一、机器学习介绍
机器学习,最简单的是二叉树模型(学过数理金融的人都知道,期权的二叉树模型(Binomial Tree Model)),其次是决策树模型(DecisionTree),然后是随机森林模型(Random Forests),后面是梯度提升树模型(Xgboost)等。难度一步步加强,深度一步步加深。
用大白话讲,就像是一颗小树苗,后面分裂的树枝越来越多,最后要去综合预测叶子的生长形态。后续就是比较预测的叶子形态与后面实际生长出来的叶子形态,差距越小越好。但是因为受环境、地区、生长气候、光照等各种因素影响,在后续得不断的去修剪树枝(优化、调整、迭代模型)。(若理解的不够形象或有误,敬请指正)
二、Python中机器学习库
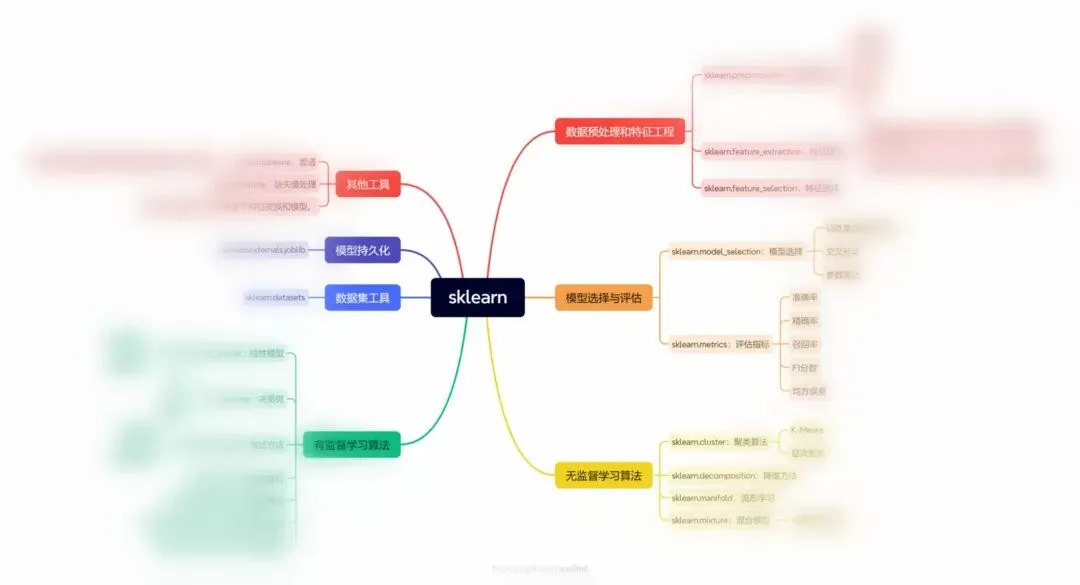
sklearn(scikit-learn)是一个功能丰富的机器学习库,包含多个模块,用于数据预处理、模型构建、模型评估等。
#数据预处理from sklearn.preprocessing import StandardScaler #标准化
#测试集、训练集划分from sklearn.model_selection import train_test_split
# 有监督学习模型from sklearn.linear_model import LinearRegression, LogisticRegression #导入线性回归、逻辑回归from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor #决策树分类和回归模型from sklearn.ensemble import RandomForestClassifier #随机森林from sklearn.neighbors import KNeighborsClassifier #KNN分类器from sklearn.naive_bayes import GaussianNB #高斯分布
#无监督学习from sklearn.cluster import KMeans #聚类算法
#评估指标 准确率 M-V 混淆矩阵from sklearn.metrics import accuracy_score, mean_squared_error, confusion_matrix
三、实战demo
1、数据准备
提供需要分析的数据,进行数据对齐、清洗,处理缺失值和异常值等(该步骤非常重要,是建模的基石。曾经看过底层数据非常混乱、逻辑不符的数据集,建模非常累且白搭)。Data scientists spend 80% of their time cleaning and preparing data。2、特征选择(降维)
在数据标签中提出Y标,其余的标签作为特征;若特征较多的话,需要对特征进行降维处理,去除噪声,提高模型效率。3、模型选择
选择合适的模型,区分特征是连续性变量还是离散型变量,选择合适的算法模块。4、模型拟合评估
用训练集训练的模型,来拟合测试集。评估模型预测能力的准确率、模型的稳定性等,压力测试等。5、后续维护和优化
模型条件发生实质性或重大变化,或数据集发生变化等,需要进行模型迭代。