前言
在上一篇,我们手握 NumPy 和 Pandas,觉得自己已经能处理全世界的数据了。
但当你试图用 NumPy 手写一个神经网络时,你会撞上两堵墙:
- 1. 算不动:矩阵一旦超过 10000 维,CPU 就开始发烫降频,NumPy 对此无能为力。
- 2. 算不准:还记得微积分里的“链式法则”吗?如果神经网络有 100 层,手推导数公式会让你崩溃。只要写错一个符号,整个模型就废了。
今天,我们请出 AI 界的“屠龙刀” —— PyTorch。
它由 Meta (Facebook) 开源,它做对了最关键的两件事:
- 1. 把张量搬到了 GPU 上(解决了“算不动”)。
- 2. 实现了自动微分系统 Autograd(解决了“算不准”)。
系好安全带,我们要开始真正的“硬核”编程了。
一、 Tensor (张量):觉醒了“原力”的 NumPy
PyTorch 的 Tensor 在语法上几乎和 NumPy 的 ndarray 一模一样。这不是巧合,而是为了降低迁移成本。但 Tensor 多了两个核心属性:device(设备)和 grad(梯度)。
1. 设备感知:CPU vs GPU
NumPy 只能在 CPU 上跑,而 Tensor 可以随意切换领地。
import torchimport numpy as npprint(f"PyTorch版本: {torch.__version__}")print(f"CUDA可用: {torch.cuda.is_available()}")print(f"CUDA版本: {torch.version.cuda}")print(f"可用设备数: {torch.cuda.device_count()}")print(f"当前设备: {torch.cuda.current_device()}")print(f"设备名称: {torch.cuda.get_device_name(0) if torch.cuda.device_count() > 0 else '无GPU'}")# 1. 创建 Tensor (和 NumPy 极其相似)x_np = np.array([1, 2, 3])x_pt = torch.tensor([1, 2, 3]) # 默认在 CPU# 2. 桥接 NumPy# 两者共享内存!修改一个,另一个也会变(如果在CPU上)y_pt = torch.from_numpy(x_np)# 3. --- 硬核时刻:搬运到 GPU ---if torch.cuda.is_available(): # 这行代码是深度学习加速 100 倍的关键 device = torch.device("cuda") x_cuda = x_pt.to(device) print(f"数据在: {x_cuda.device}") # 注意:GPU 上的张量不能直接和 NumPy 交互,必须先 .cpu() 搬回来 result = x_cuda.cpu().numpy() print(result)else: print("没有显卡,只能用 CPU 跑代码,惨。")# PyTorch版本: 2.9.1+cu126# CUDA可用: True# CUDA版本: 12.6# 可用设备数: 1# 当前设备: 0# 设备名称: NVIDIA GeForce RTX 3060# 数据在: cuda:0# [1 2 3]
干货 Tip:在写代码时,养成定义 device 的习惯,这是从脚本小子进阶到工程化的第一步。
2. 动态图机制 (Dynamic Computational Graph)
这是 PyTorch 战胜 TensorFlow 1.x 的杀手锏。
- • TensorFlow (旧版):先定义图(像画好电路板),再灌水(数据)。一旦出错,不知道是哪条线烧了。
- • PyTorch:边执行边建图。代码运行到哪,图就建到哪。你可以用 Python 的
if/else 随意控制网络结构。
二、 Autograd:自动微分的“黑魔法”
这是本篇最核心的干货。PyTorch 是如何知道怎么求导的?
当你创建一个 Tensor 并设置 requires_grad=True 时,PyTorch 就不再只把它看作一个数据,而是一个计算图的节点。
1. 追踪历史 (Tracking History)
PyTorch 会在后台启动一个“书记员”,记录你对这个张量做的每一次运算。
# 创建一个需要求导的张量 w (比如权重)w = torch.tensor(1.0, requires_grad=True)x = torch.tensor(2.0)# 定义运算y = w * x # 第一步:乘法z = y ** 2 # 第二步:平方# 此时,PyTorch 悄悄建立了一张图:# w -> [Mul] -> y -> [Pow] -> z
2. 反向传播 (Backward)
当你调用 z.backward() 时,PyTorch 会沿着刚才那张图反向跑一遍,利用链式法则自动计算出 z 对 w 的导数,并存入 w.grad 中。
z.backward()# 手推验证:# z = (wx)^2# dz/dw = 2(wx) * x = 2 * (1*2) * 2 = 8print(f"PyTorch 算的导数: {w.grad}") # 输出 8.0
干货 Tip:
- • Leaf Node (叶子节点):像
w 这种我们自己创建的变量,才有梯度。像 y 和 z 这种中间运算结果,梯度在反向传播后会被释放以节省内存。 - • grad_fn:你可以打印
z.grad_fn,会发现它叫 <PowBackward0>,这就是 PyTorch 记录的“运算历史”。
三、 实战:手写线性回归(从原理到框架)
为了让你彻底理解框架的封装艺术,我们用两种方式实现同一个线性回归任务:拟合 。
方式一:低阶实现(手动挡)
这种写法能让你看清 PyTorch 到底在干什么。
import torch# 1. 准备数据X = torch.rand(100, 1)y = 3 * X + 0.8 + 0.05 * torch.randn(100, 1) # 加点噪音# 2. 初始化参数 (随机猜)w = torch.randn(1, 1, requires_grad=True)b = torch.randn(1, 1, requires_grad=True)learning_rate = 0.1for epoch in range(1000): # --- Forward (前向传播) --- y_pred = X @ w + b # 矩阵乘法 # --- Loss (计算误差) --- loss = (y_pred - y).pow(2).mean() # MSE Loss # --- Backward (反向传播) --- # 这一步会自动把 dLoss/dw 和 dLoss/db 算出来,存进 w.grad 和 b.grad loss.backward() # --- Update (更新参数) --- # 核心干货:为什么要用 no_grad? # 因为更新参数 w = w - lr * grad 是一个计算操作。 # 如果不关掉梯度追踪,PyTorch 会以为这步操作也要算进计算图里,导致无限套娃和内存爆炸。 with torch.no_grad(): w -= learning_rate * w.grad b -= learning_rate * b.grad # 核心干货:为什么要 zero_grad? # PyTorch 的梯度默认是“累加”的(为了支持 RNN 等复杂网络)。 # 在下一轮迭代前,必须把上一轮的梯度清零! w.grad.zero_() b.grad.zero_() if epoch % 100 == 0: print(f"Epoch {epoch}: w={w.item():.2f}, b={b.item():.2f}")# Epoch 0: w=1.51, b=-1.53# Epoch 100: w=2.95, b=0.82# Epoch 200: w=2.99, b=0.80# Epoch 300: w=3.00, b=0.80# Epoch 400: w=3.00, b=0.80# Epoch 500: w=3.00, b=0.80# Epoch 600: w=3.00, b=0.80# Epoch 700: w=3.00, b=0.80# Epoch 800: w=3.00, b=0.80# Epoch 900: w=3.00, b=0.80
方式二:高阶实现(自动挡)
这才是 AI 工程师每天写的代码。 我们使用 torch.nn (Neural Network) 和 torch.optim (Optimizer)。
import torchimport torch.nn as nnimport torch.optim as optimimport matplotlib.pyplot as plt# ==================== 设置随机种子 ====================torch.manual_seed(42)# ==================== 创建训练数据 y = 3x + 0.8 ====================# 生成更多数据点n_samples = 100X = torch.randn(n_samples, 1) * 2 # 生成-2到2之间的随机数,增加数据范围true_w = 3.0true_b = 0.8noise = torch.randn(n_samples, 1) * 0.2 # 添加少量噪声y = true_w * X + true_b + noiseprint("=" * 60)print("数据生成信息:")print("=" * 60)print(f"样本数量: {n_samples}")print(f"真实关系: y = {true_w:.1f}x + {true_b:.1f}")print(f"X范围: [{X.min():.2f}, {X.max():.2f}]")print(f"y范围: [{y.min():.2f}, {y.max():.2f}]")print(f"添加噪声: 标准差 {noise.std():.3f}")# ==================== 检查 GPU 可用性 ====================device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"\n使用设备: {device}")# ==================== 可视化原始数据 ====================plt.figure(figsize=(12, 4))plt.subplot(1, 3, 1)plt.scatter(X.cpu().numpy(), y.cpu().numpy(), alpha=0.5, label='数据点')plt.plot(X.cpu().numpy(), (true_w * X + true_b).cpu().numpy(), 'r-', linewidth=3, label=f'真实: y={true_w}x+{true_b}')plt.xlabel('X')plt.ylabel('y')plt.title('原始数据 (y=3x+0.8)')plt.legend()plt.grid(True, alpha=0.3)# ==================== 1. 定义模型 ====================class LinearRegressionModel(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(1, 1) def forward(self, x): return self.linear(x)# 创建模型并移到设备model = LinearRegressionModel().to(device)print(f"\n模型初始参数:")print(f"初始权重: {model.linear.weight.item():.4f}")print(f"初始偏置: {model.linear.bias.item():.4f}")# ==================== 移动数据到设备 ====================X_gpu = X.to(device)y_gpu = y.to(device)# ==================== 2. 定义损失函数和优化器 ====================criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)# 添加学习率调度器(可选,让训练更稳定)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=200, gamma=0.9)# ==================== 3. 训练循环 ====================print("\n" + "=" * 60)print("开始训练...")print("=" * 60)losses = [] # 记录损失weights = [] # 记录权重变化biases = [] # 记录偏置变化for epoch in range(2000): # 训练步骤 optimizer.zero_grad() outputs = model(X_gpu) loss = criterion(outputs, y_gpu) loss.backward() optimizer.step() scheduler.step() # 更新学习率 # 记录 losses.append(loss.item()) weights.append(model.linear.weight.item()) biases.append(model.linear.bias.item()) # 打印进度 if (epoch + 1) % 200 == 0: current_lr = scheduler.get_last_lr()[0] print(f'Epoch [{epoch + 1:4d}/2000], Loss: {loss.item():.6f}, ' f'LR: {current_lr:.5f}, ' f'w: {model.linear.weight.item():.4f}, ' f'b: {model.linear.bias.item():.4f}')# ==================== 4. 查看训练结果 ====================print("\n" + "=" * 60)print("训练完成!")print("=" * 60)final_w = model.linear.weight.item()final_b = model.linear.bias.item()print(f"\n真实关系: y = {true_w:.4f}x + {true_b:.4f}")print(f"学习到的: y = {final_w:.4f}x + {final_b:.4f}")print(f"权重误差: {abs(final_w - true_w):.4f}")print(f"偏置误差: {abs(final_b - true_b):.4f}")# ==================== 5. 可视化训练过程 ====================plt.subplot(1, 3, 2)plt.plot(losses)plt.xlabel('Epoch')plt.ylabel('Loss (MSE)')plt.title('训练损失曲线')plt.grid(True, alpha=0.3)plt.yscale('log') # 对数坐标更清晰plt.subplot(1, 3, 3)plt.plot(weights, label='权重 w')plt.plot(biases, label='偏置 b')plt.axhline(y=true_w, color='r', linestyle='--', alpha=0.5, label='真实 w')plt.axhline(y=true_b, color='g', linestyle='--', alpha=0.5, label='真实 b')plt.xlabel('Epoch')plt.ylabel('参数值')plt.title('参数收敛过程')plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# ==================== 6. 最终拟合效果可视化 ====================plt.figure(figsize=(10, 6))plt.scatter(X.cpu().numpy(), y.cpu().numpy(), alpha=0.5, label='数据点')# 真实直线x_range = torch.linspace(X.min(), X.max(), 100).reshape(-1, 1)y_true = true_w * x_range + true_bplt.plot(x_range.numpy(), y_true.numpy(), 'r-', linewidth=3, label=f'真实: y={true_w:.2f}x+{true_b:.2f}')# 预测直线model.eval()with torch.no_grad(): x_range_gpu = x_range.to(device) y_pred = model(x_range_gpu).cpu()plt.plot(x_range.numpy(), y_pred.numpy(), 'b--', linewidth=3, label=f'拟合: y={final_w:.2f}x+{final_b:.2f}')plt.xlabel('X')plt.ylabel('y')plt.title(f'线性回归拟合结果 (y={true_w}x+{true_b})')plt.legend()plt.grid(True, alpha=0.3)plt.show()# ==================== 7. 详细参数分析 ====================print("\n" + "=" * 60)print("详细参数分析")print("=" * 60)# 查看模型的所有参数和梯度model.train() # 切回训练模式以查看梯度dummy_loss = criterion(model(X_gpu), y_gpu)dummy_loss.backward()for name, param in model.named_parameters(): print(f"\n{name}:") print(f" 数值: {param.data.cpu().numpy().flatten()}") print(f" 梯度: {param.grad.cpu().numpy().flatten() if param.grad is not None else 'None'}") print(f" 是否需要梯度: {param.requires_grad}")# ==================== 8. 测试预测 ====================print("\n" + "=" * 60)print("测试预测")print("=" * 60)test_X = torch.tensor([[0.5], [1.0], [1.5], [2.0], [2.5]]).to(device)model.eval()with torch.no_grad(): predictions = model(test_X) print(f"{'输入 x':>10} | {'预测 y':>10} | {'真实 y':>10} | {'误差':>10}") print("-" * 50) for i, x in enumerate(test_X.cpu()): pred = predictions[i].cpu().item() truth = true_w * x.item() + true_b error = abs(pred - truth) print(f"{x.item():10.2f} | {pred:10.4f} | {truth:10.4f} | {error:10.4f}")print("\n" + "=" * 60)print("模型训练完成!")print(f"最终损失: {losses[-1]:.6f}")print("=" * 60)============================================================# 数据生成信息:# ============================================================# 样本数量: 100# 真实关系: y = 3.0x + 0.8# X范围: [-4.41, 4.44]# y范围: [-12.35, 13.88]# # 添加噪声: 标准差 0.178# # 使用设备: cuda# # 模型初始参数:# 初始权重: 0.4801# 初始偏置: 0.8415# # ============================================================# 开始训练...# ============================================================# Epoch [ 200/2000], Loss: 0.031221, LR: 0.00900, w: 3.0011, b: 0.8096# Epoch [ 400/2000], Loss: 0.031214, LR: 0.00810, w: 3.0012, b: 0.8072# Epoch [ 600/2000], Loss: 0.031214, LR: 0.00729, w: 3.0012, b: 0.8071# Epoch [ 800/2000], Loss: 0.031214, LR: 0.00656, w: 3.0012, b: 0.8071# Epoch [1000/2000], Loss: 0.031214, LR: 0.00590, w: 3.0012, b: 0.8071# Epoch [1200/2000], Loss: 0.031214, LR: 0.00531, w: 3.0012, b: 0.8071# Epoch [1400/2000], Loss: 0.031214, LR: 0.00478, w: 3.0012, b: 0.8071# Epoch [1600/2000], Loss: 0.031214, LR: 0.00430, w: 3.0012, b: 0.8071# Epoch [1800/2000], Loss: 0.031214, LR: 0.00387, w: 3.0012, b: 0.8071# Epoch [2000/2000], Loss: 0.031214, LR: 0.00349, w: 3.0012, b: 0.8071# # ============================================================# 训练完成!# ============================================================# # 真实关系: y = 3.0000x + 0.8000# 学习到的: y = 3.0012x + 0.8071# 权重误差: 0.0012# 偏置误差: 0.0071# ============================================================# 详细参数分析# ============================================================# # linear.weight:# 数值: [3.0011792]# 梯度: [-2.7798116e-05]# 是否需要梯度: True# # linear.bias:# 数值: [0.8071371]# 梯度: [8.128583e-06]# 是否需要梯度: True# # ============================================================# 测试预测# ============================================================# 输入 x | 预测 y | 真实 y | 误差# --------------------------------------------------# 0.50 | 2.3077 | 2.3000 | 0.0077# 1.00 | 3.8083 | 3.8000 | 0.0083# 1.50 | 5.3089 | 5.3000 | 0.0089# 2.00 | 6.8095 | 6.8000 | 0.0095# 2.50 | 8.3101 | 8.3000 | 0.0101# # ============================================================# 模型训练完成!# 最终损失: 0.031214# ============================================================
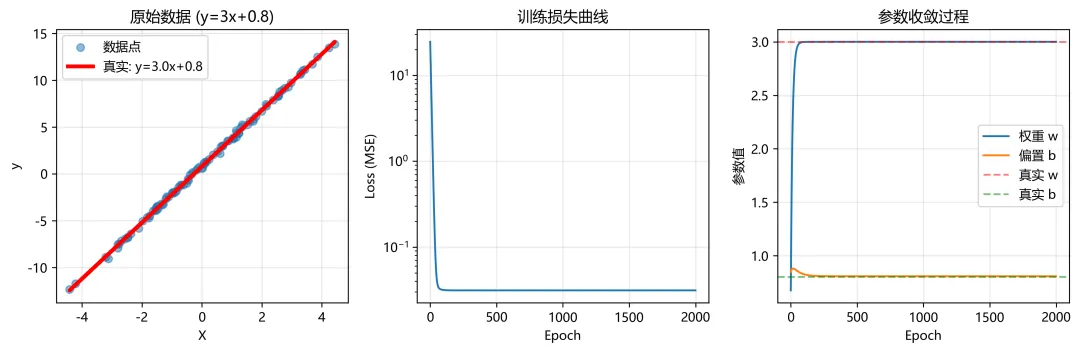 可视化训练过程
可视化训练过程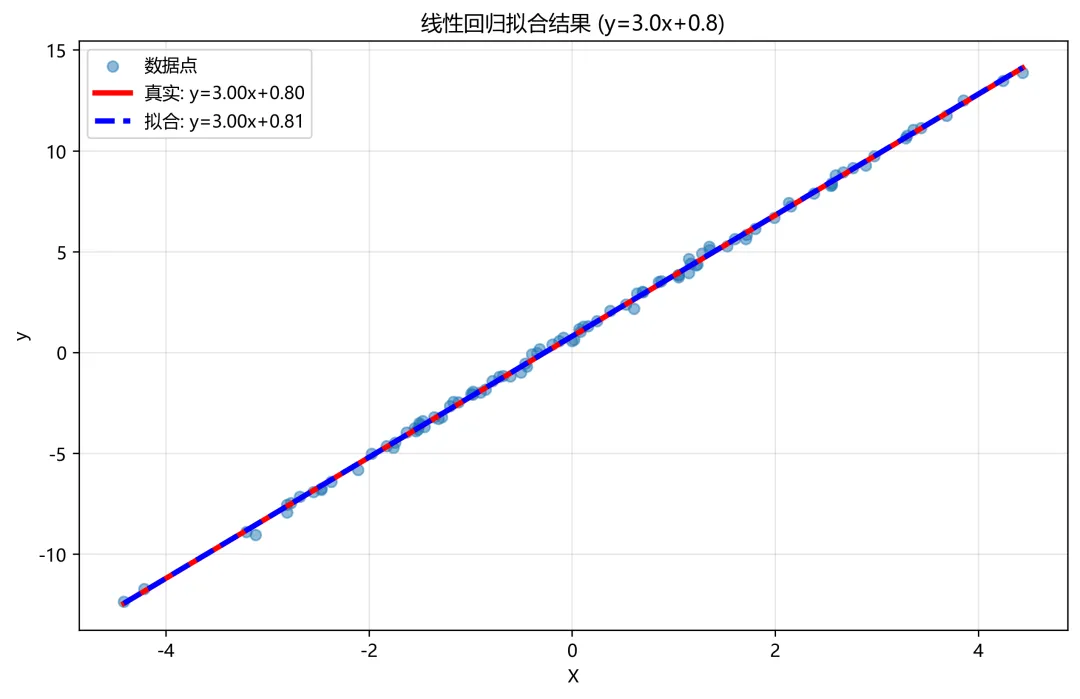 线性回归拟合结果
线性回归拟合结果
四、 核心总结:PyTorch 的“五步心法”
不管你将来写的是简单的线性回归,还是最新的 ChatGPT (Transformer) 架构,其训练核心代码永远只有这五步。请把这段代码刻在 DNA 里:
# 1. 梯度清零:打扫战场,准备下一轮optimizer.zero_grad()# 2. 前向传播:模型根据输入做出预测output = model(input)# 3. 计算损失:看看预测错得有多离谱loss = loss_fn(output, target)# 4. 反向传播:把责任(梯度)分摊给每个参数loss.backward()# 5. 优化更新:参数根据梯度修正自己optimizer.step()
五、 避坑与进阶建议
- 1. Shape Mismatch (维度地狱):
- • 90% 的 PyTorch 报错都是因为矩阵维度对不上。
- • 干货技巧:在
forward 函数里,多插几句 print(x.shape),调试时极其有用。不要瞎猜,要看形状。
- • 实际项目中,数据不是一次性塞进内存的(显存会爆)。
- • 你需要学习
torch.utils.data.DataLoader,它能帮你把数据切成小块(Batch),并在 GPU 训练的同时,利用 CPU 多进程预读取下一批数据。这是工业级训练的标配。
- • 如果你发现 Loss 不下降,或者变成
NaN,先检查学习率是不是太大了,再检查数据里有没有无穷大值,最后检查是不是忘了 optimizer.zero_grad()。
六、 结语:这才是 AI 的起点
恭喜你!学完这一篇,你才算真正拿到了进入 AI 殿堂的钥匙。
NumPy 让你理解了矩阵,Autograd 让你理解了学习,PyTorch 让你拥有了算力。
现在的你,已经具备了复现经典算法的能力。
下一阶段预告
我们将带着 PyTorch 这把屠龙刀,进入 【机器学习基础】。
我们不再手写 ,而是要去挑战经典的分类问题:逻辑回归、决策树、SVM。我们将看看 AI 是如何把花哨的数据分类得井井有条的。
作业:
尝试修改上面的“高阶实现”代码,把 nn.Linear(1, 1) 改成一个包含隐藏层的神经网络(比如 nn.Sequential(nn.Linear(1, 10), nn.ReLU(), nn.Linear(10, 1))),去拟合一个非线性函数(比如 )。体会一下深度学习的威力。

