Linux常用命令
切换用户
在 CentOS(以及其他基于Linux的操作系统)中,你可以使用 su 命令切换用户。su 是 "switch user"(切换用户)的缩写。su -
输入上述命令后,系统会要求你输入 root 用户的密码。如果密码正确,你就会切换到超级用户。su - username
将 username 替换为你要切换到的用户名。同样,系统会要求输入该用户的密码。注意,在切换用户时,使用 - 选项是一个好的实践,因为它会加载新用户的环境变量,确保你在新用户下执行的命令使用正确的配置和路径。如果你只是想在当前会话下切换到另一个用户而不切换到该用户的环境变量,你可以使用不带 - 选项的 su 命令:
su username
无论切换到哪个用户,确保在完成任务后使用 exit 命令退出该用户,返回到原来的用户。显示当前工作目录
在CentOS(或任何基于Linux的操作系统)中,pwd 是一个用于显示当前工作目录(Present Working Directory)的命令。它会输出当前你所在的文件系统路径。例如,如果你打开终端并输入:
pwd
然后按下回车键,终端会显示你当前所在的目录的完整路径,类似于:/home/your_username
这是你当前工作的目录。pwd 缩写自 "print working directory",通过执行这个命令,你可以随时查看你当前所处的文件系统路径,这在导航文件系统时非常有用。显示当前目录下的文件
删除文件夹
在CentOS中,你可以使用rm命令删除文件夹。但要小心,删除文件夹时请确保你不会误删重要数据,因为该操作是不可逆的。以下是删除文件夹的命令:
rm -r 目录路径
其中,-r选项表示递归删除,用于删除目录及其下的所有文件和子目录。请将"目录路径"替换为你要删除的实际目录路径。例如,如果要删除名为"my_folder"的目录,可以执行以下命令:
rm -r my_folder
确保在执行删除操作之前仔细检查目录路径,以避免误删除或删除重要数据。新建文件夹命令
mkdir -p /home/hadoop/data/tomcat/logs
mkdir -p /home/hadoop/data/tomcat/logs 命令用于在Linux系统中创建目录。让我们解释一下各个部分的含义:•mkdir: 是用于创建目录(文件夹)的命令,其缩写来自 "make directory"。•-p: 是mkdir命令的一个选项,用于创建目录的过程中自动创建需要的父目录。如果指定的目录路径中的某些父目录不存在,该选项会创建这些父目录。如果省略了 -p 选项,并且其中的某些父目录不存在,mkdir 将会报错。•/home/hadoop/data/tomcat/logs: 是要创建的目标目录的完整路径。在这个例子中,它是一个相对于根目录的路径。这个命令将创建一个名为 "logs" 的目录,它是 "tomcat" 目录的子目录,而 "tomcat" 目录本身是 "data" 目录的子目录,而 "data" 目录则是 "hadoop" 目录的子目录。因此,该命令的目的是创建一个目录结构,确保 /home/hadoop/data/tomcat/logs 目录存在。如果某些目录不存在,-p 选项会确保在创建目标目录之前创建整个目录路径。1.搭建Linux虚拟机
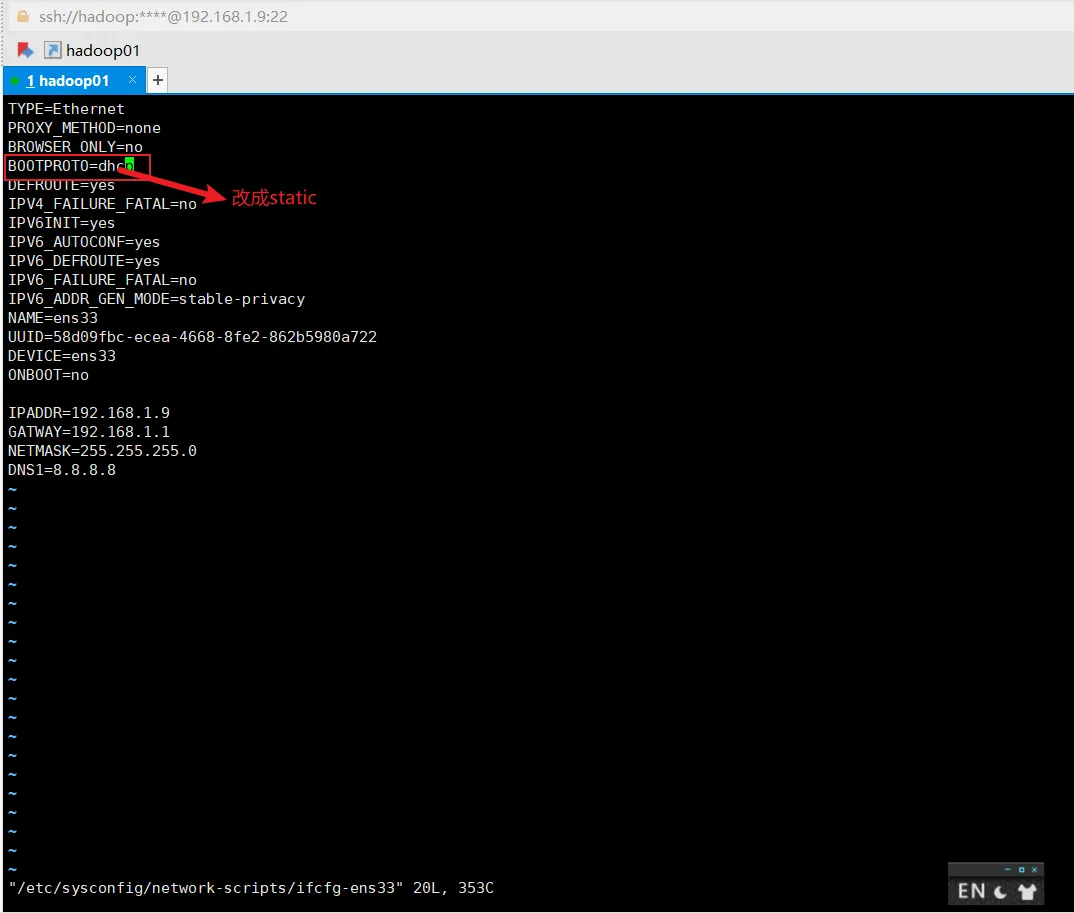
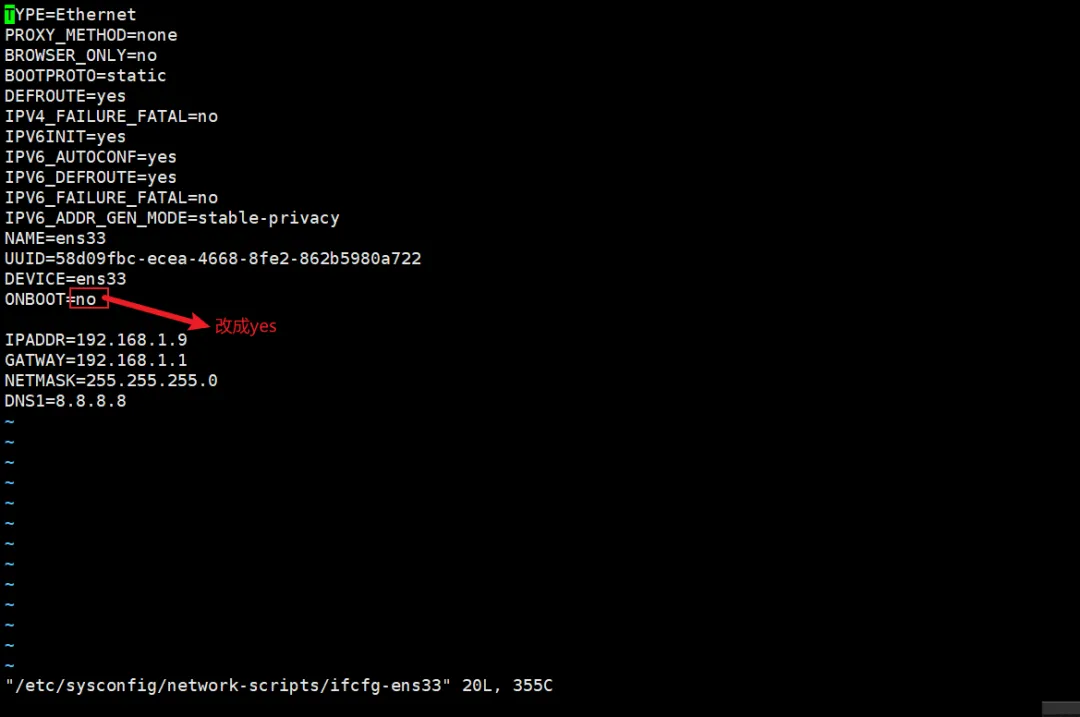
配置Linux静态IP
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33IPADDR=192.168.0.102GATEWAY=192.168.0.1NETMASK=255.255.255.0DNS1=8.8.8.8
重启网络
在较新的 CentOS 版本中,网络服务通常是由 NetworkManager 管理的,而不再使用 service 或 systemctl restart network 来重启。在这种情况下,你需要使用 nmcli(NetworkManager 命令行工具)来操作网络服务。以下是使用 nmcli 重启网络服 务的步骤:
nmcli connection show
找到你的网络连接名称,通常是类似 enp0s3 或 eth0 的名称。sudo nmcli connection up
要退出 Vi 文本编辑器并保存更改,你可以按照以下步骤操作:
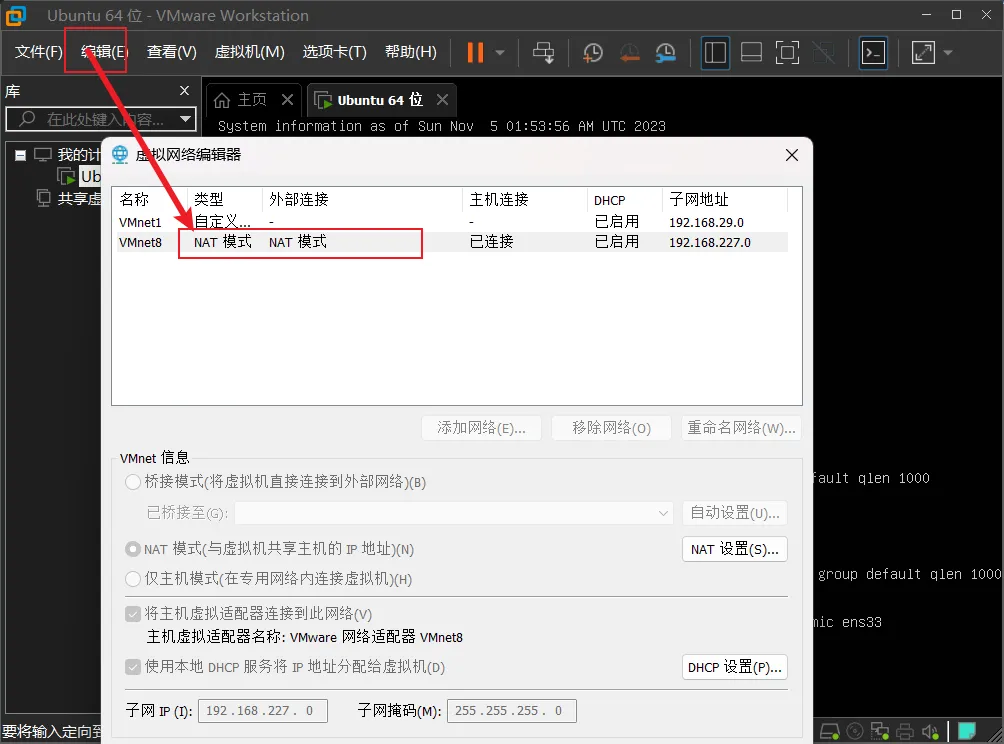
2.输入 :wq 并按下 Enter 键。这将保存你的更改并退出 Vi。如果你只是想退出 Vi 而不保存更改,可以在正常模式下按照以下步骤操作:2.输入 :q! 并按下 Enter 键。这将退出 Vi 并放弃所有未保存的更改。记住,Vi 编辑器有多种命令和模式,需要一些时间来熟悉。上述命令是保存和退出的常见命令。虚拟机默认是NAT模式
主机名的修改
临时修改方式
hostname hadoop01
重启虚拟机命令
reboothost
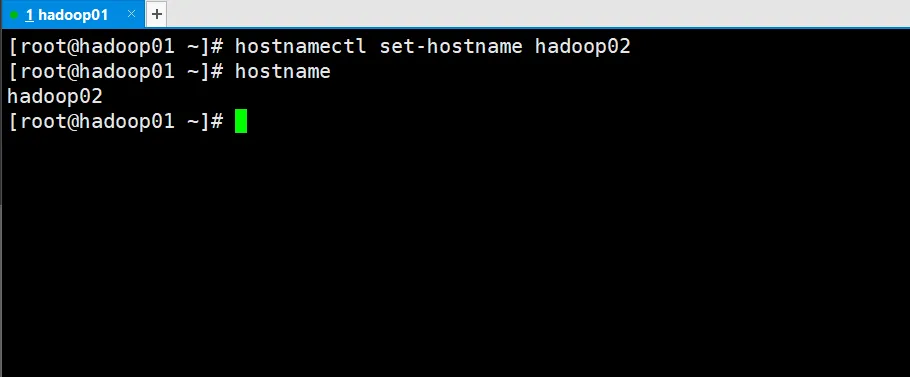
永久修改方法1
hostnamectl set-hostname hadoop03
永久修改方法2
查看文件
cat /etc/hostname
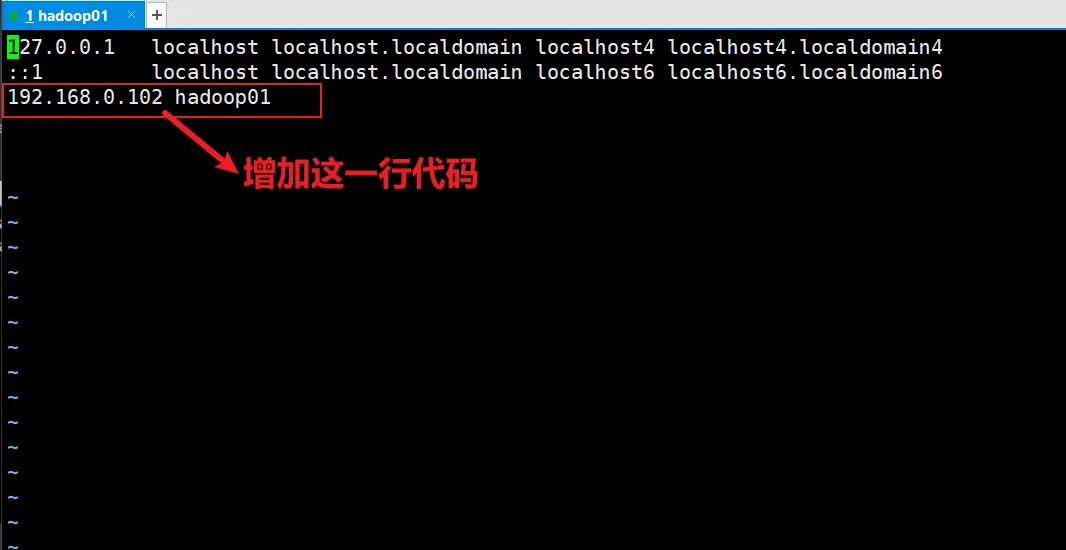
配置IP地址映射
vi /etc/hosts
192.168.0.102hadoop01
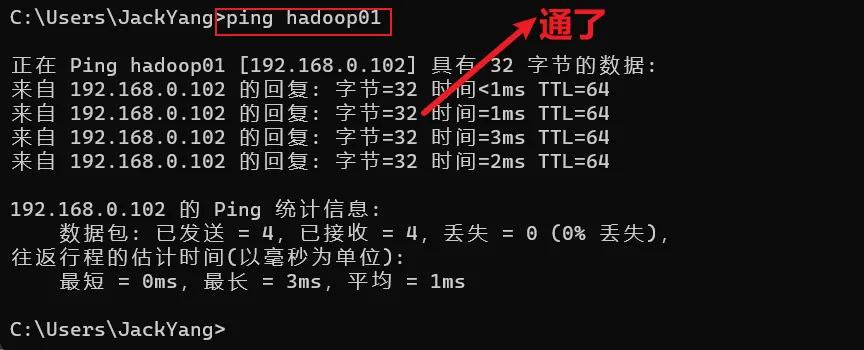
Windows配置地址映射
我的虚拟机的IP地址为:
192.168.0.102
win系统没有设置hosts时,通过 ping hadoop01 无法访问,ping不同。此时,我们需要对win系统进行IP地址映射,步骤如下:打开如下的路径:C:\Windows\System32\drivers\etc\hosts
添加 IP地址映射为 hadoop01192.168.0.102 hadoop01
总结:配置IP 地址映射是因为IP地址比较长,不容易记忆,通过映射或者给IP地址取个别名,然后通过映射名进行访问。
CentOS防火墙的关闭
在学习hadoop时,我们直接关闭防火墙,利于不同集群环境的通信,关闭和查看防火墙的命令如下:[root@hadoop01 ~]
firewall-cmd --staterunning[root@hadoop01 ~]# systemctl stop firewalld.service[root@hadoop01 ~]# firewall-cmd --statenot running
开机禁止防火墙的使用
[root@hadoop01 ~]
systemctl disable firewalld.serviceRemoved symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
开启防火墙
systemctl start firewalld.service
创建Linux用户和用户组
在 CentOS 中,su - hadoop 是切换用户的命令,将当前用户切换为 hadoop 用户,并启动一个新的 shell 会话。让我们分解这个命令:
•su: 这是 "switch user" 的缩写,用于切换当前登录用户。•-: 这个选项表示切换用户时使用目标用户的环境变量。这意味着,除了用户身份之外,还会继承目标用户的环境设置,包括路径、shell 配置等。•hadoop: 这是目标用户的用户名,即要切换到的用户。整体来说,su - hadoop 的目的是以 hadoop 用户的身份登录,并使用 hadoop 用户的环境设置。在切换到 hadoop 用户后,你将在一个新的 shell 中执行命令,就好像你以 hadoop 用户登录到系统一样。注意:在运行这个命令之前,你可能需要输入 root 用户的密码或具有 sudo 权限的用户的密码,以进行用户切换。
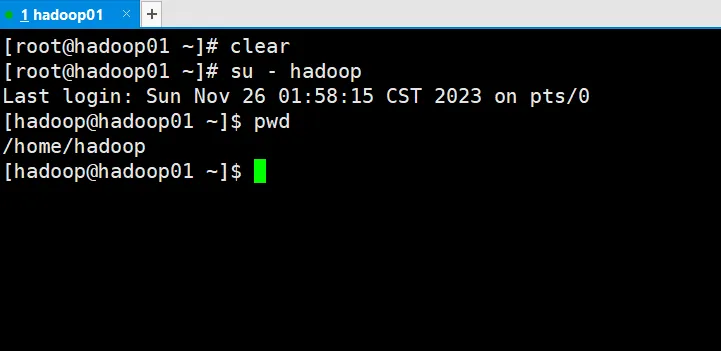
[root@hadoop01 ~]
clear[root@hadoop01 ~]# su - hadoopLast login: Sun Nov 26 01:58:15 CST 2023 on pts/0[hadoop@hadoop01 ~]$ pwd/home/hadoop[hadoop@hadoop01 ~]$
[hadoop@hadoop01 ~]$ exitlogout[root@hadoop01 ~]
adduser hadoop
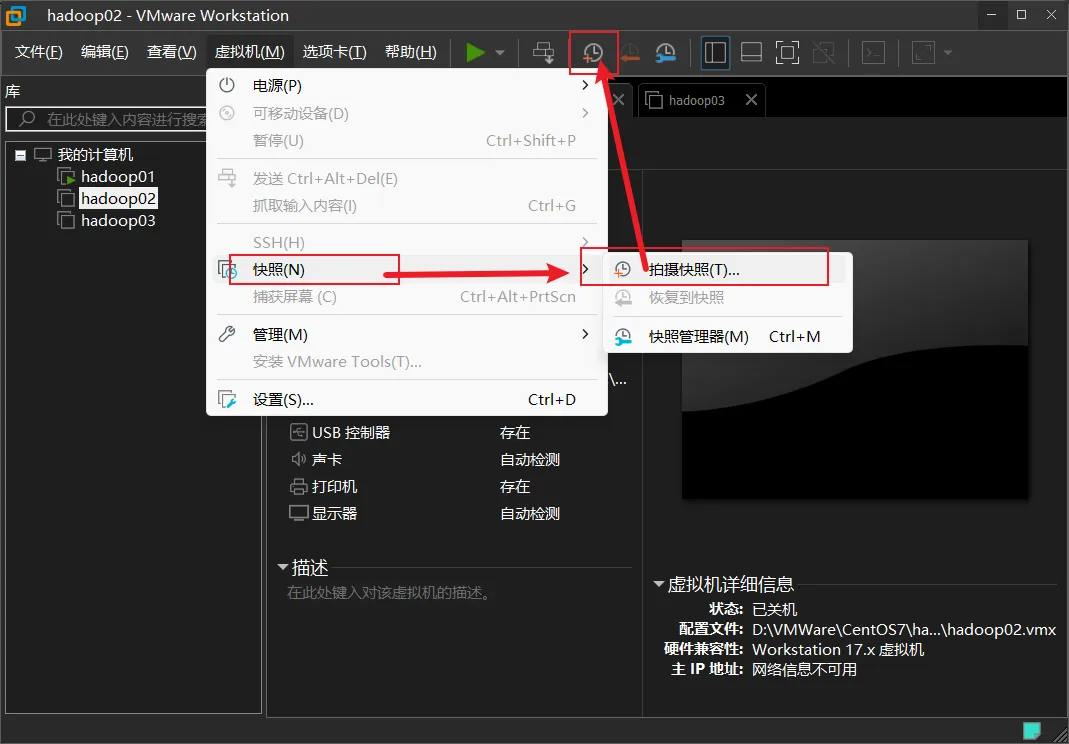
虚拟机做快照
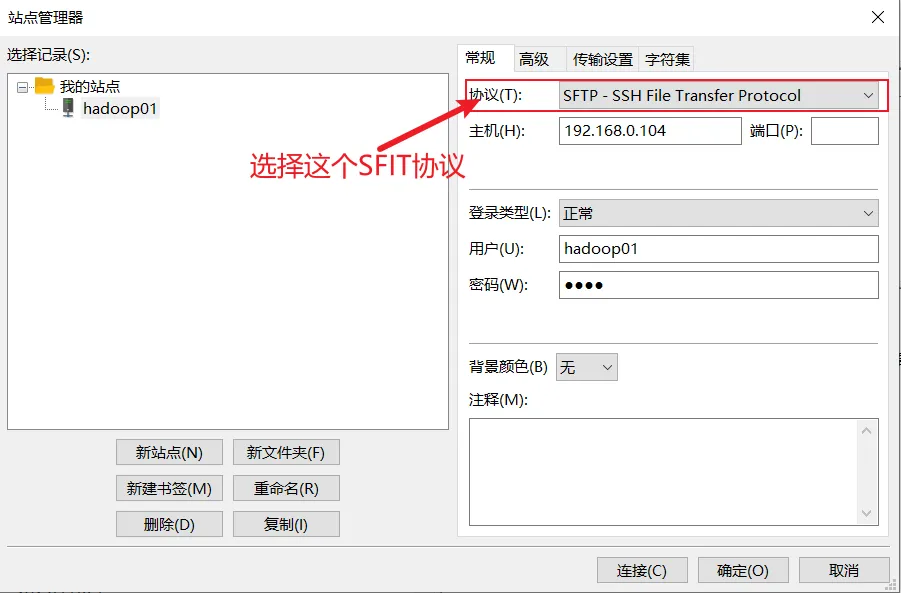
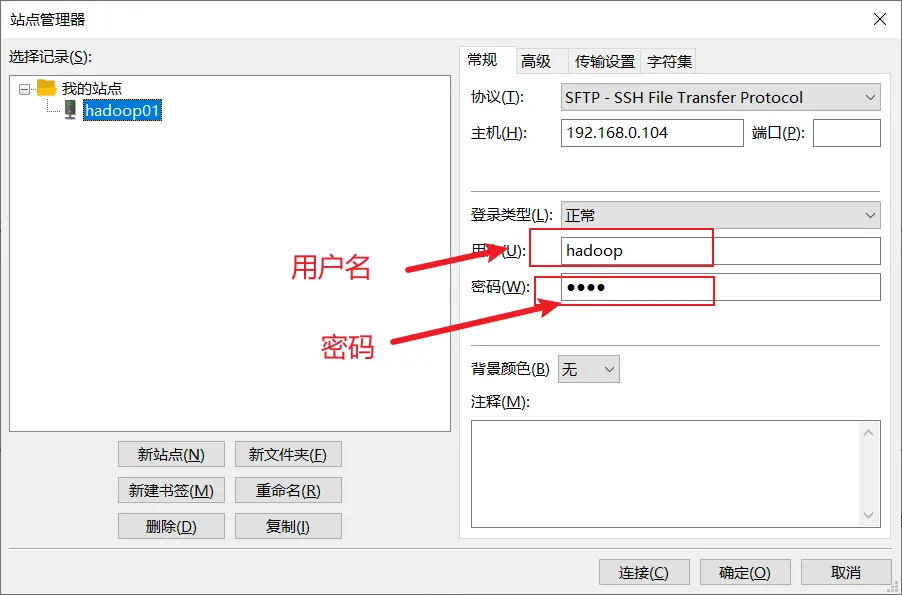
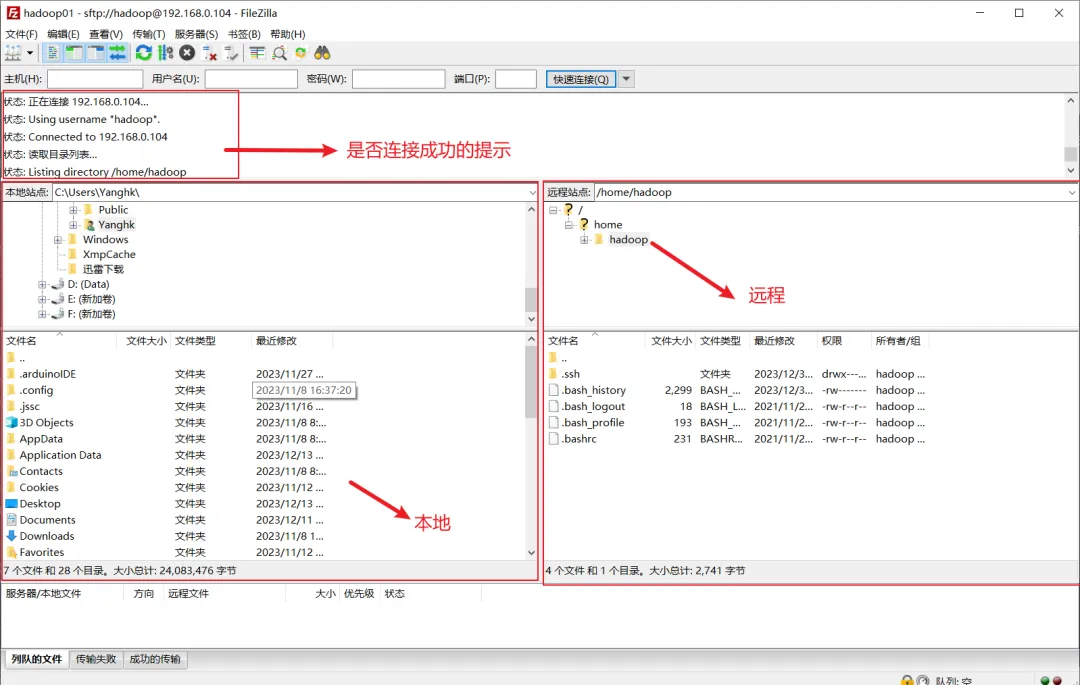
2.FileZilla软件的使用
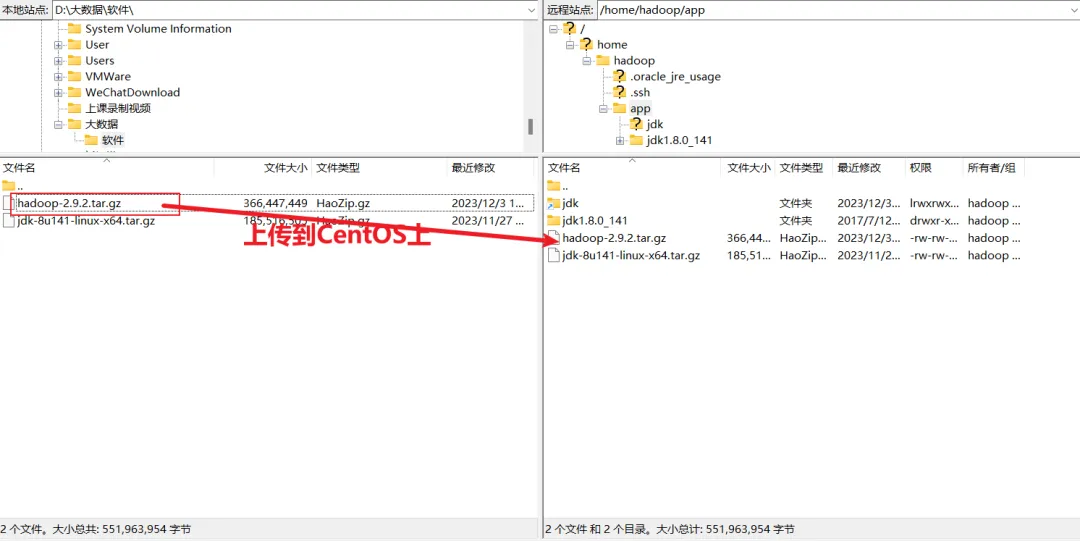
FileZilla是连接虚拟机或者远程连接Linux系统并进行文件上传或者下载的软件,这里使用该软件,主要是把本地Win系统软件上传到虚拟机中的CentOS中。连接如下:3.搭建Hadoop伪分布式集群环境
JDK的下载与安装
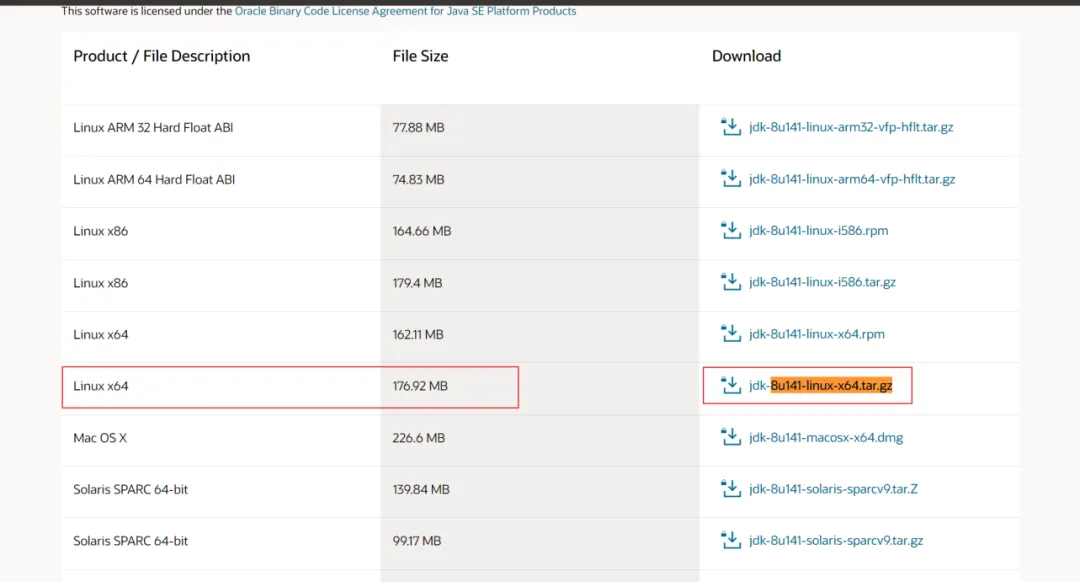
下载JDK
[root@hadoop01 ~]
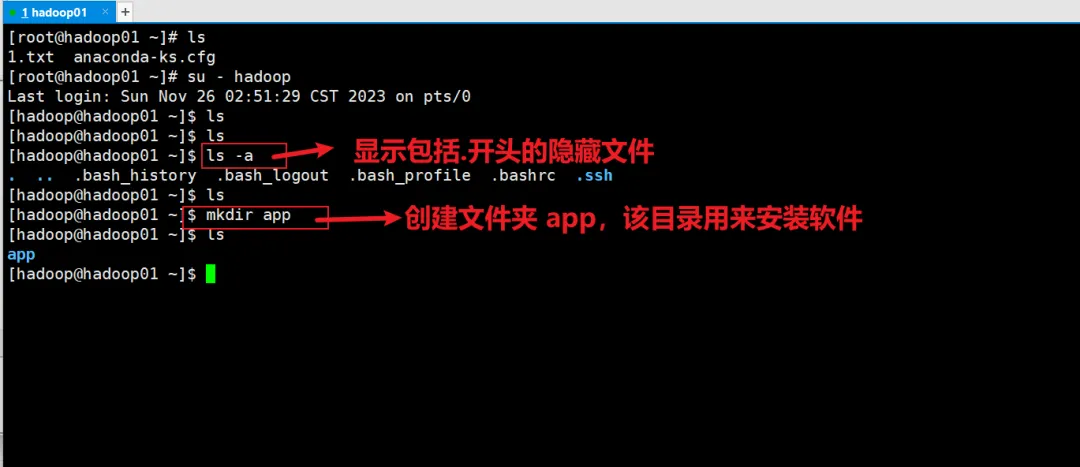
ls1.txtanaconda-ks.cfg[root@hadoop01 ~]# su - hadoopLast login: Sun Nov 26 02:51:29 CST 2023 on pts/0[hadoop@hadoop01 ~]$ ls[hadoop@hadoop01 ~]$ ls[hadoop@hadoop01 ~]$ ls -a....bash_history.bash_logout.bash_profile.bashrc.ssh[hadoop@hadoop01 ~]$ ls[hadoop@hadoop01 ~]$ mkdir app[hadoop@hadoop01 ~]$ lsapp[hadoop@hadoop01 ~]$
ls -l
在 CentOS 中,ls -l 是用于列出目录内容的命令,其中的 -l 选项表示以长格式(long format)显示文件和目录的详细信息。让我们详细解释这个命令:•ls: 这是 "list" 的缩写,用于列出目录中的文件和子目录。•-l: 这是 ls 命令的一个选项,表示以长格式显示信息。长格式包括文件的权限、所有者、组、大小、修改时间等详细信息。bashCopy code-rw-r--r-- 1 user group4096 Nov1 10:30 file1-rw-rw-r-- 1 user group8192 Nov1 11:45 file2drwxr-xr-x 2 user group4096 Nov1 09:15 directory1
•-rw-r--r-- 表示文件权限。具体来说,这个文件是一个普通文件,所有者(user)有读和写的权限,组(group)有读的权限,其他用户也有读的权限。•1 表示链接数(links),即有多少个目录项链接到这个文件或目录。这种长格式提供了更详细的信息,使你能够更好地了解文件和目录的属性。解压JDK
tar -zxvf jdk-8u141-linux-x64.tar.gz
命令 tar -zxvf 用于在Unix和类Unix系统中解压缩 tar 归档文件。这个命令有几个选项,下面是各个选项的解释:
•tar: 这是 tar 命令的基本命令,用于创建、查看或解压缩归档文件。•-z: 这个选项告诉 tar 使用 gzip 解压缩。gzip 是一种常见的压缩工具,用于减小文件大小。•-x: 这个选项表示解压缩操作,即从 tar 归档中提取文件。•-v: 这个选项启用详细模式,显示正在执行的操作的详细信息。在解压缩时,它会显示提取的文件列表。•-f: 这个选项后面通常紧跟着归档文件的名称。它指定要操作的 tar 归档文件的名称。因此,tar -zxvf archive.tar.gz 表示要解压缩名为 "archive.tar.gz" 的文件,其中 "-z" 表示使用 gzip 解压缩,"-x" 表示执行解压缩操作,"-v" 表示显示详细信息,"-f" 后面是要操作的文件的名称。为了方便管理多版本JDK,使用ln命令创建JDK软链接(取别名),操作命令如下:
[hadoop@hadoop01 app]$ ln -s jdk1.8.0_141/ jdk[hadoop@hadoop01 app]$ ls -ltotal 181172lrwxrwxrwx. 1 hadoop hadoop13 Dec3 07:44 jdk -> jdk1.8.0_141/drwxr-xr-x. 8 hadoop hadoop255 Jul 122017 jdk1.8.0_141-rw-rw-r--. 1 hadoop hadoop 185516505 Nov 27 12:46 jdk-8u141-linux-x64.tar.gz
配置JDK环境变量
在 hadoop 用户下,打开 vi ~/.bashrc 文件。[hadoop@hadoop01 app]$ vi ~/.bashrc
JAVA_HOME=/home/hadoop/app/jdkCLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarPATH=$JAVA_HOME/bin:$PATHexport JAVA_HOME CLASSPATH PATH
这是一个设置Java类路径(CLASSPATH)的命令。在这个命令中,CLASS_PATH 是一个环境变量,用于指定Java编译器和运行时应该查找类文件的位置。
让我们解释这个命令:
•CLASS_PATH=: 这部分指定了一个名为 CLASS_PATH 的环境变量。•.::表示当前目录。这样设置确保Java编译器和运行时会在当前目录中查找类文件。•$JAVA_HOME/lib/dt.jar:这是 JAVA_HOME 环境变量中Java安装目录下的 dt.jar 文件的路径。这个JAR文件包含了Java的图形用户界面(GUI)工具。•$JAVA_HOME/lib/tools.jar:这是 JAVA_HOME 环境变量中Java安装目录下的 tools.jar 文件的路径。这个JAR文件包含了Java编译器(javac)等工具。因此,整个命令表示将当前目录、dt.jar 和 tools.jar 这三个位置添加到Java类路径中,以便Java编译器和运行时能够找到相应的类文件。这对于编译和运行Java程序时需要依赖这些库和工具的情况非常重要。使用source命令执行.bashrc文件,JDK环境变量才能生效。
[hadoop@hadoop01 app]$ source ~/.bashrc[hadoop@hadoop01 app]$ echo $JAVA_HOME/home/hadoop/app/jdk
检查JDK是否安装成功
[hadoop@hadoop01 app]$ java -versionjava version "1.8.0_141"Java(TM) SE Runtime Environment (build 1.8.0_141-b15)Java HotSpot(TM) 64-Bit Server VM (build 25.141-b15, mixed mode)
Hadoop的安装与配置
JDK环境变量以及安装好,接下来开始安装Hadoop2.9.2版本。具体步骤如下:下载Hadoop
Hadoop新版本下载地址
解压Hadoop
在当前目录下,使用tar命令解压Hadoop安装包。[hadoop@hadoop01 app]$ lshadoop-2.9.2hadoop-2.9.2.tar.gzjdkjdk1.8.0_141jdk-8u141-linux-x64.tar.gz[hadoop@hadoop01 app]$ tar -zxvf hadoop-2.9.2.tar.gz
为了方便管理多版本Hadoop,使用ln命令创建软链接,具体操作命令如下。[hadoop@hadoop01 app]$ ln -s hadoop-2.9.2 hadoop[hadoop@hadoop01 app]$ lshadoophadoop-2.9.2hadoop-2.9.2.tar.gzjdkjdk1.8.0_141jdk-8u141-linux-x64.tar.gz[hadoop@hadoop01 app]$
配置Hadoop
在当前目录下进入到etc/hadoop目录,修改Hadoop相关配置文件。cd /home/hadoop/app/hadoop/etc/hadoop
[hadoop@hadoop01 app]$ cd hadoop-2.9.2[hadoop@hadoop01 hadoop-2.9.2]$ lsbinetcincludeliblibexecLICENSE.txtNOTICE.txtREADME.txtsbinshare
1.修改 core-site.xml 配置文件。 core-site.xml 文件 主要配置 Hadoop 的公有属性,具体如下:<configuration><property><name>fs.defaultFSname><value>hdfs://hadoop01:9000value>property><property><name>hadoop.tmp.dirname><value>/home/hadoop/data/tmpvalue>property>configuration>
1.修改 hdfs-site.xml 配置文件。hdfs-site.xml 文件主要配置与 HDFS 相关的属性,具体配置内容如下。[hadoop@hadoop01 hadoop]$ vi hdfs-site.xml <configuration><property><name>dfs.namenode.name.dirname><value>/home/hadoop/data/dfs/namevalue>property><property><name>dfs.namenode.data.dirname><value>/home/hadoop/data/dfs/datavalue>property><property><name>dfs.replicationname><value>1value>property><property><name>dfs.permissionsname><value>falsevalue>property>configuration>
1.修改 hadoop-env.sh 配置文件。hadoop-env.sh文件主要配置与 Hadoop 环境相关的变量,这里主要修改JAVA_HOME的安装目录,具体配置内容如下:export JAVA_HOME=${JAVA_HOME}这一行替换下面的代码export JAVA_HOME=/home/hadoop/app/jdk[hadoop@hadoop01 hadoop]$ vi hadoop-env.sh
解释:PATH=$JAVAHOME/bin:$HADOOPHOME/bin:$PATHChatGPT
这是一个在Unix/Linux环境下设置环境变量 PATH 的命令。让我们解释这个命令:
•PATH=: 这部分指定了要设置的环境变量的名称,即 PATH。•$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH: 这是 PATH 环境变量的新值。它由三个部分组成,用冒号 : 分隔:1.$JAVA_HOME/bin: 这是 Java 安装目录下的 bin 目录。将 Java 可执行文件的路径添加到 PATH 中,使系统可以直接在命令行中找到并执行 Java 相关命令。2.$HADOOP_HOME/bin: 这是 Hadoop 安装目录下的 bin 目录。将 Hadoop 可执行文件的路径添加到 PATH 中,以便可以在命令行中直接运行 Hadoop 相关命令。3.$PATH: 这是当前 PATH 环境变量的值。通过将当前 PATH 的值附加在新的路径之后,确保不会丢失现有的路径配置。这个命令的目的是将 Java 和 Hadoop 的可执行文件路径添加到系统的 PATH 环境变量中,使得在命令行中可以直接运行与 Java 和 Hadoop 相关的命令,而不需要提供完整的路径。这对于简化命令行操作和确保系统能够找到正确的执行文件非常有用。这是一个在 Hadoop YARN 集群上运行 WordCount MapReduce 作业的命令。让我们逐步解释这个命令:
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /test/words.log /test/out
•bin/yarn jar: 这部分指定了要使用的 YARN 命令行工具以及要运行的 Jar 文件。•share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar: 这是包含 MapReduce 作业的 JAR 文件的路径。在这里,它是 Hadoop 发行版中的一个示例 JAR 文件,用于运行 WordCount 示例。•wordcount: 这是要运行的 MapReduce 作业的主类。在这里,wordcount 是 WordCount 示例的主类,该类包含 Map 和 Reduce 函数的实现。•/test/words.log: 这是输入路径,指定包含要进行单词计数的文本文件的 HDFS 路径。•/test/out: 这是输出路径,指定 MapReduce 作业的结果将被写入的 HDFS 路径。因此,整个命令的目的是运行一个 WordCount MapReduce 作业,该作业会读取位于 /test/words.log 的文本文件,对其进行单词计数,并将结果写入到 /test/out 目录中。这是一个常见的 MapReduce 作业示例,用于演示 Hadoop 分布式计算的基本功能。1.修改 mapred-site.xml 配置文件。进入etc/hadoop目录下,输入以下代码。mapred-site.xml文件主要配置与 MapReduce 相关的属性,这里主要将MapReduce的运行框架形成配置为YARN,具体配置如下:vi mapred-site.xml
<configuration><property><name>mapreduce.framework.namename><value>yarnvalue>property>configuration>
1.修改 yarn-site.xml配置文件。yarn-site.xml文件主要配置与YARN相关的属性,具体配置内容如下。<configuration><property><name>yarn.nodemanager.aux-servicesname><value>mapreduce_shufflevalue>property>configuration>
2.修改 slaves 配置文件。slaves 文件主要配置那些节点为 datanode 角色,由于目前搭建的是Hadoop伪分布式集群,所以只需要填写当前主机的hostname即可,具体配置如下:[hadoop@hadoop01 hadoop]$ vi slaveshadoop01
1.配置 Hadoop 环境变量。在Hadoop用户下,添加Hadoop环境变量,具体操作命令如下:vi ~/.bashrcJAVA_HOME=/home/hadoop/app/jdkCLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarPATH=$JAVA_HOME/bin:$PATHexport JAVA_HOME CLASSPATH PATHexport HADOOP_HOME=/home/hadoop/app/hadoopPATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
使用 source 命令执行 .bashrc 文件,才能使Hadoop环境变量生效,具体如下:[hadoop@hadoop01 hadoop]$ source ~/.bashrc[hadoop@hadoop01 hadoop]$ hadoop versionHadoop 2.9.2
1.创建 Hadoop 相关数据目录
mkdir -p /home/hadoop/data/tmpmkdir -p /home/hadoop/data/dfs/namemkdir -p /home/hadoop/data/dfs/data
4.启动Hadoop伪分布式集群
1.格式化主节点 NameNode
在Hadoop安装目录下,使用如下命令对NameNode进行格式化。bin/hdfs namenode -format
注意 :第一次安装 Hadoop 集群需要对 NameNode 进行格式化,Hadoop 集群安装成功之后,下次只需要使用脚本 start-all.sh 一键启动即可。1.启动 Hadoop 伪分布式集群
[hadoop@hadoop01 hadoop]$ sbin/start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.shStarting namenodes on [hadoop01]hadoop01: Warning: Permanently added the ECDSA host key for IP address '10.0.8.155' to the list of known hosts.hadoop01: starting namenode, logging to /home/hadoop/app/hadoop-2.9.2/logs/hadoop-hadoop-namenode-hadoop01.outhadoop01: starting datanode, logging to /home/hadoop/app/hadoop-2.9.2/logs/hadoop-hadoop-datanode-hadoop01.outStarting secondary namenodes [0.0.0.0]0.0.0.0: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.9.2/logs/hadoop-hadoop-secondarynamenode-hadoop01.outstarting yarn daemonsstarting resourcemanager, logging to /home/hadoop/app/hadoop-2.9.2/logs/yarn-hadoop-resourcemanager-hadoop01.outhadoop01: starting nodemanager, logging to /home/hadoop/app/hadoop-2.9.2/logs/yarn-hadoop-nodemanager-hadoop01.out
1.查看 Hadoop 服务进程
[hadoop@hadoop01 hadoop]$ jps2482 Jps1893 SecondaryNameNode1687 DataNode1579 NameNode2157 NodeManager2047 ResourceManager
1.查看 HDFS
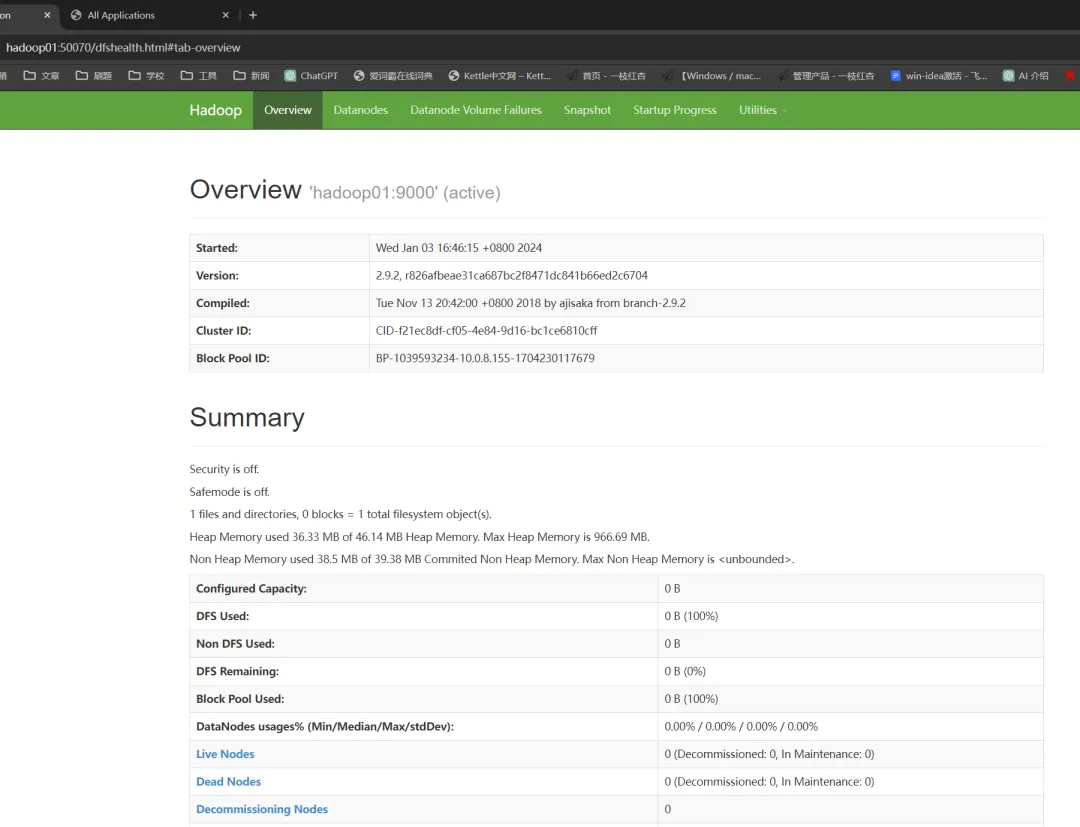
在浏览器中输入:http://hadoop01:50070/,通过Web页面查看HDFS,页面结果如下:1.查看YARN资源管理系统
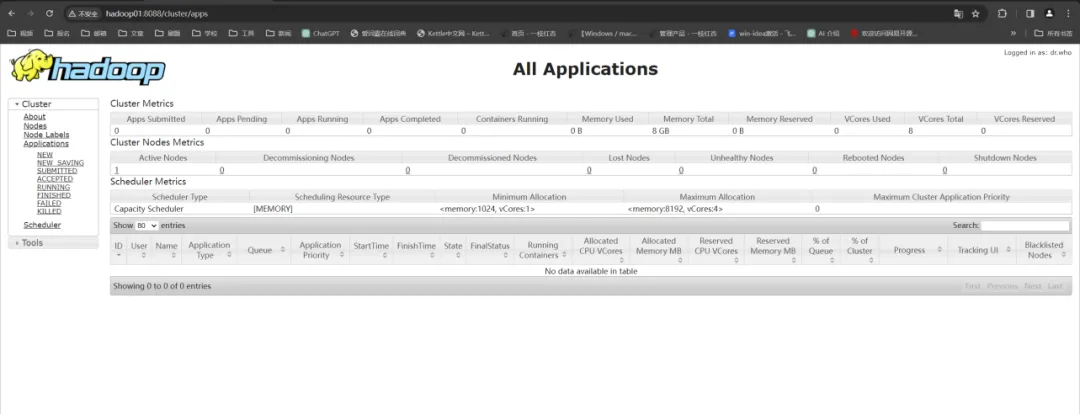
在浏览器中输入 http://hadoop01:8088/ 查看。1.jps命令执行后没有显示DataNode节点,正常情况下一共是6个节点。[hadoop@hadoop01 hadoop]$ jps2020 NodeManager1431 NameNode1896 ResourceManager2392 Jps1738 SecondaryNameNode
查看 hadoop 的版本
[hadoop@hadoop01 hadoop]$ hadoop versionHadoop 2.9.2
查看DataNode错误日志:
cd /home/hadoop/app/hadoop/logs
查看错误日志:
cat hadoop-hadoop-datanode-hadoop01.log
查看报错内容:
java.io.IOException:Incompatible clusterIDs in/home/hadoop/data/dfs/data:namenode clusterID=CID-0d724250-2bca-4bf8-a809-a8381e8719a2;datanode clusterID=CID-6cc793c1-b3e9-416d-9190-fcc6081d8151?
这个错误表明在Hadoop集群中,NameNode 和 DataNode 的集群ID(clusterID)不匹配。每个Hadoop集群都有一个唯一的clusterID,用于标识整个集群。在你的情况下,发现了不兼容的clusterIDs。要解决这个问题,你可以采取以下步骤:
1.停止Hadoop集群: 首先,停止整个Hadoop集群,包括NameNode、DataNode以及其他相关的服务。2.检查集群ID配置: 确保在Hadoop配置文件中,特别是hdfs-site.xml中,配置了正确的集群ID。检查dfs.namenode.cluster-id参数是否在NameNode的配置中设置,确保其值与错误消息中的 "namenode clusterID" 一致。xmlCopy codedfs.namenode.cluster-idCID-0d724250-2bca-4bf8-a809-a8381e8719a2
3.清理DataNode数据目录: 删除DataNode的数据目录中的所有数据。在你的情况下,数据目录是 /home/hadoop/data/dfs/data。确保在删除数据之前备份重要数据。$ rm -r /home/hadoop/data/dfs/data/*
4.重新启动Hadoop集群: 启动Hadoop集群,包括NameNode和DataNode。确保它们都能够正常启动,并且不再出现集群ID不兼容的错误。$ start-dfs.sh
这些步骤应该能够解决由于不兼容的集群ID引起的问题。确保在执行这些步骤之前备份任何重要的数据,以防万一。执行第三步,清理DataNode数据目录即可。
rm -r /home/hadoop/data/dfs/data/*
1.测试运行 Hadoop 伪分布式集群
Hadoop 伪分布式集群启动之后,以Hadoop自带的 WordCount(单词统计)案例来检测Hadoop集群环境的可用性。此命令是在Hadoop 安装目录下运行。(1). 查看 HDFS 目录
bin/hdfs dfs -ls /
因为第一次使用HDFS,所以HDFS中没有任何目录和文件。
(2). 创建 HDFS 目录
在 HDFS Shell 中,使用 mkdir命令创建 HDFS文件目录 /test,具体操作命令如下:
bin/hdfs dfs -mkdir /test
在 Hadoop 根目录下,新建 words.log 文件并输入测试数据,具体操作命令如下:
vi words.loghadoop hadoop hadoopspark spark sparkflink flink flink
[hadoop@hadoop01 hadoop]$ bin/hdfs dfs -put words.log/test
使用 yarn 脚本将 Hadoop 自带的 WordCount 程序提交到 YARN 集群运行,具体操作命令如下:
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordscount /test/words.log /test/out
http://hadoop01:8088/cluster/apps/RUNNING
如果在 YARN 集群的 Web 界面中,查看到 WordCount 作业最终的运行状态为 SUCCEEDED,就说明 MapReduce 程序可以在 YARN 集群上成功运行。
(7).查询作业运行结果
[hadoop@hadoop01 hadoop]$ bin/hdfs dfs -cat /test/out/*flink3hadoop3spark3
cd $HADOOP_HOME


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
