动态RAG新工作:效果爆了,代码已开源
- 2026-07-08 02:25:09
嗨,我是PaperAGI,主要关注LLM、RAG、Agent等AI前沿技术,每天分享业界最新成果和实战案例。
随着大语言模型(LLM)能力的提升,幻觉问题(hallucination)愈发突出:模型会生成看似合理实则错误的内容,而且往往自信满满。现有动态检索增强生成(Dynamic RAG)方法试图通过模型内部信号(如概率、熵、注意力)判断“何时检索”,但这些信号本身就不靠谱——大模型天生校准不良,常常对错误输出赋予高置信度。
核心痛点:
模型内部不确定性信号不可靠,导致“自信幻觉”; 静态RAG策略无法应对多跳问答中动态涌现的信息需求; 现有方法对长尾知识和实体间关系缺乏有效验证手段。
QuCo-RAG:用“客观证据”替代“主观自信”
QuCo-RAG(Quantifying uncertainty via pre-training Corpus for Dynamic RAG)提出从预训练语料库中挖掘统计证据,用客观频率替代主观置信度,实现毫秒级幻觉检测与动态检索触发。

核心思想:两个“零”触发检索
| 生成前 | |||
| 生成中 | 实体对在语料中从未共现 |
一句话总结:冷门实体提前防,零共现实时拦。
系统流程
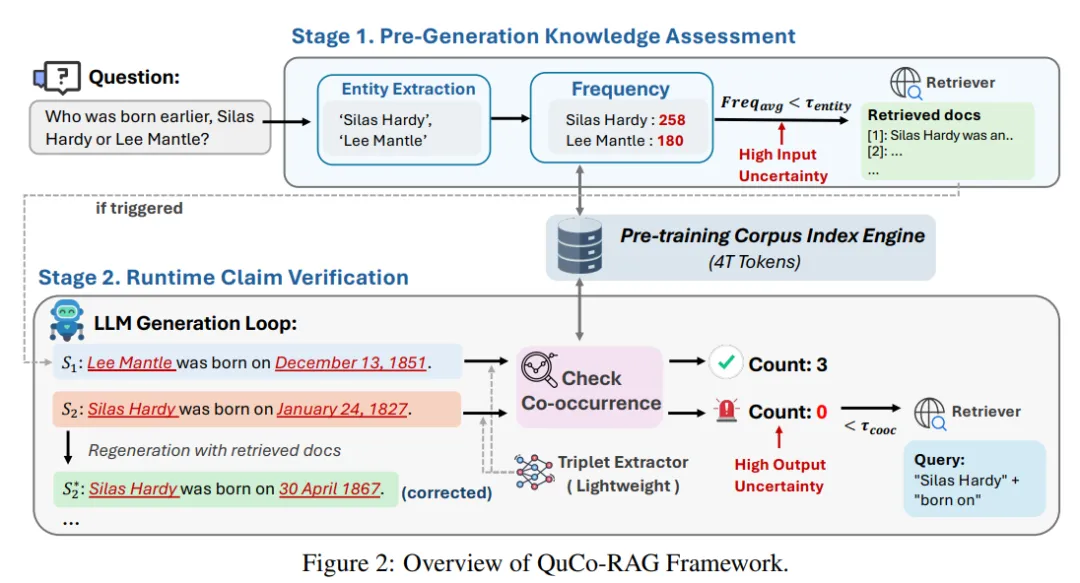
预生成知识评估抽取问题实体 → 查频率 → 低频触发检索,提前把相关文档塞进上下文。
运行时声明验证每生成一句,抽三元组(head, relation, tail) → 查head&tail在语料是否共现 → 零共现=幻觉风险 → 触发检索并重写句子。
毫秒级查询引擎借助Infini-gram后缀数组索引,在4万亿token规模上实现毫秒级n-gram/共现查询,开销可忽略。
实验结果:碾压SOTA,还能跨模型迁移
主实验:多跳问答全面领先
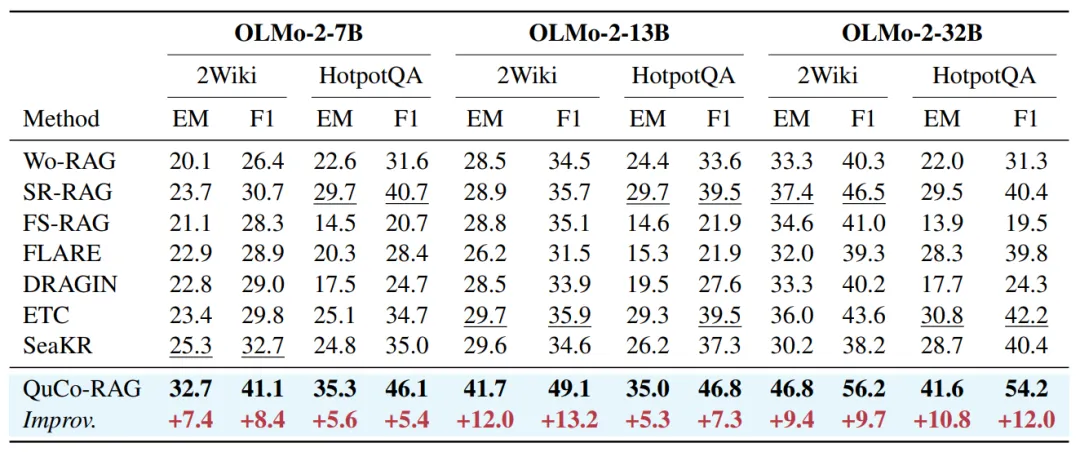
| 绝对提升 | ||||
|---|---|---|---|---|
| 32.7 | +7.4 | |||
| 41.7 | +12.0 | |||
| 41.6 | +10.8 |
结论:在所有规模、两个数据集上,QuCo-RAG稳定领先5~12个百分点,而依赖内部信号的方法(DRAGIN/ETC/SeaKR)波动剧烈,常被简单基线反杀。
跨模型迁移:用公开语料“猜”私有模型知识
| 提升 | ||||
|---|---|---|---|---|
| 50.0 | +14.1 | |||
| 38.4 | +4.9 | |||
| 64.6 | +4.6 | |||
| 48.4 | +5.5 |
洞察:Web-scale预训练语料高度重叠,用OLMo-2的4T语料做“代理”,就能给闭源模型提供有效统计信号,无需知晓其真实训练数据。
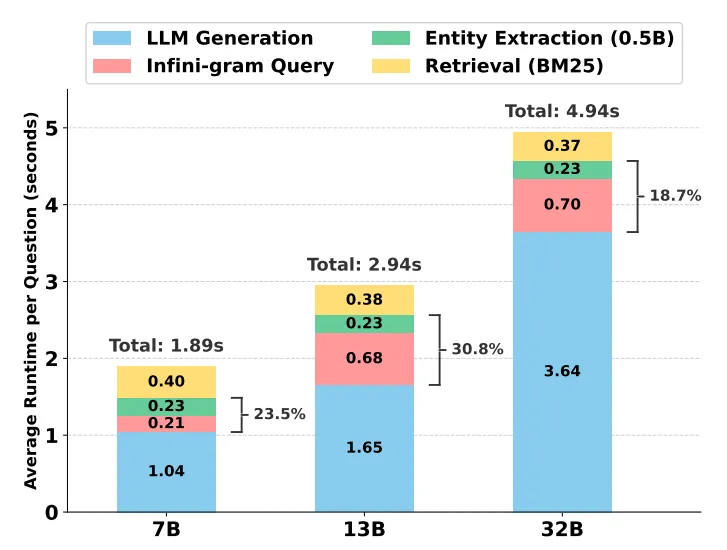
效率权衡:更高精度+更低开销
在HotpotQA(OLMo-2-13B)上:
EM最高(35.0); 平均token消耗仅87(远低于FS-RAG的464); 平均检索1.7次(FS-RAG 6.5次,SeaKR 10.3次);
深度分析:为什么QuCo-RAG更靠谱?
| 消融实验 | |
| 领域泛化 | |
| 实体频率分层 |
案例直击:DRAGIN自信幻觉,QuCo-RAG两步纠错
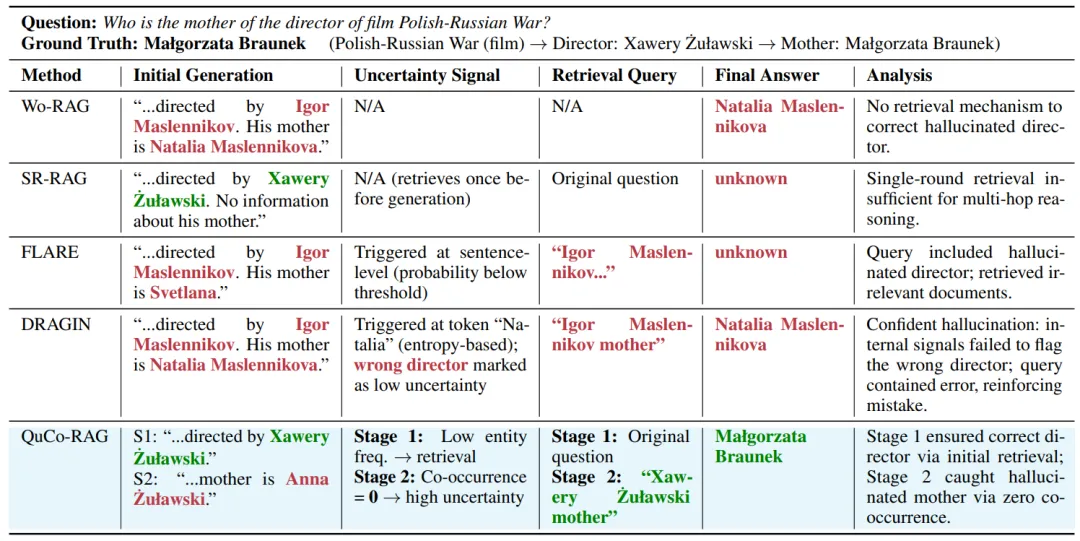
问题:Who is the mother of the director of film Polish-Russian War?标准答案:Małgorzata Braunek
| DRAGIN | |||
| QuCo-RAG | 客观语料证据 |
局限与未来
| 同义词/别名 | ||
| 静态语料 | 带时间戳的动态语料 |
QuCo-RAG用最朴素的统计量——实体频率与共现计数——就把动态RAG的不确定性估计做成了可解释、可迁移、可落地的“客观证据链”。它告诉我们:
别再迷信模型内部的“自信”了,去翻翻它小时候读过的书,用真实语料告诉它:什么时候该查资料,什么时候在胡说。
对于工业落地,QuCo-RAG不挑模型、不挑领域、不挑检索器,只需一次构建4T索引,就能给开源、闭源、通用、专业模型统一装上“幻觉雷达”,真正的即插即用。
传送门
QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generationhttps://arxiv.org/pdf/2512.19134 https://github.com/ZhishanQ/QuCo-RAG
