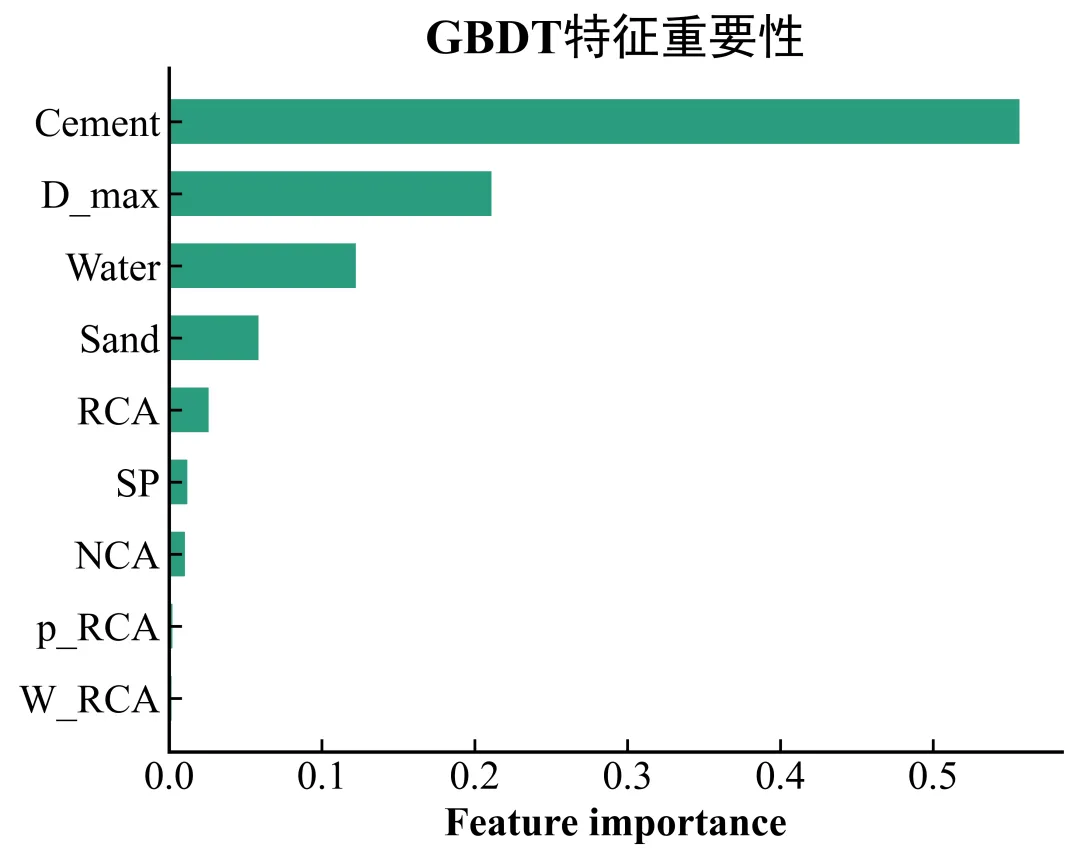
本节介绍一类常见的模型解释型论文配图:SHAP dependency plots。参考论文中使用 GBDT 模型预测再生骨料混凝土的力学性能,并进一步使用 SHAP 方法解释不同配合比变量对模型输出的贡献。本文根据原图结构和个人对该方法的理解,整理一套从模拟数据生成、模型训练、SHAP 计算到论文图复刻的完整 Python 流程,仅供学习和绘图参考。
需要说明的是,本文代码使用模拟数据进行流程演示,数据本身无任何现实实验意义。正式用于论文或项目时,应替换为自己的真实实验数据、模型结果和 SHAP 计算结果。
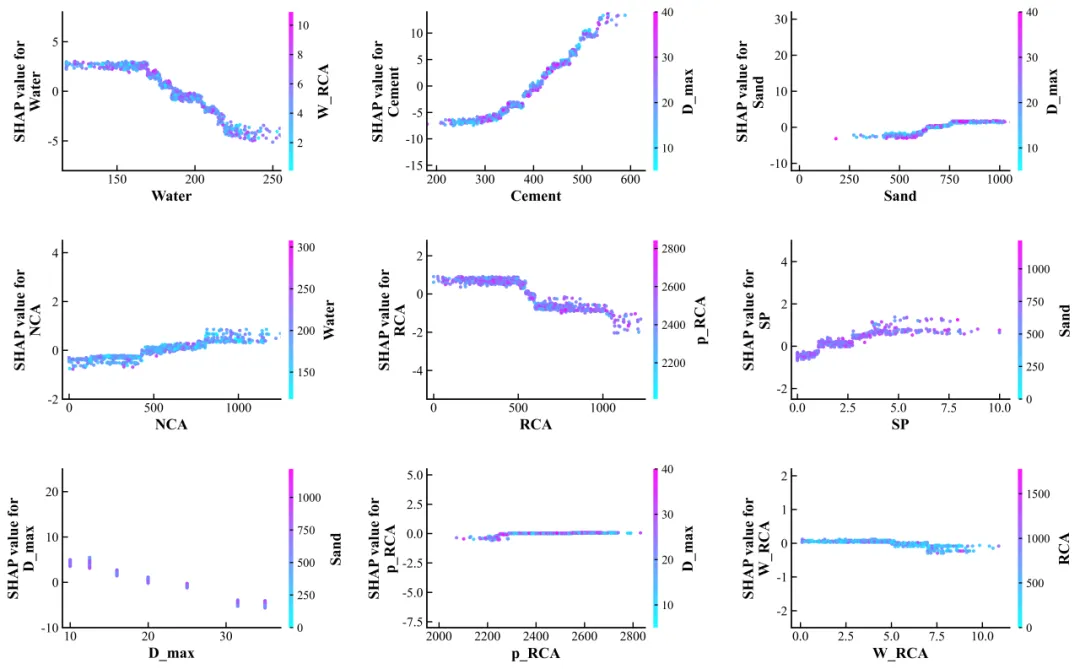
SHAP 依赖图主要用于解释某一个输入变量在不同取值下,对模型预测结果产生的正向或负向贡献。图中横轴表示变量取值,纵轴表示该变量对应的 SHAP value。当 SHAP value 大于 0 时,说明该变量在当前取值下倾向于把模型预测结果推高;当 SHAP value 小于 0 时,则表示该变量倾向于把预测结果拉低。
与普通特征重要性图相比,SHAP 依赖图不仅回答“哪个变量重要”,还进一步展示“变量取值变化时,模型响应如何变化”。因此它更适合放在论文的模型解释、变量机制分析或结果讨论部分。
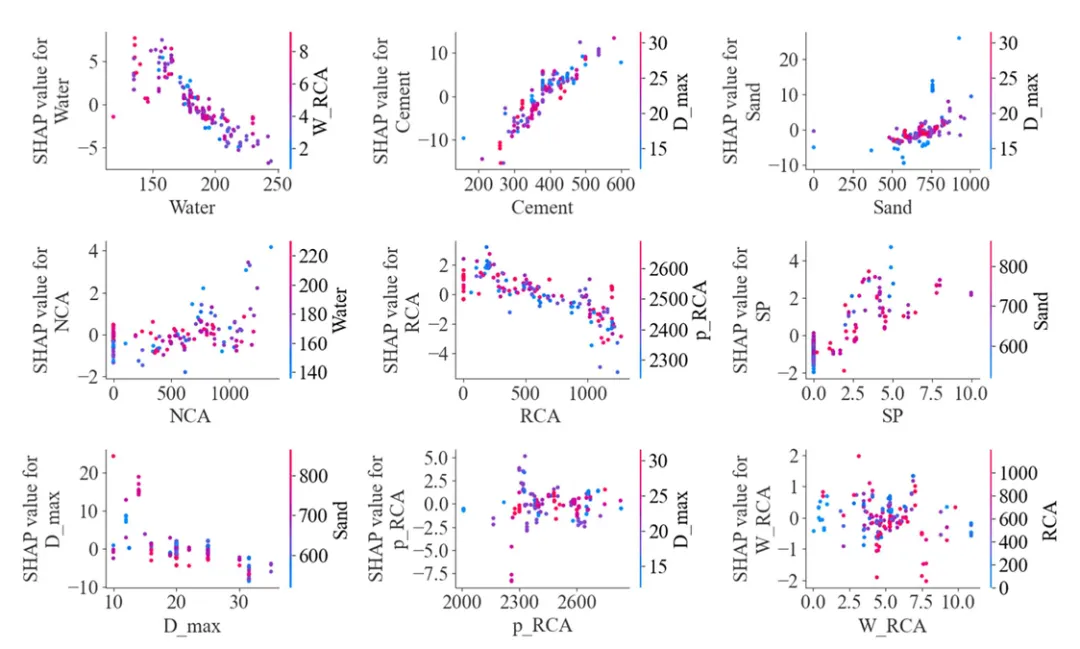
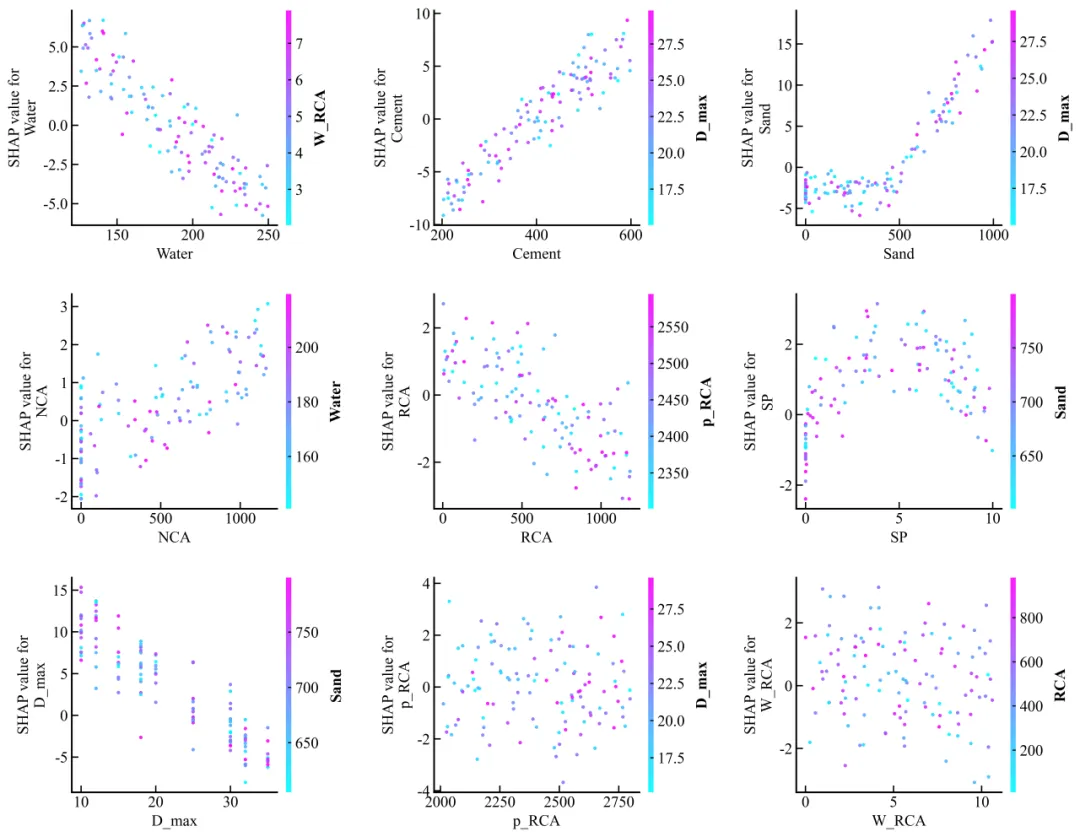
本案例复刻的是 3×3 多面板 SHAP 依赖图。每个子图对应一个输入特征,例如 Water、Cement、Sand、NCA、RCA、SP、D_max、p_RCA 和 W_RCA。散点表示样本,颜色条表示交互变量的取值,用于观察变量之间可能存在的交互关系。
首先固定绘图风格,包括字体、坐标轴、刻度、保存分辨率和散点大小等参数。论文图通常需要较克制的样式,坐标轴清晰、颜色条简洁、散点不过度装饰。
import osimport warningsfrom datetime import datetimeimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snswarnings.filterwarnings("ignore")plt.rcParams["font.family"] = ["Times New Roman", "SimHei", "DejaVu Sans"]plt.rcParams["mathtext.fontset"] = "stix"plt.rcParams["font.size"] = 14plt.rcParams["axes.linewidth"] = 1.35plt.rcParams["xtick.direction"] = "in"plt.rcParams["ytick.direction"] = "in"plt.rcParams["axes.unicode_minus"] = Falseplt.rcParams["savefig.bbox"] = "tight"plt.rcParams["savefig.dpi"] = 600CUSTOM_SCATTER_SIZE = 10CUSTOM_CMAP = "cool"RANDOM_SEED = 20260704
这一部分主要用于统一图形审美。Times New Roman 更接近期刊图的英文排版风格,cool 色图可以形成蓝色到洋红色的连续变化,和目标图中的颜色表达比较接近。
随后定义变量信息和子图结构。这里把每个变量的范围、均值、标准差和单位单独整理出来,后续模拟数据生成、坐标范围设定和颜色条归一化都会用到这些信息。
TARGET_COLUMN = "UCS"FEATURES = [ "Water", "Cement", "Sand", "NCA", "RCA", "SP", "D_max", "p_RCA", "W_RCA"]FEATURE_SPECS = { "Water": {"min": 117.6, "max": 308.0, "mean": 185.2, "std": 30.1}, "Cement": {"min": 158.0, "max": 651.0, "mean": 390.8, "std": 77.1}, "Sand": {"min": 0.0, "max": 1219.0, "mean": 698.2, "std": 147.0}, "NCA": {"min": 0.0, "max": 1753.0, "mean": 494.6, "std": 400.8}, "RCA": {"min": 0.0, "max": 1778.0, "mean": 600.0, "std": 393.9}, "SP": {"min": 0.0, "max": 10.0, "mean": 1.9, "std": 2.3}, "D_max": {"min": 5.0, "max": 40.0, "mean": 21.9, "std": 5.8}, "p_RCA": {"min": 2010.0,"max": 2842.0, "mean": 2470.4, "std": 158.9}, "W_RCA": {"min": 0.1, "max": 10.9, "mean": 4.8, "std": 2.0},}
在自己的数据中使用时,只需要把这些变量范围替换为真实数据范围,并保持变量名和后续建模代码一致即可。
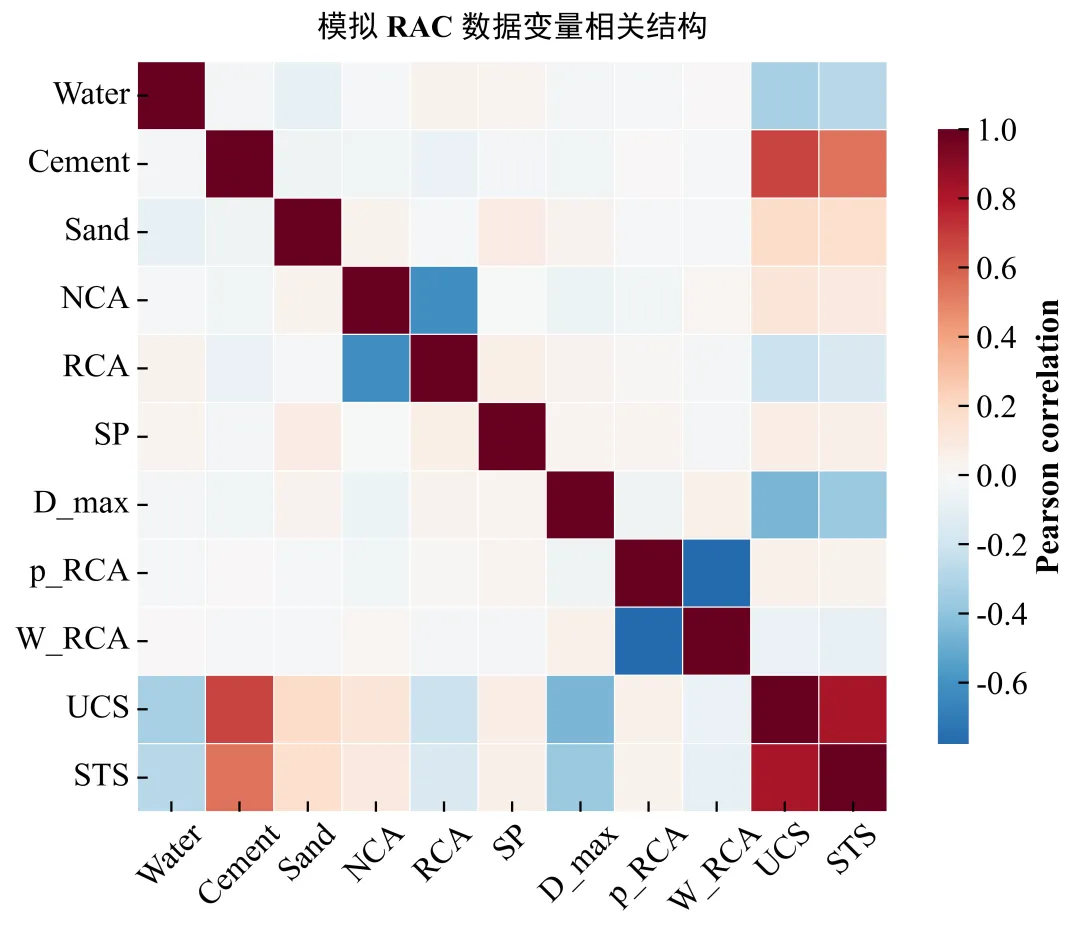
下面代码使用模拟数据演示流程。模拟逻辑并不是简单随机拼接,而是尽量保留混凝土配合比变量之间的一些合理关系,例如 RCA 和 NCA 同属于粗骨料体系,p_RCA 与 W_RCA 存在负相关倾向,UCS 与 Cement、Water、D_max 等变量具有非线性响应。
rng = np.random.default_rng(RANDOM_SEED)n_samples = 749def clipped_normal(name, size=n_samples): spec = FEATURE_SPECS[name] values = rng.normal(spec["mean"], spec["std"], size) return np.clip(values, spec["min"], spec["max"])water = clipped_normal("Water")cement = clipped_normal("Cement")sand = clipped_normal("Sand")total_coarse = np.clip(rng.normal(1120, 260, n_samples), 250, 1770)rca_ratio = rng.beta(2.1, 2.0, n_samples)rca = np.clip(total_coarse * rca_ratio + rng.normal(0, 70, n_samples), 0, 1778)nca = np.clip(total_coarse - rca + rng.normal(0, 80, n_samples), 0, 1753)sp_nonzero = np.clip(rng.gamma(shape=1.7, scale=1.6, size=n_samples), 0, 10)sp = np.where(rng.random(n_samples) < 0.36, 0, sp_nonzero)d_choices = np.array([10, 12.5, 16, 20, 25, 31.5, 35, 40])d_probs = np.array([0.10, 0.13, 0.13, 0.25, 0.18, 0.10, 0.07, 0.04])d_max = rng.choice(d_choices, size=n_samples, p=d_probs)w_rca = clipped_normal("W_RCA")p_rca = np.clip(2690 - 48 * w_rca + rng.normal(0, 80, n_samples), 2010, 2842)
这里的重点是构造“像真实实验表”的数据结构。比如 `D_max` 采用离散粒径取值,而不是连续随机数;`SP` 设置了一部分 0 值样本,用于模拟外加剂可能未掺入的情况。
继续构造目标变量 UCS,并保存为 Excel 文件:
water_effect = np.where(water <= 155, 6.2 - 0.018 * (155 - water), 6.2 - 0.115 * (water - 155))cement_effect = 0.070 * (cement - 360) + 0.00012 * (cement - 390) ** 2sand_effect = -3.5 + 6.8 / (1 + np.exp(-(sand - 640) / 90))nca_effect = -0.6 + 0.0022 * ncarca_effect = 1.5 - 0.0032 * rca + 0.0000011 * (rca - 700) ** 2sp_effect = -1.2 + 3.8 * (1 - np.exp(-sp / 2.6))dmax_effect = 9.5 - 0.48 * d_max + rng.normal(0, 0.35, n_samples)rho_effect = 0.002 * (p_rca - 2470)wrca_effect = -0.18 * (w_rca - 4.8)ucs = ( 43 + water_effect + cement_effect + sand_effect + nca_effect + rca_effect + sp_effect + dmax_effect + rho_effect + wrca_effect + rng.normal(0, 3.6, n_samples))ucs = np.clip(ucs, 13.4, 108.5)raw_data = pd.DataFrame({ "Water": water, "Cement": cement, "Sand": sand, "NCA": nca, "RCA": rca, "SP": sp, "D_max": d_max, "p_RCA": p_rca, "W_RCA": w_rca, "UCS": ucs,})today_str = datetime.today().strftime("%Y%m%d")excel_path = os.path.join(os.getcwd(), f"模拟数据-{today_str}.xlsx")raw_data.to_excel(excel_path, index=False)
该 Excel 文件用于保留模拟数据,便于后续检查、复跑或替换为真实数据。
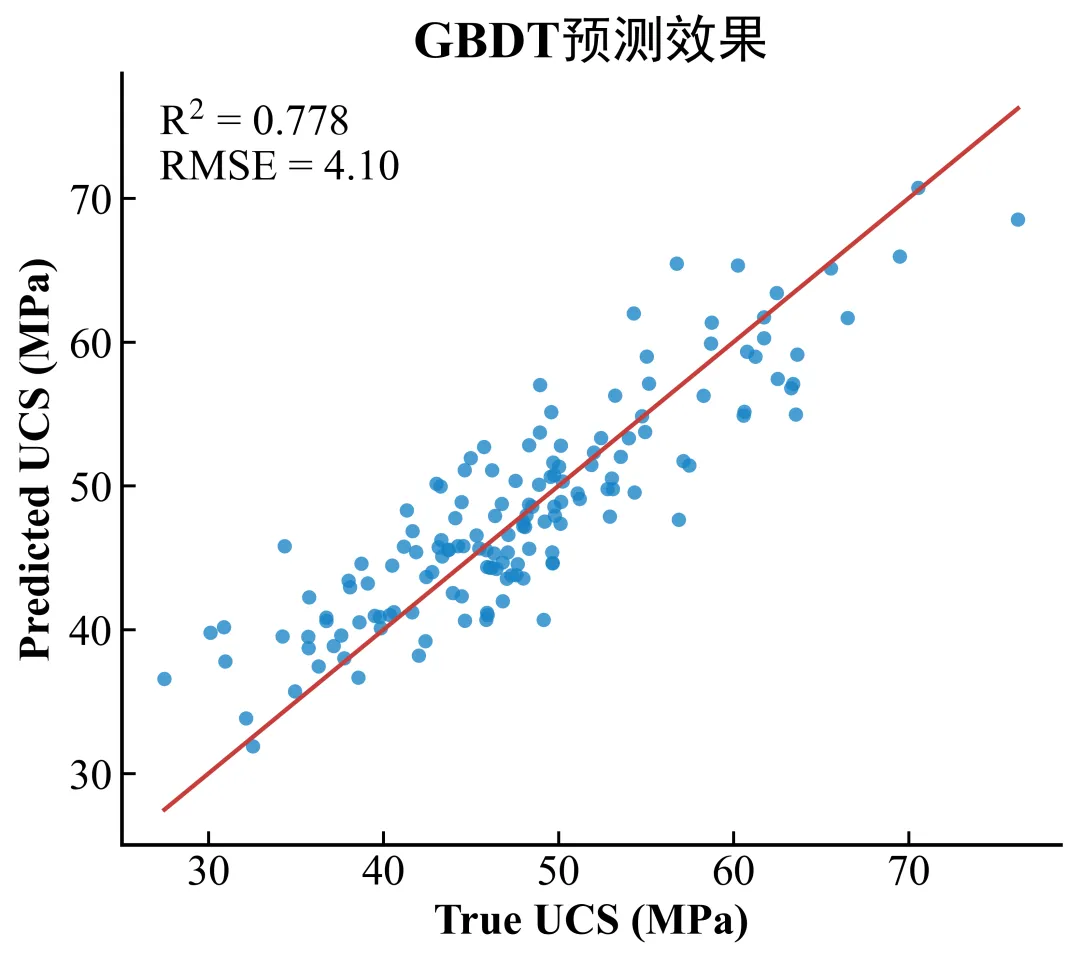
接下来将 UCS 作为目标变量,其余变量作为输入特征,使用 GBDT 回归模型进行训练。为了让流程更完整,代码中加入了训练集和测试集划分,以及简单的网格搜索。
from sklearn.ensemble import GradientBoostingRegressorfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.metrics import r2_score, mean_squared_error, mean_absolute_errorX = raw_data[FEATURES].copy()y = raw_data[TARGET_COLUMN].copy()X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.20, random_state=RANDOM_SEED)param_grid = { "n_estimators": [70, 95], "max_depth": [2, 3], "learning_rate": [0.05, 0.08], "min_samples_leaf": [2, 4],}base_model = GradientBoostingRegressor(random_state=RANDOM_SEED)search = GridSearchCV( base_model, param_grid=param_grid, scoring="r2", cv=5, n_jobs=-1,)search.fit(X_train, y_train)best_model = search.best_estimator_
在旧版本 sklearn 中,mean_squared_error 可能不支持 squared=False 参数,因此 RMSE 建议写成下面这种兼容形式:
train_pred = best_model.predict(X_train)test_pred = best_model.predict(X_test)metrics = { "Train_R2": r2_score(y_train, train_pred), "Test_R2": r2_score(y_test, test_pred), "Test_RMSE": np.sqrt(mean_squared_error(y_test, test_pred)), "Test_MAE": mean_absolute_error(y_test, test_pred),}print("最优参数:", search.best_params_)print(pd.Series(metrics).round(4))
这一步输出的 R2、RMSE 和 MAE 用于判断模型是否能够支撑后续解释。正式研究中,如果模型本身预测效果较弱,SHAP 图也要谨慎解读。
try: import shap explainer = shap.TreeExplainer(best_model) shap_values = explainer.shap_values(X) shap_values = getattr(shap_values, "values", shap_values)except Exception: pred_full = best_model.predict(X) shap_columns = [] for feature in FEATURES: X_ref = X.copy() X_ref[feature] = X[feature].median() contribution = pred_full - best_model.predict(X_ref) shap_columns.append(contribution - np.mean(contribution)) shap_values = np.vstack(shap_columns).Tshap_df = pd.DataFrame(shap_values, columns=FEATURES)
如果本地安装了 shap,优先使用 TreeExplainer。如果没有安装,则使用单变量置换贡献作为演示回退。回退结果不能等同于严格 SHAP,只适合用于绘图流程演示。
最后绘制 3×3 多面板 SHAP 依赖图。每个子图的横轴为特征值,纵轴为该特征的 SHAP value,颜色条为交互变量
from matplotlib.colors import Normalizeplot_data = raw_data[FEATURES + ["UCS"]].copy()for feature in FEATURES: plot_data[f"SHAP_{feature}"] = shap_df[feature].valuesPANEL_CONFIG = [ {"x": "Water", "color": "W_RCA", "ylabel": "SHAP value for\nWater"}, {"x": "Cement", "color": "D_max", "ylabel": "SHAP value for\nCement"}, {"x": "Sand", "color": "D_max", "ylabel": "SHAP value for\nSand"}, {"x": "NCA", "color": "Water", "ylabel": "SHAP value for\nNCA"}, {"x": "RCA", "color": "p_RCA", "ylabel": "SHAP value for\nRCA"}, {"x": "SP", "color": "Sand", "ylabel": "SHAP value for\nSP"}, {"x": "D_max", "color": "Sand", "ylabel": "SHAP value for\nD_max"}, {"x": "p_RCA", "color": "D_max", "ylabel": "SHAP value for\np_RCA"}, {"x": "W_RCA", "color": "RCA", "ylabel": "SHAP value for\nW_RCA"},]fig, axes = plt.subplots(3, 3, figsize=(14, 8.8))axes = axes.flatten()for ax, cfg in zip(axes, PANEL_CONFIG): x_name = cfg["x"] c_name = cfg["color"] y_name = f"SHAP_{x_name}" spec = FEATURE_SPECS[c_name] norm = Normalize(vmin=spec["min"], vmax=spec["max"]) sc = ax.scatter( plot_data[x_name], plot_data[y_name], c=plot_data[c_name], cmap=CUSTOM_CMAP, norm=norm, s=CUSTOM_SCATTER_SIZE, alpha=0.92, edgecolors="none", ) ax.set_xlabel(x_name) ax.set_ylabel(cfg["ylabel"]) ax.grid(False) ax.spines["top"].set_visible(False) ax.spines["right"].set_visible(False) cbar = fig.colorbar(sc, ax=ax, fraction=0.035, pad=0.035, aspect=36) cbar.set_label(c_name, rotation=90, labelpad=8) cbar.outline.set_visible(False)plt.tight_layout(w_pad=2.1, h_pad=1.8)save_dir = os.path.join(os.getcwd(), "figure")os.makedirs(save_dir, exist_ok=True)save_path = os.path.join(save_dir, "4-论文主图复刻-UCS模型SHAP依赖图.png")# plt.savefig(save_path, dpi=600, format="png")plt.show()
绘图时需要注意两个细节。第一,颜色条最好跟随每个子图单独生成,因为不同子图的颜色变量不完全一致。第二,SHAP 依赖图的散点不宜过大,否则 3×3 面板会显得拥挤。
本案例使用模拟数据,不能代表真实 RAC 实验结果。
如果替换为真实数据,应先检查缺失值、异常值、变量单位和数据分布。
GBDT 模型效果不足时,不建议直接展开 SHAP 解释。
SHAP value 的正负表示对模型预测值的推高或拉低,不表示变量本身一定存在因果作用。
多面板图要控制散点大小、颜色条宽度和子图间距,否则信息密度会过高。
👇关注公众号【嗡嗡的Python日常】
✅ 支持代码定制|承接各类定制化科研绘图|质量放心
📌 关于源码:本文核心代码为原创定制,默认不免费公开。
✅ 获取源码方式:
1、直接添加号主微信,付费购买完整源码 + 数据
2、全部完整合集158元,后续将会持续更新,决定购买请联系作者,仅分享代码文件及模拟数据,不提供答疑服务,购买后不退不换!!!
👉请直接添加号主微信联系☕️:Wjtaiztt0406













 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
