大家好,我是木木。
今天给大家分享一个灵活的 Python 库,ibis。
ibis
ibis 是一个可移植的 DataFrame 表达式库。它让你用 Python 写类似 DataFrame 的链式表达式,然后把表达式执行在不同后端上,比如 DuckDB、SQLite、PostgreSQL、BigQuery、Snowflake、ClickHouse、Polars 等。它的思路不是把所有数据都拉进本地,而是先构建惰性表达式,再交给后端编译和执行。对经常在本地和数据仓库之间切换的团队来说,这种统一 API 很有价值。
项目地址:https://github.com/ibis-project/ibis
官方文档:https://ibis-project.org/
三大特点
惰性表达式
先描述计算逻辑,真正执行时再交给后端处理,适合复杂查询组合。
后端丰富
同一套 API 可以面向本地 DuckDB,也可以迁移到云端数据仓库。
SQL 友好
表达式可以编译成 SQL,方便调试、审查和与现有 SQL 工作流衔接。
最佳实践
安装方式:pip install "ibis-framework[duckdb]"。
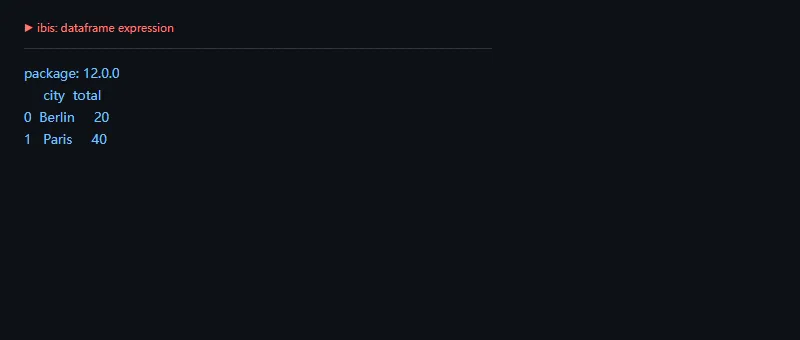
第一段代码解决的问题是:用 Ibis 的 DataFrame 表达式做分组聚合。这里使用内存表执行,能看到 Ibis API 和 pandas 的形态很接近。
importibisfromimportlib.metadataimportversiont=ibis.memtable({"city":["Paris","Berlin","Paris"],"sales":[10,20,30]})expr=t.group_by("city").aggregate(total=t.sales.sum()).order_by("city")print("package:",version("ibis-framework"))print(expr.execute())
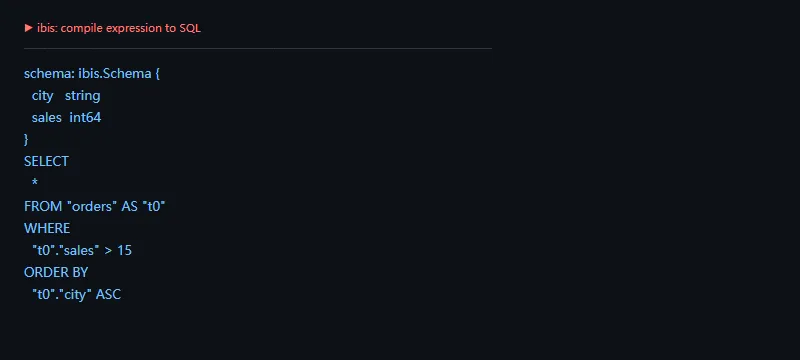
第二段代码解决的问题是:把 Python 表达式编译成 SQL。这个能力很适合排查“我写的表达式到底会变成什么查询”。
importibist=ibis.table([("city","string"),("sales","int64")],name="orders")expr=t.filter(t.sales>15).select("city","sales").order_by("city")print("schema:",expr.schema())print(ibis.to_sql(expr))
环境与版本信息
本文示例使用 Python 3.11.0、ibis-framework 12.0.0、duckdb 1.5.2。示例全部在本地执行,不连接远程数据库。
高级功能
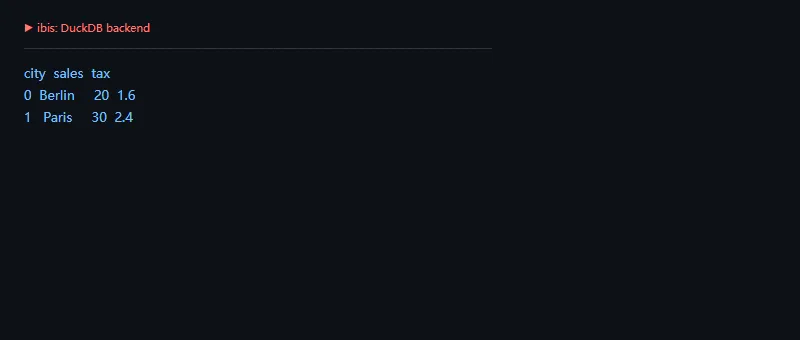
进阶一点看后端执行。Ibis 可以连接 DuckDB,把 Python 表达式交给 DuckDB 运行。以后如果切到其他后端,很多上层表达式可以保持相似结构。
importibiscon=ibis.duckdb.connect()t=con.create_table("orders",{"city":["Paris","Berlin","Paris"],"sales":[10,20,30]},temp=True)expr=t.filter(t.sales>=20).mutate(tax=t.sales*0.08).order_by("city")print(expr.execute())
适用场景
适合需要跨后端迁移的数据分析、SQL 生成、Notebook 探索、本地 DuckDB 原型、云数据仓库查询编排,以及希望用 Python 表达复杂查询逻辑的团队。
不适用场景
不适合只做很小规模的 pandas 清洗,也不适合完全依赖某个数据库专有语法且不需要可移植性的项目。复杂表达式仍要理解后端实际执行计划。
上线检查
- 明确生产后端,安装对应 extra 依赖。2. 对关键表达式输出 SQL 做审查。3. 注意不同后端的数据类型、空值和时间语义差异。4. 大查询先限制数据量或用临时表验证成本。
总结
ibis 把 Python DataFrame 写法和 SQL 后端连接得很自然。它适合那些既想保留 Python 表达力,又不想被单一执行引擎锁住的数据工作流。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
