Python酒店评论情感分类:TF-IDF、SVM、LSTM多模型对比与LDA主题建模服务优化|附AI智能体、代码和数据
- 2026-07-02 20:53:46
随着在线旅游平台的蓬勃发展,酒店评论已成为消费者决策的重要参考依据(点击文末“阅读原文”获取完整智能体、代码、数据、文档)。

Python酒店评论情感分析:TF-IDF、SVM、LSTM、CNN多模型对比与酒店服务优化研究
引言
本文基于某酒店预定平台的评论数据,综合运用TF-IDF特征提取、多种机器学习分类算法及LDA主题建模技术,构建了一套完整的酒店评论情感分析方案。
互联网用户群体的急剧扩大使人们普遍养成了通过网络表达个人看法、获取实用信息的习惯。文字、视频、图片及评论均包含用户潜在的情感倾向,具有极高的研究价值。对于企业而言,从互联网平台获取消费者评论数据相比传统问卷调查更加高效且质量更高。
在文本分析中,聚焦重点至关重要。评论文本的主客观情感分析是从中提取用户偏好的最基础、最重要的补充。因此,通过研究用户情感倾向并将其应用于预测、决策支持等领域,成为近年来的研究热点。
内容提要
1. TF-IDF算法如何从海量评论中提取影响情感分类的关键特征词?
2. SVM、逻辑回归、随机森林、LSTM、CNN等主流模型的性能差异如何?
3. 如何通过情感分析与主题建模识别酒店服务中的优势与不足?
正文
1
研究背景与情感分析概述
情感分析(Sentiment Analysis),又称意见挖掘(Opinion Mining),是文本挖掘领域的核心方向,旨在从文本数据中识别和提取主观信息。该技术广泛应用于社交媒体监测、客户反馈分析、市场研究等多个领域。在酒店行业情境下,情感分析帮助酒店管理者深入理解客户满意度、识别客户需求、评估服务质量,从而制定更优的经营策略。
传统情感分析方法主要包括基于规则的方法和基于词典的方法。规则方法依赖人工编制的规则和模式,适用于结构化文本;词典方法则利用情感词典(如SentiWordNet)为词汇赋予情感得分。近年来,随着机器学习技术的进步,基于机器学习的情感分析方法逐渐占据主导地位。这些方法从大规模数据集中学习,自动识别情感倾向,能够更有效地处理酒店评论等复杂文本数据。
酒店评论情感分析面临的主要挑战包括:评论数据的情感倾向多样性、中文表达的多样性与隐性表达使得提取关键影响因素成为难点,评分预测任务中数据的非规则性也对模型选择提出了更高要求。
2
数据来源与预处理流程
本研究所用的酒店评论数据集来自某国际酒店预定平台,涵盖多种类型的酒店评论。评论数据包含文本内容和对应的评分等级(1-5分),能够支持情感分类与评分预测两类任务。
原始评论数据需经过系统预处理,以去除噪声并保留核心信息。预处理流程包括:去除HTML标签与特殊字符、统一文本编码、移除停用词(如“的”“了”“是”等功能词)、进行英文tokenization。对于英文评论,采用TF-IDF模型进行特征向量化。

注:预处理后数据样例
资料来源:酒店预定平台评论数据
3
TF-IDF特征提取与词云可视化
TF-IDF(词频-逆文档频率)算法的核心思想是:一个词在特定文档中出现频率高,但在整个语料库中出现频率低,则该词对这篇文档具有较高重要性。TF-IDF值由词频(TF)与逆文档频率(IDF)相乘得到。
通过TF-IDF算法对正向评论进行关键词提取,并生成词云图进行可视化展示。高频关键词包括:“good”(良好)、“service”(服务)、“very”(非常)、“convenient”(便利)、“breakfast”(早餐)、“facilities”(设施)、“clean”(清洁)、“environment”(环境)等。

注:好评关键词词云图
资料来源:酒店评论数据集TF-IDF分析
4
TF-IDF关键词评分详细分析
TF-IDF得分分析显示,“good”得分最高,表明客户对酒店整体体验持积极态度;“service”紧随其后,说明服务质量是客户评价的核心关注点;“very”频繁出现表明客户常通过程度副词强化正面体验(如“very comfortable”)。此外,“convenient”(便利性)、“breakfast”(早餐)、“environment”(环境)等词汇的高频出现,为酒店继续保持和强化这些优势提供了数据支撑。

注:TF-IDF正面评论关键词得分
资料来源:酒店评论数据集分析
在负面评论中,TF-IDF提取到的高频词包括:“staff”(员工)、“room”(房间)、“dirty”(脏)、“noise”(噪音)、“small”(小)、“old”(陈旧)、“expensive”(贵)。这些词汇直接指向客户不满的核心来源——人员服务、卫生状况、环境噪音和设施老旧。
5
机器学习模型训练与评估
本研究选用六种主流分类算法进行对比实验:支持向量机(SVM)、逻辑回归、随机森林、朴素贝叶斯、多层感知器(MLP),以及LSTM和CNN两种深度学习模型。所有模型均以TF-IDF特征向量作为输入,数据按8:2比例划分训练/测试集,采用简单交叉验证方法评估泛化性能。
朴素贝叶斯以贝叶斯原理为基础,结合先验和后验概率,训练速度最快。随机森林是一种Bagging类集成算法,通过组合多个弱分类器,具有较高的精确度和泛化性能。逻辑回归在线性回归基础上通过sigmoid函数转换,可处理多分类问题。支持向量机通过构建几何间隔最大的超平面进行分类,在处理高维稀疏文本特征时具有显著优势。
模型优化方面采用了交叉检验方法:将样本数据随机分为训练集(70%)和测试集(30%),重复多次训练与验证,选择损失函数评估最优的模型和参数。此外,在数据预处理时充分考虑了英文文本自身的特点,调参时用到控制变量法和交叉检验法。
6
深度学习模型与综合性能对比
除了传统机器学习模型,本研究还尝试了长短期记忆网络(LSTM)和卷积神经网络(CNN)两种深度学习模型。然而,LSTM和CNN在本次实验中未能发挥预期效果,准确率和召回率均为0.376,远低于传统方法。核心原因在于数据量不足以支撑深度学习模型的参数训练。
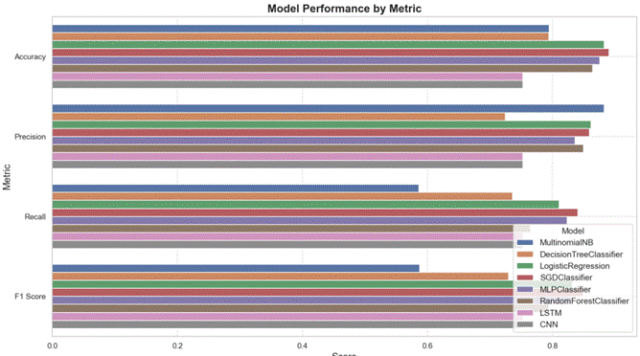
注:机器学习模型性能对比图表
资料来源:酒店评论数据集模型评估
模型性能汇总
SVM:准确率0.891,精确率0.862,召回率0.879,F1分数0.864(综合最佳)
逻辑回归:准确率0.883,精确率0.841,召回率0.858,F1分数0.832
MLP:准确率0.875,精确率0.839,召回率0.856,F1分数0.830
随机森林:准确率0.822,精确率0.818,召回率0.765,F1分数0.780
决策树:准确率0.790,精确率0.762,召回率0.743,F1分数0.725
朴素贝叶斯:准确率0.764,精确率0.882,召回率0.586,F1分数0.587
LSTM/CNN:准确率0.376,精确率0.376,召回率0.376,F1分数0.376
7
LDA主题建模分析
LDA(隐含狄利克雷分布)是一种三层贝叶斯主题模型,由Blei于2003年提出,通过无监督学习方法发现文本中隐含的主题信息。LDA是一种概率生成模型,假设每个文档由多个主题混合而成,每个主题又由一组词语构成。

注:LDA主题分析结果
资料来源:酒店评论数据集LDA建模
差评主题分析揭示了客户不满的五个主要维度:
清洁问题——与“spiders”(蜘蛛)、“clutter”(杂乱)、“dirty”(脏)等词汇高度关联,直接指向酒店的卫生管理水平。
设施陈旧——“old”(老旧)、“broken”(损坏)、“worn”(磨损)等词汇高频出现,反映设施维护不足。
服务效率与态度——“front desk”(前台)、“staff”(员工)、“rude”(粗鲁)等词汇暴露了前台接待和员工培训的短板。
位置与配套——“remote”(偏远)、“missing”(缺失)、“far”(远)等词汇反映了位置与配套设施的不足。
性价比不匹配——“too expensive”(过贵)、“overpriced”(定价过高)等词汇表明部分客户认为支付的价格与实际体验不匹配。
相关阅读
READ MORE
点击标题查阅往期内容
核心文章链接
| Python实战应用 | gensim包构建LDA模型,并结合t-SNE降维聚类和词云进行结果可视化,采用20个新闻组数据集的一部分进行演示。 | gensim) | |
| Python算法基础 | lda Python包的安装和基本用法,使用路透社新闻语料库示例说明LDA的核心思想。 | lda包) | |
| Python爬虫与LDA结合 | |||
| R语言实现 |
文章亮点概览
- Python可视化进阶
:第一篇Python文章不仅构建LDA模型,还详细展示了如何使用t-SNE进行降维聚类和词云可视化,帮助直观理解主题分布。 - 理论基础与流程
:R语言相关的文章对LDA的假设(如每个文档是主题的混合体,每个主题是单词的混合)、工作原理(如循环遍历文档优化主题分配)以及应用价值(如发现隐藏主题、文档分类)有比较清晰的阐述。 - 完整项目流程
:第三篇文章提供了一个从数据获取(网络爬虫)到主题分析(LDA)的完整项目案例,适合希望了解全流程的读者。
如何获取代码与数据
这些文章通常在其全文链接(如http://tecdat.cn/?p=xxxxx)或文末提供完整代码和数据的获取方式,例如点击“阅读原文”1, 2, 3, 4。
希望这些资源能帮助您深入学习和应用LDA主题模型!
8
模型选择建议与业务落地
对于中等规模的酒店评论情感分类任务,建议优先采用SVM或逻辑回归模型。SVM在处理高维稀疏文本特征时具有显著优势,Logistic Regression则以其简洁的模型结构和稳定的性能表现,成为二分类任务的可靠选择。
在实际业务部署中,建议采用渐进式策略:第一步,使用TF-IDF提取评论关键词,快速识别好评/差评的共性特征,建立基础监控仪表板。第二步,部署SVM或logistic回归模型,实现评论情感的自动分级,减少人工审核成本。第三步,结合LDA主题模型,定期分析评论主题分布变化,及时发现服务质量的波动趋势。第四步,随着数据积累(数万条以上),逐步引入BERT等预训练语言模型,提升情感分析的细粒度和准确率。
9
酒店服务优化方向与改进建议
五大改进方向
清洁管理——客户满意度的基础保障,应加强日常巡检与深度清洁力度。与“dirty”“clutter”等词汇相关的差评比例最高,这是酒店管理者必须优先解决的问题。
设施维护——需定期更新老旧设备,避免因设备损坏影响入住体验。空调故障、WiFi不畅等细节问题往往是差评的导火索。
服务质量——重点关注前台接待效率与员工服务态度,加强员工培训。负面评论中与“staff”相关的词汇出现频率极高。
定价策略——应与提供的服务品质相匹配,避免客户产生“价不符实”的负面感知。建议酒店根据季节和市场需求动态调整定价。
位置信息——应在预订页面充分披露,包括周边交通、餐饮、景点的可达性,避免客户到店后产生落差。
10
对话式AI智能体与未来展望
本文将酒店评论情感分类建模经验沉淀为一个对话式AI智能体,用户无需编写代码即可通过自然语言指令完成以下任务:
任务一:“帮我用TF-IDF提取酒店评论的情感关键词”——智能体自动加载数据、进行文本预处理、提取TF-IDF特征并输出关键词排名。
任务二:“比较SVM和逻辑回归在这个数据集上的表现”——智能体自动划分训练/测试集、训练模型、输出准确率/F1分数对比表。
任务三:“分析最近一个月差评的主要主题”——智能体自动筛选差评数据、运行LDA主题模型、输出主题关键词和分布。
# TF-IDF特征提取
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(max_features=5000, ngram_range=(1, 2))
features = vec.fit_transform(train_texts)
未来研究方向包括:引入BERT、GPT等预训练语言模型进行更细粒度的情感分析;结合多模态数据(图片评论、评分星级)提升预测准确度;构建实时情感监控系统,实现评论情感的实时预警与自动化响应。

本文中分析的完整智能体、数据、代码、文档分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取完整智能体、
代码、数据和文档。