李白一生写了有1000多首诗,在我们记忆的深处,李白总是与“白发三千丈”的夸张、“天生我材必有用”的狂傲以及“举杯邀明月”的潇洒联系在一起。然而,当这位“诗仙”走下神坛,他的文字在计算机的客观审视下,又会呈现出怎样的面貌?今天,作为《代码里的人文》系列的第一期,我们用Python 代码对《全唐诗》中收 录的李白诗歌进行数字化文本分析。让我们剥离感性的刻板印象,用数据解构这位浪漫主义灵魂背后的“核心高频密码”。要用代码解构李白的诗,首先得有源头活水。这里我们借助了 GitHub 上著名开源项目 chinese-poetry (最全中华古诗词数据库)。我选择其中的“全唐诗”下载,根据命名规则可以看出来,代表唐诗的JSON文件名格式如下:poet.tang.*.json,因此,我们可以拷贝出所有的唐诗。打开其中一个JSON文件,我们可以看到里面的存储结构:
{ "author": "李白", "paragraphs": [ "金樽清酒斗十千,玉盤珍羞直萬錢。", "停杯投筯不能食,拔劒四顧心茫然。", "欲渡黃河冰塞川,將登太行雪滿山。", "閑來垂釣碧溪上,忽復乘舟夢日邊。", "行路難,行路難,多岐路,今安在。", "長風破浪會有時,直挂雲帆濟滄海。" ], "tags": [ "唐诗三百首", "黄河", "励志", "友情", "八年级下册(课内)", "初中古诗", "乐府", "宴饮", "哲理", "怀才不遇" ], "title": "行路難三首 一", "id": "c348bc2e-f50d-436b-88b7-c198d63dacfc"}
其中,author代表作者名,paragraphs代表诗歌具体内容,tags代表诗歌的标签以及情感,title代表诗名,id是一个序列号。
接下来,我们编写一段 Python 脚本。为了避免繁简转换导致的统计误差,我们引入了 OpenCC 进行繁简统一,把李白的诗歌全部筛选并提取出来:
def load_li_bai_poems(): """加载所有李白诗歌""" all_poems = [] json_files = glob.glob(os.path.join(TANG_POETRY_DIR, 'poet.tang.*.json')) print(f"找到 {len(json_files)} 个唐诗JSON文件") for json_file in json_files: with open(json_file, 'r', encoding='utf-8') as f: poems = json.load(f) for poem in poems: # 转换繁体为简体后比较 author = cc.convert(poem.get('author', '')) if author == '李白': # 转换诗歌内容为简体 paragraphs = [cc.convert(p) for p in poem.get('paragraphs', [])] title = cc.convert(poem.get('title', '')) tags = [cc.convert(t) for t in poem.get('tags', [])] all_poems.append({ 'title': title, 'paragraphs': paragraphs, 'tags': tags }) print(f"共找到 {len(all_poems)} 首李白的诗歌") return all_poems
🧠第二步:自然语言处理,属于算法的“归一化”浪漫
拿到了诗歌文本,该如何分析李白最爱写什么?
这里我提取李白写的最多的十个名词,因为名词可以更好的表达出李白写的内容,其余的语气词和助词无法表现出李白所描述的主要内容。名词的切分主要使用 Python 著名的 NLP 工具包 jieba 。
我们还可以把一些自定义的词作为名词给出,这样,当程序识别到我们自定义的词后会将其认为是名词,如:“月”、“风”、“山”、“水”、“云”、“天”等。
这里还有一个要注意的地方,因为”明月“、”皓月“、”江月“、”新月“等等都是”月“,如果都按每个名词统计的话,单字“月”出现的次数会大大减少,无法还原诗人脑海中真实描绘的意象。
因此,我们在使用 jieba 进行分词提取名词的同时,必须建立一套“意象归一化(Normalization)规则”:
核心思想:我们将自然语言处理中的“同义词合并”思想注入古典文学,自定义了一个意象映射字典,如:
【月相关】:明月、皓月、月色、月光、皎月 → 月
【山相关】:青山、碧山、苍山、远山 → 山
【酒相关】:美酒、清酒、浊酒、芳酒 → 酒
【天相关】:青天、蓝天、苍天、碧天 → 天
# 定义归一化规则normalization_rules = { # 月相关 '明月': '月', '皓月': '月', '皎月': '月', '新月': '月', '满月': '月', '月色': '月', '月光': '月', '月华': '月', '月明': '月', # 天相关 '青天': '天', '蓝天': '天', '碧天': '天', '苍天': '天', '九天': '天', '天空': '天', '天际': '天', # 云相关 '白云': '云', '浮云': '云', '青云': '云', '乌云': '云', '彩云': '云', '云彩': '云', '行云': '云', '闲云': '云', # 山相关 '青山': '山', '碧山': '山', '苍山': '山', '秀山': '山', '寒山': '山', '远山': '山', '群山': '山', '山河': '山', # 水相关 '绿水': '水', '碧水': '水', '清水': '水', '江水': '水', '河水': '水', '湖水': '水', '泉水': '水', '海水': '水', '溪水': '水', # 风相关 '春风': '风', '秋风': '风', '西风': '风', '东风': '风', '北风': '风', '南风': '风', '寒风': '风', '暖风': '风', '微风': '风', '长风': '风', # 花相关 '桃花': '花', '梅花': '花', '菊花': '花', '兰花': '花', '桂花': '花', '杏花': '花', '荷花': '花', '梨花': '花', '百花': '花', '春花': '花', # 鹤相关 '白鹤': '鹤', '黄鹤': '鹤', '仙鹤': '鹤', '孤鹤': '鹤', '云鹤': '鹤', # 酒相关 '美酒': '酒', '清酒': '酒', '浊酒': '酒', '浊酒': '酒', '芳酒': '酒', # 人相关 '美人': '人', '故人': '人', '新人': '人', '人人': '人', '世人': '人', '诗人': '人', '骚人': '人', '游子': '人', '征夫': '人', '思妇': '人', # 鸟相关 '黄鹂': '鸟', '黄鸟': '鸟', '白鹭': '鸟', '飞鸟': '鸟', '百鸟': '鸟', '啼鸟': '鸟', '宿鸟': '鸟', '归鸟': '鸟', # 树相关 '绿树': '树', '青树': '树', '碧树': '树', '古树': '树', '老树': '树', # 草相关 '芳草': '草', '青草': '草', '绿草': '草', '春草': '草', '细草': '草', # 路相关 '长路': '路', '道路': '路', '路途': '路', '陌路': '路', '歧路': '路',}
同时,我们在代码中过滤掉了无意义的代词、介词和助词(如:我、你、之、于、与、和、而、以、为 等),只保留含金量最高的“名词”。def extract_nouns(text, custom_dict_set): """从文本中提取名词""" words = pseg.cut(text) nouns = [] for word, flag in words: # 提取名词 (n开头的词性标记) 或在我们的自定义词典中 if flag.startswith('n') or word in custom_dict_set: if len(word) == 1 and word in ['我', '你', '他', '她', '它', '此', '其', '之', '于', '与', '和', '而', '以', '为']: continue # 过滤单字标点和数字 if len(word) >= 1 and not word.isdigit(): nouns.append(word) return nouns
提取出名词后,我们需要对名词进行归一化,最后进行统计,看看是哪个类型的词最多。
def analyze_nouns(poems): """分析诗歌中的名词""" # 初始化jieba加载自定义词典 for line in custom_dict.strip().split('\n'): if line.strip(): word = line.strip().split()[0] # 只取词语部分 jieba.add_word(word, freq=100, tag='n') # 构建自定义词典集合 custom_set = set() for line in custom_dict.strip().split('\n'): word = line.strip() if word: custom_set.add(word) all_nouns = [] for poem in poems: # 合并所有诗句 text = ''.join(poem['paragraphs']) # 提取诗歌中的名词 nouns = extract_nouns(text, custom_set) all_nouns.extend(nouns) # 归一化处理,把同类的名词都算成是一类 normalized_nouns = normalize_nouns(all_nouns) # 统计词频 noun_counts = Counter(normalized_nouns) return noun_counts
最后,我们通过柱状图和词云来展示到底最多的十个词是什么,我们可以期待一下😀
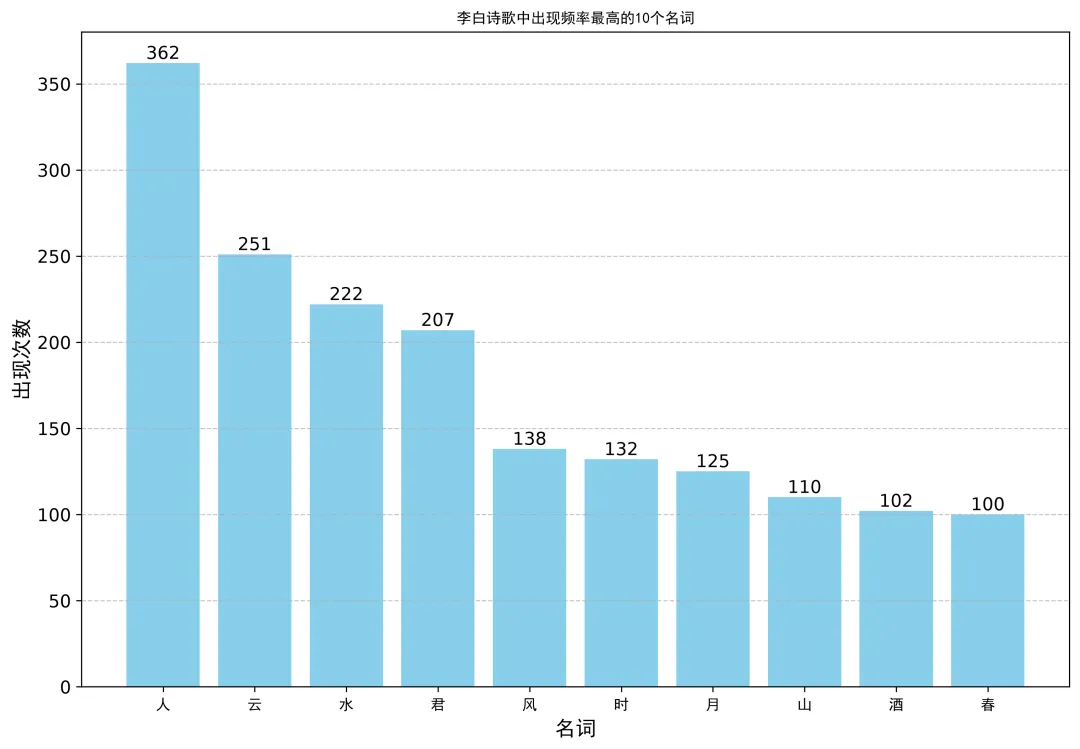
通过对李白诗歌名词的统计,排名前十的高频词依次是:
人 → 云 → 水 → 君 → 风 → 时 → 月 → 山 → 酒 → 春
除去“人”、“君”、“时”等社会属性词汇外,李白宇宙的核心是由“云、水、风、月、山、酒、 春”构成的。这简直是一幅完美的中国山水写意画。他的生性豁达与大度,在这些与自然、美酒交融的词汇中得到了完美的数字化印证。真正走入他内心的核心意象,莫过于“月”、“山”、“酒”。
我们还可以对以上程序进行修改,只要将author改成“杜甫”,我们就可以看到杜甫的诗歌中频率最高的几个词。
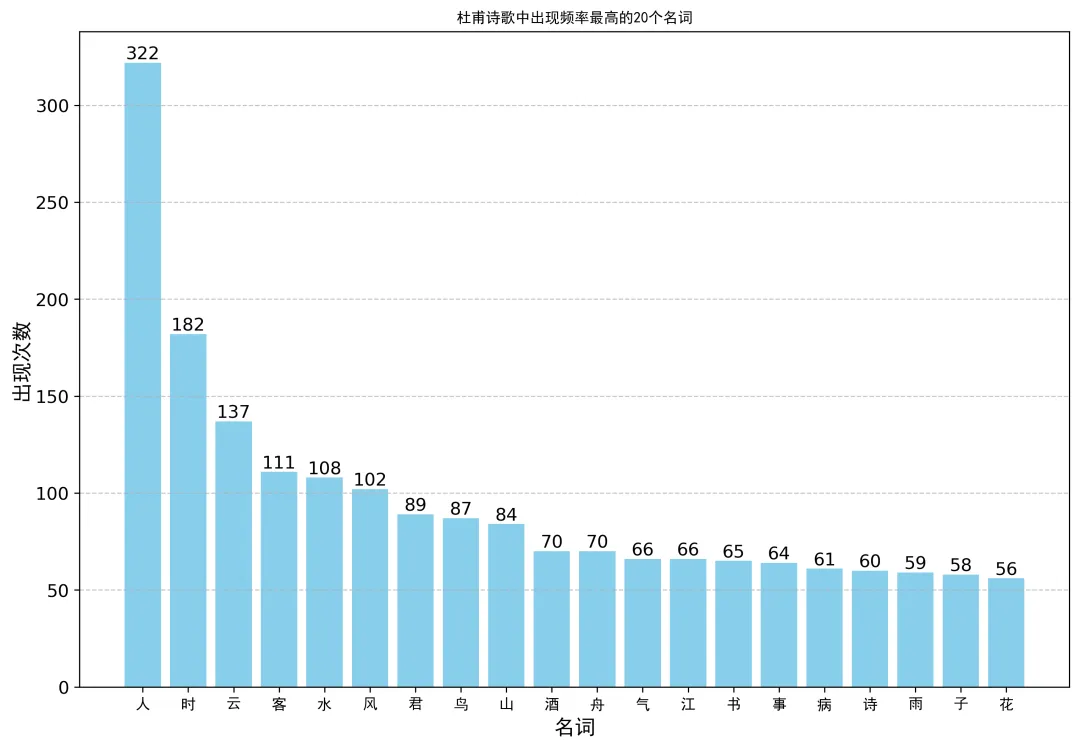
当我们把统计范围放宽到前 20 个高频词时,属于“诗圣”杜甫的词频特征呈现出了完全不同的生命质感。在杜甫的诗中,除了同样高频的“人”和自然意象外,极其刺眼地闪现出 了“客”、“鸟”、“舟”、“气”、“病”、“事”、“花”等词汇:
“客”:是颠沛流离、寄人篱下的羁旅之苦。
“舟”:是老病孤舟、漂泊无依的现实写照。
“病”与“气”:更是直接暴露出这位忧国忧民的伟大诗人,在晚年身体与精神上承受的沉重苦难。
同样活在大唐,李白的代码输出是一场“风月与美酒”的太空漫游;而杜甫的代码输出,则是“老病与羁旅”的现实大地。
✍四、结论:当人文有了数字的刻度
从冰冷的数据和严格的代码中,我们没有破坏诗歌的意境,反而通过可视化的坐标,更深地读懂了他们的灵魂。李白之所以是“诗仙”,是因为他的高频词里藏着不属于凡间的“云、风、月、酒”。他的浪漫与豪放,不仅仅是文学选集的粉饰,更是他一生真真切切、高频重复的生命体验。
下一篇我们将来看一看李白的诗歌的情感色彩是怎样的,以及他与杜甫的内心情感差别有多大。