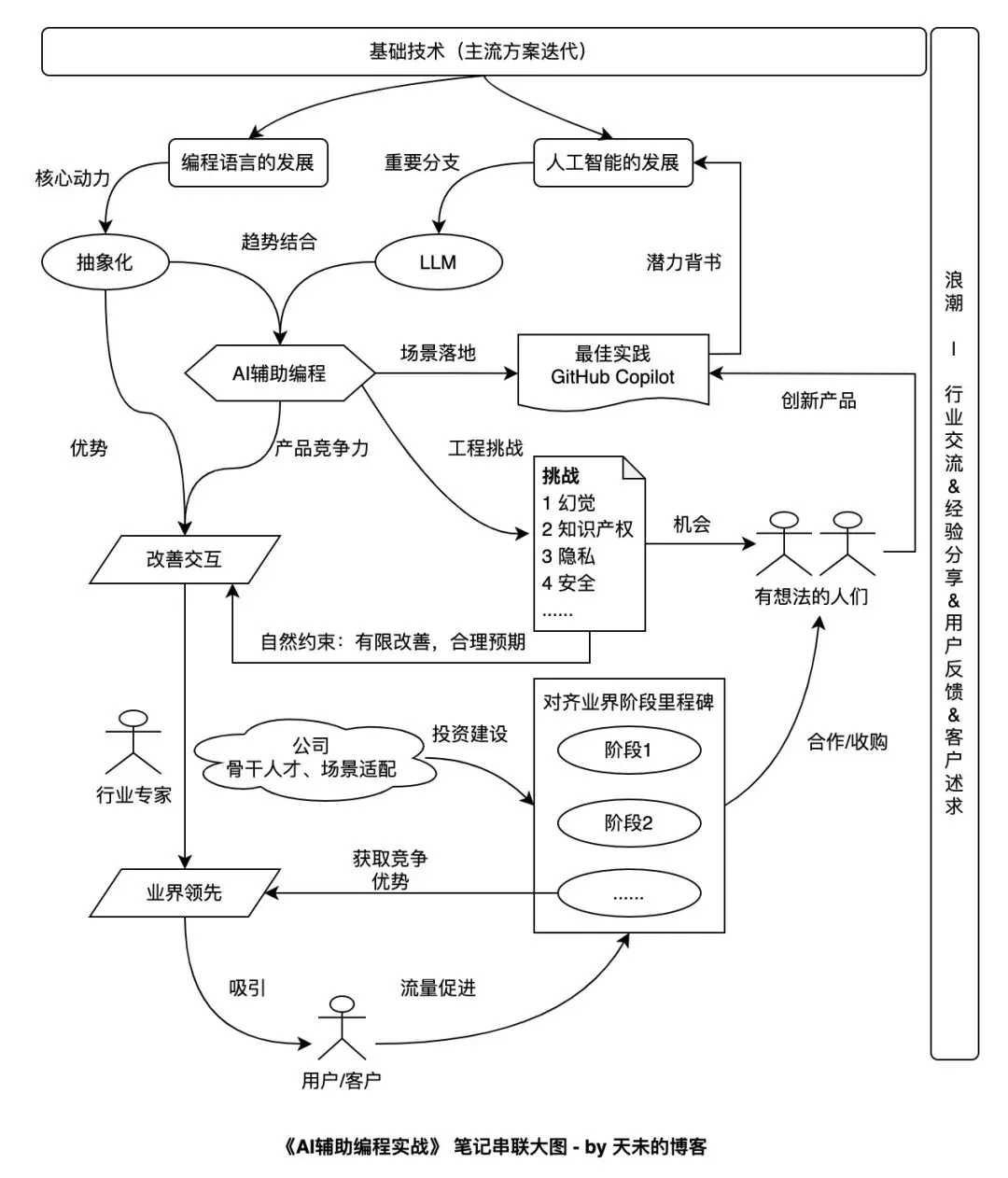
比起AI本身,我更想了解AI背后的思考逻辑和借此进行一些训练。我平时经常画图,期望将笔记和大图相结合,呈现一定的理解。本文内容笔记串联大图如下:
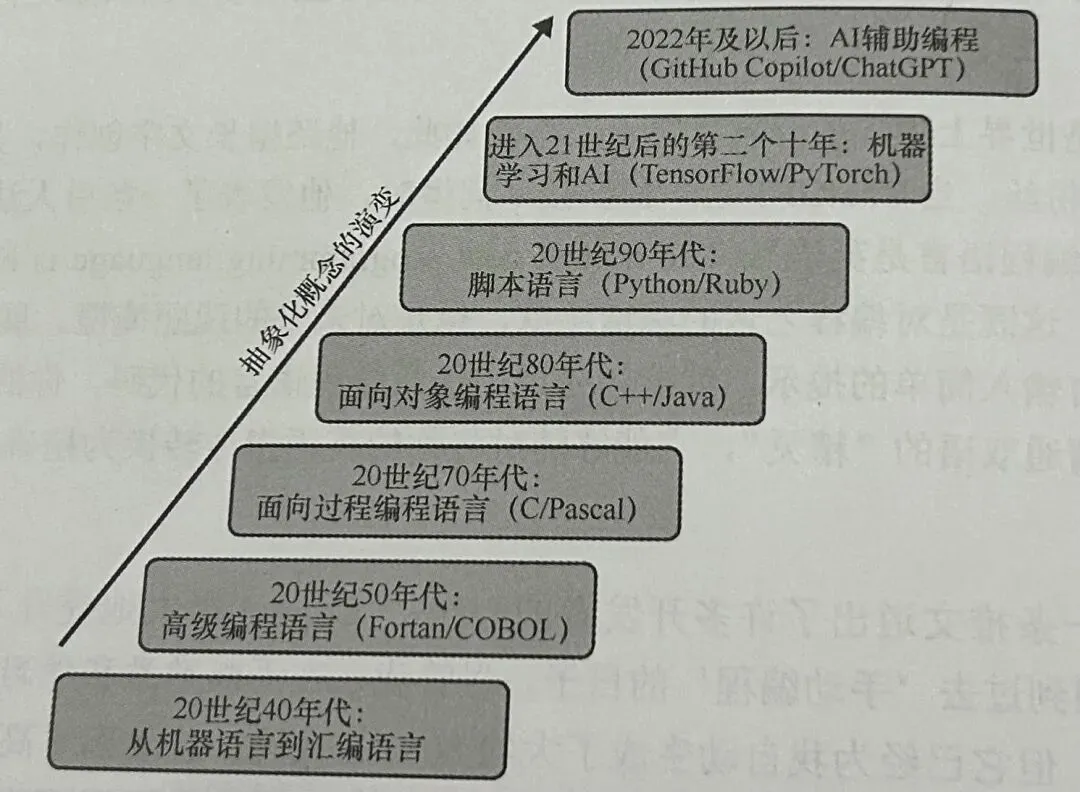
编程语言发展的核心动力之一是抽象化,这是一种独特的方法,它极大地简化了开发者与系统之间的交互。
近十年来抽象化概念在编程语言中的演变过程
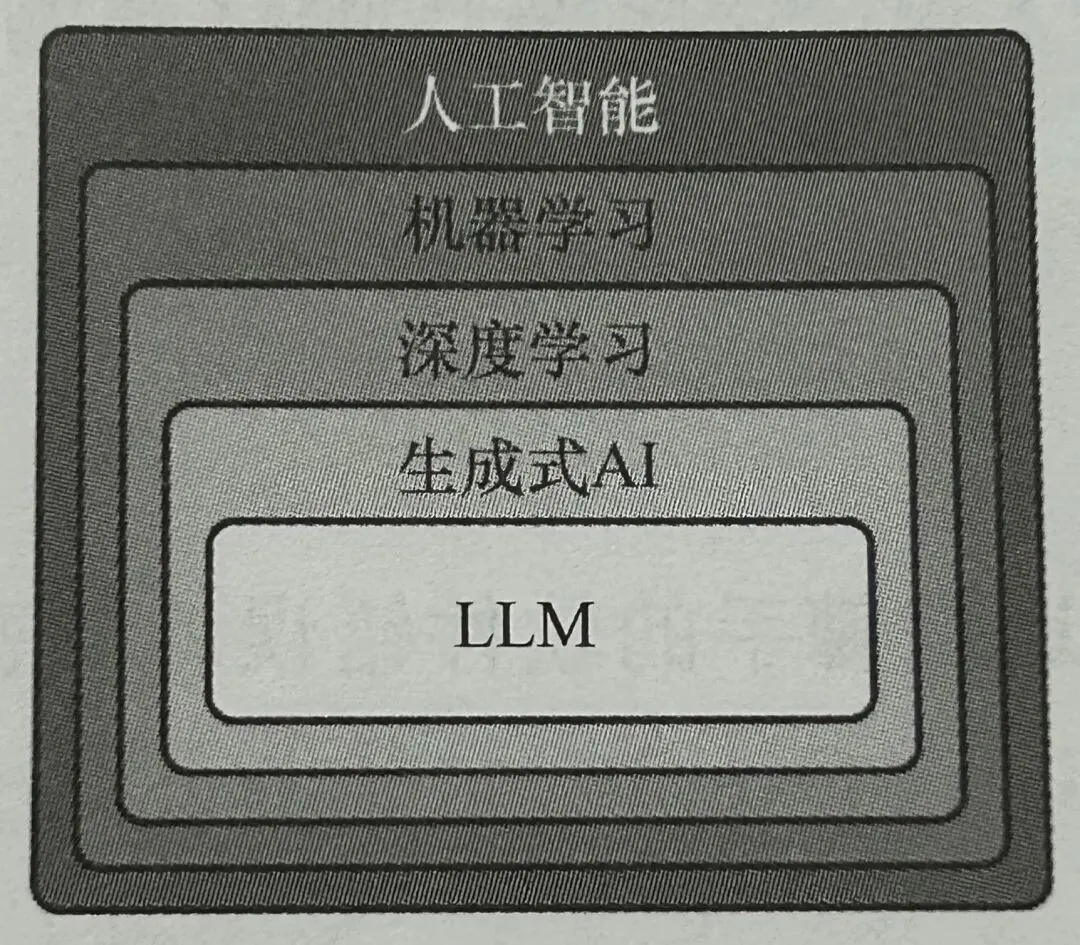
生成式 AI(Generative AI,或称为 GenAI)作为人工智能领域的一个重要分支,专注于生产创新且独一无二的内容。
不同类型的人工智能
据研究,高达88%的 GitHub Copilot 用户反馈,在使用此工具后,他们的挫败感显著降低,同时注意力也更为集中。其中一个尤为显著的原因是,GitHub Copilot 帮助他们在 IDE 中减少了搜索时间,这极大地促进了开发者持续处于高效的“心流”状态。
AI 辅助编程工具的一些不足之处如下所示:
- 幻觉:对于 LLM,幻觉是指模型输出的数据看似准确,但实际上并不正确,或者与模型所谓训练的输入数据不符。
- 知识产权:普遍认为可基于“合理使用”的原则。然而,法律界对于 AI 生成内容的处理方式并不明确,缺乏具体的指导原则。
- 隐私:AI 辅助编程工具由于云端部署的特性,引发了广泛的数据隐私和保密性问题。公司内如何妥善保护数据?这些数据是否会被用作训练数据?
- 训练数据:依赖的 LLM 训练数据,往往存在显著差距,这些差距会直接影响他它们在现实应用中的表现与实用性。
- 偏见:工具在生产代码时,可能会不自觉地延续其训练数据中已有的偏见。如,当要求生产人名列表时,它们可能会倾向于推荐英文名字。
10倍开发者:10倍开发者意味着拥有10个开发者的能力。在AI辅助编程工具的帮助下,我能成为10倍开发者吗?很抱歉,可能不会。虽然人工智能技术带来了显著的变化,但它的改进通常不是以数量级为单位的。
AI 辅助编程工具的有效性,往往取决于开发者掌握的专业知识。以下是一些考虑因素:错误修复、理解组织者的要求、解决棘手问题。
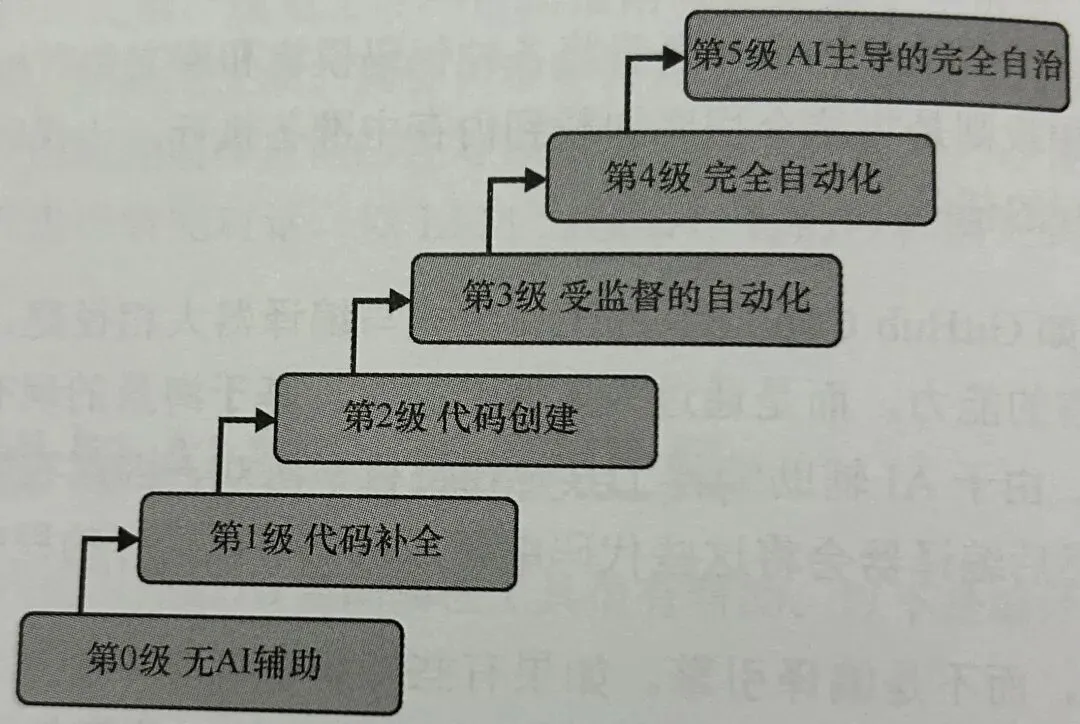
2003年10月,Sourcegraph 的首席执行官兼创始人分享了一篇颇有见地的文章,他深入探讨了像 Github Copilot 这样的 AI 辅助编程工具,并提出了一种新颖的思考模式,他称之为“AI 代码层级”。
编程系统中 AI 能力的不同层级
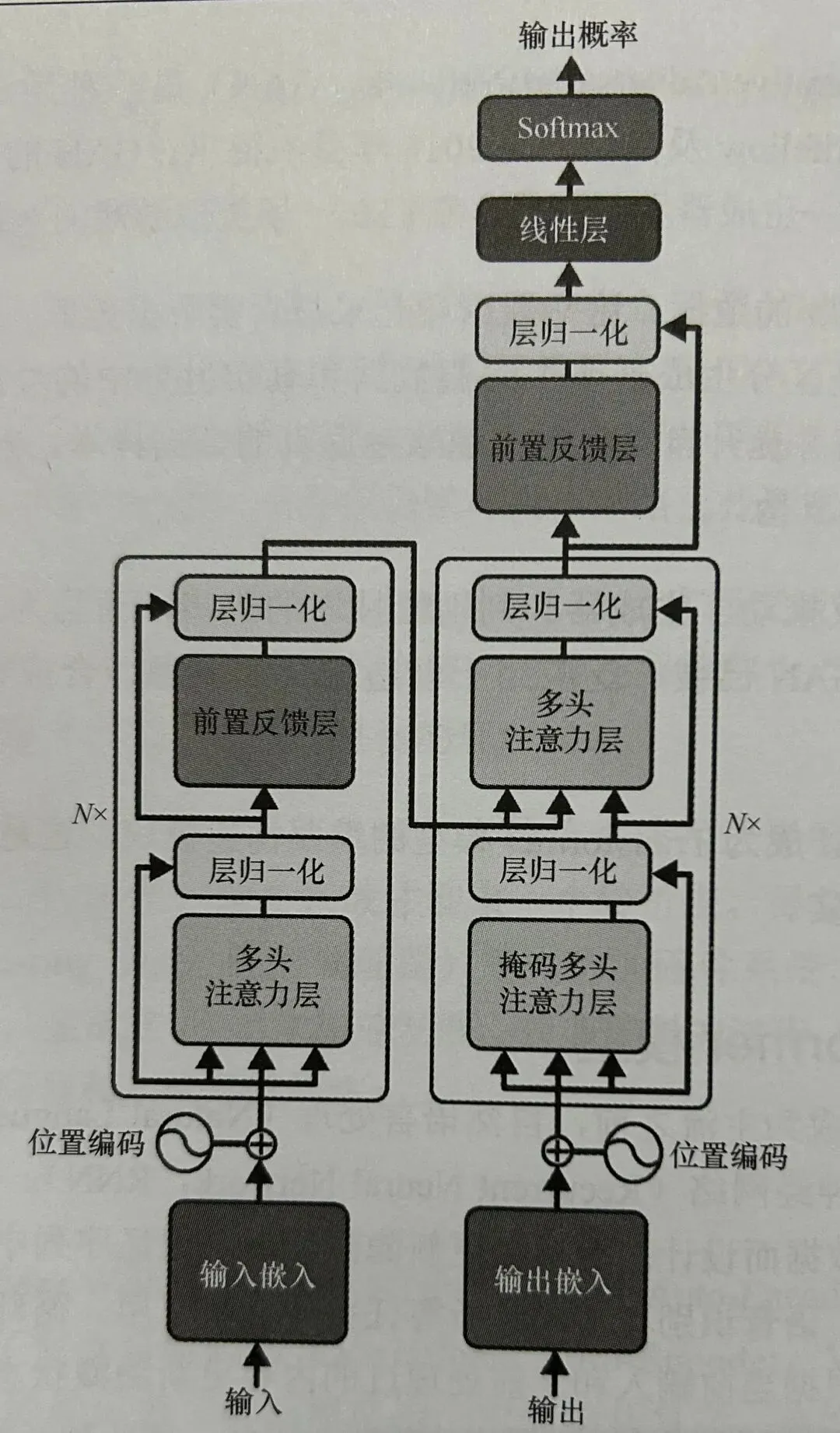
在 Transformer 模型成为主流之前,自然语言处理(Natural Language Processing,NLP)的首选技术是循环神经网络(Recurrent Neural Network,RNN)。Transformer 模型的出现彻底颠覆了这一局面。由 Ashish Vaswani 和他带领的 Google 研究团队开发的 Transformer 模型的核心架构,在 2017 年发表的开创性论文“Attention Is All You Need”中公布。
Transformer 模型的主要部分
有时候提示词工程可能会令人感到沮丧。以下是提示词面临的一些挑战:
- 啰嗦:有时候LLM可能会过于健谈。如果希望LLM直截了当地回答,你可以要求它们“简明扼要”。
- 不可移植:在一个 LLM 中表现出色的提示,在另一个 LLM 中可能效果不佳。因为不同的模型是在不同的数据集和算法上训练出来的。
- 长度敏感:LLM 可能会对过长的提示感到困惑,开始忽略或误解你输入的部分内容。因此,应避免在提示中提供过多的细节,并尽量将提示内容限制在一页之内。
- 歧义:如果你的提示不够明确,LLM 可能会感到困惑,并提供与事实完全不符或完全虚构的回答。因此,提供清晰的提示至关重要。
提示主要由4个部分组成:
- 上下文:在编写提示时,通常从简洁的一两句话开始,以便模型提供必要的上下文。这通常包括指定 LLM 在回答时应该扮演的角色或身份。
- 指令:提示词中至少应包含一个明确的指令。一些类型有:摘要、文本分类、建议、翻译。
- 输入内容:在构建提示时,使用 #### 或 """ 等特殊符号来明确区分指令和希望LLM学习的内容或信息,是一种非常有效的策略。
- 输出格式:在提示中,可以告诉 LLM 如何格式化输出。
优秀实践涉及到这些方面:
- 零样本学习和少样本学习:少样本学习指的是LLM能够利用极少量的示例或训练数据来理解任务要求并执行任务。
- 引导词:引导词是一种特殊的关键字或短语,它能够指导 LLM 生成特定类型的输出。
- COT 提示: 思维链(Chain-of-Thought,COT)通过向模型展示少量示例来引导其理解和执行任务。