Linux 服务管理到实战:告别 nohup,拥抱 systemd
引言
你有没有遇到过这样的情况:写了一个脚本或者部署了一个应用,用 nohup 丢到后台就跑,结果服务器一重启,进程没了,日志也不知道散落在哪里。又或者,装了个 Nginx,潇洒敲下 systemctl start nginx,结果返回一句 Job for nginx.service failed,瞬间懵了。
如果你有过类似的经历,这篇文章就是为你准备的。今天我们就来彻底搞懂 Linux 服务管理,从历史演进到日常操作,再到亲手创建一个生产级的系统服务。
一、从 SysVinit 到 systemd:为什么要有这场变革?
在 systemd 成为主流之前,Linux 系统普遍使用 SysVinit 作为初始化系统。那时候管理服务主要靠 /etc/init.d/ 目录下的脚本,配合 service 命令使用。
这套方案虽然简单直接,但随着系统复杂度越来越高,问题也逐渐暴露出来:
- 串行启动,速度慢
- 依赖关系靠猜:服务之间的启动顺序依赖脚本里的
sleep 硬编码,维护起来非常痛苦。 - 状态查询不统一:每个脚本实现
status 的方式各不相同,没有一个标准接口。
为了解决这些问题,systemd 于 2010 年被推出。如今,主流 Linux 发行版(CentOS 7+、Ubuntu 16.04+、Debian 8+ 等)都已全面采用 systemd 作为默认初始化系统。
systemd 的核心改进可以概括为三点:
- 并行启动:服务可以同时启动,启动时间通常能缩短 70% 到 80%。
- 依赖关系管理
- 统一日志:提供
journald 集中式日志服务,告别日志散落各处。
你可以把 systemd 理解为 Linux 的 “服务管家” ——它负责启动服务、管理生命周期、记录日志、处理依赖关系。
二、systemctl:服务管理的瑞士军刀
systemctl 是 systemd 的核心命令行工具,也是我们日常打交道最多的命令。下面是最常用的几类操作:
2.1 基本服务操作
| |
|---|
systemctl start <服务> | |
systemctl stop <服务> | |
systemctl restart <服务> | |
systemctl reload <服务> | |
systemctl status <服务> | |
systemctl enable <服务> | |
systemctl disable <服务> | |
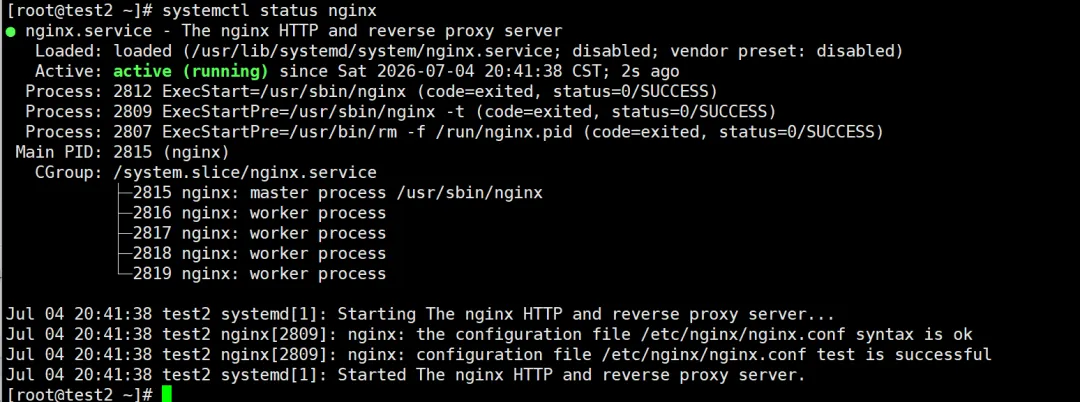
其中 status 是我个人用得最多的命令——它能显示服务是否运行、进程 ID、以及最近的错误日志,很多时候服务启动失败,看一眼 status 基本就能定位问题。
# 启动 Nginxsystemctl start nginx# 查看状态(含进程ID、日志片段)systemctl status nginx# 重启服务systemctl restart nginx# 重新加载配置(不中断服务)systemctl reload nginx
💡 小技巧:reload 不是所有服务都支持。如果不确定,可以用 reload-or-restart——支持就 reload,不支持就 restart。
2.2 开机自启管理
生产环境的服务基本都需要开机自启:
# 启用开机自启systemctl enable nginx# 禁用开机自启systemctl disable nginx# 启用并立即启动(二合一)systemctl enable --now nginx
enable 的本质是在系统启动链中创建符号链接。对应的,disable --now 会禁用并立即停止服务。
2.3 查看服务状态
除了 status,还有两个轻量级的检查命令:
# 仅检查是否在运行(返回 active/inactive)systemctl is-active nginx# 仅检查是否启用开机自启(返回 enabled/disabled)systemctl is-enabled nginx
三、服务启动失败?记住这套排错模型
服务启动失败是每个运维人员都会遇到的场景。不要反复 start,要学会“看信息”。记住这个四步排错模型:
① 看状态(入口)
看服务是 failed 还是 inactive,以及输出的错误提示。
② 看日志(核心)
重点关注这几类错误:
permission deniedport in useconfig error
③ 看资源(容易忽略)
很多服务其实是被系统资源“压死”的:
④ 看依赖(高手进阶)
有些服务启动失败,是因为依赖的服务没起来:
systemctl list-dependencies nginx
四、实战:手把手创建一个自定义 systemd 服务
理论知识学完了,我们来真刀真枪地操作一遍。假设你写了一个 Python 脚本 /opt/myapp/worker.py,想要它作为系统服务运行,开机自启、崩溃自动重启。
第 1 步:创建服务单元文件
服务单元文件通常放在 /usr/lib/systemd/system 目录下,以 .service 结尾。
vim /usr/lib/systemd/system/myapp.service
第 2 步:编写单元文件内容
一个标准的 service unit 文件分为三个段落:
[Unit]Description=My Application WorkerAfter=network-online.targetWants=network-online.target[Service]Type=simpleUser=appWorkingDirectory=/opt/myappExecStart=/usr/bin/python worker.pyRestart=on-failureRestartSec=5sStartLimitBurst=5StartLimitIntervalSec=60s[Install]WantedBy=multi-user.target
关键参数说明:
| |
|---|
After | 弱依赖网络,network-online.target 比 network.target 更稳健 |
Type=simple | 默认值,表示 ExecStart 启动的进程就是服务主进程 |
Restart=on-failure | 仅在非零退出或被信号杀掉时重启,比 always 更安全 |
RestartSec=5s | |
StartLimitBurst=5 | |
WantedBy=multi-user.target | |
第 3 步:加载并启动服务
# 重新加载 systemd 配置(每次修改 unit 文件后都要执行)systemctl daemon-reload# 启动服务systemctl start myapp# 设置开机自启systemctl enable myapp# 查看状态确认systemctl status myapp
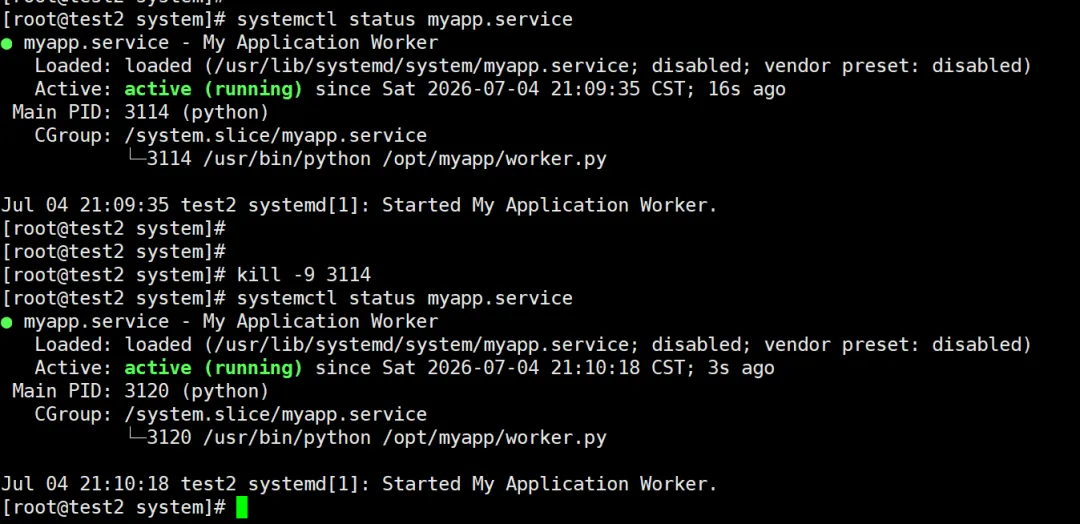
第 4 步:测试自动重启
你可以手动 kill 掉进程,验证 systemd 是否会自动拉起来:
# 找到进程 PIDsystemctl status myapp# 杀掉进程kill -9 <PID># 稍等几秒,再次查看状态——服务应该已经自动重启systemctl status myapp
五、进阶技巧:资源限制与安全加固
systemd 还可以通过 cgroup 直接限制服务的资源占用,比手写 ulimit 可靠得多。在 [Service] 段中添加以下字段:
[Service]# 内存限制,超出即 OOMMemoryMax=512M# CPU 使用率限制CPUQuota=50%# 文件描述符限制LimitNOFILE=65536
如果你的服务是网络相关的,还可以考虑加上:
# 服务启动前检查配置ExecStartPre=/usr/local/nginx/sbin/nginx -t# 优雅重载ExecReload=/bin/kill -s HUP $MAINPID
六、常见问题排查清单
最后,送上一份快速排查清单:
| | |
|---|
| | systemctl status |
| | systemctl is-enabled |
| Type | |
| | journalctl -xe |
总结
从 SysVinit 到 systemd,Linux 服务管理走过了一条从分散到统一、从串行到并行、从简陋到强大的演进之路。对于今天的开发者与运维人员来说,掌握 systemd 和 systemctl 已经是一项必备技能。
记住三句话:
- systemd 是 Linux 的“服务管家”
- 服务出问题,先看状态再看日志
- 生产环境的常驻进程,都应该用 systemd 管理
希望这篇文章能帮你建立起一套清晰的服务管理思路,下次再遇到服务相关的问题,能够从容应对。如果你有任何问题或经验分享,欢迎在评论区留言讨论!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
