点击上方蓝字【聚大模型前言】关注我,热门AI资讯每天更新~~

【导读】Cursor 的自适应上下文发现机制,会将工具输出和历史记录以文件形式存储,让智能体可以通过 tail、grep 等命令按需获取关键信息,从而减少 token 消耗,并支持 Agent Skills 等新能力。。
随着代码 Agent 在软件开发中的角色不断升级,模型变强了,但上下文窗口并没有无限扩张。大量 shell 输出、工具返回、聊天历史、MCP 工具描述,被一次性塞进提示词,不仅消耗大量 token,还会引入噪声,甚至让 Agent 在关键信息上“失忆”。
Cursor 发现,当模型越来越擅长扮演 Agent 时,预先给得越少,反而越容易让它自主、准确地获取所需信息。于是,Cursor 将上下文工程的重心,从“塞什么进去”,转向了“如何让 Agent 自己找”。
Cursor 的动态上下文发现,完全围绕一个设计来展开:将所有可能膨胀上下文的内容,统一转化为文件,再赋予 Agent 按需读取的能力。这带来了两个直接好处:只在需要时加载信息,极大节省 token;减少上下文中的冗余与冲突,提高回复质量。
官方总结了五个关键落地场景:
1. 将超长工具响应写入文件,而不是截断
第三方工具(如 shell、MCP)经常返回体量巨大的 JSON 或日志输出。过去,常见做法是直接截断,结果往往是把最有价值的信息一并丢掉。Cursor 选择了另一条路:将完整输出写入文件,并允许 Agent 使用 tail、grep 逐步查看。
Agent 可以先检查末尾内容,再决定是否需要向前读取更多数据,从而在接近上下文上限时,避免无意义的总结和信息损失。
2. 摘要不是终点,对话历史仍可被“找回”
当上下文窗口被填满时,Cursor 会自动触发摘要,为 Agent 提供一个“新上下文”。但摘要本质上是有损压缩,关键细节很容易丢失。
为此,Cursor 将完整对话历史作为文件保留。 摘要完成后,Agent 会得到一个指向历史文件的引用,如果发现摘要不够用,它可以自行搜索历史记录,把遗漏的信息找回来。
3. Agent Skills:标准化能力,也支持动态发现
Cursor 支持 Agent Skills 这一开放标准,用文件来定义 Agent 在特定领域“该怎么做”。
这些 Skills 以文件形式存在,包含名称、描述,可被 grep、语义搜索等方式动态加载,甚至可以打包可执行脚本或程序。结果是:Agent 不需要一次性“记住所有技能”,而是像查资料一样按需引入能力。
4. MCP 工具只在真正需要时才加载
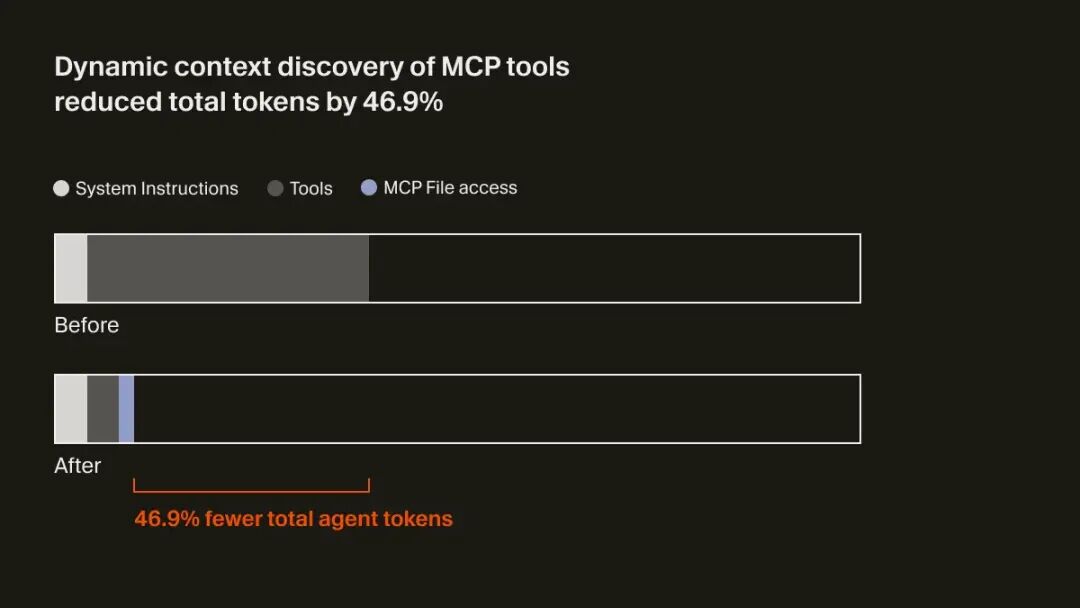
MCP 让 Agent 能访问 OAuth 保护的资源,如生产日志、内部文档等,但问题也很明显:工具多、描述长、但大多数根本不会用到。
Cursor 的做法是:将 MCP 工具描述同步到文件夹,提示词中只保留极少量静态信息,具体能力在任务需要时再动态查找。
在一次内部 A/B 测试中,这一策略在涉及 MCP 工具的 Agent 运行中,将总 token 消耗降低了 46.9% 。额外收益是,Agent 还能通过文件状态感知工具是否失效,并主动提醒用户重新认证。
5. 终端会话,本质上也是上下文文件
过去,用户需要手动复制粘贴终端输出给 Agent。现在,Cursor 会自动将集成终端的输出同步为本地文件。
用户可以直接问问题,Agent 则会自行在终端历史中 grep 相关输出。对于长时间运行的服务日志或服务器进程,这一点会非常实用。
为什么 Cursor 坚持选择「文件」?Cursor 表示:文件是否会成为 LLM 工具的最终接口形式,目前还不确定。但在 Agent 快速演进的阶段,文件是一种:简单、强健、可组合,而且不容易被未来推翻的抽象。相比设计一套复杂、但可能很快过时的新接口,文件是更安全的原语。
这套机制将在未来几周内向所有 Cursor 用户陆续上线。 而这,也释放出一个清晰信号:下一阶段代码 Agent 的竞争焦点,正在从模型能力,转向上下文工程与系统设计。
参考资料:https://cursor.com/cn/blog/dynamic-context-discovery

