大家好,我是python222_锋哥,最近更新 PyTorch2 Python深度学习视频教程系列课程,感谢大家支持。
B站连载更新地址:
https://www.bilibili.com/video/BV1eqxNzXEYc/
基于前面的机器学习Scikit-learn,深度学习Tensorflow2课程,我们继续讲解深度学习PyTorch2,所以有些机器学习,深度学习基本概念就不再重复讲解,大家务必学习好前面两个课程。本课程主要讲解基于PyTorch2的深度学习核心知识,主要讲解包括PyTorch2框架入门知识,环境搭建,张量,自动微分,数据加载与预处理,模型训练与优化,以及卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN),模型保存与加载等。
生成对抗网络(GAN)简介
GAN简介
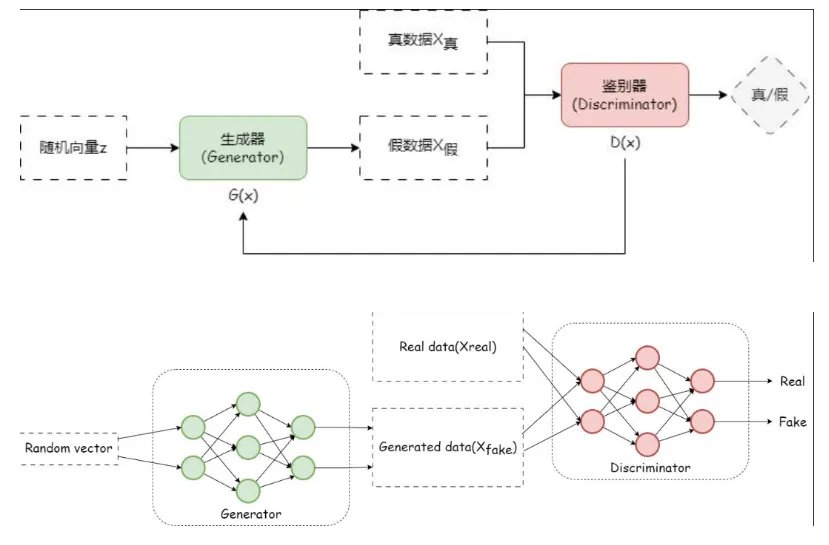
生成对抗网络是一种无监督深度学习模型,其核心思想是通过让两个神经网络相互“竞争”或“对抗”来学习。这两个网络分别是:
生成器: 它的目标是学习真实数据的分布,并生成足以“以假乱真”的虚假数据。它接收一个随机噪声向量作为输入,输出一个伪造的数据样本。
判别器: 它的目标是成为一个“鉴定专家”,能够正确区分输入的数据是来自真实数据集还是生成器生成的假数据。它接收一个数据样本,输出一个标量,表示该样本为真的概率。
对抗过程可以类比为:
GAN在多个领域具有广泛的应用,特别是在生成式任务中,如:
GAN基本架构图
GAN损失函数的定义
生成对抗网络(GAN)示例
我们以生成手写数字数据集为示例:
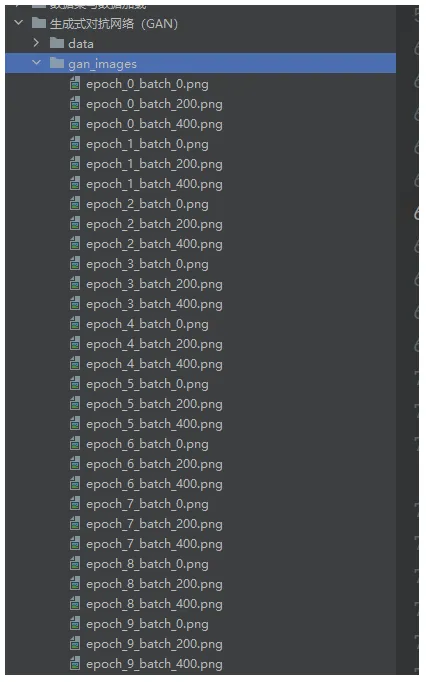
importtorchimporttorch.nnasnnimporttorch.optimasoptimimporttorchvisionimporttorchvision.transformsastransformsfromtorch.utils.dataimportDataLoaderimportos# 创建保存图像的文件夹os.makedirs("gan_images", exist_ok=True)os.makedirs("models", exist_ok=True)# 超参数设置batch_size = 128latent_dim = 100# 噪声向量维度hidden_dim = 256image_dim = 28*28# MNIST图像尺寸num_epochs = 100learning_rate = 0.0002sample_interval = 200# 每隔多少批次保存一次样本# 数据预处理transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,)) # 将像素值从[0,1]归一化到[-1,1]])# 加载MNIST数据集[citation:2][citation:3]train_dataset = torchvision.datasets.MNIST(root='./data',train=True,transform=transform,download=True)train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)# 定义生成器[citation:2][citation:5]classGenerator(nn.Module):def__init__(self, latent_dim, hidden_dim, output_dim):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(latent_dim, hidden_dim),nn.ReLU(inplace=True), # inplace=True参数表示直接在原tensor上进行修改,不创建新的tensor,可以节省内存空间nn.Linear(hidden_dim, hidden_dim*2),nn.ReLU(inplace=True),nn.Linear(hidden_dim*2, hidden_dim*4),nn.ReLU(inplace=True),nn.Linear(hidden_dim*4, output_dim),nn.Tanh() # 输出范围[-1, 1],与预处理匹配 )# 生成器类的前向传播函数。功能是接收随机噪声z作为输入,通过内部模型生成图像数据,并将输出重塑为28x28的单通道图像格式。defforward(self, z):img = self.model(z)""" 将输入的图像张量重新调整形状为(batch_size, 1, 28, 28)的格式。具体来说: img.size(0)保持批次大小不变 将图像转换为单通道(1) 调整图像尺寸为28×28像素 使用view()方法进行张量重塑,不改变数据内容只改变维度排列 """img = img.view(img.size(0), 1, 28, 28)returnimg# 定义判别器[citation:2][citation:5]classDiscriminator(nn.Module):def__init__(self, input_dim, hidden_dim):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim, hidden_dim*4),nn.LeakyReLU(0.2, inplace=True), # 0.2 是负轴部分的斜率系数,当输入为负值时,输出为输入值乘以0.2nn.Dropout(0.3),nn.Linear(hidden_dim*4, hidden_dim*2),nn.LeakyReLU(0.2, inplace=True),nn.Dropout(0.3),nn.Linear(hidden_dim*2, hidden_dim),nn.LeakyReLU(0.2, inplace=True),nn.Dropout(0.3),nn.Linear(hidden_dim, 1),nn.Sigmoid() # 输出0-1的概率值 )defforward(self, img):""" 这段代码的功能是将输入的图像数据进行展平操作。 具体来说: img.view() 是PyTorch中的张量重塑方法 img.size(0) 获取批次大小(batch size) -1 表示自动计算该维度的大小,将图像的所有像素展平成一维向量 结果是将形状为 [batch_size, channels, height, width] 的图像张量转换为 [batch_size, channels×height×width] 的二维张量 这样做的目的是将多维的图像数据转换为全连接层可以处理的一维向量格式。 """flattened = img.view(img.size(0), -1)validity = self.model(flattened)returnvalidity# 初始化模型generator = Generator(latent_dim, hidden_dim, image_dim)discriminator = Discriminator(image_dim, hidden_dim)# 定义损失函数和优化器[citation:2][citation:3]"""这段代码创建了一个Adam优化器用于训练生成器。功能解释:optim.Adam() - 创建Adam优化算法实例generator.parameters() - 获取生成器模型的所有可训练参数lr=learning_rate - 设置学习率为指定值betas=(0.5, 0.999) - 设置Adam算法的两个动量参数,分别控制一阶和二阶矩估计的指数衰减率该优化器将用于更新生成器的权重参数以最小化损失函数。"""adversarial_loss = nn.BCELoss()optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))# 用于可视化的固定噪声fixed_noise = torch.randn(64, latent_dim)# 训练统计d_losses = []g_losses = []print("开始训练GAN...")# 训练循环[citation:2][citation:3][citation:5]forepochinrange(num_epochs):fori, (real_imgs, _) inenumerate(train_loader):batch_size = real_imgs.size(0)# 创建标签real_labels = torch.ones(batch_size, 1)fake_labels = torch.zeros(batch_size, 1)# ---------------------# 训练判别器# ---------------------optimizer_D.zero_grad()# 计算真实图像的损失real_output = discriminator(real_imgs) # 判别器对真实图像进行预测d_loss_real = adversarial_loss(real_output, real_labels) # 计算真实图像的损失# 生成假图像z = torch.randn(batch_size, latent_dim) # 生成随机噪声向量fake_imgs = generator(z) # 生成假图像# 计算假图像的损失fake_output = discriminator(fake_imgs.detach()) # 判别器对生成的假图像进行预测d_loss_fake = adversarial_loss(fake_output, fake_labels) # 计算假图像的损失# 总判别器损失d_loss = (d_loss_real+d_loss_fake) /2# 计算判别器的损失d_loss.backward() # 反向传播optimizer_D.step() # 更新判别器的权重参数# ---------------------# 训练生成器# ---------------------optimizer_G.zero_grad() # 清空生成器的梯度# 生成器希望假图像被判别为真output = discriminator(fake_imgs) # 判别器对生成的假图像进行预测g_loss = adversarial_loss(output, real_labels) # 计算生成器的损失g_loss.backward() # 反向传播optimizer_G.step() # 更新生成器的权重参数# 记录损失d_losses.append(d_loss.item()) # 记录判别器的损失g_losses.append(g_loss.item()) # 记录生成器的损失# 定期保存生成的图像[citation:3]ifi%sample_interval == 0:print(f"[Epoch {epoch}/{num_epochs}] [Batch {i}/{len(train_loader)}] "f"[D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]")# 保存生成图像示例withtorch.no_grad(): # 禁用梯度计算fake_imgs_sample = generator(fixed_noise).detach().cpu() # 生成假图像# 保存为图像网格torchvision.utils.save_image(fake_imgs_sample,f"gan_images/epoch_{epoch}_batch_{i}.png",nrow=8,normalize=True )运行代码后,相对目录下生成图片:
我们打开前面的,比较差。
打开后面的一些,就很不错了。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
