十分钟实用教程 | Linux性能优化:CPU进程分析深度解析
- 2026-06-30 19:23:59
十分钟实用教程 | Linux性能优化:CPU进程分析深度解析
0. 前言
在性能优化领域,Linux从来不是一个黑盒系统。内核将几乎所有关键的运行时信息都暴露在/proc和/sys文件系统中,配合一系列命令行工具,工程师可以精确地观测系统的真实运行状态。对于高性能计算、数据库、AI推理等场景,性能问题往往不在算法本身,而在于系统资源的实际分配方式与预期是否一致。
本文的目标是:让读者理解CPU上下文切换的完整机制,掌握核心观测工具的使用方法,并建立起系统化的性能分析思维。
1. CPU上下文切换的触发场景
CPU上下文切换是操作系统实现多任务并发的核心机制。当内核决定暂停当前任务、切换到另一个任务执行时,必须保存当前任务的CPU寄存器状态和程序计数器,然后加载新任务的上下文信息。这个过程虽然在微秒级别完成,但频繁的切换会带来显著的性能开销。
结合上下文切换的类型和进程生命周期,可以归纳出以下五种典型的触发场景:
1.1 时间片耗尽
现代操作系统采用时间片轮转调度算法,将CPU执行时间划分为固定长度的时间片(通常为几毫秒到几十毫秒)。每个可运行的进程被分配一个时间片,当时间片用完后,无论任务是否完成,调度器都会强制挂起当前进程,切换到下一个就绪进程。这是最常见的上下文切换场景,也是系统在无外部事件干预下的默认行为。
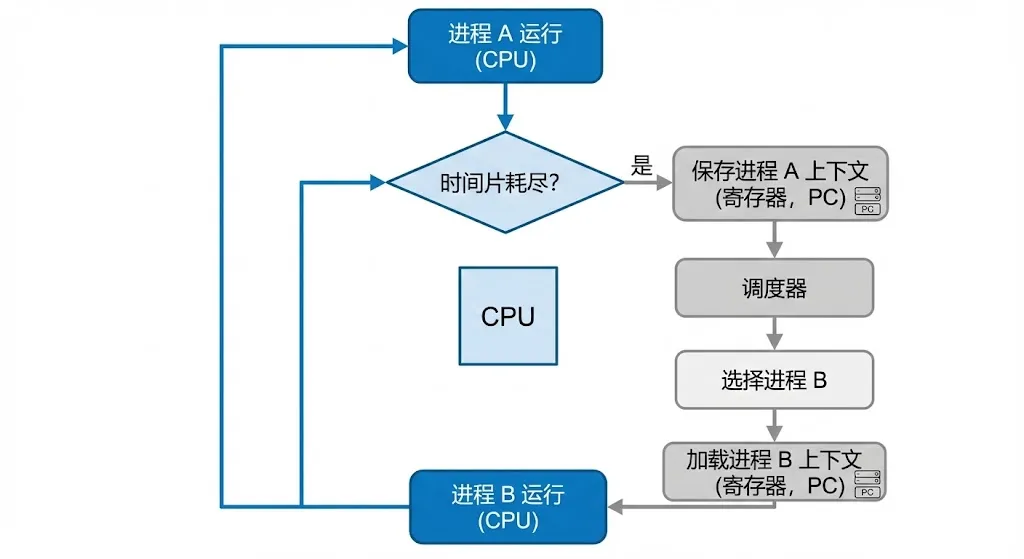
1.2 主动让出CPU
进程可以通过系统调用主动放弃CPU使用权。最典型的例子是调用sleep()函数,进程会进入睡眠状态,等待指定时间后被唤醒。此外,当进程调用阻塞式I/O操作(如read()读取磁盘文件)时,由于I/O操作耗时较长,进程会主动让出CPU,等待I/O完成后再被调度执行。
// 示例:进程主动让出CPU的几种方式#include <unistd.h>#include <sched.h>// 方式1:sleep系统调用sleep(1); // 睡眠1秒,主动让出CPU// 方式2:sched_yield显式让出sched_yield(); // 让出CPU给同优先级的其他进程// 方式3:阻塞式I/Ochar buf[1024];read(fd, buf, sizeof(buf)); // 等待I/O完成,期间让出CPU1.3 优先级抢占
Linux调度器支持进程优先级机制。当一个高优先级进程变为可运行状态时(例如从睡眠中被唤醒),调度器会立即抢占当前正在运行的低优先级进程,将CPU分配给高优先级进程。实时进程(SCHED_FIFO、SCHED_RR调度策略)具有比普通进程更高的优先级,可以抢占任何普通进程。
1.4 资源等待
当进程请求的系统资源暂时不可用时,进程会被挂起等待。常见的资源等待场景包括:等待互斥锁(mutex)、等待信号量(semaphore)、等待内存分配、等待网络数据到达等。资源等待导致的上下文切换通常意味着系统存在资源竞争或资源不足的问题。
1.5 硬件中断
当外部硬件设备(如网卡、磁盘控制器、定时器)产生中断信号时,CPU会暂停当前任务,转而执行中断处理程序。中断处理完成后,可能会唤醒等待该事件的进程,从而触发进程调度和上下文切换。硬件中断是系统响应外部事件的核心机制,但过于频繁的中断也会影响系统性能。
2. 使用vmstat观察系统级上下文切换
vmstat(Virtual Memory Statistics)是Linux系统中最常用的性能监控工具之一,它能够提供系统整体的进程、内存、交换分区、I/O和CPU使用情况的统计信息。对于上下文切换分析而言,vmstat是首选的入门级工具。
2.1 vmstat基本用法
vmstat命令的基本语法为vmstat [间隔秒数] [执行次数]。以下是一个典型的输出示例:
# 每3秒输出一次系统状态root@node:~# vmstat 3procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 477767936 883712 9970296 0 0 0 2 0 0 0 0 99 0 0 0 0 0 477766688 883716 9970120 0 0 0 12 380 754 0 0 100 0 0 0 0 0 477770016 883716 9970292 0 0 0 0 1956 4706 1 1 98 0 02.2 关键指标解读
在vmstat的输出中,与CPU上下文切换直接相关的指标位于procs和system两个区域:
procs区域(进程状态):
system区域(系统活动):
cpu区域(CPU使用率):
2.3 上下文切换的判断标准
上下文切换次数(cs)本身没有绝对的"正常值",需要结合系统配置和业务特点来判断。以下是一些经验性的参考标准:

当观察到cs值异常升高时,通常伴随着以下现象:
• sy(内核态CPU使用率)明显上升 • r(运行队列)持续大于CPU核心数 • 应用响应延迟增加
3. 使用pidstat观察进程级上下文切换
vmstat提供的是系统整体视角,当发现上下文切换异常时,需要进一步定位到具体的进程。pidstat是sysstat工具包中的一个命令,能够按进程或线程维度展示CPU、内存、I/O等详细统计信息。
3.1 pidstat基本用法
使用-w参数可以查看进程的上下文切换统计:
# 每3秒输出一次进程上下文切换信息root@node:~# pidstat -w 3Linux 4.15.0-58-generic (node) 11/26/2025 _x86_64_ (64 CPU)09:20:52 PM UID PID cswch/s nvcswch/s Command09:20:55 PM 0 8 0.33 0.00 ksoftirqd/009:20:55 PM 0 9 12.83 0.00 rcu_sched09:20:55 PM 0 12 0.33 0.00 watchdog/009:20:55 PM 0 1234 45.67 2.33 mysql09:20:55 PM 0 5678 123.45 15.67 java3.2 自愿与非自愿上下文切换
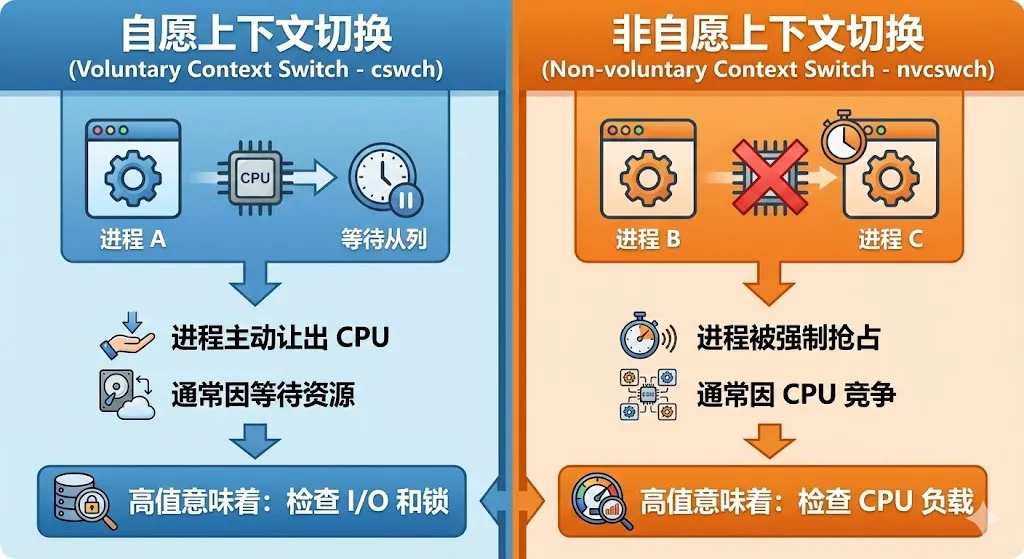
pidstat输出中最关键的两个指标是cswch和nvcswch,它们代表了两种本质不同的上下文切换类型:
cswch(voluntary context switches)- 自愿上下文切换:
自愿上下文切换是指进程主动放弃CPU而发生的切换。典型场景包括:
• 等待I/O操作完成(磁盘读写、网络收发) • 等待锁或信号量 • 调用sleep()等主动让出CPU的系统调用 • 等待其他系统资源
当cswch值较高时,通常意味着进程在等待某种资源,需要检查I/O性能、锁竞争等问题。
nvcswch(non-voluntary context switches)- 非自愿上下文切换:
非自愿上下文切换是指进程被强制剥夺CPU而发生的切换。典型场景包括:
• 时间片耗尽被调度器抢占 • 被更高优先级进程抢占 • CPU资源竞争激烈
当nvcswch值较高时,说明系统CPU资源紧张,进程之间存在激烈的CPU竞争。
3.3 查看线程级上下文切换
在多线程应用中,问题可能出在某个特定线程上。使用-t参数可以查看线程级别的统计:
# 查看线程级上下文切换(-w上下文切换 -t线程)root@node:~# pidstat -wt 3Linux 4.15.0-58-generic (node) 11/27/2025 _x86_64_ (64 CPU)05:17:45 PM UID TGID TID cswch/s nvcswch/s Command05:17:48 PM 0 8 - 10.79 0.00 ksoftirqd/005:17:48 PM 0 - 8 10.79 0.00 |__ksoftirqd/005:17:48 PM 0 9 - 107.62 0.00 rcu_sched05:17:48 PM 0 - 9 107.62 0.00 |__rcu_sched05:17:48 PM 0 4695 - 1.27 0.00 ntpd05:17:48 PM 0 - 4695 1.27 0.00 |__ntpd05:17:48 PM 0 - 4832 3.81 0.00 |__worker_thread05:17:48 PM 0 - 4863 48.25 0.00 |__log_writer输出中的TGID(Thread Group ID)等同于进程ID,TID是线程ID。带有|__前缀的行表示该进程下的具体线程。通过这种方式,可以精确定位到哪个线程导致了上下文切换异常。
4. CPU性能问题分析方法论
掌握了vmstat和pidstat这两个核心工具后,需要建立一套系统化的分析方法。CPU性能问题的排查应当遵循"从宏观到微观、从现象到根因"的原则。
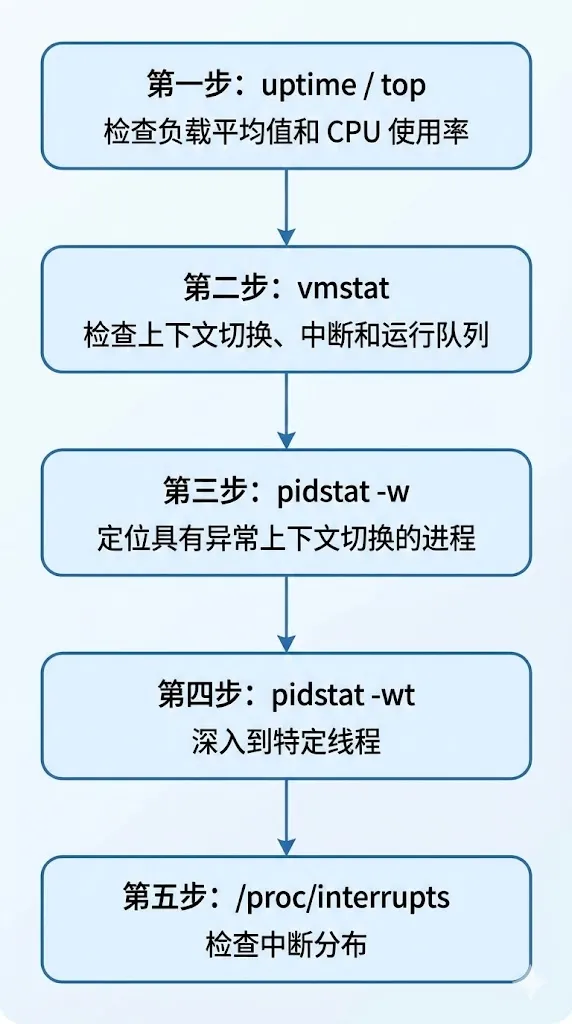
4.1 分析流程
当系统出现性能问题时,建议按照以下流程进行排查:
4.2 关键指标关联分析
单独看某一个指标往往难以得出结论,需要将多个指标关联起来分析:
场景一:r值高 + cs值高 + nvcswch高
这种组合说明运行队列中有大量进程在争抢CPU,导致频繁的非自愿上下文切换。根本原因是CPU资源不足,解决方案包括:优化应用减少CPU消耗、增加CPU核心数、或者将部分负载迁移到其他服务器。
场景二:cs值高 + cswch高 + wa值高
这种组合说明进程频繁因为等待I/O而让出CPU。根本原因是I/O性能瓶颈,需要检查磁盘性能、网络延迟等。
场景三:sy值高 + cs值高
内核态CPU使用率高,伴随大量上下文切换,说明系统调用过于频繁或存在内核级别的性能问题。需要使用perf等工具进一步分析内核热点。
5. 中断异常排查
在vmstat输出中,in参数表示每秒的CPU中断次数。中断是硬件与操作系统通信的核心机制,当中断频率异常时,往往伴随着CPU性能问题。Linux将详细的中断统计信息暴露在/proc/interrupts文件中。
5.1 查看中断统计
使用watch命令可以实时观察中断变化:
# 每2秒刷新一次,高亮显示变化的部分watch -d cat /proc/interrupts典型输出如下:
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 0: 22 0 0 0 0 0 0 0 IO-APIC 2-edge timer 8: 0 0 0 0 0 0 0 0 IO-APIC 8-edge rtc0 9: 0 0 0 0 0 0 0 0 IO-APIC 9-fasteoi acpi 60: 0 0 0 256 0 0 0 0 PCI-MSI 131075-edge virtio4-requestNMI: 0 0 0 0 0 0 0 0 Non-maskable interruptsLOC: 19978406 21499538 19037427 19051650 24423046 16673118 16385116 16393098 Local timer interruptsRES: 6886121 6006679 7293859 5923199 5446282 7366956 7156611 6750252 Rescheduling interruptsCAL: 492454 478584 493309 495546 405377 394787 400837 410006 Function call interruptsTLB: 585098 564485 581136 594965 564140 550393 550720 550566 TLB shootdowns5.2 关键中断类型解读
5.3 常见中断问题诊断
NMI(Non-maskable interrupts)异常:
NMI是不可屏蔽中断,正常情况下应该为0。如果出现非零值,通常表示发生了严重的硬件问题,如内存错误、总线错误等。此时应该使用dmesg命令查看内核日志:
# 查看内核日志中的硬件错误信息dmesg | grep -i "error\|fault\|fail"LOC(Local timer interrupts)不均衡:
LOC是CPU本地定时器中断,用于驱动进程调度。正常情况下,各CPU核心的LOC值应该大致相当。如果某个核心的值明显偏高或偏低,可能存在以下问题:
• CPU核心故障 • 进程绑定不当导致负载不均 • 内核调度器配置问题
RES(Rescheduling interrupts)剧增:
RES是重调度中断,当一个CPU核心需要通知另一个核心进行进程调度时会触发。在高负载场景下,RES值会自然增加。但如果RES值剧烈波动,通常伴随着:
• 进程频繁在不同CPU核心间迁移 • 上下文切换次数(cs)同步增加 • 系统响应延迟上升
TLB(TLB shootdowns)异常:
TLB是页表缓存,当进程的虚拟内存映射发生变化时,需要通知所有CPU核心刷新TLB缓存。TLB shootdowns异常增加通常意味着:
• 进程频繁申请和释放大量内存 • 存在内存泄漏后的大规模回收 • 使用了大量共享内存
可以使用以下命令查看内存使用异常的进程:
# 按内存使用率排序显示进程ps aux --sort=-%mem | head -206. Linux性能工具矩阵
除了vmstat和pidstat之外,Linux还提供了一系列工具用于深入分析CPU和系统性能。理解这些工具的定位和使用场景,是构建完整性能分析能力的基础。
6.1 lscpu:CPU拓扑结构查看
lscpu用于输出CPU架构的整体视图,包括Socket数量、物理核心数、逻辑线程数、NUMA节点划分以及缓存层级结构。
root@node:~# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitCPU(s): 64On-line CPU(s) list: 0-63Thread(s) per core: 2Core(s) per socket: 16Socket(s): 2NUMA node(s): 2L1d cache: 32KL1i cache: 32KL2 cache: 1024KL3 cache: 22528KNUMA node0 CPU(s): 0-15,32-47NUMA node1 CPU(s): 16-31,48-63lscpu的价值在于帮助确认操作系统是否正确识别了硬件拓扑。常见的问题包括:BIOS中的NUMA配置与OS识别不一致、核心数与硬件规格不符等。Linux调度器的所有决策都基于OS识别到的CPU拓扑,如果lscpu输出有误,后续的优化都将建立在错误的基础上。
6.2 numactl:NUMA策略控制
在NUMA(Non-Uniform Memory Access)架构下,内存访问延迟取决于CPU与内存的物理距离。本地内存访问延迟低、带宽高,而跨节点的远程内存访问则会带来显著的性能损失。
numactl允许显式控制进程的CPU亲和性和内存分配策略:
# 查看NUMA硬件配置numactl --hardware# 将进程绑定到NUMA节点0的CPU上运行,内存也从节点0分配numactl --cpunodebind=0 --membind=0 ./my_application# 查看当前进程的NUMA策略numactl --show对于内存密集型应用(如数据库、缓存服务),合理的NUMA绑定可以显著提升性能。
6.3 numastat:NUMA内存分配验证
即便使用了numactl进行绑定,也不代表配置一定生效。numastat用于验证实际的内存分配情况:
# 查看系统级NUMA内存统计root@node:~# numastat node0 node1numa_hit 12345678 11234567numa_miss 1234 5678numa_foreign 5678 1234interleave_hit 1000 1000local_node 12340000 11230000other_node 5678 4567# 查看特定进程的NUMA内存分布numastat -p <pid>关键指标解读:
• numa_hit:成功从本地节点分配内存的次数 • numa_miss:本地节点内存不足,从远程节点分配的次数 • local_node:进程在本地节点分配的内存页数 • other_node:进程在远程节点分配的内存页数
如果numa_miss或other_node值较高,说明存在跨NUMA节点的内存访问,需要检查内存绑定策略或增加本地节点的内存容量。
6.4 turbostat:CPU频率与功耗监控
现代CPU的运行频率并非固定值,而是根据负载、温度、功耗等因素动态调整。turbostat可以实时监控CPU的实际运行频率和功耗状态:
root@node:~# turbostat --interval 1Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz- - 1200 45.2 2654 26000 0 1180 44.8 2634 26000 1 1220 45.6 2674 26001 2 1190 45.0 2644 2600当应用性能不达预期时,turbostat可以帮助确认CPU是否因为功耗墙或温度墙而被限频。
6.5 htop:交互式进程监控
htop是top命令的增强版,提供了更直观的交互式界面,可以实时显示每个CPU核心的使用情况、内存占用以及进程状态。
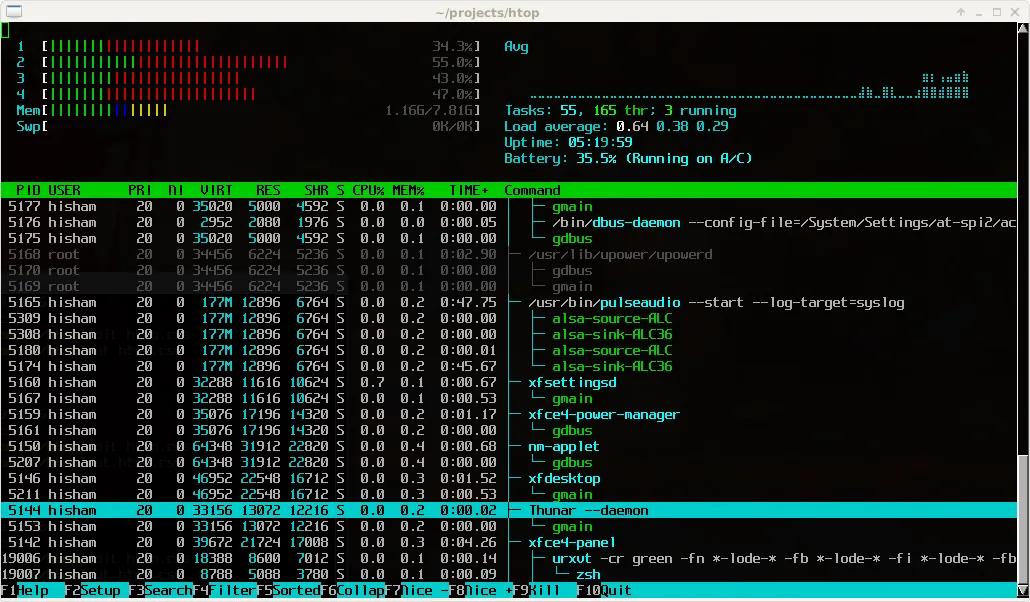
htop的优势在于能够直观地发现负载不均衡的问题。如果某些CPU核心负载很高而其他核心空闲,说明应用的并行度不足或存在线程绑定问题。
6.6 硬件信息查看工具
除了运行时监控,有时还需要确认底层硬件配置是否符合预期:
dmidecode:BIOS和硬件规格
# 查看内存条信息dmidecode -t memory# 查看处理器信息dmidecode -t processorlsmem:内存块和NUMA映射
# 查看内存块分布lsmemRANGE SIZE STATE REMOVABLE BLOCK0x0000000000000000-0x000000007fffffff 2G online yes 0-150x0000000100000000-0x000000107fffffff 62G online yes 32-543这些工具可以帮助发现内存混插、频率不一致、通道未插满等硬件配置问题。
6.7 lstopo:系统拓扑可视化
lstopo(来自hwloc工具包)可以将系统的硬件拓扑以图形或文本方式展示,包括CPU、缓存、NUMA节点、PCIe设备等的层级关系。
# 文本方式输出拓扑lstopo-no-graphics# 输出到图片文件lstopo topology.png对于复杂的多路服务器,lstopo生成的拓扑图可以直观地展示GPU、网卡等设备与CPU的物理距离,帮助优化设备亲和性配置。
6.8 工具矩阵总结
7. 总结
本文系统地介绍了CPU上下文切换的触发场景、观测方法和问题排查思路。从宏观到微观,先用vmstat确认问题存在,再用pidstat定位具体进程,最后结合业务逻辑分析根因。
性能优化的第一步永远是观测和验证。Linux提供了丰富的工具让系统状态透明可见,工程师需要做的是建立系统化的分析思维,将工具输出与业务场景关联起来,找到真正的性能瓶颈。
8. 参考内容
CPU篇
内存篇
磁盘篇
更多ROS、具身智能相关内容,请关注古月居
👉 关注我们,发现更多有深度的自动驾驶/具身智能/GitHub 内容!
🚀 往期内容回顾 👀
🔥 读读代码 | EmbodiChain: 面向具身智能的生成式仿真世界模型深度解析🔥 十分钟实用教程 | BMAD-METHOD 深度解析:当 AI 学会像工程师一样思考🔥 行业杂谈 | 具身智能与机器人学习资源全景图:从SLAM到大模型再到VLA/VLN的技术演进
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 未来3年,最值得大学生学习的,不是Python,而是AI协作能力
- Python 2026:自由线程(无 GIL)来了!从零基础到实战,这条学习路线别再走弯路了
- Python 3.11.3 永久使用教程及安装包下载(附全部版本安装包)
- Linux 基金会推出 Akrites 开源协同防御、千万级 Chrome 扩展存远程注入隐患|6月28日安全动态
- 天花板级Python100道经典题!闭眼狂背,基础直接焊死
- 7python之nginx报错及改用户配置接口
- CTFHub:第七十四关——PHP——GC UAF
- 这20个Linux搞定故障,你的运维水平已经超过80%的人
- DirtyClone:Linux 内核第四个"脏"漏洞,克隆网络包污染内存提权
- [linux 调度器第11讲] 时间片与调度粒度:为什么你的任务跑一会儿就停了?
