Linux内核,2800万行代码,7.5万个文件。
这是什么概念?一个人如果每天读1万行代码,不吃不睡不休息,也要读七年半。
7月2日,西班牙工程师Guillermo Casaus发了一条推文,说有人把这么庞大的一坨代码,用AI在3分钟内"读完"了,还建成了一张能查询的知识图谱。
评论区里挤满了同一个反应:这怎么可能。
一个数字,把所有人看懵了
推文原文是这么写的:
"El kernel de Linux tiene 28 millones de líneas de código. Han creado un MCP capaz de indexarlo por completo en solo 3 minutos."
「Linux内核有2800万行代码。有人创建了一个MCP,能在短短3分钟内完全索引它。」
这条推文发布短短两天,浏览量冲到6.1万,1.2万人收藏,1051个赞。评论区里挤满了同一种声音:不可能吧。


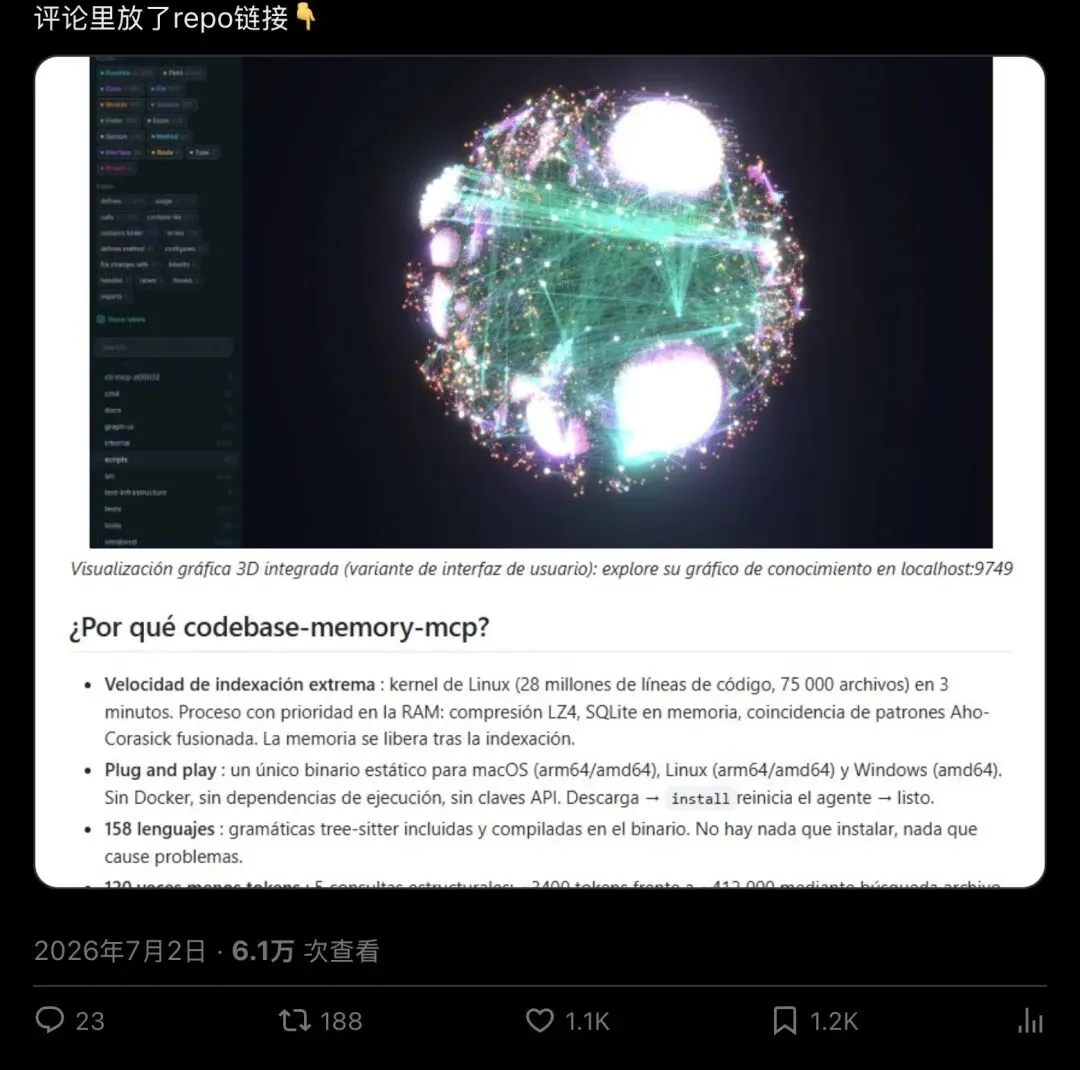
▲ @_guillecasaus 的推文(西语原文+中文翻译),6.1万次查看,评论区23条、转发188次
工具的名字叫 Codebase Memory MCP。它承诺的效果是:
→ 上下文消耗减少99%
→ 代码查询响应速度低于1毫秒
→ 兼容 Claude Code、Cursor、Gemini CLI 等11种主流AI编程工具
这几个数字放在一起,正好戳中程序员最敏感的神经:又快又省。
AI编程助手,其实一直在"笨着用"
要理解这件事为什么让人震惊,得先明白AI编程代理平时是怎么"看"代码的。
打个比方。你让Claude Code去修一个大项目里的bug,先得让它搞清楚一件事:这个函数被谁调用了?
代理没有地图,只能自己一个文件一个文件地翻。打开这个文件,搜一遍;没找到,再打开下一个;还没有,接着搜。一次简单的"谁调用了这个函数",可能要触发几十次工具调用,读几十个文件,每个文件几千token,堆起来就是数万甚至数十万token。
伦敦技术博主Russ McKendrick在评测文章里写道:
"Anyone who has spent a few hours with Claude Code or Codex on a growing project will have watched the agent grep its way around the same files over and over... It works, but it's not exactly elegant."
「只要用Claude Code或Codex碰过稍微大一点的项目,你一定见过代理在同样几个文件里来回grep。能跑通,但一点都不优雅。」
▲ Russ McKendrick的博客文章《codebase-memory-mcp: Giving Claude Code (and Codex) a Map》,配图是一个侦探式的"CALL GRAPH"照片墙,形容代理当下办案的方式:满墙贴纸条,靠人力连线
代码本质上是一张结构图:谁调用谁、谁依赖谁、路由指向哪。可AI代理长期以来被迫把代码当成纯文本去啃,一行一行读,效率低到离谱。
这就是Codebase Memory MCP瞄准的痛点。
拆开黑箱:三分钟到底发生了什么
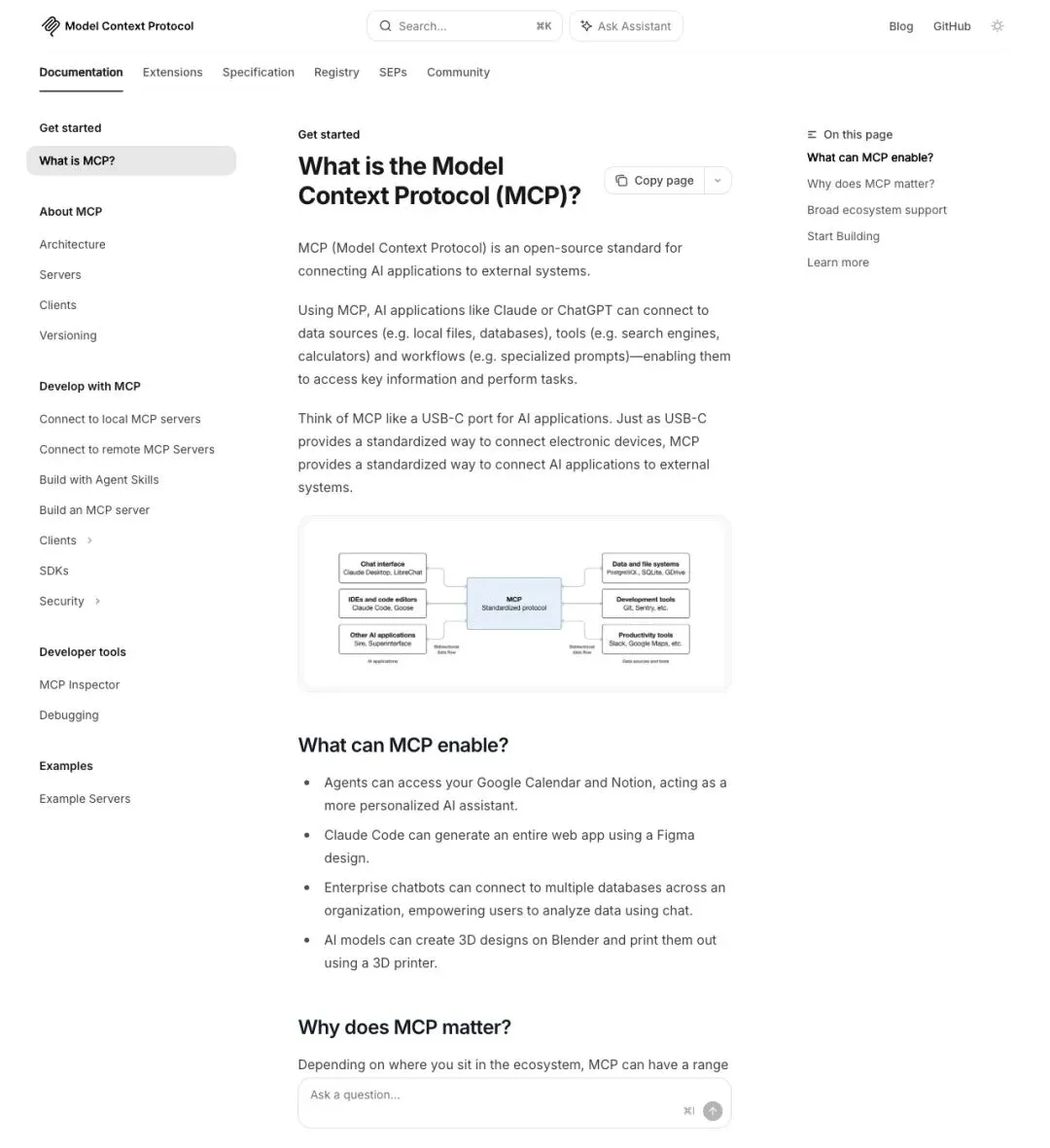
项目名字里的"MCP",全称是Model Context Protocol(模型上下文协议),2024年底由Anthropic开源,后来捐给了Linux基金会。它的作用可以理解成"AI界的USB-C",以前每个AI工具想接入一个数据源或工具,都要单独写一套对接代码;现在只要遵循MCP这一个协议标准,插上就能用。
▲ modelcontextprotocol.io 官网首页说明:MCP就像给AI应用装了个标准接口,聊天界面、IDE、数据库都能"插拔式"接入
Codebase Memory MCP,就是一个专门做"代码结构分析"的MCP服务器。它的工作流程大致是这样:
第一步,用Tree-sitter(一种快速、支持增量解析、容错率高的语法解析器)给158种编程语言的代码生成抽象语法树,把函数、类、导入关系都提取出来。
第二步,对Python、TypeScript、Go、C++、Java、Rust等主流语言,再叠加一层"Hybrid LSP"(轻量级语言服务器协议解析),处理泛型、指针、继承这些复杂场景,让"谁调用了谁"这条边尽量准确。
第三步,多个worker并行跑:发现文件、提取定义、解析调用关系、构建图、存进SQLite数据库,还会用Louvain社区检测算法自动划分出"模块"。
跑完这一整套流程,最终暴露出14个MCP工具给AI代理调用,查函数调用链的、查架构总览的、查死代码的、用类似Cypher语法查图的,一应俱全。以后代理再问"这个函数谁调用了",不用满世界翻文件,查一次图就有答案。
而这一切打包成一个静态二进制文件,不需要Docker、不需要Ollama、不需要API密钥。下载、装好、重启一下AI代理,就能用。
▲ DeusData/codebase-memory-mcp 仓库主页:2.5万星、1.9千次fork、86位贡献者,简介写着"平均一个仓库毫秒级索引完,158种语言,亚毫秒级查询,token减少99%"
论文先来,热度后到
有意思的是,这个项目走的是一条反常路径,论文先挂出来,热度才姗姗来迟。
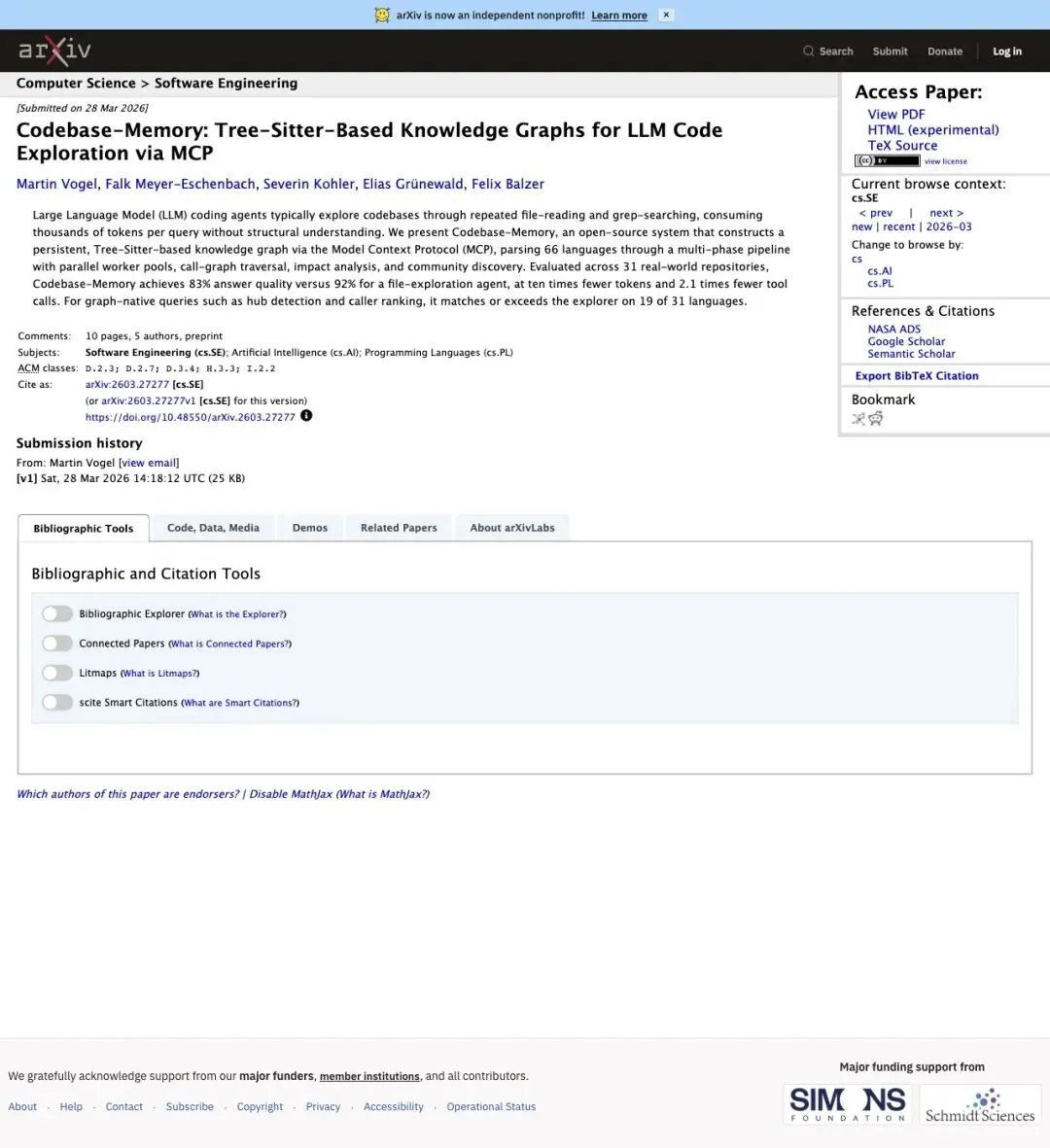
早在2026年3月28日,Martin Vogel等5位作者就在arXiv上挂出了预印本论文《Codebase-Memory: Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP》。
▲ arXiv:2603.27277,提交于2026年3月28日,作者Martin Vogel、Falk Meyer-Eschenbach等5人,隶属Software Engineering分类
论文里最关键的一句摘要是:
"Evaluated across 31 real-world repositories, Codebase-Memory achieves 83% answer quality versus 92% for a file-exploration agent, at ten times fewer tokens and 2.1 times fewer tool calls."
「在31个真实世界仓库上评估,Codebase-Memory的回答质量达到83%(对比传统文件遍历代理的92%),但token消耗只有十分之一,工具调用次数减少2.1倍。」
注意这个83%对92%,结构化图查询并没有全面碾压传统方法,在需要通读全文语境的问题上,图查询反而略逊一筹。但对付"谁调用了这个函数""这个模块的架构长什么样"这类结构性问题,图查询能匹配甚至超过传统探索方式,成本却只要几分之一。
这篇论文挂出来的时候,圈子里没什么水花。
真正把它炒热的,是6月15日数据科学博主Charly Wargnier(@DataChaz)的一条长推文。他把论文数据、项目卖点拆解得明明白白,还抛出了一个让人愣住的问题:
"Are we one good index away from cutting AI dev costs to zero?"
「我们离把AI开发成本降到零,只差一个好索引吗?」
这条推文拿到8.7万次浏览,1.2万赞,2000次收藏。
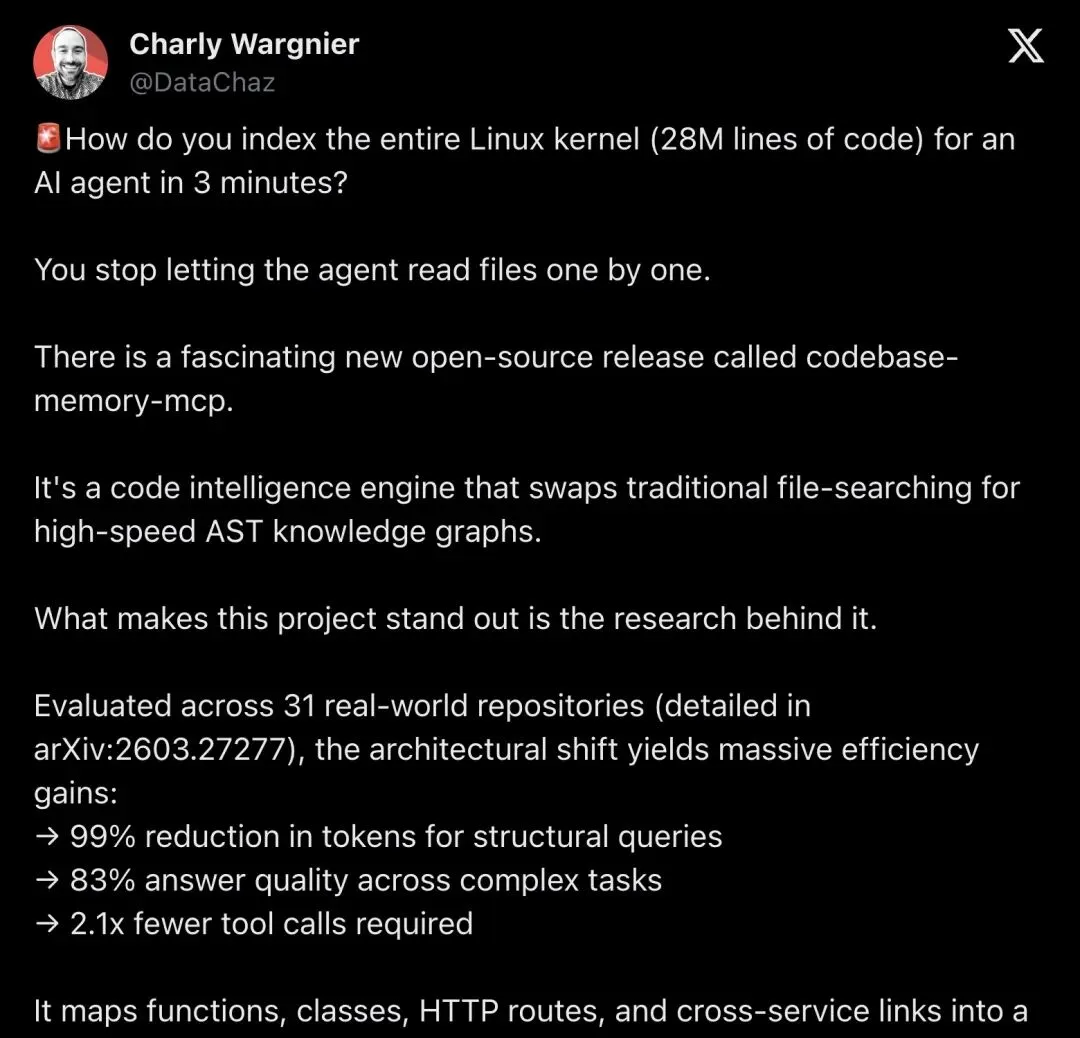


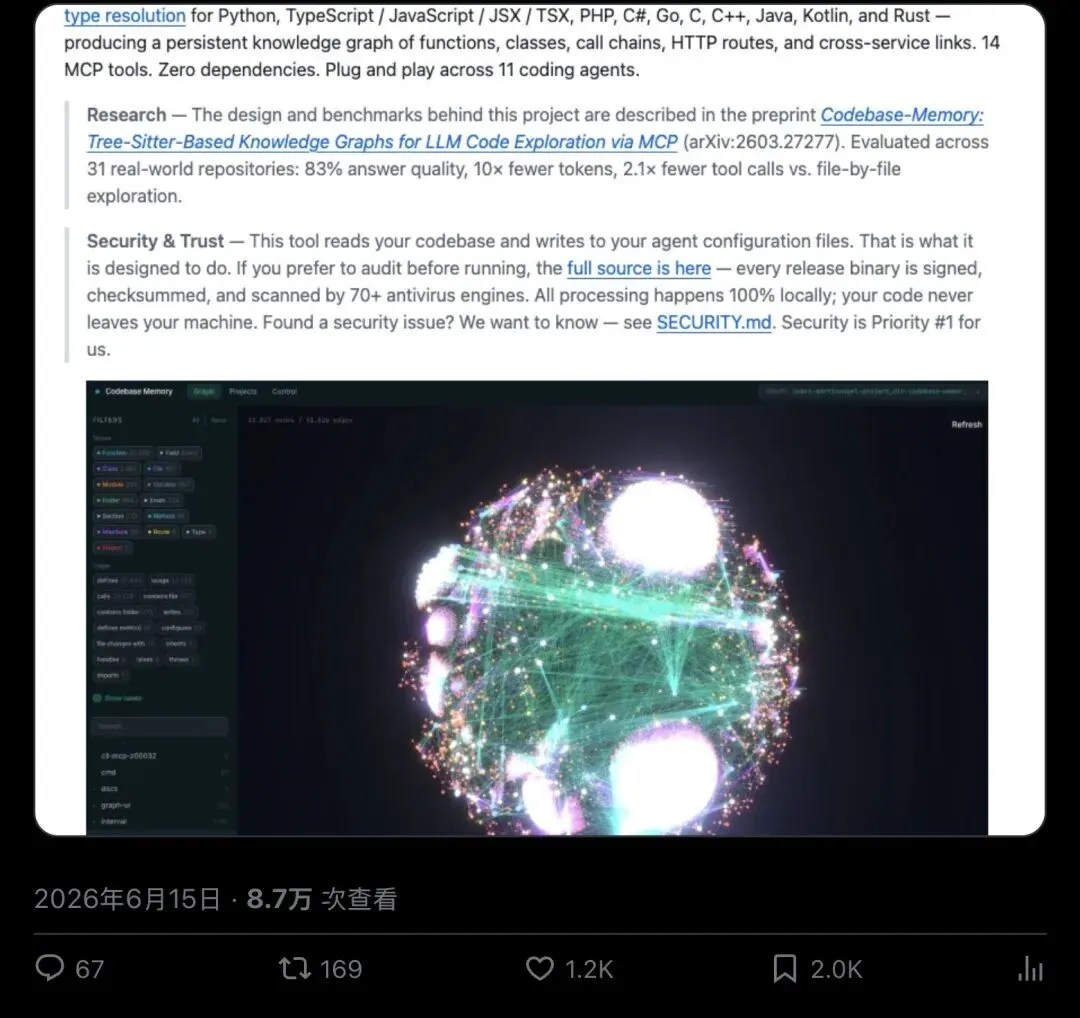
▲ @DataChaz 的推文,6月15日发布,8.7万次查看:把论文数据、性能对比讲得非常细,是这一轮讨论里信息量最大的一条
从3月的论文,到6月的技术圈层扩散,再到7月初西班牙语、中文社区跟进转发,GitHub star数从几千一路涨到2.5万+。项目也从最初支持66种语言,迭代到了现在的158种,还加上了3D图形化界面、团队共享图谱等新功能。
这是一条典型的开源走红路径:论文打底、benchmark撑腰、一条推文点火,社区跟着口口相传。
快归快,代价也不小
数字好看归好看,这工具也算不上万能钥匙。
它是纯静态分析,抓不住运行时才会发生的事情:反射、动态注册、依赖注入。C语言里的宏展开,解析质量也打了折扣。图里存的是结构关系,具体某一行代码写了什么它并不记录,代理真要看代码内容,还是得回退去调用读文件的工具。
社区里也有人质疑:这会不会只是换了个花哨说法的AST分块工具?但从Linux内核这个"压力测试"级别的案例、加上论文31个仓库的实证结果来看,它确实做出了超越简单文本切块的效果。
还有一层顾虑更现实:这类MCP服务器权限不小,既要读你的代码,还要写AI代理的配置文件。供应链安全是绕不开的问题。项目方给出的应对是:每次发布都做代码签名,跑70多个杀毒引擎扫描,符合SLSA L3供应链安全标准,处理过程全程离线,任何数据都不会传出这台机器。
这也是为什么这套方案在受监管、重隐私的企业环境里特别受欢迎,一切都留在本地机器上,不需要API key,也不用把数据传到云端。
一张图,正在改写agent的经济账
从ctags到LSP,再到今天的知识图谱,每一次工具进化,本质上都是在降低"理解代码"这件事的摩擦力。
以前AI代理为了搞清楚一个改动会影响哪些地方,可能要读50个文件,每个文件几千token,堆起来轻松破10万。现在图建好之后,一次结构化查询就能拿到答案,代理省下来的token,能拿去做真正该做的事,推理和写代码,不用再耗在文件系统里瞎逛。
这笔账算下来,如果大型重构、跨服务调试这类agent任务的成本能被压缩到原来的百分之一,那对整个AI编程行业意味着什么,已经不言而喻。
至于DataChaz抛出的那个问题,只差一个好索引,就能把AI开发成本降到零吗?
答案大概率是否定的。但2800万行代码、3分钟、99%这几个数字凑在一起的时候,至少说明一件事:这个方向,走对了。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
