1 月 9 日,硅谷科技媒体《The Information》传出了一则重磅消息:DeepSeek 预计将在 2 月中旬发布新一代模型 DeepSeek V4。据爆料,V4 将主打编程能力与**超长代码提示(Context)**的处理能力。内部测试更显示,其在代码相关任务上的表现,可能已经超越了 Anthropic 的 Claude 和 OpenAI 的 GPT 系列。
但比传闻更耐人寻味的,是 DeepSeek 最近的一个“反常”动作。
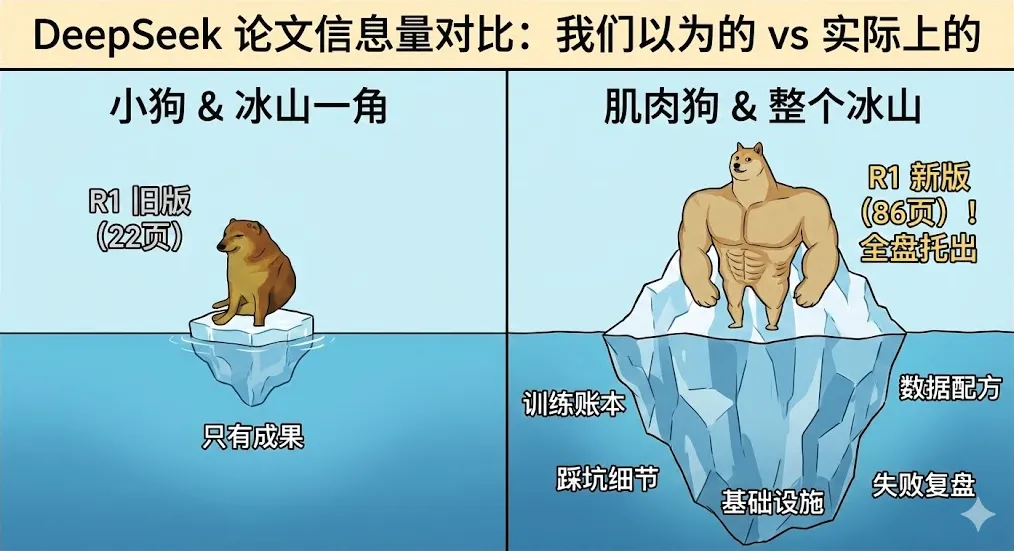
在此之前,他们悄然更新了去年发布的 R1 论文——从原本的 22 页直接扩充到了 86 页!
这不仅仅是加了几张图,而是相当于把训练的“账本”和踩过的“坑”一次性全部摊开。这种“先补齐上一代,再发布下一代”的节奏,很难不让人联想:这或许正是在为 V4 铺路。
社区越理解 R1 的底层技术,就越能看清即将到来的 V4 到底强在哪里。
这份 86 页的“加料版”论文,主要更新了以下核心干货:
💰 1. 训练成本彻底透明
总计消耗 147K GPU 小时。如果按 H800 租赁价 $2/小时计算,总成本约 29.4 万美元。R1-Zero 与 R1 两个阶段加起来,不到 12 天就完成了训练。
📊 2. 数据“配方”公开
使用了约 15 万条 RL 数据,覆盖数学、代码(算法竞赛 + 真实 Bug 修复)、STEM 选择题、逻辑题等。文中甚至给出了“冷启动”数据的生成与重写流程。
💣 3. 失败经验“直球”复盘
很少有厂商愿意细说自己“怎么失败的”。但 DeepSeek 详细记录了 Reward Hacking(奖励黑客)与 PRM/MCTS 尝试的不足。最终他们选择了更稳妥的规则式奖励(如代码跑测试),强调模型要抗“讨好奖励函数”的鲁棒性。
⚙️ 4. 基础设施全披露
从 vLLM 推理、MoE 专家并行,到 MTP 自推理加速、DualPipe 流水并行,再到显存/内存/磁盘的自动 Offload 策略。这是一份企业级的架构参考。
🛡️ 5. 安全评估加码
补充了整整 10 页的安全报告,公开了风险审查 Prompt 和企业风控搭建思路。
如果传闻属实,V4 大概率会在春节前后亮相。
但无论 V4 表现如何,这份 86 页的补充论文本身已是“真正的开放”:它不仅给了权重和效果,更给了可复现的训练细节与基建做法。
对于开发者与企业而言,这份文档的价值在于:你可以照着把系统搭起来,避开已被证实的坑,在验证与安全上少走弯路。
一句话总结:DeepSeek 这一波,不是砸钱,而是砸效率;不是只开源“成果”,而是开源了“过程”。
V4 值得期待,但 R1 的这次扩写,已经让业界更接近“能用、可复现”的标准。
看来这个春节,AI 圈的各位是很难“躺平”了,咱们随时保持关注!
🔗 更多工具与 Claude Code 工作流实践:cc.guapihub.net