很多新手在操作 Linux 时会遇到一个非常令人困惑的现象。想要批量删除所有的 txt 后缀文件,输入 rm *.txt,系统执行得非常顺利。但是,当想要用 grep 去搜索包含特定内容的文件时,输入同样的 *.txt,命令窗口什么都搜不到。这两个地方用的明明都是星号,看起来一模一样,为什么待遇差别这么大?
1. Linux 中的通配符与正则表达式
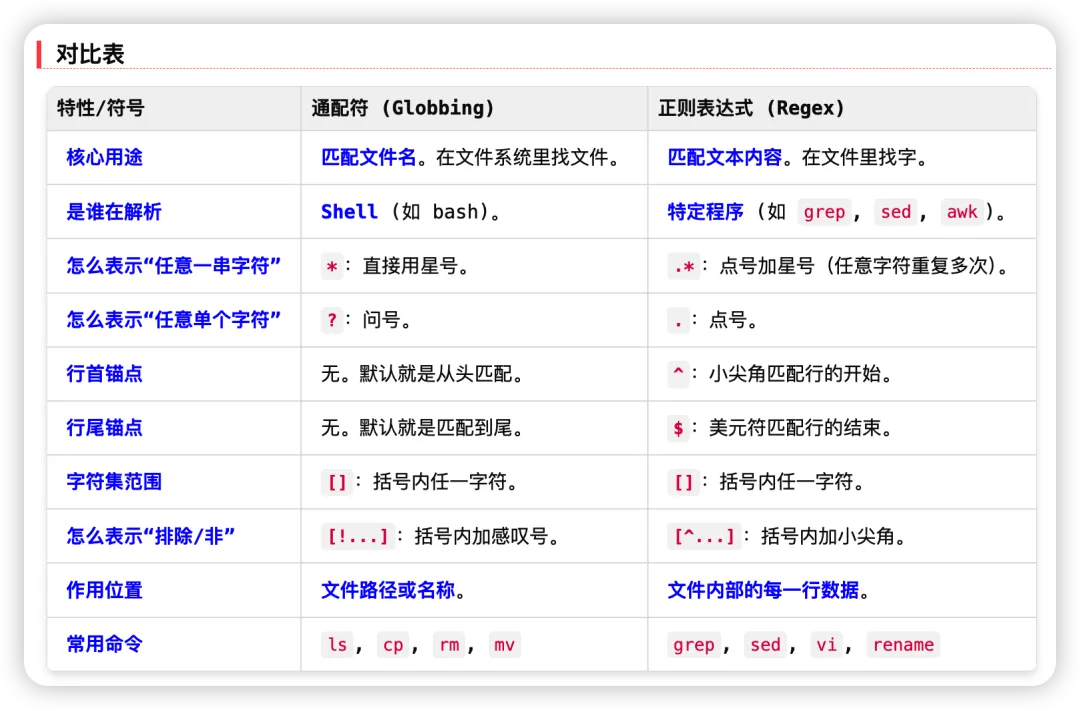
要解决上面那个问题,必须先明白 Linux 系统里其实有两套完全不同的规则。第一套叫做通配符,第二套叫做正则表达式。
简单来说,通配符是交给 Shell(也就是那个黑色的命令行窗口)去处理的,它的工作主要就是用来找文件,匹配文件名的。
而正则表达式是交给具体的软件工具(比如 grep、awk 或者编辑器)去处理的,它的工作是用来找文字,处理文件里面具体内容的。
分工不同,规则自然就不一样。
2. 通配符与正则表达式的使用场景
1. 使用通配符的场景
通配符的主战场就是 Shell 的文件名匹配。
这就好比在点名。当在命令行里输入一个带有通配符的命令时,Shell 这个“管家”非常勤快。它会在命令真正执行之前,先把这些通配符全部翻译成具体的文件名。
举个例子,输入 ls *.txt。Shell 看到 *.txt 后,会先去当前目录下找找有没有结尾是 .txt 的文件。如果找到了 a.txt 和 b.txt,Shell 就会把命令自动变成 ls a.txt b.txt,然后再交给 ls 命令去执行。ls 命令自己其实根本没看见那个星号,它看到的是已经被 Shell 替换好的完整文件名。
以下这些场景用的全是通配符:
文件管理命令
只要是涉及对文件本身进行操作的命令,基本都用通配符。ls:列出文件。想看所有以 file 开头的文件,就用 ls file*。rm:删除文件。想删光所有 txt,就用 rm *.txt。cp 和 mv:复制或移动文件。把所有符合样子的文件搬到另一个地方。touch:虽然一般用来新建文件,但如果配合通配符,也可以用来批量更新现有文件的时间戳。
Shell 脚本逻辑
for 循环:写脚本时经常需要轮询处理文件。
for tfile in *.txt; do ...
这里的 *.txt 会被 Shell 自动展开成一个文件列表,然后循环一个个处理。
文件搜索工具
find:这个命令有点特殊。它在 -name 参数里用的是通配符。但是,为了防止 Shell 这个“管家”太勤快,提前把星号给展开了,通常需要给参数加上引号。
find . -name 'music*'
加了引号,Shell 就不会乱动,而是把 music* 原封不动地传给 find 命令,让 find 自己去目录里慢慢比对文件名。
2. 使用正则表达式的场景
正则表达式完全是另一回事。它定义的是一套非常复杂的文本搜索、替换和过滤模式。它的眼睛盯着的是文件里面那一行行的字符数据,而不是文件外面的名字。
以下这些工具和场景,用的全是正则表达式:
文本搜索与处理工具
grep:这是最经典的正则工具,专门用来过滤包含特定内容的行。
grep '^K' tennis
这个命令的意思是,在 tennis 这个文件里,找出所有以 K 字符开头的行。这里的 ^ 就是正则符号,表示行首。
sed:流编辑器,用来做复杂的文本替换。
sed 's/Sun/Mon/'
把文本里的 Sun 换成 Mon,这里就在用正则匹配。
awk:强大的文本处理语言,提取数据时大量依赖正则。
编辑器
vi / vim:在编辑器里按 / 查找内容,或者用 :%s 替换内容时,输入的模式全都是正则表达式。
高级文件重命名
rename:在 Debian 等系统里,这个命令可以用正则表达式来改名。
rename 's/\.txt$/.TXT/' *
这比简单的 mv 强大得多,可以精细控制文件名里哪一部分要改,哪一部分保留。
Shell 历史记录操作
Bash History:这是个冷知识。可以用正则去搜索并替换历史命令里的打错的字。
!t:s/1/42/
特别注意:像 find 这种命令很狡猾,有些参数支持通配符,有些参数可能又支持正则。另外,在使用 grep 等正则工具时,强烈建议把写的模式用单引号包起来。为什么?因为如果不加引号,Shell 看到里面有星号或美元符号,可能会以为是通配符,自作主张给展开了,结果传给 grep 的东西就全乱套了。
3. 关键差异详解:为什么会搞混?
这里把最容易坑人的几个点详细拆开来讲。
星号 (*) 的本质区别
这是最大的误区。在通配符里,* 是个独挡一面的大佬。它自己就代表“任意长度的任意字符”。写下 file*,它就能匹配 file1、fileABC、file_long_name。在正则表达式里,* 只是个跟班,叫“量词”。它自己没有意义,必须跟在别人屁股后面,修饰前一个字符。它说的是:“前面那个家伙,可以出现零次,也可以出现无数次”。比如正则里的 a*,匹配的是空字符串、a、aa、aaa。如果想在正则里表达“任意字符”,必须由“点号”(代表任意一个字符)和“星号”(代表重复)配合,写成 .*。
匹配逻辑的不同
通配符匹配通常是“全匹配”。Shell 拿着模式去套文件名,必须从头到尾对得上才算数。正则表达式匹配通常是“包含匹配”。只要这一行里有任何一部分符合模式,grep 就认为匹配成功,把这行字显示出来。所以正则才需要 ^(行首)和 $(行尾)这种符号来把位置卡死。
符号的含义不同
通配符里的 ? 代表“必须要有一个字符”。正则表达式里的 . 代表“除换行符外的任意一个字符”。正则表达式里用 ^ 表示行首,$ 表示行尾。通配符里压根没这东西,因为它默认就是匹配整个名字。
排除字符的写法不同
通配符里要排除某些字符,用 [!...],里面是感叹号。正则表达式里要排除某些字符,用 [^...],里面是脱字符(小尖角)。
对比表
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
