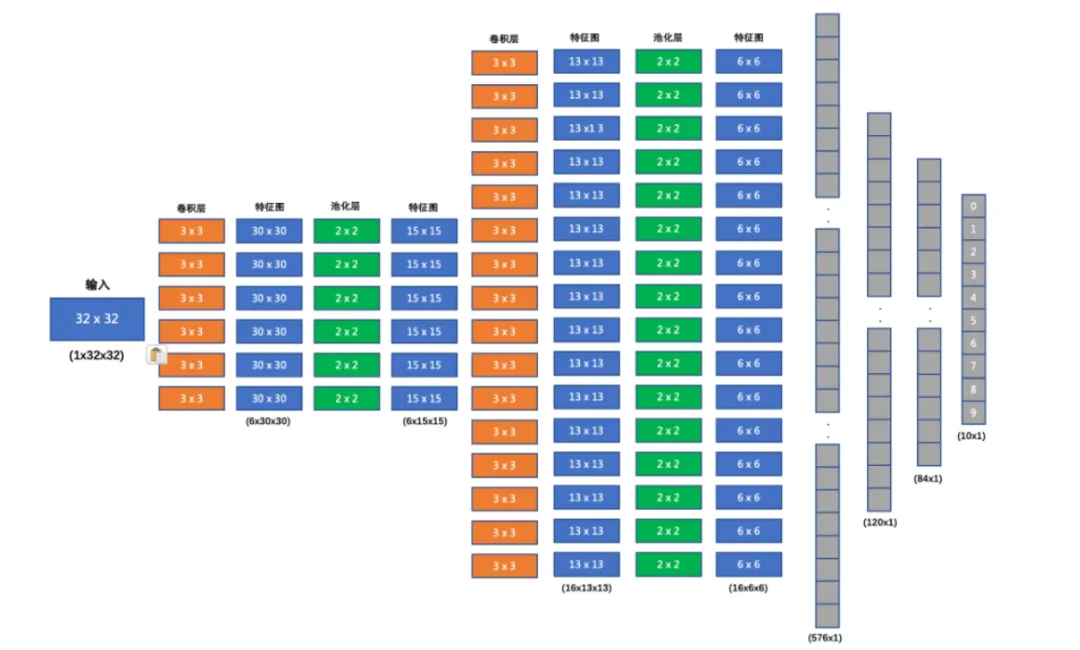
今天我们来聊聊卷积神经网络(CNN)在图像分类上的实战应用。相信很多同学在学完CNN的理论后,总想亲手搭建一个网络试试效果。本文就以经典的CIFAR-10数据集为例,带你一步步完成一个图像分类模型的构建、训练和预测。
📦 数据集介绍:CIFAR-10
CIFAR-10是一个常用的图像分类基准数据集,包含10个类别,每个类别6000张图像,共计6万张。所有图片尺寸统一为32×32像素,彩色三通道。
类别包括:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。
在PyTorch中,我们可以直接用torchvision.datasets.CIFAR10加载它,并自动转为Tensor格式,非常方便。
from torchvision.datasets import CIFAR10from torchvision.transforms import ToTensortrain = CIFAR10(root='data', train=True, transform=ToTensor())test = CIFAR10(root='data', train=False, transform=ToTensor())
🧠 网络结构设计
我们设计一个简单的CNN网络,包含:
- 1. 卷积层1:输入3通道 → 输出6通道,3×3卷积核
- 3. 卷积层2:输入6通道 → 输出16通道,3×3卷积核
- 7. 输出层:输入84维 → 输出10维(对应10个类别)
每个卷积层后接ReLU激活函数,增加非线性表达能力。
import torch.nn as nnclassImageClassification(nn.Module):def__init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 6, kernel_size=3)self.pool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, kernel_size=3)self.pool2 = nn.MaxPool2d(2, 2)self.linear1 = nn.Linear(576, 120)self.linear2 = nn.Linear(120, 84)self.out = nn.Linear(84, 10)defforward(self, x): x = self.pool1(torch.relu(self.conv1(x))) x = self.pool2(torch.relu(self.conv2(x))) x = x.view(x.size(0), -1) x = torch.relu(self.linear1(x)) x = torch.relu(self.linear2(x))returnself.out(x)
🚀 训练模型
我们使用交叉熵损失函数和Adam优化器,设置学习率为0.001,训练100个epoch。
deftrain(model, train_dataset): dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=1e-3)for epoch inrange(100):for x, y in dataloader: output = model(x) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step()
测试结果:
epoch: 1 loss:1.59926 acc:0.41 time:28.97sepoch: 2 loss:1.32861 acc:0.52 time:29.98sepoch: 3 loss:1.22957 acc:0.56 time:29.44sepoch: 4 loss:1.15541 acc:0.59 time:30.45sepoch: 5 loss:1.09832 acc:0.61 time:29.69s...epoch:96 loss:0.30592 acc:0.89 time:37.28sepoch:97 loss:0.29255 acc:0.90 time:37.11sepoch:98 loss:0.29470 acc:0.90 time:36.98sepoch:99 loss:0.29472 acc:0.90 time:36.79sepoch:100 loss:0.29903 acc:0.90 time:37.66s
训练过程中,我们看到训练准确率从41%逐步提升到90%,说明模型在学习有效的特征。
📈 测试与优化
训练完成后,我们在测试集上评估模型,初始准确率为57%,说明模型有一定泛化能力,但仍有提升空间。
为了缓解过拟合,我们可以:
- 2. 增加网络宽度和深度(如通道数从6/16改为32/128)
class ImageClassification(nn.Module): def __init__(self): super(ImageClassification, self).__init__() self.conv1 = nn.Conv2d(3, 32, stride=1, kernel_size=3) self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) self.conv2 = nn.Conv2d(32, 128, stride=1, kernel_size=3) self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) self.linear1 = nn.Linear(128 * 6 * 6, 2048) self.linear2 = nn.Linear(2048, 2048) self.out = nn.Linear(2048, 10) # Dropout层,p表示神经元被丢弃的概率 self.dropout = nn.Dropout(p=0.5) def forward(self, x): x = torch.relu(self.conv1(x)) x = self.pool1(x) x = torch.relu(self.conv2(x)) x = self.pool2(x) # 由于最后一个批次可能不够 32,所以需要根据批次数量来 flatten x = x.reshape(x.size(0), -1) x = torch.relu(self.linear1(x)) # dropout正则化 # 训练集准确率远远高于测试准确率,模型产生了过拟合 x = self.dropout(x) x = torch.relu(self.linear2(x)) x = self.dropout(x) return self.out(x)
优化后,测试准确率提升至93%,效果显著!
总结
过这个案例,你可以学习到:
注意:训练过程发现CPU的训练耗时较长,可使用GPU提速。CNN并不神秘,从理论到实践,往往只需要一个清晰的案例。希望这个CIFAR-10分类项目能成为你进入计算机视觉领域的第一块敲门砖。