一个AI代理要读懂一个函数被谁调用,正常情况下要干什么?
打开文件,搜索关键词,再打开十几个相关文件,一行行看过去,猜哪个是真正的调用者。中大型项目里,这个过程能烧掉几十万token,等上几分钟,账单唰唰往上涨。
现在有人把这套流程整个砍掉了。
Linux内核,2800万行代码,7.5万个文件。用一个叫Codebase Memory MCP的开源工具,3分钟建完整个知识图谱。建完之后,AI代理问什么,图谱答什么,响应时间不到1毫秒。
这条消息从西班牙科技博主 @_guillecasaus 的推文传出来,一天之内点赞破千,转发飞快。而更早之前,另一位博主 @DataChaz 六月中旬发的英文版,已经在推特上滚了半个月雪球。
一条推文,把整个开发者圈子炸醒
@_guillecasaus 在推文里这么写:
"El kernel de Linux tiene 28 millones de líneas de código. Han creado un MCP capaz de indexarlo por completo en solo 3 minutos."
「Linux内核有2800万行代码。他们创建了一个MCP,只用3分钟就能完全索引它。」
他接着列出三条效果:
- 兼容 Claude Code、Cursor、Gemini CLI 等多种工具


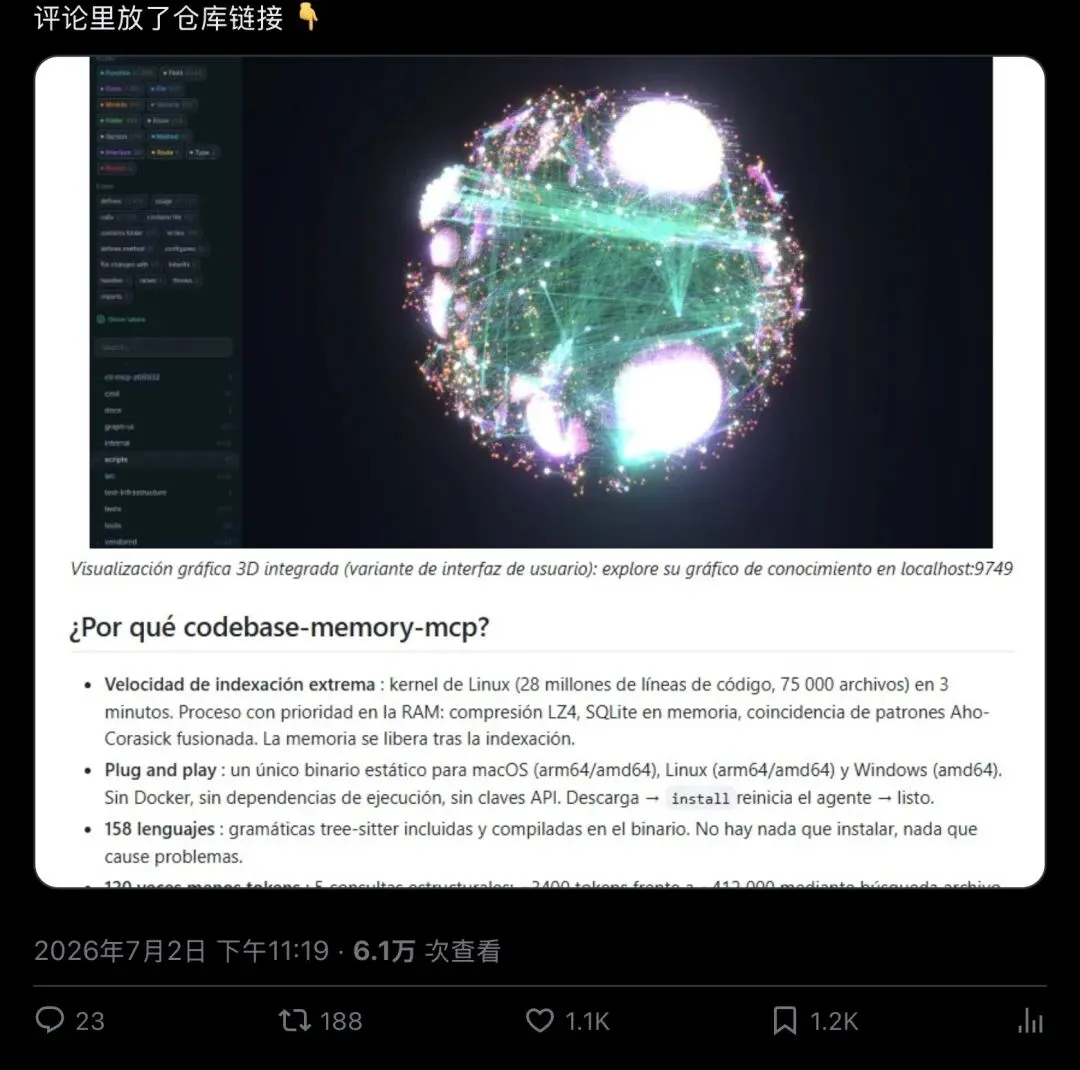
▲ @_guillecasaus 发布于2026年7月2日,6.1万次查看,1.1K点赞,1.2K收藏
这条帖子发出时,Codebase Memory MCP 在GitHub上已经超过2.4万星。而把这个项目最早推上风口的,其实是另一位博主 @DataChaz。他六月中旬那条帖子提了个更狠的问题:
"How do you index the entire Linux kernel (28M lines of code) for an AI agent in 3 minutes? You stop letting the agent read files one by one."
「怎么在3分钟内为AI代理索引整个Linux内核(2800万行代码)?答案是:别再让代理一个文件一个文件地读了。」


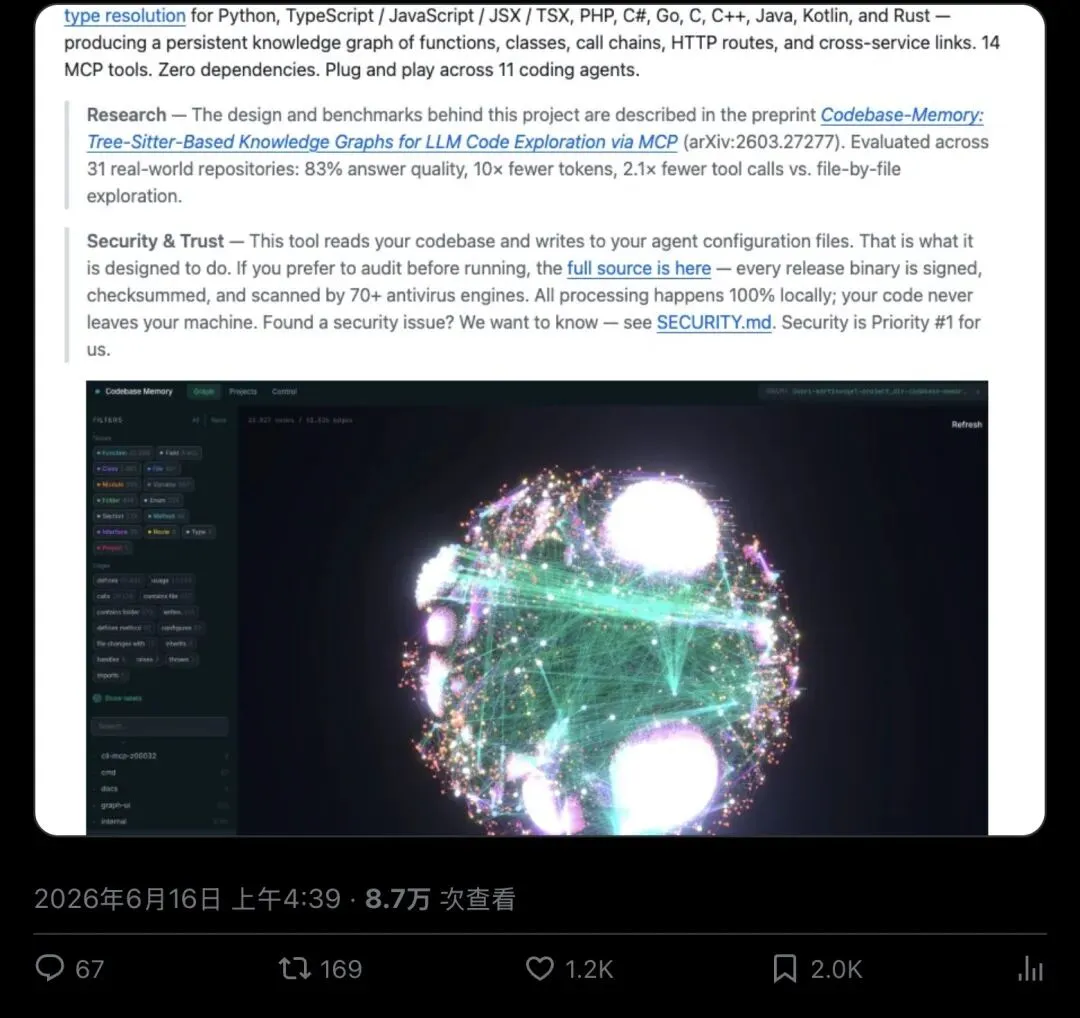
▲ @DataChaz 发布于2026年6月16日,8.7万次查看,1.2K点赞,2.0K收藏,是这波热议最早的源头帖
两条推文隔了半个多月,说的是同一件事:AI代理干活的方式,可能要变了。
AI写代码为什么这么烧钱
想弄明白这事有多颠覆,得先搞清楚AI代理原来是怎么干活的。
Claude Code、Cursor这类编码代理本质是个"对话+工具调用"循环。每一轮,代理决定要不要打开一个文件、搜一个关键词、列一下目录,把拿到的文本塞进上下文,再想下一步干嘛。
问题是,大项目动辄几万个文件。代理想搞清楚一个函数的调用链、一条HTTP路由背后挂了哪些处理逻辑,往往要跑上三十到一百多次工具调用。上下文越滚越大,token账单跟着涨,响应也越来越慢。
有实测数据能说明这事有多离谱:同样是五个结构性问题,靠文件遍历要消耗约41.2万token,换成图谱查询,只需要约3400token,降了99.2%。
这换掉的,是整套活法,而不只是某个环节的效率。
把代码结构变成一张地图
Codebase Memory MCP 干的事,核心就一件:把整个代码仓库解析成一张知识图谱,让AI代理查图找答案,不用再满仓库瞎翻。
拆开看,它靠几层东西撑起来:
第一层,Tree-sitter快速解析。这是一款诞生于2018年、被VSCode、Zed等主流编辑器广泛采用的语法解析引擎,增量、容错、速度快。Codebase Memory MCP把158种语言的语法规则整份打包进二进制文件,装上就能用,不用额外安装任何东西。
第二层,Hybrid LSP语义层。对Python、TypeScript、Go、C、C++、Java等9种主力语言,再叠加一层轻量类型解析,跟踪import关系、处理泛型和this/super指向,让"谁调用了谁"这条边尽量准确,而不用真跑一个笨重的language server进程。
第三层,多阶段并行流水线。定义提取、调用解析(6种策略级联加类型回填)、HTTP/gRPC跨服务边识别、Louvain社区发现算法自动聚类功能模块,最后落进一个SQLite文件里,走LZ4压缩,全程RAM优先,索引完就释放内存。
建完图之后,MCP协议对外暴露14个工具:search_graph搜索、trace_call_path追调用链、get_architecture拿架构全貌、query_graph跑类似Cypher的图查询语句、detect_changes感知代码变动……AI代理不再需要自己摸索代码结构,问图就能拿到答案。
代理终于揣着一张地图上路了,不用每次都重新走一遍迷宫。
性能指标摆出来
翻GitHub主页能看到最直观的对比表:Linux内核这个体量的仓库,完整索引只要3分钟(M3 Pro芯片测试);Django这种中型项目,6秒搞定,产出4.9万个节点、19.6万条边。查询层面,图关系遍历不到1毫秒,名称正则搜索不到10毫秒,死代码检测约150毫秒,五层调用链追踪不到10毫秒。
▲ GitHub仓库首页:25.5k星标,1.9k复刻,性能对比表和一键安装命令一目了然
支撑这些数字的不只是营销话术。柏林多家研究机构在今年3月发了篇论文,题目叫《Codebase-Memory: Tree-Sitter-Based Knowledge Graphs for LLM Code Exploration via MCP》,挂在arXiv上,编号2603.27277。
▲ 论文由Martin Vogel等5位作者提交,2026年3月28日上线,主题词覆盖软件工程、人工智能、编程语言三个分类
论文在31个真实仓库上做了对比测试:图谱代理的答案质量是83%,文件遍历代理是92%,图谱代理略输一筹;但图谱代理消耗的token少了10倍,工具调用次数少了2.1倍。更关键的是,在需要理解代码结构的查询上(比如找核心枢纽函数、给调用者排名),图谱代理在31种语言里的19种打平甚至反超了文件遍历代理。
这组数字其实挺诚实:图谱查询换不来百分百的准确率,拿的是87%左右的答案质量,换来的是十倍以上的效率。对大多数结构性问题,这笔账划算。
真实场景里,它到底好不好用
数据之外,独立开发者的实测更有说服力。技术博主Russ McKendrick五月份写了篇长文,标题就叫《codebase-memory-mcp: 给Claude Code和Codex一张地图》,里面记录了自己给Claude Code装上这个工具后的真实使用体验,包括token账单变化和内置3D图谱可视化界面的截图。
▲ Russ McKendrick的评测文章插画:一个像素小人在"调用关系墙"前研究process_order函数是谁在调用
社区里的技术文章跟进也很快。dev.to上一篇标题起得毫不客气的文章写道:
"Stop Making Your AI Coding Agent Grep Your Whole Repo — Try codebase-memory-mcp"
「别再让你的AI编码代理满仓库grep了,试试codebase-memory-mcp。」
作者形容得很生动:代理"grep一下,读几个文件,再grep一下,再读几个文件,最后总算答上来了,可这一路烧掉了一小片森林的token"。
▲ dev.to作者ArshTechPro的文章,获得多个emoji反应,评论区也在讨论实际接入体验
质疑的声音也不少
爆火归爆火,冷静的声音一直没断。
有开发者在评论区追着问:"建图这个过程本身不也要消耗token去分析代码吗?之后AI用的是MCP给出的结果,会不会漏掉细节,甚至产生幻觉?"
这个问题问到了点子上。图谱能精准捕捉函数调用、类继承这类结构性关系,但代码里那些靠宏展开、反射、运行时动态注册实现的逻辑,图谱天生抓不住,论文里也承认,C语言这类重宏项目的解析质量评分只有0.58(满分1.00)。
市面上类似定位的项目也不止这一个,codegraph、graphify、RemembrallMCP、GitNexus等都在做相近的事,评论区里反复出现"这个和XX有什么区别"的追问。而且代码改动之后,图谱需要靠watcher做增量更新,超大单体仓库的内存峰值也是要盯的指标。
说到底,它顶多算半个答案机,替代不了人工审阅。遇到框架魔法和动态特性密集的代码,还是得回退到老办法,读几个文件确认一下。
安全这张牌,打得挺稳
MCP服务器天生权限就大,能读全部代码,还能写代理的配置文件。一旦被污染,静默把代码外泄出去,这种风险谁也担不起。
这也是Codebase Memory MCP刻意做重的一块。它是纯C语言写的静态二进制,不依赖任何运行时环境。每个发布版本都过70多个杀毒引擎扫描,检出数是0。构建流程符合SLSA 3级标准,可证明构建过程没被篡改;发布产物用Sigstore签名;CI流水线还叠了危险libc函数白名单审计、strace网络行为监控、地址消毒器(ASan)等多层检查。
▲ 最新版本v0.8.1发布说明:70+杀毒引擎0检出,SHA-256校验和VirusTotal链接一应俱全
在"代码即命根子"的年代,一个明确写着"全程本地处理、代码从不离开你的机器"的工具,本身就是最有说服力的卖点。不用连云端,不用API key,下载完二进制文件重启代理就能用。
这事真正在改变什么
把镜头拉远一点看。
Model Context Protocol这套标准这两年被越来越多AI代理采用,本意是让代理能以统一方式接外部工具和数据源。早期大部分MCP服务器做的都是简单的资源暴露,Codebase Memory MCP算是把复杂静态分析这件重活,第一次做成了标准化、可插拔的基础设施。
索引一次,查询无数次,这是它真正的杀手锏。传统方式把"搞懂代码结构"这个成本摊到了每一次对话里,代理每次都要从头认路。知识图谱把这笔成本一次性付清,后面的每次查询都近乎免费。
2800万行代码、3分钟建完,换算下来大概是每秒解析15.5万行的吞吐量。普通中小项目,几秒到十几秒就能跑完全量索引。这个数字之所以能成为最强的营销钩子,是因为它证明了一件事:这套方法在真实世界最庞大的代码库上也立得住。
代理和代码之间,原来隔着一堆文件和猜测;现在隔着的,是一张实时更新的地图。