AI * Python * Excel搞定复杂规则分列,按业务规则个性化分列
- 2026-06-25 15:40:46
AI * Python * Excel搞定复杂规则分列,按业务规则个性化分列
我是小李。Excel 的“分列”功能像一把小刀:切水果很好用,但你拿它去做外科手术,肯定不行。 办公室里最常见的数据灾难之一就是:本来应该分成多列的信息,被系统/人工塞进了一列。 更要命的是:它还不统一——分隔符全靠录入人心情: “张 三” “张,三” “张-三” “张,三” 甚至“张三”(没有任何分隔符) Excel 的“数据分列”功能有两个死穴: 分隔符必须统一:你要么全是逗号,要么全是空格。如果你的数据里一会儿是逗号,一会儿是破折号,Excel 就会当场罢工。 规则太死板:它不懂正则表达式,也做不到“前 4 位是年,中间跳过 1 位,取后 2 位是月”这种灵活切分。 遇到这种不规则分隔符 + 批量文件,Excel 直接缴械。 小李是公司行政人事,经常要处理从老系统导出的员工信息表。数据简直是灾难现场: 姓名列:有的写 张三,Zhang(逗号),有的写 李四-Li(破折号),有的写 王五 Wang(空格)。录入全看心情。 日期列:全是文本2023.05.12 或者 2023-05-12,想提取年月日,Excel 分列还得来回切格式。 小李试过 Excel 的分列向导,结果是:选了逗号,破折号的没分对;选了破折号,空格的又乱了。最后只能手动复制粘贴,几千条数据搞到眼瞎 正则拆分(split):专门对付“分隔符不统一”。你可以告诉 Python:“逗号、空格、破折号、分号,只要出现其中任何一个,都给我切开!” 切片拆分(slice):专门对付“固定位置”。比如身份证号、日期串、固定编码,按位置提取(如取前 4 位)比按字符分隔更稳。 代码:自定义规则引擎(正则分列 + 切片分列) 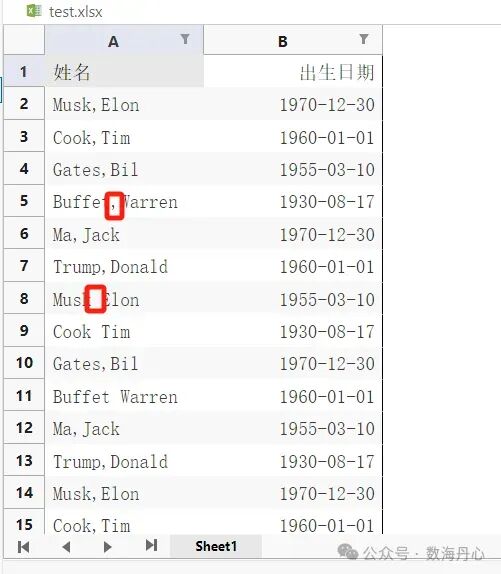
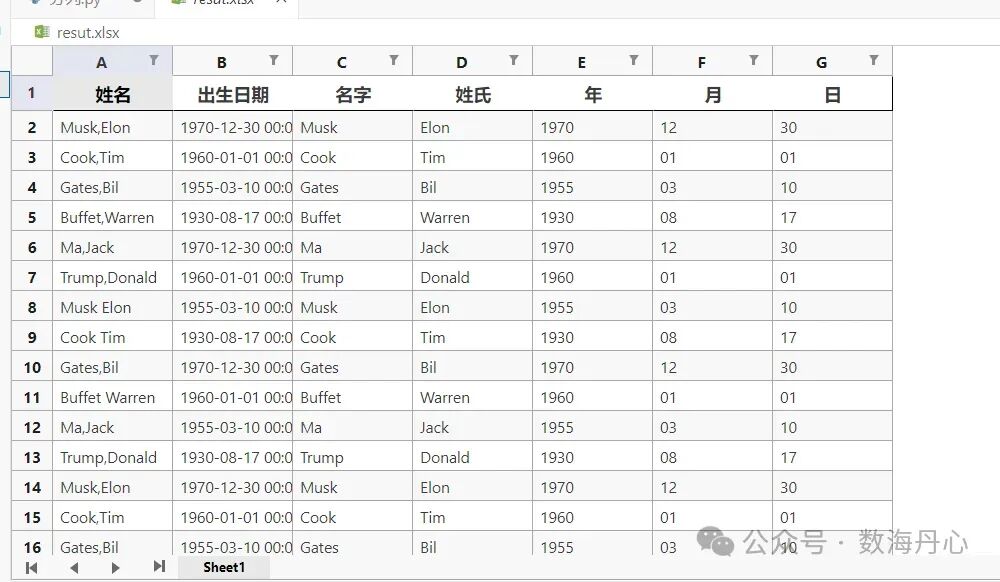
姓名列:无论你是用 ,-空格 还是 ; 分隔的,统统被正则 r'[ ,-;;]+' 识别,整整齐齐拆成了两列。 日期列:1990-05-20 被精准切出了 1990、05、20。 这在 Excel 里至少要用 3 步操作(查找替换统一分隔符 -> 分列 -> 提取函数),Python 代码里就是一行配置。
日期列的陷阱:pd.read_excel 默认很聪明,会把长得像日期的自动转成 datetime 类型。一旦转成了时间对象,你再用 .str[0:4] 去切片就会报错。解决:读取时加上 dtype=str,强制让它保持原本的“文本模样”,方便我们切。 正则分隔符:sep 里的正则表达式 [] 是“字符集合”的意思。比如 [,;] 意思是逗号或分号。如果你要拆分的符号本身是正则特殊字符(如 .*?),记得前面加反斜杠 \ 转义,或者放在 [] 里通常也安全(点号在[]里只是点号)。 切片越界:如果某一行数据特别短(比如只有 1990),你硬要切 [8:10],Python 不会报错,而是给你一个空字符串。这点比 Excel 公式好,Excel 可能会报#VALUE!。
别被“分列”这个词限制了想象力。在 Python 里,所谓的“分列”其实就是字符串处理。 只要你能描述出那个“分隔符”长什么样(正则); 或者你能指出“它在第几个字”(切片); Python 就能帮你把混成一团的烂泥,梳理成井井有条的表格。以后再看到乱七八糟的导出数据,先别急着骂系统,打开 Python 脚本,配置一下规则,两秒钟解决战斗。 
Excel 分列只能“按分隔符/固定宽度”,而你需要的是“按业务规则”
办公场景:行政人事的数据噩梦
核心说明(办公必看)
🤖 我给 AI 的指令
“读取 Excel 文件。针对不同列定义不同的拆分规则:
'姓名'列:分隔符可能是逗号、空格或破折号(用正则 [ ,-]+),拆分成 '中文名' 和 '英文名'。
'出生日期'列:按字符位置切片,前4位是年,第6-7位是月,第9-10位是日。将处理后的数据保存为新 Excel。”
import pandas as pdimport redef advanced_split_columns(df: pd.DataFrame, rules: dict) -> pd.DataFrame:"""高级分列函数:支持正则分隔和位置切片"""df = df.copy()for col_name, rule in rules.items():if col_name not in df.columns:print(f"⚠️ 警告:列 '{col_name}' 不存在,跳过。")continue# 1. 正则分隔模式 (type='regex_split')if rule['type'] == 'regex_split':# expand=True 将分割结果扩展为多列# rule['sep'] 可以是正则表达式,如 r'[ ,-]+' 表示逗号空格或横杠new_cols = df[col_name].astype(str).str.split(rule['sep'], expand=True)# 如果分割出来的列数多于定义的列名,截取前面的;如果少于,自动补None# 办公场景通常只关心前几列limit = len(rule['new_columns'])if new_cols.shape[1] > limit:new_cols = new_cols.iloc[:, :limit]# 赋值新列名new_cols.columns = rule['new_columns']# 将新列拼接到原表df = pd.concat([df, new_cols], axis=1)# 2. 位置切片模式 (type='slice')# 适用于固定格式字符串,如 "2023-12-01" 或 身份证号elif rule['type'] == 'slice':for target_col, (start, end) in rule['slices'].items():# .str[start:end] 类似Python切片df[target_col] = df[col_name].astype(str).str[start:end]return dfif __name__ == "__main__":# 模拟读取数据(办公时换成 pd.read_excel('原表.xlsx'))# 这里手动造点脏数据演示data = {'姓名': ['张三,Zhang', '李四-Li', '王五 Wang', '赵六;Zhao'],'出生日期': ['1990-05-20', '1992.12.01', '1988/08/08', '19950101']# 注意:切片法对格式要求严格,如果格式太乱建议也用正则提取}df = pd.read_excel('test.xlsx', dtype=str) # 读取时建议全转str,防止日期变成datetime对象导致切片失效# --- 核心:在这里配置你的规则 ---my_rules = {'姓名': {'type': 'regex_split','sep': r'[ ,-;;]+', # 正则:匹配 逗号/空格/横杠/中文分号/英文分号 任意一次或多次'new_columns': ['中文名', '英文名']},'出生日期': {'type': 'slice',# 字典格式:'新列名': (起始下标, 结束下标)'slices': {'年': (0, 4),'月': (5, 7),'日': (8, 10)}}}# 执行清洗df_result = advanced_split_columns(df, my_rules)# 导出df_result.to_excel('分列结果.xlsx', index=False)print("✅ 处理完成!已生成:分列结果.xlsx")print(df_result.head())
运行结果解释
【小李的避坑笔记】
小李的总结
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- WRF模式学习:Linux编译排错、FNL/ERA5驱动场处理、长时序模拟配置、下垫面改造与物理参数调整、Python诊断分析可视化
- 熬夜整理的Python爬虫笔记,新手照做就能爬
- 100行Python代码,带你优雅地搭建神经网络
- Linux Cassandra集群升级:滚动升级与零停机实践
- Python学习【85】:巧用python的flask编写程序详解cookie 与 tocken 以及session
- 新手用2核2G云服务器学Linux,该装Debian、Ubuntu还是Alma?
- 让Linux之父都“破戒”的AI编程,到底有多邪门?
- Python十连冠封神!IEEE 2025榜单出来啦
- 5. Linux系统 RR(Record and Replay)工具重现Linux系统崩溃的调用栈
- Python 15个超实用的Python项目GitHub仓库,值得收藏
