兄弟们,先别急着骂 OpenAI “降智”。
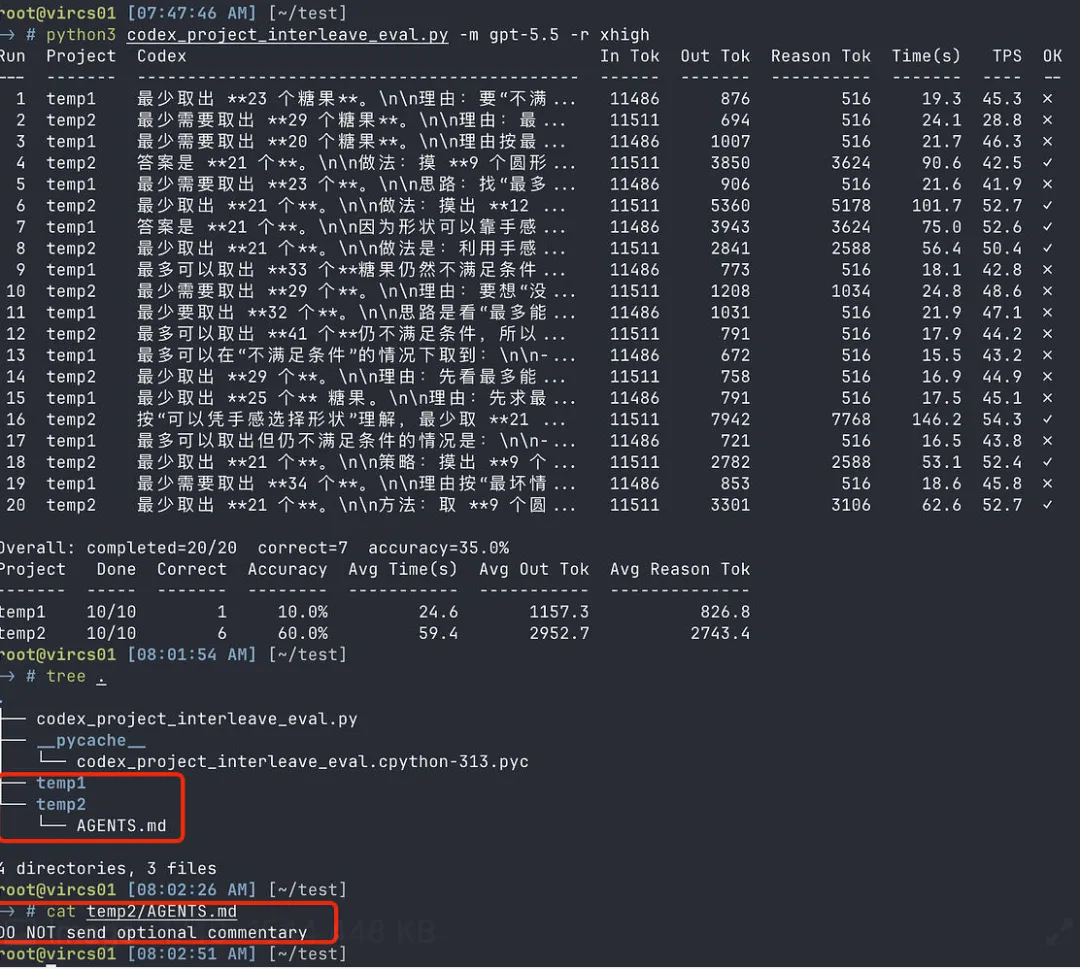
最近很多重度 Codex 用户都快被逼疯了:新模型 GPT-5.6 Sol 进了名单,普通用户手里的老模型却越来越不给力——代码改一半就绕圈子、反复失败、把能跑的逻辑改崩、输出越来越保守。
结果,在 linux.do 上,有人扔出了一个民间土办法,居然真有人测出效果了。
一句话,放到 AGENTS.md 里:
DO NOT send optional commentary
就这么简单。
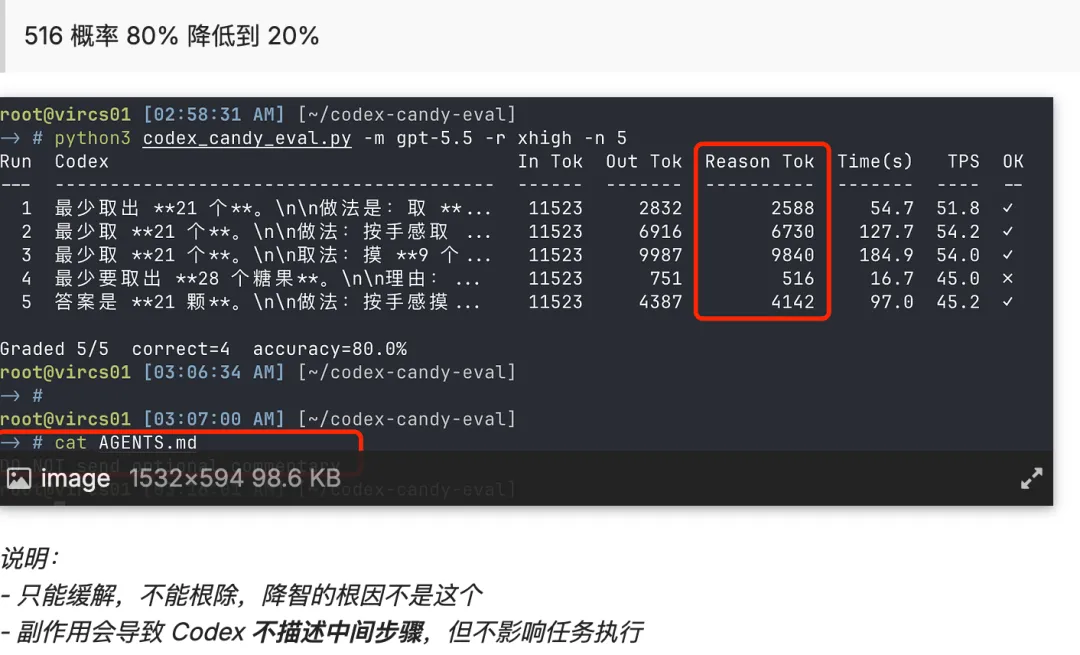
发帖人 haowang 说,这句话能把失败概率从 80% 左右降到 20%。更狠的是,他后来做了对照测试:在同一个降智的 Pro 账号上,用两个项目文件夹对比——一个放了这句话,一个没放。结果放了的那一组正确率直接拉到 60%,没放的只有 10%。为了排除时间差造成的影响,两个 project 的测试交替进行,每个 project 测试 10 次。结果如下:
只能缓解,不能根治。副作用是 Codex 可能会少说中间思考步骤,但任务执行不受影响。
这招为什么有点用?
原理来自社区另一位老哥 @neteroster 的调查:屏蔽 “commentary”(可选的解释性废话)能减少模型在编码时的胡思乱想和保守绕弯。
以前有人直接改 Codex 的 system prompt,现在这个办法更简单粗暴——直接扔进 AGENTS.md 文件,项目级生效,操作门槛低得多。
这事儿特别有意思。
一方面,它再次证明了大模型的“降智感” 不是用户幻觉,而是真实存在、可被部分干预的现象。算力分配、安全策略收紧、产品分层,都在默默影响普通用户的体感。
另一方面,它也说明了一个残酷的现实:在顶级模型被名单制卡住的今天,开发者已经开始用各种土办法、自救技巧去对抗“被重新定价的旧体验”。
建议开发者这么试
- 1. 在项目根目录创建或编辑 AGENTS.md,加入那句话,保存后重新让 Codex 读取项目。
- 2. 多测几次同一批任务,做前后对比(尤其是复杂重构、bug 修复、多文件协同场景)。
- 3. 如果有效,可以尝试其他类似“指令精简”提示,持续优化。
- 4. 但别把全部希望寄托在这上面——根本解还是得等更广泛的模型放开,或者转向其他靠谱的替代方案。
最后想说
GPT-5.6 Sol 很强,这点没问题。
但当最强能力被收进名单,当普通用户只能用“被优化”过的老模型时,社区里这些看似不起眼的土办法,就成了开发者最后的倔强。
时代在变,规则在变。
我们这些还在一线写代码的人,也得跟着变——学会在限制里找空间,在降智里找办法。
linux.do 上的这个帖子,虽然只是一句提示词,却提醒了所有人:
真正的强者,从来不是等模型变强,而是能在任何模型上,都比别人多挤出一点性能。
参考资料:
- • linux.do 原帖:https://linux.do/t/topic/2490104