LMCacheEngine 核心引擎代码分析
本文档深入剖析 LMCache 的核心调度中枢 LMCacheEngine——该组件不仅统筹 KV Cache 的存储、检索全生命周期管理,还支撑层级流水线并行推理的 I/O-计算协同,同时实现与 vLLM 等计算引擎的无缝交互、缓存钉住(Pin)/压缩等进阶能力,并联动存储后端完成跨节点缓存迁移与资源释放。
相关文章:
LMCache 架构概览
LMCache 分层存储架构与调度机制详解
1. 引擎概览
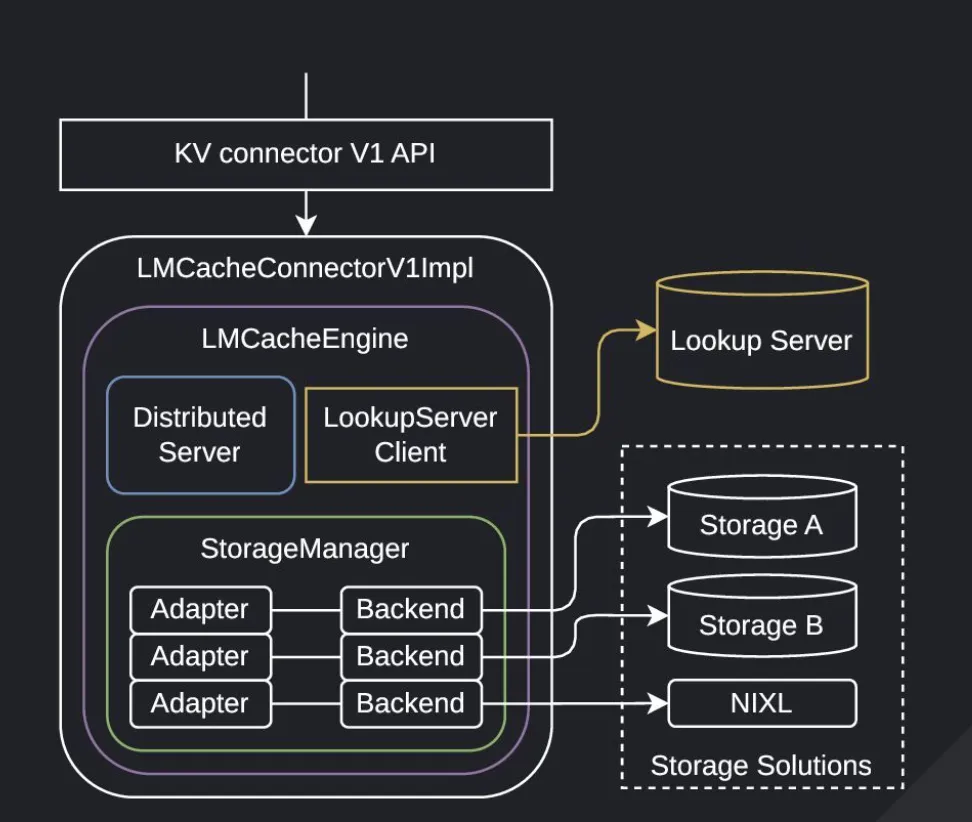
LMCacheEngine 位于 lmcache/v1/cache_engine.py,它是整个系统的控制中枢,集成了多个关键组件以实现高效的 KV Cache 管理。
1.1 核心组件
- • 核心组件协调:连接
StorageManager(多级存储后端)、GPUConnector(Host-Device 数据传输)和 TokenDatabase(Token-Key 映射索引)。 - • 异步事件管理:通过
EventManager 追踪和管理异步 I/O 任务的状态,支持非阻塞的查询与预取 (Async Lookup & Prefetch)。 - • 缓存操作接口:提供
store(存储)、retrieve(检索)和 lookup(查询)等标准 API,屏蔽底层存储细节。 - • 流水线优化:支持
store_layer 和 retrieve_layer 接口,实现层级流水线(Layerwise Pipelining),允许计算与 I/O 重叠。 - • 分布式协同:在 MLA (Multi-Head Latent Attention) 等场景下,支持通过广播机制在 Rank 间同步 KV Cache。
- • 可观测性:集成
LMCStatsMonitor,实时采集缓存命中率、存储延迟等关键性能指标。
1.2 核心概念:层级流水线 (Layerwise Pipelining)
层级流水线是 LMCache 的核心优化机制之一,专为 vLLM 等逐层推理引擎设计。它通过将 I/O 操作(加载/存储)与 GPU 计算并行化,显著降低了 KV Cache 的访问延迟。
- • 计算与 I/O 重叠:在 GPU 计算第 层时,后台并行加载第 层的数据(或持久化第 层的数据)。
- • 同位置约束:为了保证流水线的连续性和稳定性,当前实现要求同一 Key 的所有层级数据必须存储在同一个后端位置(例如都在 Local Disk 或都在 Remote),不支持跨后端碎片化存储。
2. 实例创建与管理
LMCache 使用 LMCacheEngineBuilder 类来管理 LMCacheEngine 的生命周期,采用单例模式确保每个 instance_id 对应唯一的引擎实例。其核心方法 get_or_create 实现了以下逻辑:
- 1. 单例检查:首先检查
_instances 中是否存在指定 instance_id 的实例。 - 2. 组件初始化:如果不存在,则初始化
NUMADetector、TokenDatabase 和 LMCStatsMonitor 等组件。 - 3. Engine 实例化:创建并注册
LMCacheEngine 实例。 - 4. 配置校验:如果实例已存在,校验其配置和元数据是否与当前请求一致,防止配置冲突。
# lmcache/v1/cache_engine.pyclass LMCacheEngineBuilder: _instances: Dict[str, LMCacheEngine] = {} @classmethod def get_or_create(cls, instance_id, config, metadata, ...) -> LMCacheEngine: # 1. 检查是否存在 if instance_id not in cls._instances: # 2. 组件初始化 numa_mapping = NUMADetector.get_numa_mapping(config) token_database = cls._Create_token_database(config, metadata) stat_logger = LMCacheStatsLogger(metadata, log_interval=10) # 3. 创建 Engine engine = LMCacheEngine(config, metadata, token_database, ...) # 4. 注册实例 cls._instances[instance_id] = engine cls._cfgs[instance_id] = config cls._metadatas[instance_id] = metadata cls._stat_loggers[instance_id] = stat_logger return engine else: # 5. 已存在则校验配置 if ( cls._cfgs[instance_id] != config or cls._metadatas[instance_id] != metadata ): raise ValueError("Instance already exists with a different configuration or metadata.") return cls._instances[instance_id]
3. 初始化流程
LMCacheEngine 的初始化过程分为两个阶段:__init__(构造函数)和 post_init(延迟初始化)。
3.1 构造函数
构造函数主要负责初始化内部核心组件,确立组件间的引用关系:
- • StorageManager: 负责底层存储后端的管理(如 Local CPU, Disk, Remote)。
- • LMCacheWorker: 如果启用 Controller,初始化 Worker 线程负责与 Controller 通信。
- • LMCStatsMonitor: 初始化统计监控单例。
# lmcache/v1/cache_engine.pyclass LMCacheEngine: def __init__(self, config, metadata, token_database, ...): self.config = config self.metadata = metadata self.token_database = token_database # 初始化存储管理器 self.storage_manager = LMCacheStorageManager(config, metadata, ...) # 初始化后台 Worker (若启用) if self.enable_controller: self.lmcache_worker = LMCacheWorker(config, metadata, self) # 初始化统计监控 self.stats_monitor = LMCStatsMonitor.GetOrCreate()
3.2 延迟初始化
post_init 方法用于处理那些依赖于外部上下文(如 GPU 环境完全就绪)的初始化任务。例如,GPU 显存指针的初始化通常需要等待 CUDA 上下文建立。
def post_init(self, **kwargs) -> None: if not self.post_inited: # 级联调用 StorageManager 的 post_init if self.storage_manager is not None: self.storage_manager.post_init(**kwargs) # 初始化 GPU 连接器的显存指针 if self.gpu_connector is not None: self.gpu_connector.initialize_kvcaches_ptr(**kwargs) self.post_inited = True
4. 核心操作:Retrieve (检索)
retrieve 方法负责将 KV Cache 从存储后端加载回 GPU。这一过程首先通过 StorageManager 将数据从后端(如磁盘或远程服务器)加载到 CPU 内存,随后利用 GPUConnector 组件高效地将数据批量传输至 GPU 显存中。
4.1 接口定义
def retrieve( self, tokens: Union[torch.Tensor, list[int]], mask: Optional[torch.Tensor] = None, **kwargs,) -> torch.Tensor:
4.2 完整检索流程
retrieve 的执行流程主要分为三个阶段:确定数据来源(异步预取或同步查找)、处理多卡数据同步(如 MLA 广播),以及执行最终的 Host-to-Device 数据传输。
- • 异步路径: 当启用
async_loading 时,引擎直接从 EventManager 获取预取任务的结果。这通常与 async_lookup_and_prefetch 配合,允许在计算的同时后台加载数据,掩盖 I/O 延迟。 - • 同步路径: 若未启用异步模式,则调用
_process_tokens_internal 执行标准层级查找。该过程依次扫描 L1 (Local CPU)、L2 (Local Disk/P2P) 和 L3 (Remote Backend),直到找到所需数据。
- • 在 MLA 场景下(配置
save_only_first_rank),为减少存储开销,仅 Rank 0 负责实际的数据检索。检索完成后,Rank 0 通过 NCCL 将 MemoryObj 广播给其他被动 Rank。
- • 调用
gpu_connector.batched_to_gpu 将 CPU 端的 MemoryObj 数据批量传输到 GPU 显存。此步骤经过优化,能高效处理并发拷贝请求。
# lmcache/v1/cache_engine.pydef retrieve(self, tokens, mask, **kwargs) -> torch.Tensor: # 初始化返回掩码 ret_mask = torch.zeros(len(tokens), dtype=torch.int32, device=self.device) # 1. 获取内存对象 (MemoryObj) if self.async_loading: # 从预取事件中获取 reordered_chunks, tot_kv_size = self._async_process_tokens_internal(...) else: # 执行层级查找 reordered_chunks, tot_kv_size = self._process_tokens_internal(...) # 2. MLA 广播 (Rank 0 -> Other Ranks) if self.save_only_first_rank: with torch.cuda.stream(self.broadcast_stream): self._broadcast_or_receive_memory_objs(reordered_chunks, ret_mask) # 3. 数据传输 (Host -> Device) if len(reordered_chunks) > 0: _, memory_objs, starts, ends = zip(*reordered_chunks) self.gpu_connector.batched_to_gpu( list(memory_objs), list(starts), list(ends), **kwargs ) # 返回检索掩码 (指示哪些 Token 已就绪) return ret_mask
4.3 层级流水线检索
retrieve_layer 实现了上文提到的 层级流水线 机制。
同位置约束:如前所述,该接口强制要求同一 Key 的所有层级数据必须存储在同一个后端位置。代码中通过 location 变量来校验这一约束。
核心流程:
- 1. 构建 I/O 生产者: 调用
storage_manager.layerwise_batched_get 初始化一个生成器,负责按层级顺序从后端读取数据。 - 2. 启动 H2D 消费者: 启动
gpu_connector.batched_to_gpu 协程,它作为消费者等待接收 CPU 端的 MemoryObj 并将其拷贝至 GPU。 - • 触发 I/O: 在每一层迭代开始时,获取当前层的数据加载任务(Task)。
- • 并行计算: 通过
yield 将控制权交还给计算引擎,使其能利用 I/O 等待时间执行上一层的计算。 - • 完成加载: 计算间隙控制权返回后,等待 I/O 任务完成,并将数据发送给 H2D 消费者送入显存。
def retrieve_layer(self, tokens, mask, **kwargs): # 初始化返回掩码 ret_mask = torch.zeros(len(tokens), dtype=torch.int32, device=self.device) # ... (Token 处理与 location 校验) ... # 1. I/O 生成器 (Producer) # 这里的 keys_layer_major 已经按层组织 get_generator = self.storage_manager.layerwise_batched_get( keys_layer_major, location=location, ) # 2. H2D 消费者 (Consumer) mem_obj_consumer = self.gpu_connector.batched_to_gpu(starts, ends, **kwargs) next(mem_obj_consumer) # 启动协程 # 3. 流水线执行 for layer_id in range(self.num_layers): # 触发当前层 I/O 获取 task = next(get_generator) # Yield 给计算引擎 (执行上一层的计算) # 第一层需要返回 retrieved_tokens 数量,后续层返回 None if layer_id == 0: yield torch.sum(ret_mask) else: yield None # 获取 I/O 结果并送入 H2D 队列 mem_objs_layer = task.result() mem_obj_consumer.send(mem_objs_layer)
4.4 分离式推理支持 (PD Support)
在 Prefill-Decode 分离 (Disaggregated Prefill) 架构中,LMCache 被用于在 Prefill 实例(Sender)和 Decode 实例(Receiver)之间传输 KV Cache。
为了优化 Decode 节点的内存使用,LMCache 提供了 remove_after_retrieve 机制。当 Decode 节点(配置为 pd_role="receiver")成功检索数据并加载到 GPU 后,会自动从本地 CPU 缓存中移除这些数据 (MemoryObj),避免重复占用资源。这一行为在初始化时由配置项 enable_pd 自动决定。
5. 核心操作:Store (存储)
store 操作负责将 KV Cache 从 GPU 显存持久化到存储后端。为了适应不同的推理场景,LMCache 提供了两种模式:全量存储 (store) 和流水线存储 (store_layer)。
5.1 冻结模式
为了保护高频访问的“热点缓存”不被驱逐或覆盖,LMCache 引入了冻结模式。当 is_frozen() 返回 True 时,所有的存储操作都会被直接跳过。这通常用于在系统预热阶段加载了关键数据后,锁定缓存状态。
5.2 全量存储
store 方法执行一次性阻塞式的存储操作。它适用于推理结束后的统一保存,或者非流式生成的场景。
执行流程:
- 1. 预检查:检查当前节点角色(是否为被动接收节点)以及是否处于冻结模式。
- 2. Token 处理与索引构建:遍历
TokenDatabase,将 Token 序列切分为 Chunk,并计算每个 Chunk 的 Hash Key。 - 3. 内存分配:调用
storage_manager.allocate 为所有待存储的 Chunk 分配 CPU 内存 (MemoryObj)。 - 4. 数据下回 (GPU -> CPU):调用
gpu_connector.batched_from_gpu 将 KV Cache 从 GPU 显存批量拷贝到 CPU 内存。 - 5. 持久化 (CPU -> Backend):调用
storage_manager.batched_put 将数据写入存储后端。
关键代码:
# lmcache/v1/cache_engine.pydef store(self, tokens, mask, **kwargs): # 1. 预检查 if self._is_passive(): return if self.is_frozen(): return # 2. 准备:计算 Hash 并分配内存 for start, end, key in self.token_database.process_tokens(...): memory_obj = self.storage_manager.allocate(...) memory_objs.append(memory_obj) keys.append(key) # 3. 传输:GPU -> CPU self.gpu_connector.batched_from_gpu(memory_objs, starts, ends, **kwargs) # 4. 存储:CPU -> Backend self.storage_manager.batched_put(keys, memory_objs, ...)
5.3 层级流水线存储
store_layer 专为 vLLM 等逐层推理引擎设计,通过生成器 (Generator) 机制实现计算与存储的流水线并行。它在计算第 i+1 层时,异步处理第 i 层的数据传输和第 i-1 层的持久化。
执行流程:
- 1. 全局分配:在流水线启动前,预先计算所有层的 Hash Key,并一次性分配所有层所需的 CPU 内存。这是为了避免在流水线执行中频繁申请内存造成抖动。
- • 启动 GPU 连接器,准备接收第 0 层数据。
- • 进入生成器循环,通过
yield 将控制权交还给推理引擎。
- • Yield 返回:当推理引擎完成第
i 层的计算并再次调用 next() 时,LMCache 恢复执行。 - • 异步传输:触发
gpu_connector 将刚计算完成的第 i+1 层数据从 GPU 拷贝到 CPU。 - • 持久化:将上一轮已经拷贝到 CPU 的第
i 层数据 (keys[layer_id]) 提交给 storage_manager 写入后端。
这种设计确保了 I/O 操作(特别是耗时的磁盘/网络写入)被计算密集型的 GPU 推理过程所掩盖。
关键代码:
# lmcache/v1/cache_engine.pydef store_layer(self, tokens, ...): # 1. 预分配所有层的内存 for start, end, key in self.token_database.process_tokens(...): memory_objs_multi_layer = self.storage_manager.batched_allocate(..., batch_size=self.num_layers) memory_objs.append(memory_objs_multi_layer) # ... 收集 keys ... # 2. 启动 GPU 传输生成器 mem_obj_generator = self.gpu_connector.batched_from_gpu(memory_objs, ...) # 启动第 0 层传输 next(mem_obj_generator) # 3. 流水线循环 for layer_id in range(self.num_layers): # 让出控制权,等待引擎完成当前层计算 yield # 恢复后: # 1. 继续驱动 GPU 传输 (准备下一层) next(mem_obj_generator) # 2. 将当前层 (layer_id) 数据写入后端 self.storage_manager.batched_put(keys[layer_id], memory_objs[layer_id])
6. 核心操作:Lookup (查询)
lookup 操作用于快速检测给定的 Token 序列是否已存在于缓存中。这一步通常发生在推理请求的早期(如 Schedule 阶段),用于决定是否可以利用缓存进行加速。
6.1 同步查询
lookup 方法通过 TokenDatabase 将 Token 序列映射为 Hash Key,并查询存储后端是否存在对应的数据块。
执行流程:
- 1. 预处理:根据
num_computed_tokens 跳过已计算的 Token 前缀。 - 2. Token 映射:遍历
TokenDatabase,将剩余 Token 转换为 Hash Key 序列。 - 3. 存在性检查:调用
storage_manager.batched_contains 检查 Key 是否存在。 - • 普通模式:批量检查所有 Key,返回连续命中的 Chunk 数量。
- • 流水线模式 (
use_layerwise=True):逐个 Chunk 检查,要求该 Chunk 的所有层必须存在于同一个存储后端位置才算命中。
- 4. 缓存锁定 (Pin):如果
pin=True: - • 将命中的缓存块映射记录到
self.lookup_pins[lookup_id]。 - • 方法结束前调用
touch_cache() 刷新缓存活跃状态(防止 LRU 淘汰)。
- 5. 返回结果:返回命中的总 Token 数量(包含已计算部分)。
提示:关于层级流水线机制的详细背景,请参阅 1.2 核心概念:层级流水线。这里的“同位置一致性”检查正是为了满足该机制对数据连续性的要求。
关键代码:
# lmcache/v1/cache_engine.pydef lookup(self, tokens, search_range=None, lookup_id=None, pin=False, ...): # 1. 预处理与 Token -> Key 转换 chunk_info_iterator = self.token_database.process_tokens(...) # 2. 存在性检查 (分两种模式) if self.use_layerwise: # 模式 A: 流水线模式 (逐个 Chunk 检查层级完整性) for start, end, key in chunk_info_iterator: key_all_layers = key.split_layers(self.num_layers) hit_chunks, block_mapping = self.storage_manager.batched_contains( key_all_layers, search_range, pin ) # 要求: 所有层命中且在同一位置 if hit_chunks == self.num_layers and len(block_mapping) == 1: if pin: # 记录 Pin 信息 location = next(iter(block_mapping.keys())) self.lookup_pins[lookup_id][location].extend(key_all_layers) res = end continue return res else: # 模式 B: 普通模式 (批量检查) hit_chunks, block_mapping = self.storage_manager.batched_contains( keys, search_range, pin ) if pin and block_mapping: assert lookup_id is not None self.lookup_pins[lookup_id] = block_mapping # 3. 刷新缓存状态 if pin: self.storage_manager.touch_cache() return res
6.2 异步查询与预取
为了最大程度利用调度阶段的空闲时间,async_lookup_and_prefetch 提供了一种“非阻塞查询 + 后台预加载”的机制。它不仅返回缓存命中情况,还会在后台默默地将数据从慢速存储介质(如远程节点、磁盘)加载到本地 CPU 内存中。
核心机制:
- 1. 预加载 (Pre-loading):当调度器发起查询时,如果发现数据在远程或磁盘,LMCache 会立即启动 I/O 任务将其拉取到本地内存 (
MemoryObj)。 - 2. 无缝衔接:当推理引擎随后调用
retrieve 时,所需数据极有可能已经就绪在内存中,从而将 I/O 延迟从关键路径上移除。 - 3. 资源管理:预取操作会占用内存资源。如果请求被中止或最终未被调度,必须调用
cleanup_memory_objs 来释放这些预先分配的内存对象。
执行流程:
- 1. 任务封装与提交:将查询和预取请求封装为协程,提交给
StorageManager 的事件循环。 - 2. 事件注册:任务状态被注册到全局
EventManager,与 lookup_id 绑定。 - 3. 清理机制:如果预取任务完成但数据未被使用(例如请求取消),调度器需显式触发清理。
关键代码:
# lmcache/v1/cache_engine.pydef async_lookup_and_prefetch(self, lookup_id, tokens, ...): # ... Token 处理 ... # 提交异步任务:查询 + 数据预加载 asyncio.run_coroutine_threadsafe( self.storage_manager.async_lookup_and_prefetch( lookup_id, keys, ... ), self.storage_manager.loop, )def cleanup_memory_objs(self, lookup_id): # 清理因预取而占用但未被使用的内存资源 if self.event_manager.get_event_status(..., lookup_id) == EventStatus.DONE: future = self.event_manager.pop_event(..., lookup_id) memory_objs = future.result() for obj in memory_objs: obj.ref_count_down() # 释放内存引用
7. 高级功能
除了基础的存储和检索操作外,LMCacheEngine 还提供了一系列高级功能,旨在支持更复杂的分布式推理场景。这些功能包括跨节点的数据迁移、节省存储空间的压缩机制,以及灵活的缓存生命周期管理。
7.1 跨节点移动
move 接口支持将 KV Cache 从一个节点(或存储后端)迁移到另一个节点。这在集群负载均衡或 P2P 共享场景中尤为关键。该操作底层依赖于 StorageManager 中的网络后端(如 P2PBackend)来实现高效的数据传输。
执行流程:
- 1. 查找与锁定:根据输入的 Token 序列在源位置 (
old_position) 查找并锁定对应的缓存块,防止在传输期间被淘汰。 - 2. 数据获取:从源位置的存储后端批量读取 KV Cache 数据 (
MemoryObj)。 - 3. 异步传输:通过网络后端将数据发送到目标位置 (
new_position)。 - 4. 源清理 (可选):如果
do_copy=False,则在传输成功后从源位置删除数据,完成“移动”语义;否则仅做“复制”。
关键代码:
# lmcache/v1/cache_engine.pydef move(self, tokens, old_position, new_position, event_id, do_copy=True): # 1. 查找数据并锁定 self.lookup(..., search_range=[old_position], pin=True) # 2. 获取源数据对象 keys = self.lookup_pins[event_id][old_position] memory_objs = self.storage_manager.batched_get(keys=keys, location=old_position) # 3. 异步发送到目标位置 # (假设后端支持 put_task) p2p_backend = self.storage_manager.storage_backends["P2PBackend"] future = asyncio.run_coroutine_threadsafe( p2p_backend.async_batched_submit_put_task(keys, memory_objs, ...), self.storage_manager.loop, ) future.result() # 4. (可选) 清理源数据 if not do_copy: self.storage_manager.batched_remove(keys, locations=[old_position])
7.2 压缩与解压
LMCache 支持对已存储的 KV Cache 进行原位压缩和解压,以节省存储空间或减少网络传输带宽。目前集成了 CacheGen 等压缩算法。
Compress 流程:
- 1. 初始化序列化器:根据指定的算法(如 "cachegen")创建对应的序列化器。
- 2. 获取原始数据:从指定位置读取原始的
MemoryObj。 - 3. 序列化 (压缩):调用
serializer.serialize() 将数据转换为压缩格式。 - 4. 原位替换:先删除旧数据,再写入压缩后的新数据,保持 Key 不变。
关键代码:
# lmcache/v1/cache_engine.pydef compress(self, tokens, method, location, event_id): # ... 创建 serializer ... # 1. 获取并序列化 memory_objs = self.storage_manager.batched_get(keys=keys, location=location) compressed_objs = [serializer.serialize(m) for m in memory_objs] # 2. 原位替换 (Remove + Put) self.storage_manager.batched_remove(keys, locations=[location]) self.storage_manager.batched_put(keys, compressed_objs, location=location)
Decompress 流程:与压缩类似,通过 deserializer.deserialize() 将压缩数据还原,并覆盖原有存储。
7.3 缓存清理
clear 接口提供了灵活的缓存清除机制,支持按 Token 范围清理或指定后端全量清理。
清理模式:
- 1. 全量清理:若未指定
tokens,则直接调用 storage_manager.clear(locations) 清空指定后端的所有数据。 - 2. 按 Token 清理:若指定了
tokens,则通过 TokenDatabase 计算出对应的 Hash Key,仅移除这些特定的缓存块。
此外,在 MLA (Multi-Head Latent Attention) 架构下,为了避免多节点重复操作,只有 Rank 0 节点(is_first_rank)有权限执行清理。
关键代码:
# lmcache/v1/cache_engine.pydef clear(self, tokens=None, locations=None, ...): # 权限检查:MLA 模式下仅 Rank 0 执行 if self.save_only_first_rank and not self.metadata.is_first_rank(): return 0 return self._clear(tokens, locations, ...)def _clear(self, tokens, locations, ...): # 模式 1: 全量清理 if tokens is None or len(tokens) == 0: return self.storage_manager.clear(locations) # 模式 2: 按 Token 精确清理 for start, end, key in self.token_database.process_tokens(tokens, ...): self.storage_manager.remove(key, locations)
8. 生命周期管理
LMCacheEngine 的生命周期管理主要涉及两个方法:close 和 destroy。
8.1 Close
close 方法负责优雅地关闭引擎实例,释放其持有的资源。这是一个实例方法,通常在引擎不再使用时调用。
执行流程:
- 1. 关闭后台 Worker: 如果初始化了
LMCacheWorker(用于 Controller 通信),调用其 close() 方法断开连接。 - 2. 关闭存储管理器: 调用
StorageManager.close(),级联关闭所有活跃的存储后端(停止线程池、断开网络连接等)。 - 3. 异常处理: 每个关闭步骤都包裹在 try-except 块中,确保部分组件关闭失败不会阻塞整体清理。
关键代码如下:
# lmcache/v1/cache_engine.pydef close(self) -> None: """Close the cache engine and free all the resources""" # 1. 关闭后台 Worker if self.lmcache_worker is not None: try: self.lmcache_worker.close() except Exception as e: logger.error(f"Error closing lmcache_worker: {e}") # 2. 关闭存储管理器 try: if self.storage_manager is not None: self.storage_manager.close() except Exception as e: logger.error(f"Error closing storage_manager: {e}")
8.2 Destroy
LMCacheEngineBuilder.destroy 是一个类方法,用于根据 instance_id 彻底销毁一个引擎实例及其所有相关联的全局状态。这通常在系统重置或完全退出时调用。
执行流程:
- 1. 关闭统计: 停止
LMCacheStatsLogger 的数据收集。 - 2. 关闭引擎: 获取实例并调用其
close() 方法。 - 3. 清理注册表: 从
LMCacheEngineBuilder 的类属性(_instances, _cfgs 等)中移除该实例。 - 4. 销毁监控器: 清理全局唯一的
LMCStatsMonitor 单例。
关键代码如下:
# lmcache/v1/cache_engine.py@classmethoddef destroy(cls, instance_id: str) -> None: """Close and delete the LMCacheEngine instance by the instance ID""" if instance_id in cls._instances: # 1. 关闭统计 Logger stat_logger = cls._stat_loggers[instance_id] stat_logger.shutdown() # 2. 关闭引擎 engine = cls._instances[instance_id] engine.close() # 3. 清理全局注册表 cls._instances.pop(instance_id, None) cls._cfgs.pop(instance_id, None) cls._metadatas.pop(instance_id, None) cls._stat_loggers.pop(instance_id, None) # 4. 销毁全局监控器 LMCStatsMonitor.DestroyInstance()
9. 监控与统计
LMCache 内置了完善的可观测性(Observability)系统,基于 Prometheus 标准提供多维度的性能指标监控。这对于生产环境中的性能调优、故障排查和资源规划至关重要。
9.1 核心组件
监控系统主要由以下两个组件构成:
- • LMCStatsMonitor:核心监控单例,负责实时采集各类指标(Counter, Gauge, Histogram)。它支持多进程模式(Multi-process Mode),能够正确汇总 vLLM 等多进程架构下的指标数据。
- • LMCacheStatsLogger:一个后台线程,负责定期(默认 10 秒)将聚合后的统计信息输出到日志中,便于快速查看系统运行状态。
9.2 关键指标体系
LMCache 暴露了丰富的指标,主要包括以下几类:
- 1. 请求与吞吐 (Requests & Throughput):
- •
lmcache:num_retrieve_requests / lmcache:num_store_requests:检索和存储请求的总数。 - •
lmcache:num_requested_tokens / lmcache:num_stored_tokens:处理的 Token 总量,用于计算吞吐量。
- •
lmcache:retrieve_hit_rate:KV Cache 检索命中率,直接反映了缓存对推理性能的提升效果。 - •
lmcache:lookup_hit_rate:前缀匹配查找的命中率。
- 3. 存储与资源 (Storage & Resources):
- •
lmcache:local_cache_usage:本地 CPU 内存缓存的使用量。 - •
lmcache:remote_cache_usage:远程存储(如 Redis/Disk)的使用量。
- 4. 延迟与性能 (Latency & Performance):
- •
lmcache:remote_time_to_get / lmcache:remote_time_to_put:远程存储后端的读写延迟分布。 - •
lmcache:p2p_transfer_latency:P2P 传输延迟。
9.3 集成方式
在 vLLM 集成场景下,LMCache 的指标通常通过 vLLM 的 /metrics 接口统一暴露。用户只需配置 Prometheus 抓取该端口,即可通过 Grafana 等工具进行可视化展示。
代码引用:
# lmcache/v1/cache_engine.pyclass LMCacheEngine: def __init__(self, ...): # 初始化统计监控单例 self.stats_monitor = LMCStatsMonitor.GetOrCreate() # ... def store(self, ...): # 记录存储请求 req_id = self.stats_monitor.on_store_request(num_tokens) try: # ... 执行存储 ... finally: # 记录完成状态 self.stats_monitor.on_store_finished(req_id, num_tokens)
9.4 事件追踪 (Event Tracing)
除了聚合指标外,LMCache 还支持详细的事件追踪机制。通过配置 enable_kv_events=True,引擎会记录关键操作(如存储)的详细元数据,包括耗时、涉及的 Key 和数据大小等。这些事件以 CacheStoreEvent 对象的形式存储,可用于细粒度的性能分析。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
