大家好,我是木木。
今天给大家分享一个省力的 Python 库,modin。
modin
modin 是一个尽量兼容 pandas API 的 DataFrame 库,目标是让你通过改一行导入语句,把 pandas 工作流扩展到多核或分布式执行引擎上。典型写法是把 import pandas as pd 换成 import modin.pandas as pd,上层代码尽量保持不变。它很适合 pandas 代码已经很多、但数据量开始变大、单进程执行开始吃力的团队。
项目地址:https://github.com/modin-project/modin
官方文档:https://modin.readthedocs.io/
三大特点
迁移成本低
大多数代码仍然按 pandas 风格写,先从替换导入语句开始。
执行引擎可选
可以配合 Ray、Dask、Unidist 等引擎扩展执行能力。
适合渐进优化
不需要一开始重写整套数据处理逻辑,可以先找热点流程试点。
最佳实践
安装方式:pip install modin;生产环境通常会选择 modin[ray]、modin[dask] 或其他引擎组合。本文为了截图稳定,使用 MODIN_ENGINE=python 运行小样本。
第一段代码解决的问题是:保持 pandas 风格的 DataFrame 和 groupby 写法,同时确认对象来自 modin.pandas。
importosos.environ["MODIN_ENGINE"]="python"importmodin.pandasaspdfromimportlib.metadataimportversiondf=pd.DataFrame({"city":["Paris","Berlin","Paris"],"sales":[10,20,30]})print("package:",version("modin"))print("module:",type(df).__module__)print(df.groupby("city").sales.sum().sort_index())
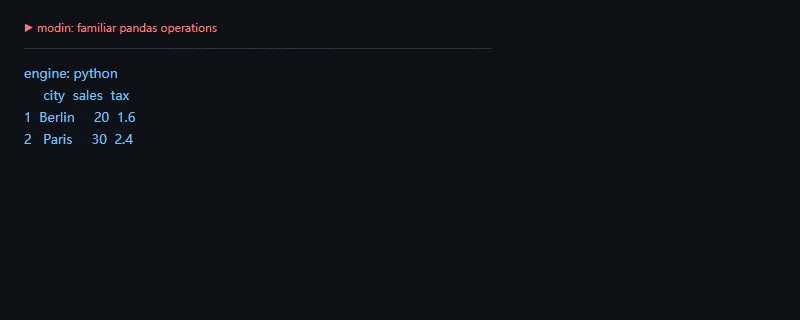
第二段代码解决的问题是:继续使用熟悉的 assign、query 和列选择。迁移时越少改业务代码,越容易先做小范围验证。
importosos.environ["MODIN_ENGINE"]="python"importmodin.pandasaspddf=pd.DataFrame({"city":["Paris","Berlin","Paris"],"sales":[10,20,30]})result=df.assign(tax=df.sales*0.08).query("sales >= 20")print("engine:",os.environ["MODIN_ENGINE"])print(result[["city","sales","tax"]])
环境与版本信息
本文示例使用 Python 3.11.0、modin 0.37.1、pandas 2.3.3。示例使用 Python engine 跑小数据;真实性能收益通常需要配置 Ray、Dask 或其他并行执行后端。
高级功能
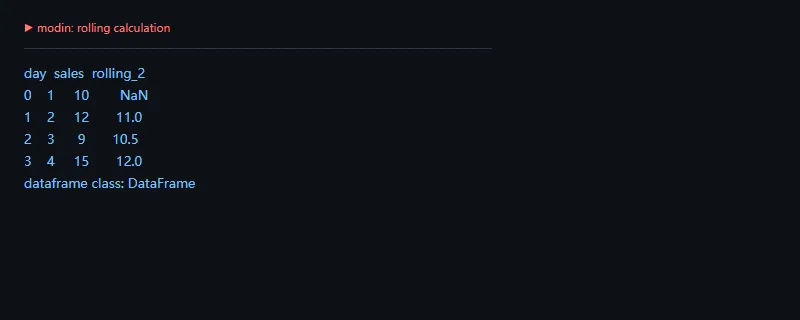
进阶一点看窗口计算。很多 pandas 常用操作在 Modin 中保留相近接口,适合把已有分析脚本逐段迁移,再用真实数据评估兼容性和性能。
importosos.environ["MODIN_ENGINE"]="python"importmodin.pandasaspddf=pd.DataFrame({"day":[1,2,3,4],"sales":[10,12,9,15]})df["rolling_2"]=df.sales.rolling(2).mean()print(df)print("dataframe class:",type(df).__name__)
适用场景
适合已有大量 pandas 代码、数据量逐渐变大、希望用 Ray/Dask 等后端扩展执行、但短期不想重写为 Spark 或 SQL 的团队。
不适用场景
不适合极小数据集,也不适合对每个 pandas API 都要求完全一致语义的高风险流程。遇到未覆盖 API 时可能回退或行为不同,需要实测。
上线检查
- 选定并固定执行引擎,不要在运行中随意切换。2. 用真实数据对关键链路做 pandas 与 Modin 结果对比。3. 观察内存、任务调度和回退到 pandas 的日志。4. 先迁移耗时明显的批处理任务,不要从核心生产链路一口气全换。
总结
modin 的价值在于“少改代码,先试扩展”。它不保证每个场景都比 pandas 快,但对已经有 pandas 资产的团队来说,是一条很实际的渐进优化路线。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
