大厂二面深挖:Linux 如何验证 C++ 类内存布局?
- 2026-07-05 18:23:44

在进行 C++开发的过程中,类的内存布局如同程序底层的建筑方面的规划图一样。它隐匿于代码表面的下方之处。但是它对于程序的性能以及稳定性有着极为深刻的影响。并且它还是深入去理解继承、多态、内存对齐等核心的语法特性的根基所在。搞清楚类成员在内存当中的排列的逻辑,一方面可以精准地去把控内存的开销情况,去适配像嵌入式、大型游戏这类内存资源比较有限的开发的场景。另一方面能够去避免内存对齐方面的损耗、非法的内存访问、多态调用崩溃等那种隐蔽而且难以去处理的 bug。
Linux 具备开源的生态以及完备的开发工具链,这使得对 C++类内存布局进行解析变得较为便利。我们可以利用 GCC 内置的功能来开展静态分析,还能够依靠 gdb 调试器去查看运行时对象真实的内存状况,也能够通过 objdump、readelf 来解析 ELF 二进制文件,从静态和动态这两个方面来校验类完整的内存结构。接下来会一层一层地去拆解各类工具的实操流程,带领你完完全全弄清楚 C++类内存布局底层的细节。
一、理解 C++ 类内存布局基础
面试题写作模版
1.1 为何要弄懂 C++ 类内存布局?
在 C++的编程领域当中,类的内存布局可不是无关紧要的小细节。它对于程序的性能、稳定性以及可维护性有着极大的影响。从性能优化这个方面来说,清楚了解类的内存布局能够帮助我们编写更为高效的代码。就好比在嵌入式系统开发这样对内存使用十分敏感的场景里,内存资源往往是非常有限的,合理的内存布局能够避免不必要的内存浪费情况的出现,从而提升内存的利用率。
又比如说在大数据处理的时候,要是需要创建大量的对象,如果类的内存布局不合理的话,就有可能使得内存频繁地进行分配和释放,进而增加系统的开销,影响程序运行的效率。对类的内存布局进行优化能够减少内存碎片的产生,提高缓存的命中率,让程序运行得更加快速。
对类的内存布局进行理解是十分重要的。编译器在处理类的时候,会按照一系列的规则来安排类里面成员的存储顺序以及内存对齐的方式。不同的编译器实现可能会存在小小的差别,而这就有可能使得同样的代码在不同的编译器之下内存布局不一样。举例来说在 GCC 和 Clang 编译器当中,对于简单的类,内存布局有可能是一样的,但是当涉及复杂的继承体系以及虚函数的时候,这两者的处理方式会有差别。了解这些差别,能够帮助我们写出更具有移植性的代码,避免因为编译器不一样而出现意外的问题。
另外,清晰地知道类的内存布局能够协助我们有效地去避开内存方面相关的错误。在 C++当中,内存错误可是很常见而且还很难去调试,像悬空指针、内存泄漏这类情况。当我们对于类的内存布局有着清晰的认识的时候,就可以更好地去理解对象的生命周期以及内存的分配和释放的过程,从而进一步减少这类错误的出现。比如说在用继承和多态的时候,如果不明白虚函数表指针在内存里的位置和起到的作用,就很容易在对象转换和析构的时候出错,使得程序出现崩溃的情况。
1.2 C++ 类内存布局原理
在 C++ 中,类的内存布局主要涉及数据成员和成员函数在内存中的分布。首先,数据成员是按照声明顺序在内存中依次排列的。比如下面这个简单的类:
class MyClass {public: int num; char ch; double value;};在名为 MyClass 的这个类之中,首先对 num 来进行内存空间的分配操作。接着是对 ch 进行相关操作。随后是对 value 进行相应操作。但是需要留意,由于内存对齐的规则,它们相互之间有可能并不是紧紧地挨在一起的。
内存对齐乃是编译器为了提高内存访问的效率,会按照一定的规则将数据成员存储到特定的内存地址之处。每一个数据类型都有着其自身所对应的对齐要求,例如 int 类型在 32 位系统当中一般要求是 4 字节对齐,double 类型一般要求是 8 字节对齐。类的对齐值则是其所有数据成员里最大的那个对齐值。
谈及 MyClass 类的时候,int 的对齐是 4 字节,char 的对齐是 1 字节,double 的对齐是 8 字节,那么整个类的对齐值就就是 8 字节了。这也就意味着 ch 后面得填充若干字节,以此来确保 value 能够从 8 字节对齐的地址之处开始进行存储 。
而成员函数并不占用类对象的内存空间。它们被存储在代码段,所有该类的对象共享这些成员函数。编译器在编译成员函数时,会给函数添加一个隐藏的 this 指针形参,通过这个指针来区分不同对象对成员函数的调用。比如下面这个带成员函数的类:
class AnotherClass {public: int data;void printData(){ std::cout << "Data: " << data << std::endl; }};printData 函数处于代码段之中。AnotherClass 类的对象在内存里仅仅只有 data 这个数据成员。当调用 obj.printData()的时候,实际上是将 obj 的地址当作 this 指针传递给 printData 函数,如此一来函数便能够去访问 obj 的 data 成员。
1.3 内存对齐的影响
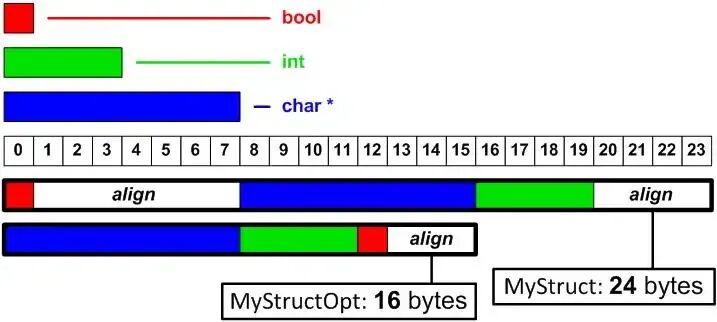
内存对齐对类的大小和内存使用效率有着显著影响。还是以上面的 MyClass 类为例,我们来计算一下它的大小。int 占 4 字节,char 占 1 字节,double 占 8 字节,如果不考虑内存对齐,它们的总大小应该是 4 + 1 + 8 = 13 字节。但由于内存对齐,实际情况并非如此。因为类的对齐值是 8 字节,num 占用 4 字节后,ch 占用 1 字节,为了让 value 从 8 字节对齐的地址开始,ch 后面需要填充 3 字节,这样 value 就能从第 8 字节开始存储,最后整个类的大小需要是 8 的倍数,所以还需要在 value 后面填充 7 字节,最终 MyClass 类的大小是 24 字节。再看一个更直观的对比示例:
class Struct1 {public: char a; double b; int c;};class Struct2 {public: double b; int c; char a;};对于 Struct1,char 占 1 字节,double 对齐 8 字节,所以 a 后面要填充 7 字节,double 占 8 字节,int 对齐 4 字节,double 后面填充 4 字节,int 占 4 字节,最后还需填充 4 字节保证整体是 8 的倍数,其大小为 24 字节。而 Struct2,double 占 8 字节,int 对齐 4 字节,int 占 4 字节,char 占 1 字节,最后填充 3 字节保证整体是 8 的倍数,其大小为 16 字节。
可以看到,仅仅调整了成员顺序,由于内存对齐的作用,两个类的大小就有明显差异,这体现了内存对齐对内存使用效率的影响。如果在一个包含大量对象的数组或容器中,这种差异会被放大,进而影响整个程序的内存占用和性能。
1.4 前期环境搭建
在开始验证 C++ 类的内存布局之前,需要先搭建好相应的 Linux 开发环境,准备好必要的工具。首先,确保你已经安装了 Linux 系统,比如常见的 Ubuntu、CentOS 等。接下来,需要安装 GCC 编译器,它是 Linux 下常用的 C/C++ 编译器。以 Ubuntu 系统为例,打开终端,输入以下命令安装 GCC:
sudo apt updatesudo apt install build-essentialsudo apt update 乃是用于对软件包列表进行更新的操作,如此便能够获取到最新的软件相关信息。sudo apt install build - essential 会去安装一系列的编译工具,在这些工具当中包含着 GCC 编译器。在安装完毕之后,可以运用 gcc --version 命令来对是否安装成功进行验证,要是成功安装好了的话,那就会显示出 GCC 的版本信息。
GDB 调试器也是必不可少的工具,它可以帮助我们在程序运行时查看变量、内存等信息。在 Ubuntu 系统中安装 GDB,只需在终端输入:
sudo apt install gdb安装完成之后,你便运用 gdb --version 这个命令去检查安装的状况。
objdump 和 readelf 工具用于解析二进制文件,它们通常包含在 GNU Binutils 工具集中。同样在 Ubuntu 系统下,安装命令如下:
sudo apt install binutils安装完毕之后,你便可以运用 objdump --version 这个命令以及 readelf --version 那个命令,来查验这两个工具是否已经安装好了。
编写测试代码——为了后续验证内存布局,我们先编写一个简单的 C++ 类。这个类包含成员变量和成员函数,代码如下:
#include <iostream>class MyClass {private: int a; double b;public: MyClass(int _a, double _b) : a(_a), b(_b) {}void print(){ std::cout << "a = " << a << ", b = " << b << std::endl; }};int main(){ MyClass obj(10, 3.14); obj.print(); return 0;}在名为 MyClass 的这个类之中,存在着两个私有成员变量,其中一个是 int 类型的 a,另外一个是 double 类型的 b。还有一个公有构造函数用于对成员变量进行初始化,并且还有一个公有成员函数 print 用于输出成员变量的值。在 main 函数当中创建一个 MyClass 对象,之后调用 print 函数。这个简单的类将会被当作后续对内存布局进行验证的例子。
二、使用 GDB 调试器验证内存布局
面试题写作模版
2.1 编译带有调试信息的代码
在使用 GDB 调试器验证 C++ 类的内存布局之前,我们需要先编译带有调试信息的代码。这一步非常关键,因为调试信息能够帮助 GDB 将内存地址与源代码中的变量、函数等对应起来,从而让我们在调试过程中更清晰地了解程序的运行状态。在编译时,我们要加上-g 选项,它会告诉编译器在生成的可执行文件中包含调试信息 。对于前面编写的 MyClass 类的代码,编译命令如下:
g++ -g -o myclass myclass.cpp在上述所提及的很多命令之中,g++乃是 C++的编译器。-g 这一个选项是用于生成调试方面的信息的。-o 这一个选项是用来指定输出的可执行文件的名字叫做 myclass。最后的 myclass.cpp 是所编写的源代码的文件名。经过这样的一番编译之后,生成的 myclass 可执行文件就具有丰富的调试方面的信息,这就为后续运用 GDB 来进行调试做好了基础。
2.2 启动 GDB 调试
编译完成后,就可以启动 GDB 并加载可执行文件了。在终端中输入以下命令启动 GDB 并加载刚才生成的 myclass 可执行文件:
gdb myclass执行上述命令后,会进入 GDB 的调试界面,显示一些 GDB 的版本信息和版权声明等内容,最后出现(gdb)提示符,这就表示 GDB 已经准备好接受调试命令了。此时,GDB 已经加载了 myclass 可执行文件,但程序还没有开始运行 。
2.3 常用 GDB 命令
在运用 GDB 进行调试的过程当中,存在着若干个常用的命令。要是能够熟练地将这些命令给掌握得很好,就可以使得我们在调试工作当中更为高效地去进行开展。
list,其简写为 l,是用于查看源代码的。在默认的情况下,它会把当前所处位置附近的 10 行代码显示出来。举个例子来说,输入 list 然后按下回车键,就会显示出一部分源代码。要是想要查看指定行号附近的代码,那就使用 list 行号这样的方式,例如 list 10 就会把第 10 行附近的代码显示出来。要是想要查看某个函数的源代码,那就使用 list 函数名这样的方式,比如 list main 就能够显示 main 函数的源代码。 break(简称为 b):其作用是用于设置断点。断点在调试过程之中是极为重要的。它可以使得程序在执行到指定的位置的时候停下来,便于我们去查看程序的状态。可以在指定的行设置断点,命令的格式是 break 行号,例如 break 15 就是在第 15 行设置一个断点。也能够在指定的函数处设置断点,使用 break 函数名的方式,比如 break MyClass::print 就是在 MyClass 类的 print 函数那里设置断点。 run(缩写为 r):对程序进行运行操作。在已经设定好了断点之后,输入 run 命令,程序便开始进行运行,一直到遭遇到第一个断点的时候才会停止下来。 print(被简称为 p):是用于把变量或者表达式的值进行打印输出的一个东西。当程序处于暂停状态的时候,可以利用这个命令来查看变量的值。举个例子来说,print a 的话,就会把变量 a 的值给打印出来。而且还能够对表达式进行计算,比如 print a + b 的话,就会算出 a 和 b 的和然后把那个结果给显示出来。
若要去查看内存地址的具体内容,它的格式是比较复杂的。常见的格式是 x/nfu 地址。在这里面 n 代表着要显示的单元的数量。f 代表着显示的格式,像 x 就代表着十六进制,d 代表着十进制,c 代表着字符等等。u 代表着每个单元的大小,比如说 b 代表着字节,h 代表着半字,w 代表着字,g 代表着双字。比如说 x/4xb 0x7fffffffe4a0,这就意味着从内存地址 0x7fffffffe4a0 开始,用十六进制的格式来显示 4 个字节的内容。
2.4 验证 C++ 类内存布局的步骤
下面我们通过具体步骤在 GDB 中验证 MyClass 类的内存布局。
(1)启动 GDB 并加载可执行文件后,首先在 main 函数中创建 MyClass 对象的那一行设置断点,假设这一行是第 12 行,输入命令:
(gdb) break 12(2)设置好断点后,输入 run 命令运行程序,程序会在第 12 行暂停:
(gdb) runStarting program: /path/to/myclass Breakpoint 1, main () at myclass.cpp:1212 MyClass obj(10, 3.14);(3)程序暂停后,我们要获取 obj 对象的地址。在 GDB 中,可以使用&运算符来获取变量的地址,输入命令:
(gdb) print &obj$1 = (MyClass *) 0x7fffffffe4a0这里的$1 是 GDB 分配的一个临时变量,用于存储表达式的结果,0x7fffffffe4a0 就是 obj 对象的内存地址。
(4)得到 obj 对象的地址后,就可以使用 x 命令查看其内存内容了。因为 MyClass 类中先定义了 int 类型的 a,再定义了 double 类型的 b,int 类型通常占 4 个字节,double 类型占 8 个字节。我们先查看 a 的值,输入命令:
(gdb) x/1xw 0x7fffffffe4a00x7fffffffe4a0: 0x0000000a这里 x/1xw 表示以十六进制格式显示 1 个字(4 个字节)的内容,从输出结果可以看到,0x0000000a 就是 a 的值,也就是 10(十六进制的 0xa 等于十进制的 10)。
(5)接着查看 b 的值,由于 b 在 a 之后,且 a 占 4 个字节,所以 b 的地址是 0x7fffffffe4a0 + 4,输入命令:
(gdb) x/1xg 0x7fffffffe4a40x7fffffffe4a4: 0x40091eb851eb851fx/1xg 是以十六进制的格式来显示 1 个双字也就是 8 个字节的内容。这里所显示的 0x40091eb851eb851f 是 b 的二进制表示。可以通过某些工具或者转换的方法来验证一下它确实是对应着 3.14 。经过这些步骤,我们就在 GDB 当中验证了 MyClass 类成员变量在内存当中的布局情况 。
三、objdump 校验 C++ 类内存布局
面试题写作模版
3.1 objdump 常用选项介绍
objdump 乃是 GNU Binutils 工具集合当中的一个重要的工具。它专门是用来去显示目标文件的各种各样的信息。在对于二进制文件进行分析以及对于验证 C++类内存布局的时候是很有作用的。它有着不少实用的选项,接下来就来介绍一些常用的。
-h 这个选项乃是用于显示文件的节头部信息的。借助它我们可以看到二进制文件当中各个节的名称、大小、加载地址以及文件偏移量等重要信息。举个例子而言,针对一个可执行文件,使用 objdump -h myprogram 这样的命令,就能够把各个节的详细信息给列出来,从而让我们知道文件的基本结构。
它的一个作用便是尽可能地混合着去显示源代码以及汇编代码,前提条件是在编译的时候使用了 -g 这个选项,也就是说文件得有调试信息。这个选项在分析程序逻辑的时候还是挺方便的。我们能够一边看着汇编代码,一边对照着源代码,从而更好地去理解程序的执行过程。比如说有一个含有调试信息的可执行文件 myprogram,执行 objdump -S myprogram,输出内容里就会交叉地显示源代码以及对应的汇编代码 。
-t 这个选项乃是用于展现符号表的。符号表会记录程序当中所定义以及所引用的函数名、全局变量名等符号的信息,还有它们的地址以及类型相关的情况。使用 objdump -t myprogram 命令,就能够查看 myprogram 文件里边的符号表。这对于找寻特定函数或者变量在内存里的位置是有帮助的,在验证类的内存布局的时候,也能够找到类相关的符号 。
3.2 利用 objdump 验证内存布局
下面通过实际操作,利用 objdump 验证之前编写的 MyClass 类的内存布局。首先,确保之前编写的 MyClass 类代码已经被编译成可执行文件,假设可执行文件名为 myclass。
(1)使用 objdump -t myclass 命令查看符号表,命令执行后的输出结果中,会包含许多符号信息,我们重点关注与 MyClass 类相关的符号。比如,可能会看到类似下面的输出:
0000000000401160 l F .text 0000000000000023 MyClass::MyClass(int, double)0000000000401183 l F .text 000000000000001a MyClass::print()从这里可以获取到 MyClass 类的构造函数和 print 函数在代码段中的起始地址,这是后续分析的重要依据。通过这些地址,我们可以在反汇编代码中找到对应的函数实现,进而分析类成员在内存中的操作 。
(2)使用 objdump -d -S myclass 命令反汇编并显示源代码和汇编代码。这个命令会输出大量内容,其中与 MyClass 类相关的部分是我们关注的重点。在输出结果中,找到 MyClass 类的构造函数部分,会看到类似下面的汇编代码和对应的源代码:
MyClass::MyClass(int, double) {401160: 55 push %rbp401161: 48 89 e5 mov %rsp,%rbp401164: 48 83 ec 10 sub $0x10,%rsp401168: 89 7d fc mov %edi,-0x4(%rbp)40116b: f2 0f 11 75 f0 movsd %xmm0,-0x10(%rbp) this->a = _a; this->b = _b;}401170: 48 83 c4 10 add $0x10,%rsp401174: 5d pop %rbp401175: c3 ret从汇编代码当中可以看得到,401168 这一行的 89 7d fc mov %edi,-0x4(%rbp),是将构造函数的第一个参数_a(通过%edi 寄存器来进行传递)存放到-0x4(%rbp)这个位置,而-0x4(%rbp)便是 MyClass 对象里成员变量 a 在栈上的存储之处。还有 40116b 那一行的 f2 0f 11 75 f0 movsd %xmm0,-0x10(%rbp),是把第二个参数_b(通过%xmm0 寄存器来进行传递)存放到-0x10(%rbp)这个位置,这也就是成员变量 b 在栈上的存储位置 。
int 类型所占据的字节数量为 4 个字节。double 类型所占据的字节数量为 8 个字节。b 处于 a 的之后位置。内存方面的布局情况和预期是一致的。如此一来就对 MyClass 类成员变量在内存当中的布局情况进行了验证。我们运用 objdump 工具,从二进制文件这个角度对 C++类的内存布局进行了验证。
四、用 readelf 验证类内存布局
面试题写作模版
4.1 readelf 常用选项介绍
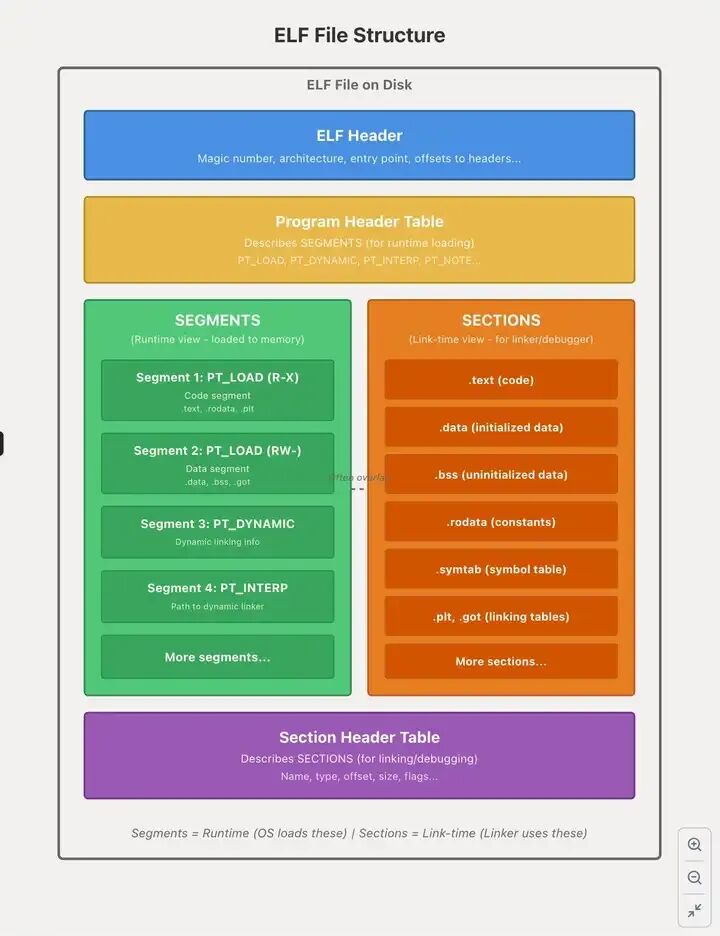
readelf 乃是一种具备极为强大功能的工具。它专门就是用于去显示 ELF 文件的结构方面的信息。在对 C++类内存布局进行验证的时候,它能够提供不少关键的相关信息。下面就是 readelf 的一些常用的选项。
-h 用于展现 ELF 文件头的信息,这是文件重要的元数据部分。它包含着文件的类型,像可执行文件、共享库相关的,还有目标机器的架构,比如说 x86 - 64、ARM 等等,还有入口点地址等关键的信息。运用 readelf -h myclass 命令,能够迅速地知道二进制文件的基本属性,这些信息是后续解析类内存布局的重要根基。
S:此选项乃是用于展现节区头表信息的。节区头表对 ELF 文件里各个节区的位置、大小以及属性等状况进行描述。在 ELF 文件当中,不同的节区有着不同的用途,比如说.text 节区用来存放代码,.data 节区用来存放已经初始化了的数据,.bss 节区用来存放未初始化的数据等等。使用 readelf -S myclass 命令,能够列出所有节区的详细信息,从这些信息之中能够找寻到和类相关的数据所处的节区,随后就可以对它的内存布局进行分析。
它的功用乃是展现符号表。符号表记载着程序当中所定义以及所引用的函数名称、变量名称等符号,还有它们的地址以及类型等方面的信息。针对 C++类来说,符号表将会包含类的构造函数、析构函数、成员函数还有成员变量等相关的符号。运用 readelf -s myclass 命令来查看符号表,能够获取到类的相关符号方面的信息。这些信息对于确定类在内存里的位置以及解析其成员的内存布局是有帮助的。
4.2 利用 readelf 验证内存布局
接下来,利用 readelf 工具验证 MyClass 类的内存布局,假设之前编写的 MyClass 类代码已被编译成名为 myclass 的可执行文件。
(1)首先使用 readelf -h myclass 命令查看 ELF 文件头信息,输出结果类似如下:
ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: Advanced Micro Devices X86-64 Version: 0x1 Entry point address: 0x40112a Start of program headers: 64 (bytes into file) Start of section headers: 2336 (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 9 Size of section headers: 64 (bytes) Number of section headers: 30 Section header string table index: 29从这里我们可以了解到文件的类型是可执行文件(Type: EXEC),机器架构是 Advanced Micro Devices X86-64,这些信息虽然没有直接显示类的内存布局,但为后续分析提供了基础环境信息。
(2)接着使用 readelf -S myclass 命令查看节区头表信息,输出中会包含很多节区的信息,部分关键节区信息如下:
Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 1] .interp PROGBITS 0000000000400238 00000238 000000000000001c 0000000000000000 A 0 0 1 [ 2] .note.ABI-tag NOTE 0000000000400254 00000254 0000000000000020 0000000000000000 A 0 0 4 [ 3] .note.gnu.build-i NOTE 0000000000400274 00000274 0000000000000024 0000000000000000 A 0 0 4 [ 4] .text PROGBITS 0000000000400298 00000298 000000000000012a 0000000000000000 AX 0 0 16 [ 5] .fini PROGBITS 00000000004003c4 000003c4 0000000000000009 0000000000000000 AX 0 0 4 [ 6] .rodata PROGBITS 00000000004003d0 000003d0 0000000000000020 0000000000000000 A 0 0 4 [ 7] .eh_frame_hdr PROGBITS 00000000004003f0 000003f0 000000000000003c 0000000000000000 A 0 0 4 [ 8] .eh_frame PROGBITS 000000000040042c 0000042c 0000000000000138 0000000000000000 A 0 0 8 [ 9] .init_array INIT_ARRAY 0000000000404e18 00004e18 0000000000000008 0000000000000008 WA 0 0 8 [10] .fini_array FINI_ARRAY 0000000000404e20 00004e20 0000000000000008 0000000000000008 WA 0 0 8 [11] .dynamic DYNAMIC 0000000000404e28 00004e28 00000000000001d0 0000000000000010 WA 6 0 8 [12] .got PROGBITS 0000000000404ff8 00004ff8 0000000000000010 0000000000000008 WA 0 0 8 [13] .got.plt PROGBITS 0000000000405008 00005008 0000000000000030 0000000000000008 WA 0 0 8 [14] .data PROGBITS 0000000000405038 00005038 0000000000000000 0000000000000000 WA 0 0 1 [15] .bss NOBITS 0000000000405038 00005038 0000000000000000 0000000000000000 WA 0 0 1在这些节区中,.text 节区存放代码,MyClass 类的构造函数和 print 函数的代码可能就存放在这里;.data 节区存放已初始化的数据,不过我们的 MyClass 类中没有静态已初始化数据成员,所以这里可能没有直接相关内容;.bss 节区存放未初始化的数据,同样,MyClass 类中也没有未初始化的静态数据成员。虽然这里没有直接给出类成员变量的内存布局,但通过了解这些节区的作用和位置,我们可以进一步分析符号表来获取更详细信息。
(3)使用 readelf -s myclass 命令查看符号表,输出中与 MyClass 类相关的符号信息可能如下:
Symbol table '.symtab' contains 36 entries: Num: Value Size Type Bind Vis Ndx Name 8: 0000000000401160 35 FUNC GLOBAL DEFAULT 13 MyClass::MyClass(int, double) 11: 0000000000401183 26 FUNC GLOBAL DEFAULT 13 MyClass::print() 15: 0000000000405038 0 NOTYPE GLOBAL DEFAULT 24 _ZTV7MyClass 16: 0000000000405040 0 NOTYPE GLOBAL DEFAULT 24 _ZTI7MyClass在此处能够看见 MyClass 类的构造函数 MyClass::MyClass(int, double)以及 print 函数 MyClass::print()的符号,还有它们在代码片段里的地址(Value 列)。对于类的内存布局的解析来讲,虽然还没有直接看见成员变量的布局,但是这些函数的地址信息可以帮助在反汇编代码中寻找到操作成员变量的指令,从而推断成员变量的内存布局。
经过对 MyClass 的构造函数代码进行反汇编操作,像是 MyClass::MyClass(int, double)这类情况,能够查看到将传入的参数赋值给成员变量 a 以及 b 的指令,进而以此来明确它们在内存当中的存储位置以及顺序。随后借助 readelf 工具从不一样的层面去获取相关信息,一步步地来对 C++类的内存布局展开验证。
end
如果这篇文章对你有所启发,欢迎点赞、在看,转发三连。星标⭐账号,还可以第一时间收到推送,感谢你的收看,我们下期再见~
往期干货推荐
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- linux 内核里的 THIS_MODULE 宏
- 一个基于 PHP 封装的 IP138 API SDK & 简化 IP & 手机号归属地
- Linux 日报 | 7.2内核进入RC、Bad Epoll漏洞紧急预警、GNOME 51砍掉旧N卡
- 背完这本“Python词典”,我竟然也能看懂AI代码了!
- Linux 网络监控与日志分析实战
- Ultramarine Linux 44,全面增强Plasma桌面!
- 【上新】狗熊会在线实习|AI辅助的Python数据分析入门
- 【第41期】21天养成编程习惯:Python刷题第05天
- 《Python 从入门到精通》104|re 模块实战:提取手机号、邮箱、日期
- 少儿编程 ‖ 从Python开始学编程-7
