Python大佬手把手教你如何自制小说下载器
- 2026-07-01 19:00:01
点击上方“IT共享之家”,进行关注
回复“资料”可获赠IT学习福利
今天说的这个小说下载器是之前一个小姐姐要我帮她做的,感觉还不错,就来做个demo。(本文使用python2.7)
这个网站(https://www.po18.tw/site/alarm)必须要先登录才能进行搜索与小说的阅读,所以第一步就是模拟登录(https://members.po18.tw/apps/login.php)。
它的密码部分是没有加密的,属于最简单的登录,而且没有验证码,非常的贴心~~~比较适合模拟登录入门训练。
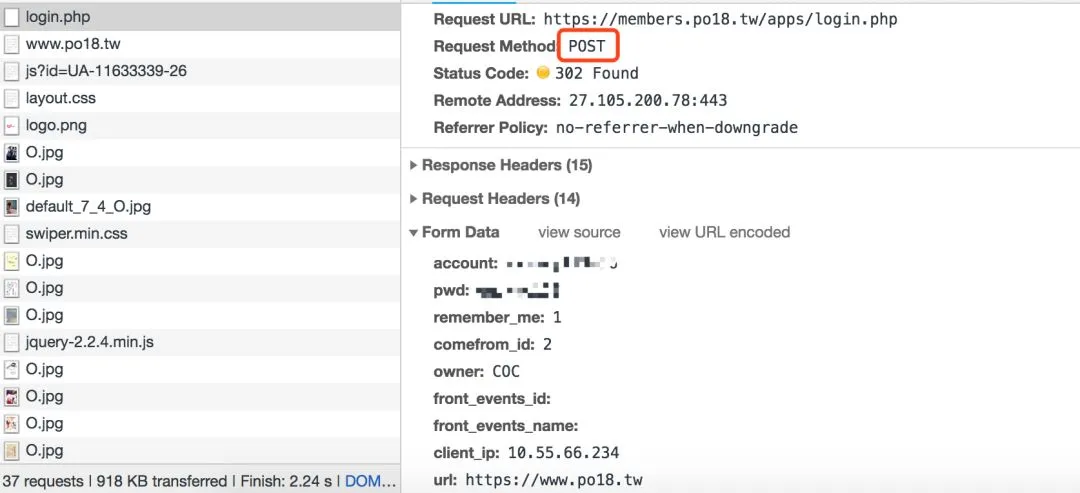
进行小说的搜索和阅读时,需要有登录信息,所以要用requests.session()保持对话。当登录成功时,url会变成网站的主页面(https://www.po18.tw);反之登录失败的话url会返回网站的登录页(https://members.po18.tw/apps/login.php)。请求时设置了响应时间,self.wait_time,当请求超时或ConnectionError时,重新登录,直到登录成功。
def login(self):try:headers = {'Connection': "keep-alive",'Pragma': "no-cache",'Cache-Control': "no-cache",'Origin': "https://members.po18.tw",'Upgrade-Insecure-Requests': "1",'Content-Type': "application/x-www-form-urlencoded",'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",'Referer': "https://members.po18.tw/apps/login.php",'Accept-Encoding': "gzip, deflate, br",'Accept-Language': "zh-CN,zh;q=0.9",'cache-control': "no-cache",'Postman-Token': "9e794009-96a6-4d22-be14-4b128cd7bd41"}account = raw_input(u"请输入账号:").decode(sys.stdin.encoding)pwd = raw_input(u"请输入密码:").decode(sys.stdin.encoding)data = {'account': account,'pwd': pwd,'remember_me': '1','comefrom_id': '2','owner': 'COC','front_events_id': '','front_events_name': '','client_ip': '10.55.66.233','url': 'https://www.po18.tw'}login_url = 'https://members.po18.tw/apps/login.php'login_html = self.session.post(login_url, data=data,timeout=self.wait_time,headers=headers)if login_html.url == 'https://members.po18.tw/apps/login.php':print'账号或密码错误,请重新输入'self.login()elif login_html.url == 'https://www.po18.tw':print'登陆成功'else:print'---error---'except requests.exceptions.ConnectionError:print'ConnectionError,请重新登陆'self.login()except requests.exceptions.ReadTimeout or RuntimeError:print'登陆超时,重新登陆'self.login()
提示登录成功后,就可以进行小说的搜索(以关键词:迟早为例)。
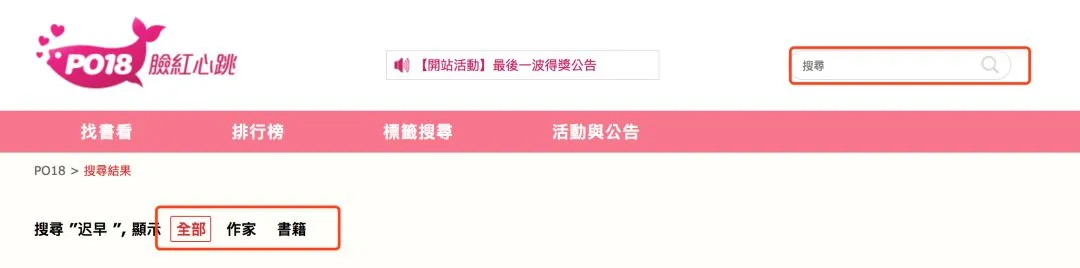
在搜索页面输入的关键词有三种类型,分别为全部/作家/书籍:映射关系如下:
search_type = {'全部': 'all','作家': 'author','书籍': 'book'}
仅搜索作者时,searchtype==‘author’;仅搜索相关书籍时,searchtype==‘book’;两者都要时,searchtype==‘all’。这里默认为all。
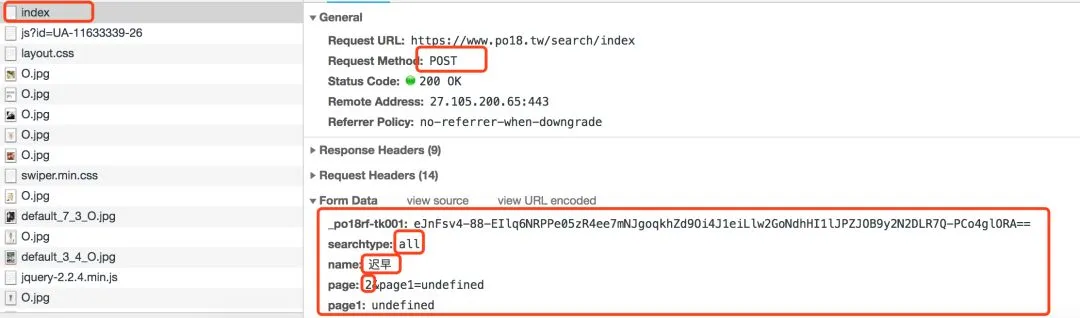
输入关键词(迟早)后,会有两组结果:
关于作者部分,有显示作家笔名,以及简介。为了获得该作者的系列小说,需要进入作者主页查看。

try:author = soup.find('div', attrs={'id': "AUTHOR"}).find('h2').textauthor_inf = soup.find_all('div', class_='author_info')for i in range(len(author_inf)):name = author_inf[i].find('div', class_='author_name').find('a').textdes = author_inf[i].find('dd', class_='about_author').textauthor_url = 'https://www.po18.tw' + author_inf[i].find('div', class_='author_name').find('a').get('href')result = self.get_author_book(name, author_url)printu"作者姓名: " + nameprintu"作者简介: " + destry:for j in result:printu'该作者的系列小说: ' + j[0] + ' ' + u'简介: ' + j[1]book_dict[j[0]] = j[2]except TypeError:passexcept AttributeError:k = k + 1#print 'k: ', kprint soup.find('div', attrs={'id': "AUTHOR"}).text
进入作者页面后,可以看到该作者的系列小说,我们需要返回书名以及该书的简介:

defget_author_book(self,author_name,author_url):#print author_urltry:headers = {'Host': 'www.po18.tw','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}result = []html = self.session.get(author_url, headers=headers,timeout=self.wait_time).textsoup = BeautifulSoup(html, 'lxml')for i in soup.find('div', class_='work_list').find_all('div', class_='book_info'):one_result = []book_name1 = i.find('div', class_='book_name').find('a').textdes1 = i.find('dd', class_='intro').textbook_url1 = i.find('div', class_='book_name').find('a').get('href') + '/articles'print book_url1one_result.append(book_name1)one_result.append(des1)one_result.append(book_url1)result.append(one_result)return resultexcept requests.exceptions.ConnectionError:self.get_author_book(author_name,author_url)print '重新获得%s的系列书籍'%author_name.encode('utf-8')except requests.exceptions.ReadTimeout orRuntimeError:self.get_author_book(author_name, author_url)print '搜索超时,重新搜索中......'
最后返回的结果如下:

关于书籍部分,就要比作者部分简单很多,只需要定位得到每本书籍的链接;书名以及简介,就可以print跟关键词相关的所有书籍及其简介。

try:book = soup.find('div', attrs={'id': "BOOK"}).find('h2').textbook_inf = soup.find_all('div', class_='book_info')for i in range(len(book_inf)):book_name = book_inf[i].find('div', class_='book_name').find('a').textbook_author = book_inf[i].find('div', class_='book_author').find('a').textdes = book_inf[i].find('div', class_='intro').textbook_dict[book_name] = 'https://www.po18.tw' + book_inf[i].find('div', class_='book_name').find('a').get('href') + '/articles'printu"书名: " + book_nameprintu"作者: " + book_authorprintu"简介: " + desexcept AttributeError:k = k + 1#print 'k: ', kprint soup.find('div', attrs={'id': 'BOOK'}).text
最后返回一个字典:{书名:链接}。方便下一步选择小说进行下载。
但是存在两种特殊情况:第一种是输入的关键词既搜不到作者,也搜不到相关书籍;此时需要重新输入关键词。
效果如下:
请输入关键字:python~~~~~~~~~~~~~~~~~无法找到相关内容!请重新搜索!~~~~~~~~~~~~~~~~~请输入关键字:java~~~~~~~~~~~~~~~~~无法找到相关内容!请重新搜索!~~~~~~~~~~~~~~~~~
第二种是关于关键词的返回结果非常多,这里设置仅返回前两页的内容,设置一个search_page为当前页面数;
total_page=2search_page=1while search_page<total_page:ta = {'_po18rf-tk001': '_B3ubdEpdkVZeUlR2-l2rOa5FnjITrQBy1yzk9NYQoKNUcNUuBoDKgo6D2aL3k-ekNUjJ4sj-laZLue-piw26A==','name': search_name,'searchtype': 'all','page': str(search_page).decode('utf-8') + '&page1=undefined','page1': 'undefined'}html = self.session.post(url, data=data, headers=headers, timeout=self.wait_time).text# print htmlsoup = BeautifulSoup(html, 'lxml')try:v = int(soup.find('div', class_='result_list', attrs={'id': "BOOK"}).find('h2').find('span').text)if v % 10 == 0:total_page = v / 10else:total_page = v/10 + 2if total_page>3:total_page=3except:print'~~~~~~~~~~~~~~~~~'print'无法找到相关内容!'print'请重新搜索!'print'~~~~~~~~~~~~~~~~~'self.search()
最后return回一个字典类参数,key是书本名,value是改书本的url。比如输入关键词(迟早)后返回于迟早相关的所有书籍名和其相应的书籍链接;以及相关作者的所有系列书籍和链接:
{u'宿命': 'https://www.po18.tw/books/527881/articles', u'快穿之为入穹顶': 'https://www.po18.tw/books/558233/articles', u'xx要趁早': 'https://www.po18.tw/books/538222/articles', u'罂粟(NPH)': 'https://www.po18.tw/books/665523/articles', u'莲花梦迟': 'https://www.po18.tw/books/203355/articles', u'(女变男)快穿渣男的死亡姿势': 'https://www.po18.tw/books/639590/articles', u'天作之合【高H,简】': 'https://www.po18.tw/books/585425/articles', u'迟到的爱情': 'https://www.po18.tw/books/567516/articles', u'黎明向晚': 'https://www.po18.tw/books/657155/articles', u'[快穿]系统,这锅我不背!': 'https://www.po18.tw/books/642849/articles', u'快穿之精液收集系统': 'https://www.po18.tw/books/621188/articles', u'离歌不散(H 简繁)': 'https://www.po18.tw/books/640195/articles', u'还债(1V1/H)': 'https://www.po18.tw/books/673401/articles', u'报应': 'https://www.po18.tw/books/646584/articles', u'快穿游戏用性来拯救低欲望': 'https://www.po18.tw/books/658652/articles', u'迟早(限)': 'https://www.po18.tw/books/666331/articles', u'迟暮央央': 'https://www.po18.tw/books/571399/articles', u'影后媳妇养成记gl(NP)': 'https://www.po18.tw/books/552827/articles', u'他的小阴谋家': 'https://www.po18.tw/books/671472/articles', u'迟暮西沉【H】': 'https://www.po18.tw/books/664991/articles', u'女王陛下今天技术好一点了吗': 'https://www.po18.tw/books/667909/articles', u'黑皇后(H)': 'https://www.po18.tw/books/557724/articles', u'蓮花夢遲【繁】': 'https://www.po18.tw/books/570932/articles', u'我知道你迟早是我的(h)': 'https://www.po18.tw/books/670242/articles', u'柠.迟': 'https://www.po18.tw/books/614132/articles', u'【短篇rou】阿萌和爷爷的爱爱': 'https://www.po18.tw/books/656135/articles', u'[ow同人]肥水不流外人田': 'https://www.po18.tw/books/667808/articles', u'询迟': 'https://www.po18.tw/books/670528/articles', u'(西幻)干掉勇者的一百种方法': 'https://www.po18.tw/books/668725/articles', u'意何迟迟': 'https://www.po18.tw/books/658095/articles', u'【快穿】情不自矜': 'https://www.po18.tw/books/570989/articles'}现在就可以下载你想要下载的书籍啦,这里选(迟到的爱情)这本书。
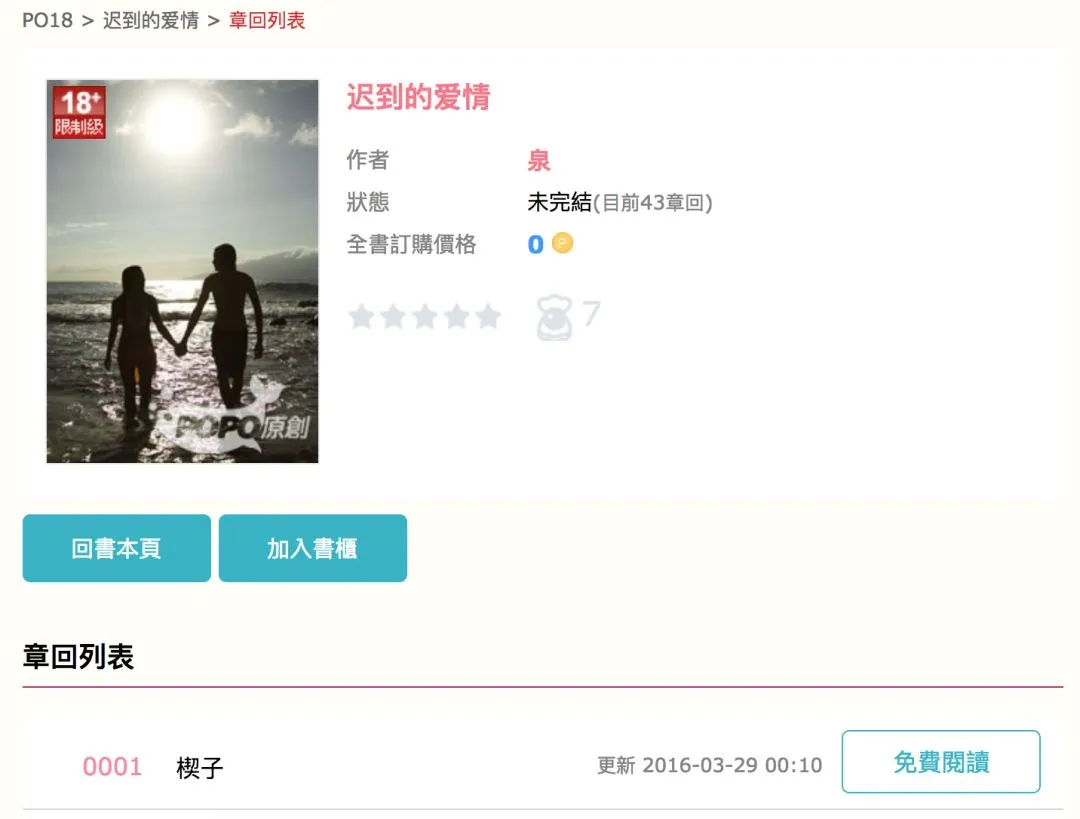
有时候我们并不想从头开始下载,所以在下载前设定一个起始章节:当输入all时,表示下载全部章节;当输入5时,代表从0005章节开始下载,page为1;当输入100时,代表从0100章节开始下载,page为1。
defpages_cha(self):cha_num = raw_input('请输入章节序号:').decode(sys.stdin.encoding)if cha_num == u'all':pages = 1cha_num = 0elif int(cha_num) / 100 == 0and int(cha_num) >= 100:pages = int(cha_num) / 100cha_num = int(cha_num)else:pages = int(cha_num) / 100 + 1cha_num = int(cha_num)return pages,cha_num
效果如下:

当你输入的章节序号大于小说的章节序号时,会提示你一共多少章,并要求重新输入章节序号。
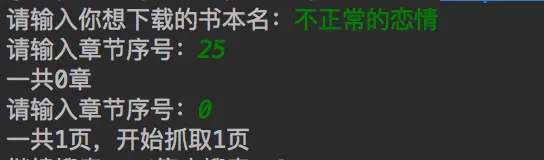
输入关键词以后就开始下载小说了,这个网页的小说章节有三种情况:第一种是不要钱就可以看的免费章节,它的Botton是蓝色的’免費閱讀‘;第二种是已经购买的章节,它的Botton是蓝色的‘閱讀’;第三种是付费为购买的章节,它的Botton是红色的;所以根据class_='btn_L_blue'或者class_='btn_L_red'来判断该章节能否下载。如果该章节可以被下载,在<a>标签内有这一章节的url。
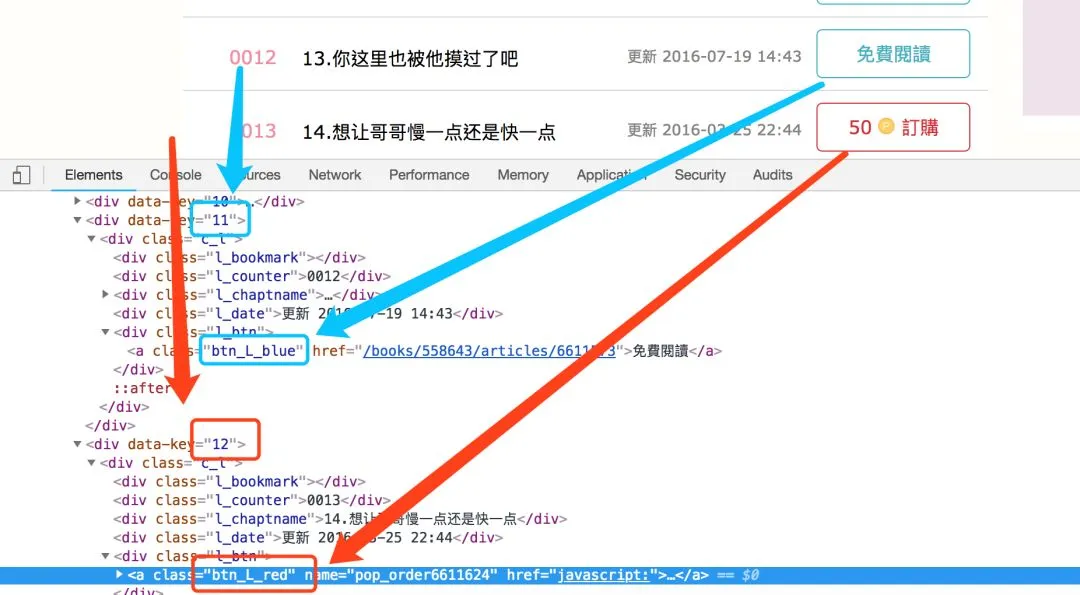
将获得的url在新窗口打开,虽然可以看到小说的内容,但是却无法选中,因为小说的内容根本就不在这个网页的源代码中。
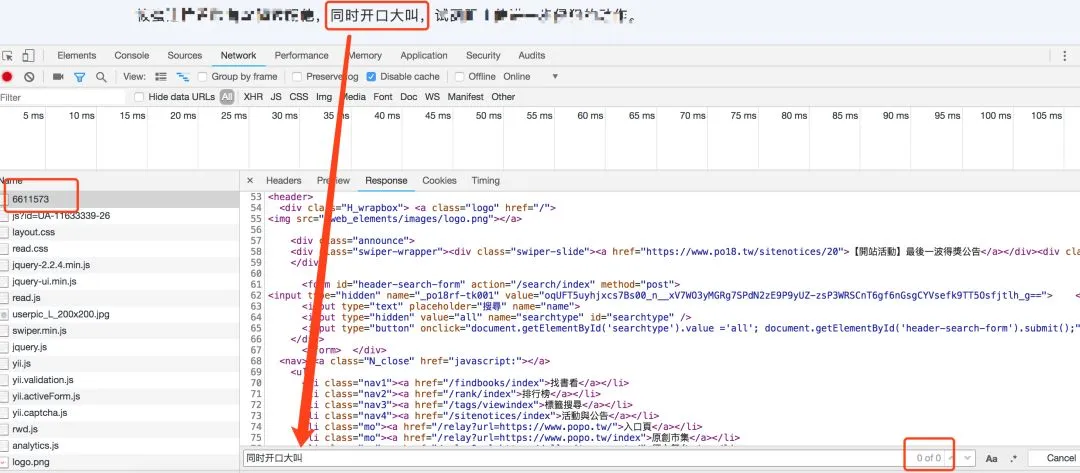
全局搜索后发现在另外一个类似的网页中:
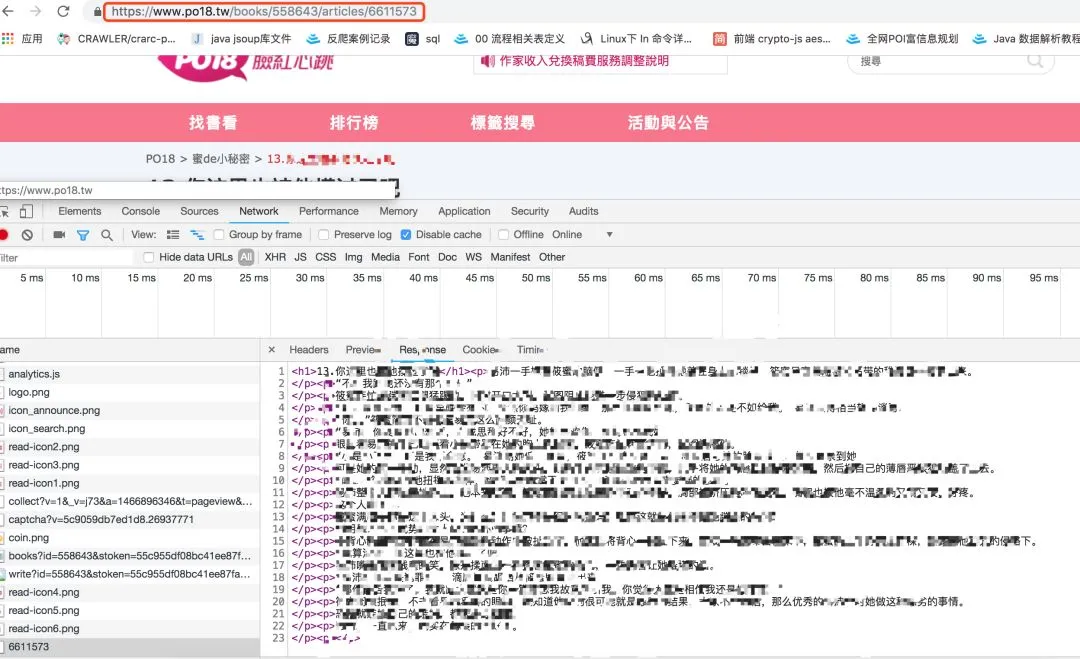
想要获得这个网页的内容有两个非常重要的request headers。一个是referer必须是该章节小说的url,(必须保持一致,否则无法获得内容);另外一个是cookie;比如判断该收费章节能否下载就是通过cookie。
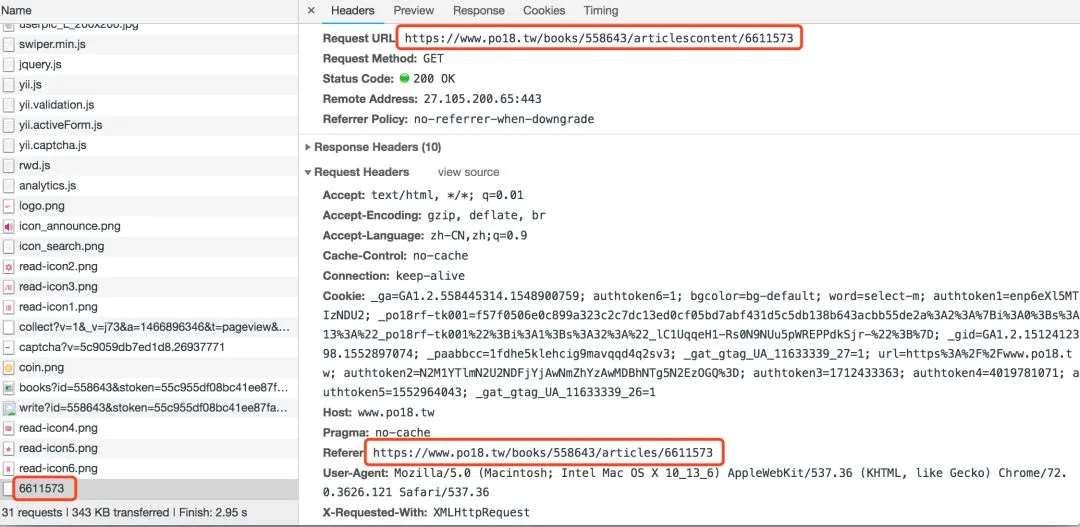
在下载中发现,每次下载都只能下载部分章节,有一些章节会返回空值,所以加入一个全局变量nu=10:若该章节返回空值,则一直发送请求,直至获得章节内容,这个操作超过10次的话就放弃下载该章节的内容;经测试当nu为10时所有可下载的章节内容都可以成功获得。
def chapter_content(self,chapterurl,title,type,nu):try:url = chapterurl.replace("articles", "articlescontent")if u'免費閱讀'==type:coo=["authToken=2ulk99qiju6q1auq1t9u0jrs14; _ga=GA1.2.327249816.1548928435; _gid=GA1.2.368859719.1548928435; url=https%3A%2F%2Fwww.po18.tw; authtoken1=enp6eXl5MTIzNDU2; authtoken2=MjdmY2ZiMzE0ZjM3NzYzMzY2Yzk2Y2E2OGEwNDQzMTk%3D; authtoken3=1712433363; authtoken4=3697529318; authtoken5=1548928452; authtoken6=1; _po18rf-token=f19fb4bd5947e47a8ad4bc29a70ceb8720a7e133bfcb51b47870adb7f92c5aa8a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_po18rf-token%22%3Bi%3A1%3Bs%3A32%3A%22-NbZMI2Mozyxj_X012cQtSSc-sRRNDhz%22%3B%7D; _gat_gtag_UA_11633339_26=1; bgcolor=bg-default; word=select-m",'authToken=nb5tvum3gg5aq7cl4umdtgr524; _po18rf-token=20985fb4cc41d9fdeeb2781aae404bf30d882c4681a7fa2df32cc70ee00d3788a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_po18rf-token%22%3Bi%3A1%3Bs%3A32%3A%22JTET5c8V4-1vkmSYMD9Cdor2d9iG3OxP%22%3B%7D; _ga=GA1.2.558445314.1548900759; _gid=GA1.2.1735490823.1548900759; authtoken1=enp6eXl5MTIzNDU2; authtoken6=1; bgcolor=bg-default; word=select-m; url=https%3A%2F%2Fwww.po18.tw%2Fbooks%2F661373%2Farticles%2F7574637; authtoken2=Y2VlOGI4YjFlY2E4ZjAzNGMxMDQ3MTgwMjIxZTNhNzA%3D; authtoken3=1712433363; authtoken4=233406403; authtoken5=1548989298; _gat_gtag_UA_11633339_26=1',"authToken=nb5tvum3gg5aq7cl4umdtgr524; _po18rf-token=20985fb4cc41d9fdeeb2781aae404bf30d882c4681a7fa2df32cc70ee00d3788a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_po18rf-token%22%3Bi%3A1%3Bs%3A32%3A%22JTET5c8V4-1vkmSYMD9Cdor2d9iG3OxP%22%3B%7D; _ga=GA1.2.558445314.1548900759; _gid=GA1.2.1735490823.1548900759; authtoken6=1; bgcolor=bg-default; word=select-m; po18Limit=6d4c449fc3268973f92df90aad9af59af0885074fe02e29be9cf3d42d091ec89a%3A2%3A%7Bi%3A0%3Bs%3A9%3A%22po18Limit%22%3Bi%3A1%3Bs%3A1%3A%221%22%3B%7D; url=https%3A%2F%2Fwww.po18.tw%2F; authtoken1=bHVvbHVvMTM3MTQy; authtoken2=ZGI5NjQ5ZDdmMzZmODliM2Q2MTM0Y2FhZDBkOTA1Y2M%3D; authtoken3=3355602036; authtoken4=889142853; authtoken5=1549008835; _gat_gtag_UA_11633339_26=1"]headers = {'Referer': chapterurl,'Cookie': random.choice(coo)}elif u'閱讀'==type:cookie=['authToken=nb5tvum3gg5aq7cl4umdtgr524; _po18rf-token=20985fb4cc41d9fdeeb2781aae404bf30d882c4681a7fa2df32cc70ee00d3788a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_po18rf-token%22%3Bi%3A1%3Bs%3A32%3A%22JTET5c8V4-1vkmSYMD9Cdor2d9iG3OxP%22%3B%7D; _ga=GA1.2.558445314.1548900759; _gid=GA1.2.1735490823.1548900759; authtoken6=1; bgcolor=bg-default; word=select-m; po18Limit=6d4c449fc3268973f92df90aad9af59af0885074fe02e29be9cf3d42d091ec89a%3A2%3A%7Bi%3A0%3Bs%3A9%3A%22po18Limit%22%3Bi%3A1%3Bs%3A1%3A%221%22%3B%7D; url=https%3A%2F%2Fwww.po18.tw%2F; authtoken1=bHVvbHVvMTM3MTQy; authtoken2=ZGI5NjQ5ZDdmMzZmODliM2Q2MTM0Y2FhZDBkOTA1Y2M%3D; authtoken3=3355602036; authtoken4=889142853; authtoken5=1549008835; _gat_gtag_UA_11633339_26=1','authToken=nb5tvum3gg5aq7cl4umdtgr524; _po18rf-token=20985fb4cc41d9fdeeb2781aae404bf30d882c4681a7fa2df32cc70ee00d3788a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_po18rf-token%22%3Bi%3A1%3Bs%3A32%3A%22JTET5c8V4-1vkmSYMD9Cdor2d9iG3OxP%22%3B%7D; _ga=GA1.2.558445314.1548900759; _gid=GA1.2.1735490823.1548900759; authtoken6=1; bgcolor=bg-default; word=select-m; po18Limit=6d4c449fc3268973f92df90aad9af59af0885074fe02e29be9cf3d42d091ec89a%3A2%3A%7Bi%3A0%3Bs%3A9%3A%22po18Limit%22%3Bi%3A1%3Bs%3A1%3A%221%22%3B%7D; url=https%3A%2F%2Fwww.po18.tw%2F; authtoken1=bHVvbHVvMTM3MTQy; authtoken2=ZGI5NjQ5ZDdmMzZmODliM2Q2MTM0Y2FhZDBkOTA1Y2M%3D; authtoken3=3355602036; authtoken4=889142853; authtoken5=1549008835; _gat_gtag_UA_11633339_26=','authToken=nb5tvum3gg5aq7cl4umdtgr524; _po18rf-token=20985fb4cc41d9fdeeb2781aae404bf30d882c4681a7fa2df32cc70ee00d3788a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_po18rf-token%22%3Bi%3A1%3Bs%3A32%3A%22JTET5c8V4-1vkmSYMD9Cdor2d9iG3OxP%22%3B%7D; _ga=GA1.2.558445314.1548900759; _gid=GA1.2.1735490823.1548900759; authtoken6=1; bgcolor=bg-default; word=select-m; po18Limit=6d4c449fc3268973f92df90aad9af59af0885074fe02e29be9cf3d42d091ec89a%3A2%3A%7Bi%3A0%3Bs%3A9%3A%22po18Limit%22%3Bi%3A1%3Bs%3A1%3A%221%22%3B%7D; url=https%3A%2F%2Fwww.po18.tw%2F; authtoken1=bHVvbHVvMTM3MTQy; authtoken2=ZGI5NjQ5ZDdmMzZmODliM2Q2MTM0Y2FhZDBkOTA1Y2M%3D; authtoken3=3355602036; authtoken4=889142853; authtoken5=1549008835; _gat_gtag_UA_11633339_26=1']headers = {'Referer': chapterurl,'Cookie':random.choice(cookie)}response = self.session.get(url, headers=headers,timeout=self.wait_time)chp_con = response.text.replace(" ", '')soup = BeautifulSoup(chp_con, 'lxml')if len(soup.find_all('p'))<10:nu = nu - 1print'---error---,%s开始第%d次下载'%(title.encode('utf-8'),11-nu)chp_con=self.chapter_content(chapterurl, title, type,nu)if nu:passreturn chp_conexcept requests.exceptions.ConnectionError :print'重新下载%s' % title.encode('utf-8')self.chapter_content(chapterurl,title,type,nu)except requests.exceptions.ReadTimeout or RuntimeError:print '请求超时,请重新下载%s' % title.encode('utf-8')self.chapter_content(chapterurl,title,type,nu)
下载完一章就会print 下载完毕;如果某一章一直返回空值,则会显示:'---error---,%s开始第%d次下载'。
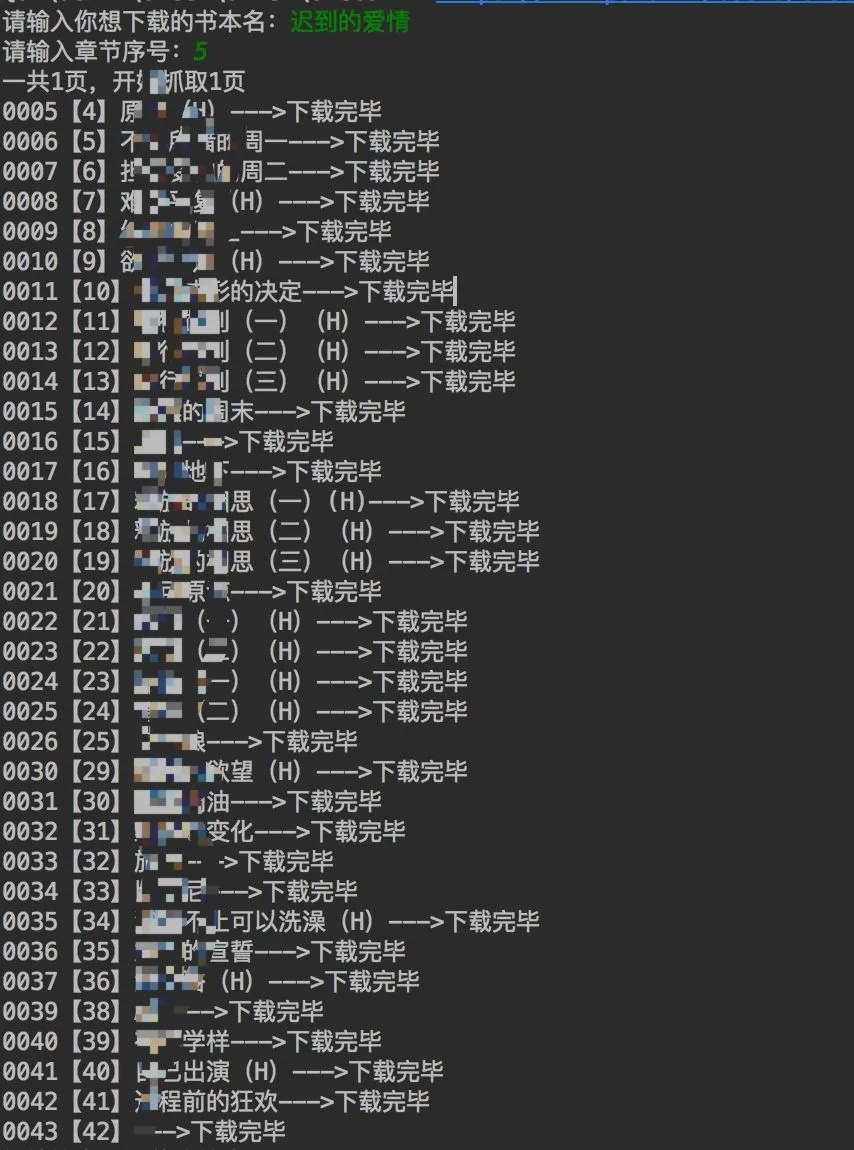
下载完以后就可以在本地看啦。
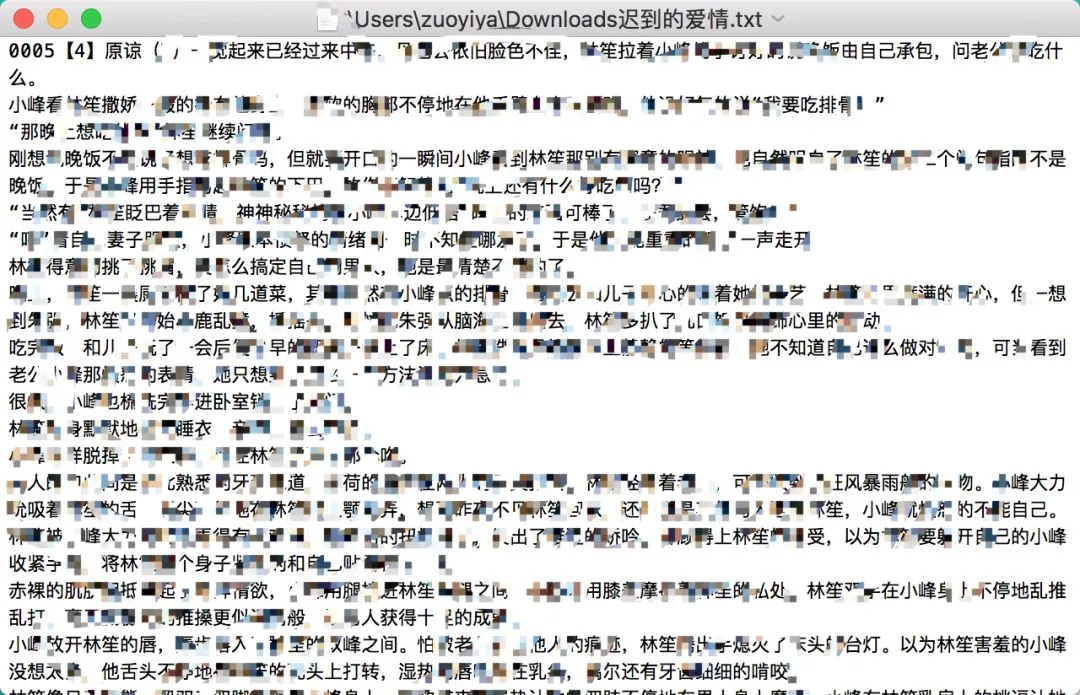
在下载完一本后,你可以选择是否要继续下载,如果希望继续搜索则输入1;否则输入0。停止搜索:

继续搜索:
到这就全部说完啦,小伙伴是不是迫不及待的想去做一个属于自己的小说下载器呢~~~
--------------------- End ---------------------
往期精彩文章推荐:
网络爬虫过程中5种网页去重方法简要介绍
【推荐】一个网站,解决你的论文下载、论文查重还有...
手把手教你抓取微博火锅信息Top3——火锅只能点三样
手把手教你用Fiddler+MongoDB抓取猫眼APP短评
Python大佬抓取房价信息带你开展多维度分析深圳房租
Python数据可视化:2018年电影分析
看完本文有收获?请转发分享给更多的人
入群请在微信后台回复【学习】
在公众号后台回复下列关键词可以免费获取相应的学习资料:
Python3、Python基础、Python进阶、网络爬虫 、书籍、
自然语言处理、数据分析、机器学习、数据结构、
大数据、服务器、Spark、Redis、C++、C、
php、mysql、java、Android、其
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Debian Linux 26.06 汇总!
- Linux 终端家谱:从40年前的"老祖宗"到今天的GPU战场,一个不将就的世界
- 搭建Linux虚拟机
- Linux 用户管理运维最佳实践汇总、跨平台混合环境集成与长期运维策略
- Linux是实时系统吗
- Linux安全检查与应急响应一键脚本:这款工具让运维工程师彻底告别手动排查时代
- 从零搞懂 Linux 防火墙:iptables 核心原理与实战配置全攻略
- Linux 进程管理实战SSH 一断程序就没了?三个命令解决这个烦恼
- Linux 为什么说「一切皆文件」?从重定向到文件操作,一次讲透
- 008 Linux怎么删除文件和目录?rm命令详解与避坑指南(可以有后悔药)
