在云原生环境中,网络丢包是最让人头疼的问题之一(应用日志报连接超时,TCP 重传率飙升),但丢包发生在内核协议栈的哪个环节?是防火墙规则丢弃、路由查找失败、还是接收缓冲区溢出?传统的 dropwatch 或 perf record -e skb:kfree_skb 只能给出丢包地点的符号地址,缺乏数据包上下文,难以快速判断丢包是否影响了业务流量。
HUATUO 项目的 dropwatch 工具从内核 Tracepoint tracepoint/skb/kfree_skb 出发,在 eBPF 探针中一次性采集丢包事件的完整上下文:IP 五元组、进程信息、网络设备、MAC 地址,以及触发丢包的内核调用栈。更重要的是,它支持 tcpdump 风格的内核侧过滤——过滤逻辑在加载时被编译为 eBPF 字节码,只有匹配的数据包才会上报到用户空间,避免海量无关丢包事件淹没真正的问题线索。
本文将从实际排查场景出发,介绍 dropwatch 的工作方式、过滤能力、输出结构,以及如何与 huatuo-bamai 集成实现长期丢包观测。
从一个线上问题说起
某 Kubernetes 集群中,订单服务的 P99 延迟周期性从 50ms 飙升至 2s。应用日志只有零星的 connection reset by peer,而节点上的 netstat -s 显示 TCPLostRetransmit 在持续增长。
传统的排查路径是:先 tcpdump 抓包确认对端是否收到 SYN,再 iptables -L 检查规则,再 ip route get 验证路由,最后 perf record -e skb:kfree_skb 看内核丢包点——整个流程至少需要 30 分钟,而且 perf 输出的符号地址还需要手动对照内核符号表。
用 dropwatch,一条命令就能定位:
sudo dropwatch --bpf-path bpf/dropwatch.o \ --filter "tcp and port 8080"\ --device eth0 \ --duration 60\ --output json
输出中每条事件都携带了完整的丢包上下文:哪个进程的包被丢、源目 IP 和端口、丢包发生时的内核调用栈。结合 jq 过滤,几秒内就能找到根因。
内核侧过滤:把无关丢包挡在内核态
生产环境中 kfree_skb 的触发频率极高——邻居表清理、套接字关闭、驱动 DMA 完成等都会触发,但它们并不是业务层面的丢包。如果在用户空间逐条过滤,不仅 CPU 开销高,还会丢失真正关键的丢包信号。
dropwatch 的方案是将过滤逻辑下沉到内核态执行。它内置了一个纯 Go 实现的 pcap 编译器 internal/pcapfilter,在 eBPF 程序加载时将 tcpdump 风格的过滤表达式编译为 eBPF 字节码,直接嵌入探针逻辑。只有匹配的数据包才会通过 perf ring buffer 上报到用户空间。
过滤原语
internal/pcapfilter 实现了 tcpdump 标准语法的一个实用子集:
协议与方向
ip ip6 tcp udp icmp icmp6 arpip proto tcp ip6 proto udpsrc host 10.0.0.1 dst host 10.0.0.1src port 443 dst port 8080src net 192.168.1.0/24
布尔组合
tcp and port 443tcp or udpnot arpip and src net 192.168.1.0/24 and tcp dst port 3306
过滤实战
# 只监控目标端口的 TCP 丢包--filter "tcp and port 443"# 排除元数据服务 IP 的噪声--filter "tcp and not host 169.254.169.254"# 精确锁定某个子网到数据库端口的丢包--filter "src net 192.168.1.0/24 and tcp dst port 3306"
--filter 与设备过滤(--device / --device-excluded)相互正交,同时指定时两者均生效(AND 语义)。设备白名单会丢弃没有 net_device 的 SKB,黑名单则放行——这在容器 veth 设备场景下尤其有用。
事件输出:结构化的丢包上下文
每条丢包事件以 NDJSON 格式输出,核心字段如下:
{ "observed_timestamp":"2026-06-20T08:30:12.123456789Z", "comm":"nginx", "pid":4521, "container_id":"a1b2c3d4", "netdev_name":"eth0", "packet_eth_proto":"0x0800", "packet_len":74, "layers":{ "label":"IPv4/TCP", "ether": {"src":"aa:bb:cc:dd:ee:ff","dst":"11:22:33:44:55:66","type":"IPv4"}, "ipv4":{"src":"10.0.1.5","dst":"10.0.2.10","ttl":64,"protocol":"TCP"}, "tcp":{"sport":54321,"dport":8080,"flags":"SYN","seq":0,"ack":0,"window":65535,"sk_state":"SYN_SENT"}}, "stack":"kfree_skb\ntcp_v4_rcv\ntcp_rcv_established\n..."}
几个值得关注的字段:
layers分层协议解析结果,每层为一个嵌套对象,缺失的层自动省略。不再依赖单独的协议枚举,下游消费者直接用字段存在性判断协议组合(如 ev.Layers.TCP != nil)。stack触发丢包的完整内核调用栈,换行分隔。这是区分丢包原因的关键——同样是 TCP 丢包,tcp_v4_rcv 和 ip_output 对应的排查方向完全不同。container_id由 huatuo-bamai 根据内存 cgroup CSS 地址或网络命名空间 cookie 解析填充,直接关联到 Kubernetes Pod。netdev_linkstatus网络设备链路标志数组,可用来判断设备是否处于 carrier-down 或 dormant 状态。
layers 各层的完整字段列表:
用 jq 做用户态过滤
当内核侧过滤不够精细时,可以在用户态用 jq 对 JSON 输出做二次筛选:
# 只看 RST 包sudo dropwatch --bpf-path bpf/dropwatch.o --output json | jq 'select(.layers.tcp.flags == "RST")'# 排除调用栈包含 ip_finish_output 的事件(通常是正常路由输出)sudo dropwatch --output json --duration 10 --bpf-path bpf/dropwatch.o \| jq -c 'select(.stack | test("ip_finish_output") | not)'# 只看元数据,不打印调用栈(适合快速统计丢包分布)sudo dropwatch --output json --duration 10 --bpf-path bpf/dropwatch.o \| jq -c 'del(.stack)'
jq -c 将每条事件压缩为单行 JSON,便于保存为 NDJSON 文件或继续管道处理。
噪声过滤:屏蔽非数据面丢包
并非所有 kfree_skb 事件都是真正的数据面丢包。以下三类事件在默认配置下会被 huatuo-bamai 过滤:
| | |
|---|
TCP CLOSE_WAIT + skb_rbtree_purge | | 正常的套接字关闭:内核释放 CLOSE_WAIT 状态套接字中飞行中的 SKB |
| | |
| bnxt_tx_int/ | Broadcom bnxt 驱动在 DMA 发送完成后释放 SKB,是正常行为 |
在 huatuo-bamai 配置中,噪声规则通过 EventTracing.IssuesList 管理:
[EventTracing] IssuesList =[["neigh_invalidate","neigh_invalidate"],["bnxt_tx_int","bnxt_tx_int"]][EventTracing.Dropwatch] Filter ="tcp" MaxEventsPerSecond =100
如果需要观察邻居表相关的丢包(例如调试 ARP 风暴),可以从 IssuesList 中移除对应规则。
与 huatuo-bamai 集成:长期丢包观测
单次运行 dropwatch 适合临时排查,但生产环境更需要持续的丢包观测。huatuo-bamai 以子进程方式启动 dropwatch,通过 --output-storage 将事件经 Unix socket 发送到内置处理流程,最终存储至 Elasticsearch。
dropwatch \ --bpf-path <CoreBpfDir>/dropwatch.o \ --output-storage /var/run/huatuo/events.sock \ --filter "tcp"
存储后可以实现:
- 时间线关联在 Grafana 中将丢包事件叠加到应用延迟曲线上,对齐丢包时间点与延迟 spike
- 多维聚合按
container_id、netdev_name、layers.label 聚合丢包分布,快速锁定问题 Pod 或设备 - 历史回溯保留丢包事件的完整上下文,支持事后根因分析,无需复现问题
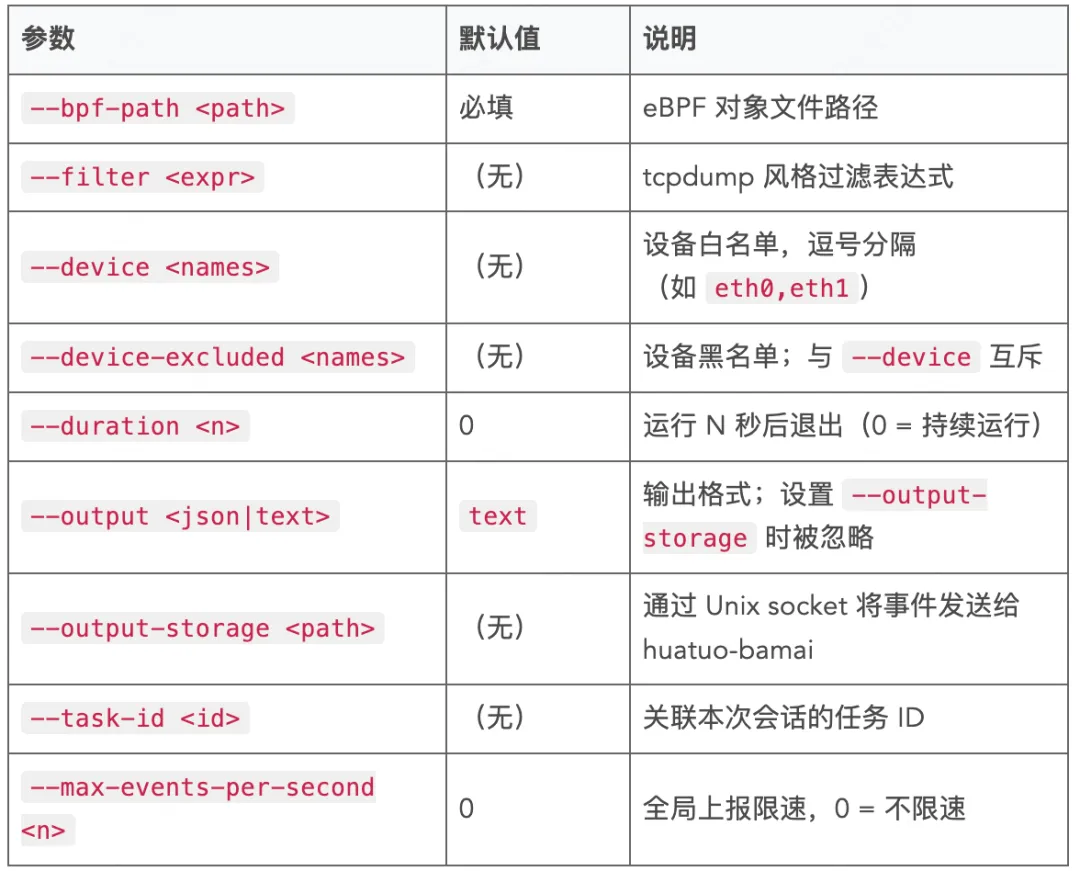
全部命令行参数
小结
网络丢包的排查难点在于:丢包发生在内核协议栈深处,传统工具缺乏数据包上下文,难以判断丢包是否影响了业务流量。dropwatch 通过 eBPF 探针在 kfree_skb Tracepoint 上采集完整的丢包上下文,并将过滤逻辑编译为 eBPF 字节码在内核态执行,在不影响宿主机性能的前提下,将关键丢包事件精准地呈现给运维人员。
配合 huatuo-bamai 的持续集成能力,dropwatch 可以从"临时排查工具"升级为"长期丢包观测基础设施",将内核丢包与应用异常在时间线上精确关联,把网络丢包的定位从"猜测 + 验证"转变为"观测 + 归因"。
项目地址:https://github.com/ccfos/huatuo

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
