.6ms(60fps 帧间隔)内的延迟极为敏感。
- 0.7ms 是甜点区:在典型负载下,它让上下文切换开销保持在 2-5% 以下,同时保证 10 个任务轮转一轮不超过 7ms,处于人类感知阈值之下。
为什么需要随 CPU 数量缩放?
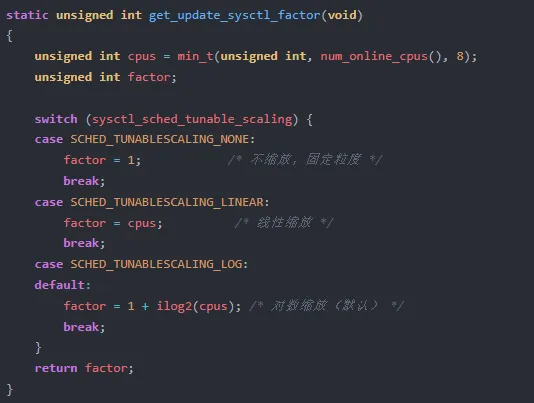
关键在 fair.c:L192-210 中的缩放因子:
默认采用对数缩放(SCHED_TUNABLESCALING_LOG),实际生效的时间片 = 0.7ms × (1 + ilog2(ncpus))。
为什么是对数而不是线性? 这是一个精妙的架构选择。想象一个 64 核服务器:
- 线性缩放:0.7ms × 64 = 44.8ms。最后一个任务等 44 核 × 44.8ms ≈ 2 秒,交互式体验崩溃。
- 对数缩放:0.7ms × (1 + 6) = 4.9ms。64 核下轮转一轮约 300ms,虽然也不理想,但比线性方案好一个数量级。
对数缩放的哲学是:核数增加时,调度粒度应该适度放宽,但不能线性增长。核数从 1 到 8 的变化比从 32 到 64 的变化更应该影响调度粒度,因为前者对单线程任务的影响更大。ilog2 恰好捕捉了这种边际递减效应。
二、EEVDF 中的 deadline 计算:slice 如何变成调度决策?
EEVDF 的核心公式 vd_i = ve_i + r_i / w_i 将时间片与调度优先级绑定在一起。让我们逐变量拆解:
- vd_i(virtual deadline)
- ve_i(virtual eligible time / vruntime)
- r_i(request time):请求时间,即
se->slice(默认 0.7ms) - w_i(weight):任务权重,由 nice 值映射而来(nice 0 = 1024)
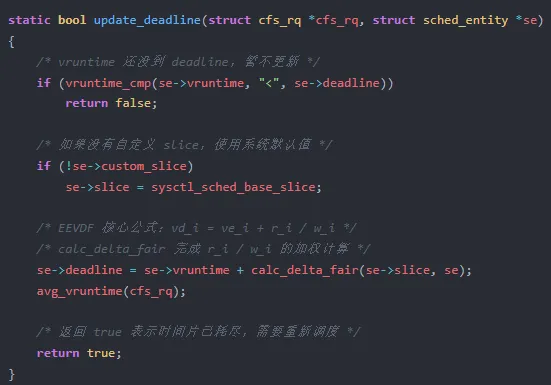
公式的直观含义:deadline = 当前 vruntime + (slice / weight 归一化系数)。权重越高(nice 值越低),deadline 增量越小,任务在红黑树中越靠左,越早被调度。
关键代码在 fair.c:L1117-1140:
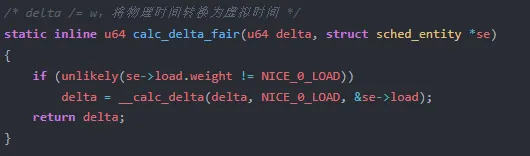
calc_delta_fair 是公式中 r_i / w_i 的具体实现(fair.c:L290-296):
当一个 nice 0 的任务(权重 1024)消耗 0.7ms 的物理时间,calc_delta_fair 返回 0.7ms,deadline = vruntime + 0.7ms。而一个 nice 5 的任务(权重 335)消耗同样的 0.7ms,calc_delta_fair 返回约 2.1ms——它的 deadline 增长更快,在红黑树中排得更靠右,优先级更低。
slice 和 deadline 的关系可以这样理解:slice 是"燃料",deadline 是"油表"。 燃料消耗完时,油表指向下一个截止点。调度器每次选择 deadline 最早的任务执行,确保高权重任务获得更多 CPU 份额。
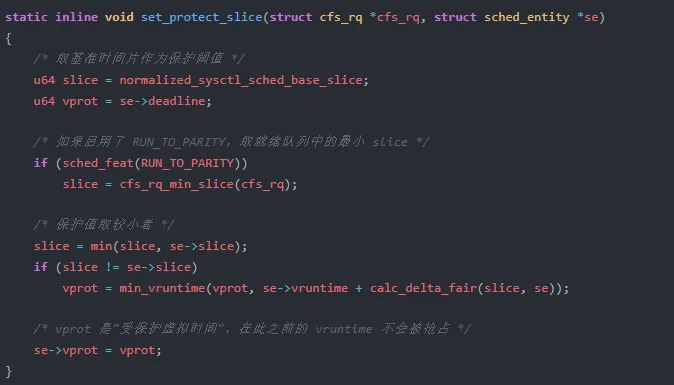
三、set_protect_slice 与 cfs_rq_min_slice:防止饿死的保护机制
在 EEVDF 中,有一个微妙的问题:如果一个任务的时间片还剩下一点点,而另一个任务的 deadline 更紧急,调度器是否应该立即切换?
如果每次 tick 都严格比较 deadline,那剩余 1 微秒时间片的任务可能被立刻踢下 CPU,造成"碎片化浪费"——它已经获得了调度开销,却没来得及做任何实际工作。
set_protect_slice 就是解决这个问题的保护机制(fair.c:L958-971):
这个机制的核心思想是:给当前任务一个最小保证运行窗口,在窗口内不执行抢占。这个窗口的大小取 min(基准时间片, 剩余时间片),确保即使时间片快耗尽,任务也至少能运行一个最小量子。
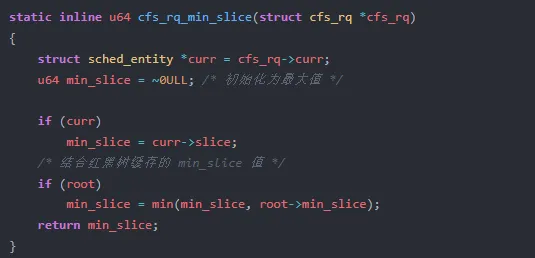
cfs_rq_min_slice() 遍历红黑树,找到就绪队列中所有任务的最小 slice 值(fair.c:L818-830):
min_slice 字段在每个 sched_entity 的红黑树节点中维护,通过 fair.c:L884-906 的回调函数在树结构变化时增量更新,避免了每次都遍历整棵树。
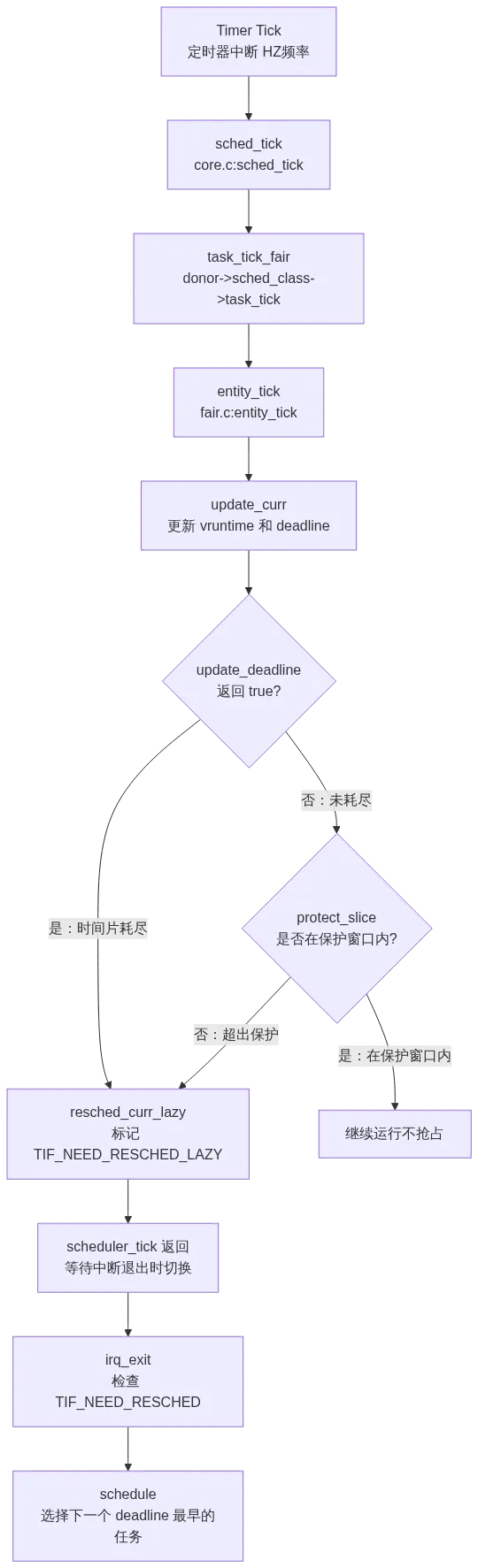
四、时间片耗尽的完整执行路径
理解了参数和机制,现在追踪一个任务从运行到被调度的完整生命周期。路径如下:
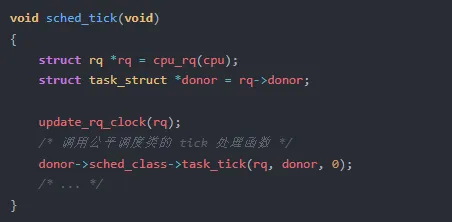
第一阶段:sched_tick 驱动
每个定时器中断(默认 HZ=250 或 1000,即每 4ms 或 1ms 一次),内核调用 core.c:L5515-5549 中的 sched_tick:
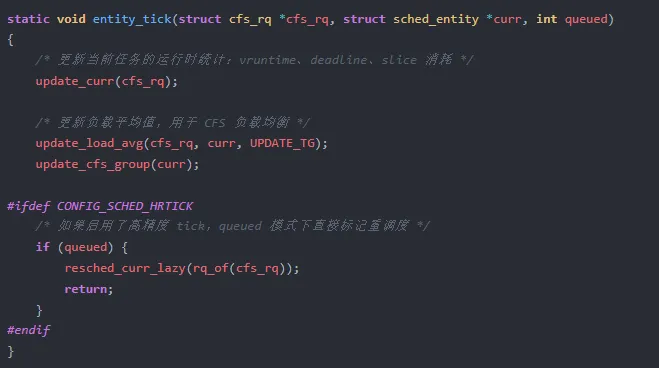
task_tick 最终调用到 entity_tick,这是时间片检测的入口。
第二阶段:entity_tick 更新运行时
fair.c:L5627-5650 是时间片检测的核心函数:
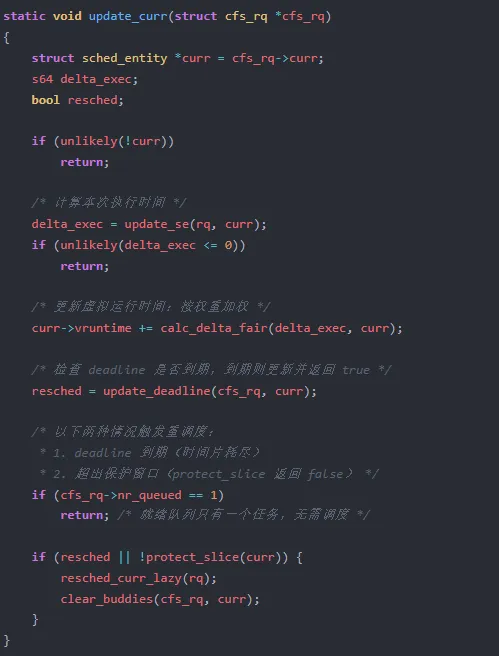
第三阶段:update_curr 判断是否需要重调度
真正的决策逻辑在 update_curr 中(fair.c:L1286-1332):
这里有两个触发重调度的条件:
resched == true:update_deadline 返回 true,表示 vruntime >= deadline,时间片已完全耗尽。!protect_slice(curr):当前任务的 vruntime 已超出保护窗口 vprot,即使时间片未完全耗尽,也应该让位给 deadline 更紧急的任务。
第四阶段:resched_curr_lazy 标记重调度
resched_curr_lazy 设置线程信息标志 TIF_NEED_RESCHED_LAZY。这个"lazy"版本是内核的优化:不立即触发 IPI(处理器间中断),而是等待当前中断退出或下次内核态返回用户态时再执行调度。这减少了不必要的中断风暴,在多核系统中显著降低了调度开销。
当系统需要立即调度时(如 HRTICK 高精度定时器到期),会使用 resched_curr 直接设置 TIF_NEED_RESCHED,强制下一次调度时机立刻到来。
五、用户空间视角:你能控制什么?
内核的时间片机制并非完全黑盒。用户空间可以通过多个途径影响调度行为。
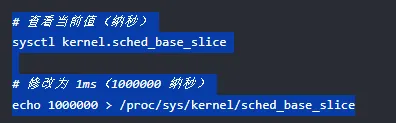
1. sysctl kernel.sched_base_slice
适用场景:
- 批处理服务器:增大到 2-5ms,减少上下文切换,提升吞吐量。适合编译、数据处理等 CPU 密集型任务。
- 桌面/交互系统:保持默认或略微减小到 0.5ms,降低交互延迟。适合 GUI 应用、游戏服务器。
- 实时性要求高的场景:不建议通过调整 slice 来满足实时需求,应使用
SCHED_FIFO 或 SCHED_DEADLINE 实时调度类。
2. cgroup cpu.weight 与时间片的关系
cgroup v2 的 cpu.weight 影响任务的权重 w_i,进而间接影响有效时间片:
权重为 200 的任务相对于权重 100 的任务,在相同时间内能获得约 2 倍的 CPU 份额。但这不是因为它的时间片变大了——se->slice 仍然是 0.7ms——而是因为它的 deadline 增长更慢(calc_delta_fair 中除以更大的权重),在红黑树中更靠前,被选中的频率更高。
类比:时间片是"每次上车能坐多久",权重是"排队的优先级"。权重高不代表坐得更久,只代表上车更频繁。
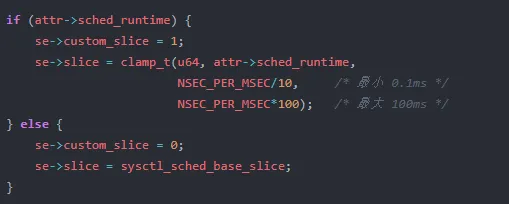
3. sched_setattr 自定义时间片
通过 sched_setattr 系统调用,可以为特定任务设置自定义时间片:
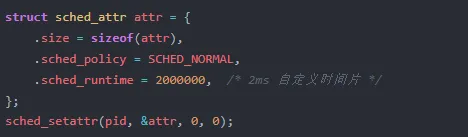
这对应源码中 fair.c:L5196-5204 的逻辑:
内核限制了自定义时间片的范围:0.1ms 到 100ms。太小的值会导致调度抖动,太大的值会破坏系统的公平性。
4. 吞吐量 vs 延迟的权衡矩阵
六、架构要点总结
时间片机制是 EEVDF 调度器的节拍器,它用 0.7 毫秒的粒度丈量着每个任务的 CPU 使用量。理解它,就理解了调度器的大部分行为。
核心要点:
- 0.7ms 是吞吐量和延迟的甜点值
- 对数缩放因子
1 + ilog2(ncpus) 让调度粒度在多核系统中适度放宽,避免核数增长导致调度延迟线性恶化 update_deadline 中的 vd_i = ve_i + r_i / w_i 是 EEVDF 的灵魂:slice 通过权重加权后变成 deadline,deadline 决定红黑树排序,红黑树排序决定谁先执行set_protect_slice 防止碎片化抢占update_curr 中的双重判断(deadline 到期 || 超出保护窗口)覆盖了所有需要重调度的场景- 用户空间可以通过 sysctl、cgroup weight、sched_setattr 三个层次干预
下次当你看到任务"跑一会儿就停了",不要急着调优——这可能正是调度器在忠实地执行它的职责:在精确的时间片耗尽后,把 CPU 让给下一个更需要的任务。
互动问题:你的生产环境中,有没有遇到过因为时间片设置不当导致的性能问题?是批处理任务被频繁打断,还是交互式任务响应延迟过高?欢迎在评论区分享你的经验和调优参数。
本系列文章基于 Linux 6.19.13 内核源码采用 CC BY-NC-SA 4.0 协议,转载请注明出处