- 一个西班牙年轻人在X上发了条帖子,7月3日上午11点19分,6.1万次浏览,1.1K点赞,188转发。
他说的事情听起来像个笑话:全世界最庞大、最复杂的开源项目之一,Linux内核,2800万行代码,7.5万个文件,一个AI工具3分钟就能把它"看完"。
它扫一遍,就能建出一张481万节点、772万条边的完整知识图谱。之后AI再问"这个函数被谁调用",不用再翻文件,查一下图就知道。
这条帖子的评论区,有人甩出了GitHub链接:github.com/DeusData/codebase-memory-mcp。短短几天,这个项目的星标从两万多路涨到了25.5K。
一条推特,把AI编程最烦人的毛病摆上台面
@_guillecasaus,本名Guillermo Casaus,在推文里写道:
"El kernel de Linux tiene 28 millones de líneas de código. Han creado un MCP capaz de indexarlo por completo en solo 3 minutos."
「Linux内核有2800万行代码。有人做了一个MCP,只用3分钟就能把它完整索引。」
他接着列出三个数字:上下文消耗最多降低99%,代码查询响应时间不到1毫秒,兼容Claude Code、Cursor、Gemini CLI等一大票AI编程工具。


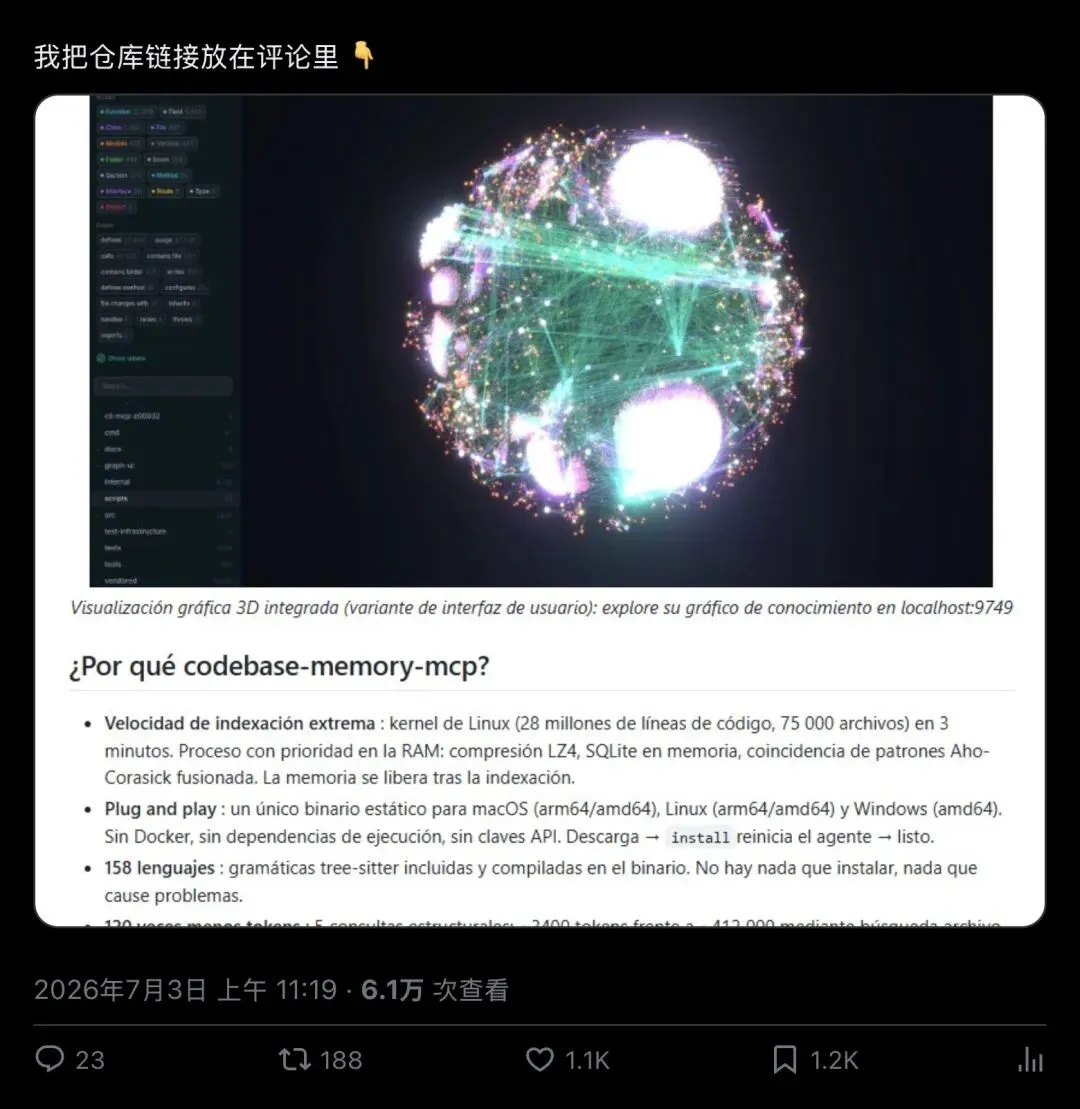
▲ @_guillecasaus的原帖,配图是项目自带的3D知识图谱可视化界面,发布于2026年7月3日,6.1万次浏览。
这条帖子能在中文、西语圈同时刷屏,底层原因很简单:几乎每个用过AI编程工具的人,都被同一个问题折磨过。
AI写代码,烧钱的环节是"找"
用过Claude Code或Cursor的人都懂这种憋屈:你问一句"这个函数谁在调用",它不会马上给答案,得先启动一轮"考古"。
grep一下,读几个文件,再grep,再读文件,翻来覆去十几个来回,答案才姗姗来迟。整个过程里,大段源码被塞进提示词,一次问答就能烧掉几万token。
有位常年用Claude Code配合Django项目开发的博主在dev.to上写道:
"It would consume thousands of tokens, take longer than necessary, and sometimes still miss a function call hidden deep inside the project."
「它会消耗数千token,花的时间比应该花的更长,有时候还是会漏掉藏得比较深的一处函数调用。」
他给这个现象起的标题,像在吐槽一样不留情面:"Stop Making Your AI Coding Agent Grep Your Whole Repo",别再让你的AI编程助手满仓库瞎翻了。
▲ dev.to作者ArshTechPro的实测文章,标题直指AI编程工具"逐文件遍历"的老毛病。
问题的根子在于,大模型的上下文窗口再大也是有限的。项目越庞大,代理要"重新认识"这个项目所花的成本就越高。像Linux内核这种量级的单体仓库,传统做法几乎是灾难,代理把大半预算都花在弄清楚"这是个什么项目"上,真正解决问题的余量所剩无几。
图谱代替翻文件:3分钟背后的工程细节
Codebase Memory MCP给出的方案,说穿了就四个字:建一次,记一辈子。
它的开发团队DeusData,由Martin Vogel等人牵头,选择了一条和"塞更大上下文窗口"完全不同的路,把代码结构预先解析成图,让代理去查图,不用每次都重新阅读源码。
具体怎么做到的?拆开看有三层。
第一层,解析。 它内置了tree-sitter语法,支持158种编程语言的语法解析,全部打包进一个二进制文件里,用户不用额外装任何东西。
第二层,补语义。 对Python、TypeScript、Go、Rust、Java等9种以上主流语言,它还加了一层轻量级的类型解析(团队管这个叫"Hybrid LSP"),把继承关系、泛型、跨文件的import绑定这些tree-sitter抓不住的语义信息补全。
第三层,建图存图。 函数、类、路由、基础设施资源都变成图里的节点,调用关系、导入关系、HTTP请求链路变成边。整个过程优先放在内存里跑,用LZ4压缩加内存SQLite,索引完再落盘。
最后暴露给AI代理的,是14个标准化的MCP工具,搜索图、追踪调用链、拿架构总览、看git变更影响到哪些代码、跑一段Cypher查询、甚至内置向量语义搜索,都不需要额外配API key。
▲ 项目GitHub主页,标注"average repo in milliseconds"(普通仓库毫秒级索引),写稿这一刻星标已经涨到25.5K,一周内合并了数十个PR。
这套逻辑装进AI编程工具里之后,原本要"读文件"的问题,变成了"查数据库"的问题。查询代替遍历,确定性代替猜测。
数字最有说服力:5次查询,3400 token对412000 token
光讲原理不够震撼,团队干脆把数字摆出来给人算账。
一个典型场景:对同一个代码库跑5次结构化查询。传统的文件遍历方式,累计要吃掉41.2万token。换成图查询,只需要3400token。
省下的比例,接近99%。
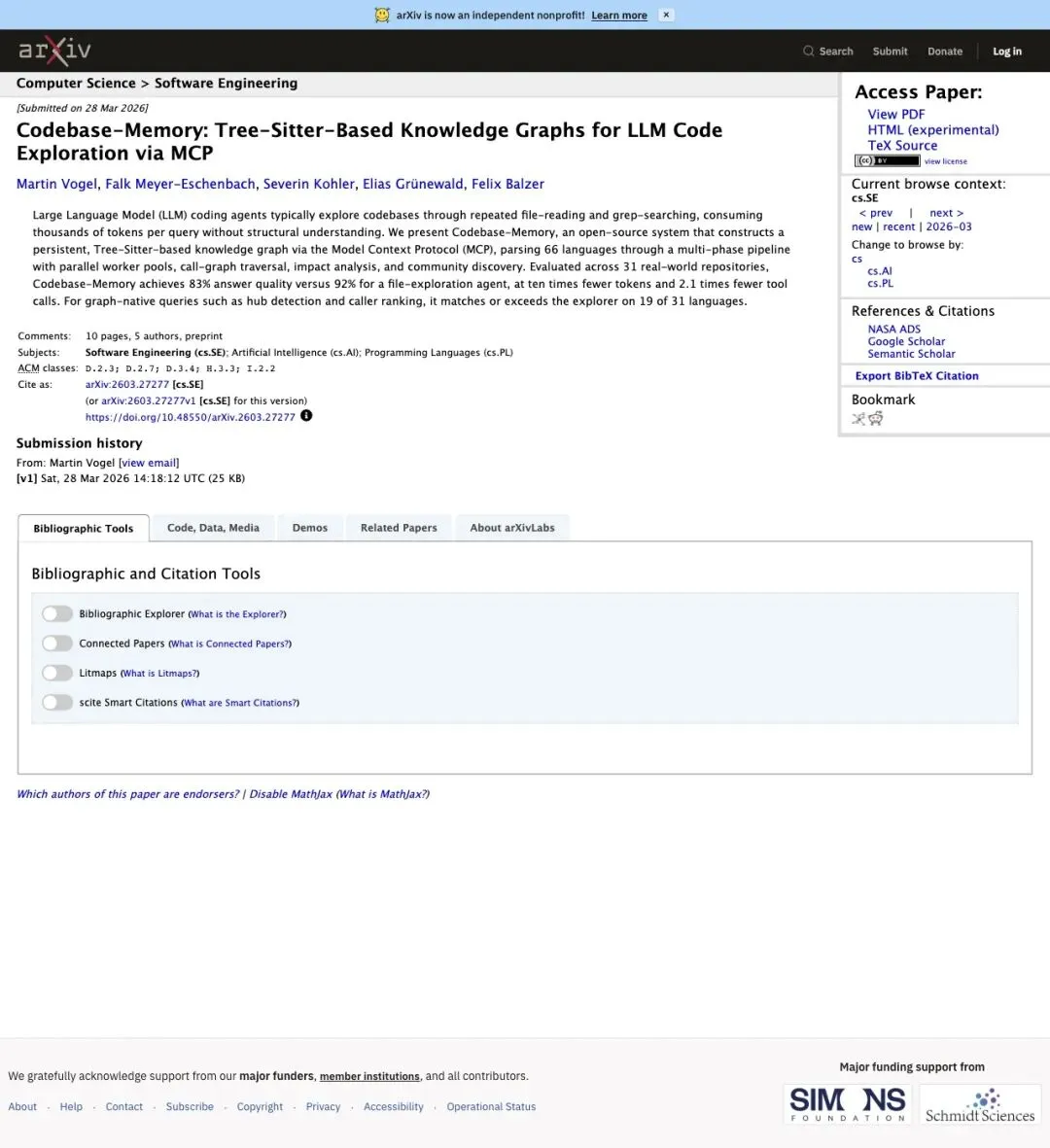
这几个数字站得住脚,背后有一份正式论文撑腰。2026年3月28日,Martin Vogel联合Falk Meyer-Eschenbach、Severin Kohler、Elias Grünewald、Felix Balzer五人,把方法和实验数据整理成论文提交到了arXiv,编号2603.27277。
▲ arXiv论文摘要页。论文测试时的语言解析覆盖是66种,如今生产版本已经扩展到158种,三个多月里语言支持翻了一倍还多。
论文里跑了31个真实世界的代码仓库做评测,给出的结果很坦诚:图谱代理的token消耗只有文件探索代理的十分之一,工具调用次数少2.1倍。但在综合答案质量上,图谱代理拿到83分,文件探索代理拿到92分,输给了9分。
不过在"纯图结构"类的问题上,比如找系统里的核心枢纽模块、给调用者排序,图谱代理在31个仓库里的19个上打平甚至反超。
论文团队给出的结论很务实:图查询优先,查不到或者查得不够细时,再回退去读文件,图谱负责先把能省的token省下来,文件探索留着兜底。
批评的声音没有缺席
社区里叫好的同时,反对和质疑一直都在。
有人在Reddit上提出一个挺尖锐的问题:构建图谱本身也要花时间和计算资源,如果代理之后只依赖图谱给出的"总结",会不会反而漏掉细节,甚至产生幻觉?
也有开发者指出,动态语言的运行时特性,反射、依赖注入、框架的"魔法"绑定、动态分发,这些在真正运行前都不确定指向谁,静态解析很难完全捕捉。对不断快速迭代的超大代码库,增量更新是否可靠,低配置机器上初始索引的压力有多大,都还是待验证的问题。
还有人提醒,做同类事情的项目不止这一个,CodeGraph、graphify、RemembrallMCP、GitNexus各有侧重,有的偏重运行时trace,有的偏重向量检索,选哪个取决于具体仓库的特点。
项目团队的解释很干脆:自己扮演的角色一直是结构分析后端,把图和代码片段准备好,推理这件事仍旧交给上层的AI代理来做。遇到grep不到的情况,还提供非阻塞的hooks,把图查询结果顺带塞进去做补充。
一个二进制文件,却要过70多道安全关
当一个工具要读写你本地的代码和配置文件时,信任从哪里来是绕不开的问题。
Codebase Memory MCP给出的答案是把安全流程做到近乎苛刻。每次发布,二进制文件要过70多个杀毒引擎扫描,VirusTotal检测结果是0命中。构建过程遵循SLSA Level 3溯源标准,用Sigstore做签名,每个资产都带SHA-256校验值。
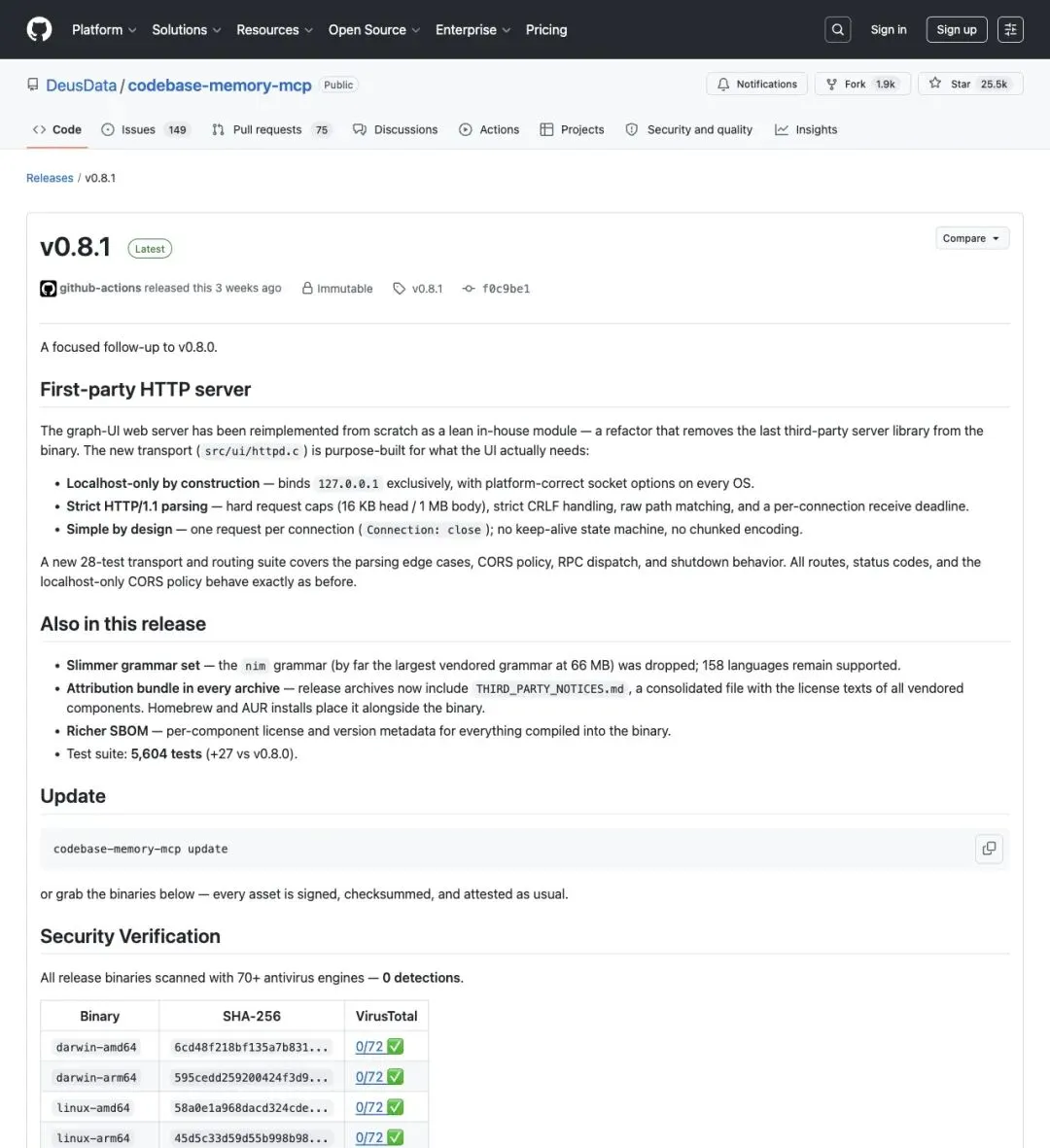
最新的v0.8.1版本里,团队甚至把图形界面用的HTTP服务器整个重写了一遍,换成自己实现的轻量模块,目的只有一个,彻底去掉第三方服务器库的依赖。新服务器只绑定127.0.0.1,只接受本地访问,连请求头大小、请求体大小都设了上限。这一版光是新增的传输层测试用例就有28个,整个项目的测试总数达到5604个。
▲ v0.8.1发布页面:自研本地HTTP服务器、精简语言语法包、5604个测试用例、安全验证表格一目了然。
代码不出本机,不遥测,连本地起的可视化界面都主动收紧到只有自己能访问,对于一个要处理全公司源码的工具而言,这几乎是能做到的极限。
中文圈的复盘:11种代理、14个工具全讲透了
这波讨论传到中文圈时,有人做了更系统的梳理。
推特博主@AriXZone在自己的帖子里,把整个项目的核心信息浓缩成几行字:基于tree-sitter支持158种语言解析,主流语言额外用Hybrid LSP做语义补全,构建函数、类、调用链、HTTP路由及跨服务关系的完整图谱;提供14个MCP工具,覆盖搜索、调用链追踪、架构总览、影响分析、Cypher查询、死代码检测、语义搜索;单一静态二进制,零运行时依赖,不需要API key,不内置LLM,只做图谱构建与查询,推理仍由调用它的智能体完成。
▲ @AriXZone的中文技术复盘帖,发布于2026年7月3日晚10点05分。
这条帖子没有前两条那么高的转发量,但它把项目最关键的部分,支持11种主流AI编程代理、单一二进制零依赖、数据全程本地不上传,讲得足够清楚,成了不少中文开发者第一次完整了解这个项目的入口。
从ctags到知识图谱:一场十年跨度的接力
把时间线拉长看,这背后是一场跨度十年的技术接力。
代码智能工具的进化,走了很长一段路。早年靠ctags、cscope做符号跳转;2016年前后,Language Server Protocol(LSP)统一了IDE里补全、跳转、诊断这些能力;2018年之后,tree-sitter带来了快速、增量、跨语言的解析方式,被GitHub CodeQL、Sourcegraph这些大项目采纳。
2023年到2025年,AI编程代理开始大规模普及,大家才发现"每次会话都要重新认识代码"这件事,成本高到离谱。向量检索(RAG)一度被寄予厚望,但它有个天生的短板,丢失了代码本身的结构信息,调用链、类型关系、控制流,这些东西向量相似度算不出来。
2024年11月,Anthropic开源了Model Context Protocol,把它比作"AI界的USB-C接口",一次开发,多端复用,任何遵循这个协议的AI应用都能接入外部数据源和工具。
▲ MCP官方文档:"Think of MCP like a USB-C port for AI applications"(把MCP想象成AI应用的USB-C接口)。
Codebase Memory MCP正是长在这套协议之上的一个垂直服务,它不需要重新发明客户端,Claude Code、Cursor、Zed这些工具原生就能接进来。MCP负责连接,图谱负责记忆,两者拼在一起,才有了"3分钟建完Linux内核知识图谱"这种听起来夸张、实际有据可查的场景。
记忆一旦持久化,游戏规则就变了
这件事真正值得留意的地方,是"记忆"这个动作本身发生了变化。
过去,AI代理对一个项目的理解,是一次性的、用完即焚的。这次会话读了十个文件搞懂了架构,下次会话打开,一切归零,重新再来一遍。
现在,理解可以被固化成一张图,存下来,团队里的下一个人接手项目、换一台机器,导入压缩快照就能立刻拥有和上一个人同等质量的上下文。架构决策记录、死代码检测、变更影响分析,这些原本靠人工写文档、开会讨论的事情,变成了代理能随时查询的既成事实。
这也带来一个新问题:当图谱本身成了整个系统里唯一的"事实来源",它的构建质量,几乎决定了代理能力的天花板。图谱要怎么审计,要怎么随代码版本一起演进,谁来保证它没有过时,这些追问,恰恰是接下来这类工具要一起回答的功课。
上下文窗口还在变大,价格和延迟却没有同比例下降。用结构化压缩去换效率,是一条和"堆更大窗口"完全不同、却同样值得走下去的路。
一个西班牙年轻人的一条推文,一段跑在苹果M3 Pro上的3分钟索引记录,让更多人看见了这条路径的存在。至于它能走多远,接下来31个仓库之外的更多真实项目,会给出答案。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
