注:文末有视频版
大家好,我是阿隆。
这节课带大家了解一下在AI世界里我们经常听到的一个词——大模型。
要想更好地驾驭AI工具,理解AI的能力边界,我们就必须理解好这个核心概念。
接下来我会用最通俗易懂的语言,配合生活中的例子,带你轻松理解它。
什么是大模型?
大模型的全称是大语言模型(LLM) 。
怎么理解呢?我们可以把这个名字拆成两部分来看:「大」和「语言」。
1)怎么理解「大」
我们把这个过程,理解为将一个孩子从幼儿园培养到博士毕业:
- 数据量大(知识广度)
大模型吃掉了几乎整个互联网的公开数据,包括文学、科学、代码等,所以它的认知才这么全面。
就像一个孩子想升博士,那他得读海量的书、论文,经历几十年的学习。
- 参数量大(脑容量)
参数就像模型大脑里的神经元,参数越多,模型就越聪明,能处理的事情也就越复杂。
类比这个孩子博士毕业时,大脑里其实已经形成了无数复杂的神经连接,能解决高难度问题了。
- 计算资源大(教育成本)
训练一个模型需要成千上万块昂贵的GPU运行好几个月,光是电费就是天文数字。
就像在整个教育过程中,家长要砸巨额资金给这孩子交学费、买日常生活用品、实验设备什么的。
2)怎么理解「语言」
这是大模型最厉害的地方:
它听得懂人话,也能说人话。
以前的AI也很牛,比如打败围棋冠军的AlphaGO,但它只会下棋,不会说人话。
而现在的语言模型,本质上是一个顶级程序员、作家和翻译官的合体。
它是AI产品背后的大脑
平时咱们用一些AI产品,比如DeepSeek、豆包的时候,你可能会觉得它们无所不能——
能写文章、写代码、画画、P图、语音聊天、生成视频……
其实,这些AI产品背后,就是一群具有特定能力的大模型。
 豆包的界面
豆包的界面
以豆包为例,它背后的大模型有:
- 豆包图片生成模型(Doubao-Seedream系列)
- 豆包视频生成模型(Doubao-Seedance系列)
所以,你要记住一句话:
我们平时对话的界面,它只是个壳子,真正干活的是背后这些被汗水(数据)喂出来的模型。
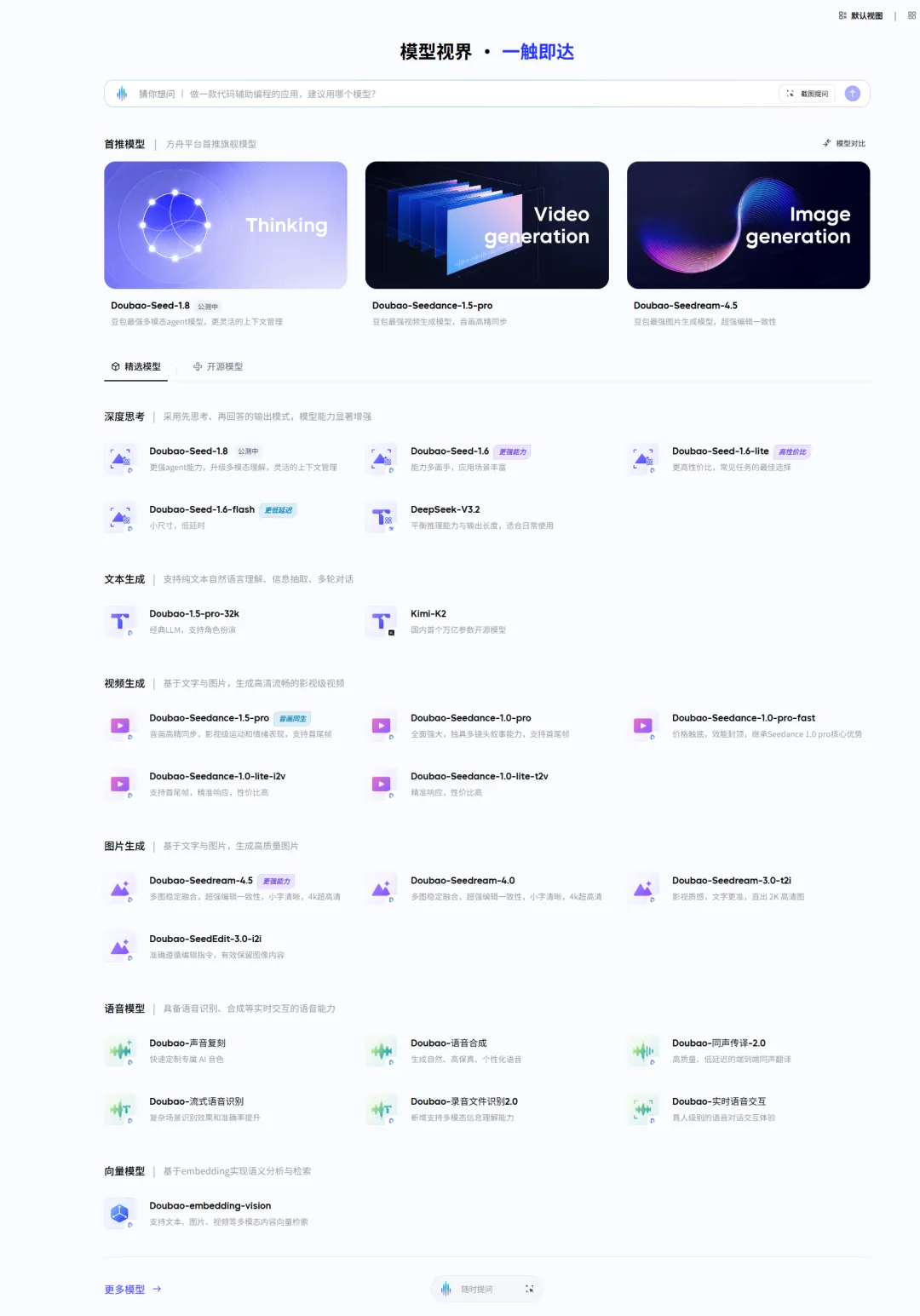 火山引擎控制台-模型广场
火山引擎控制台-模型广场
最后的话
就像开车不需要懂发动机原理一样,我们使用大模型也不必纠结底层代码。
弄清楚它能做什么、不能做什么(能力边界),远比弄懂它是怎么做到的更重要。
我是阿隆。2026 年目标——教会1000人用AI编程。工具让生活更美好,拒绝空谈,只教落地。

