你有没有遇到过这种情况:手里捏着好几个模型,跑出了几十个指标,Excel 表格拉得老长,结果导师看了一眼说:“这数据太多了,我看不过来,画张图吧。”
于是你打开 Python,画了 10 张柱状图,贴到论文里,审稿人又说:“版面太浪费,信息密度低。”
这时候,你需要的就是一张“高维数据浓缩矩阵”。
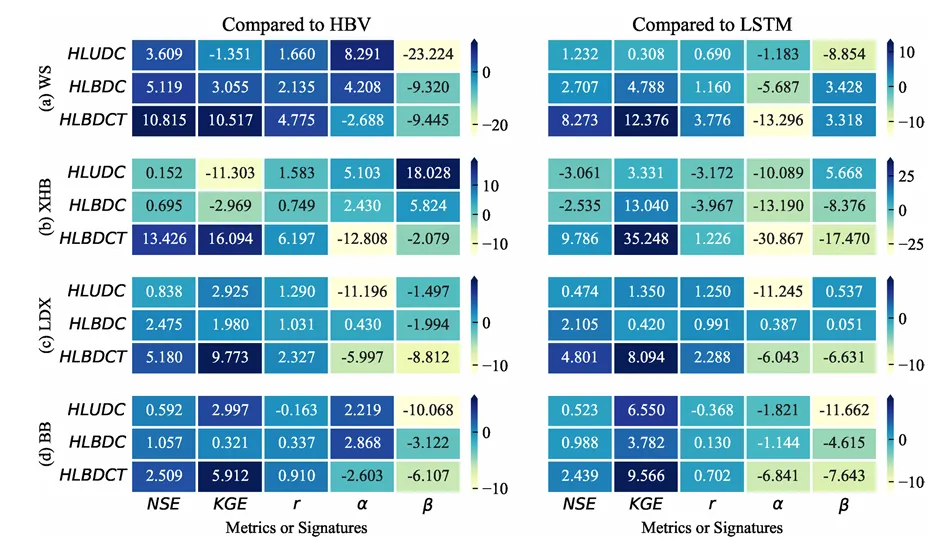
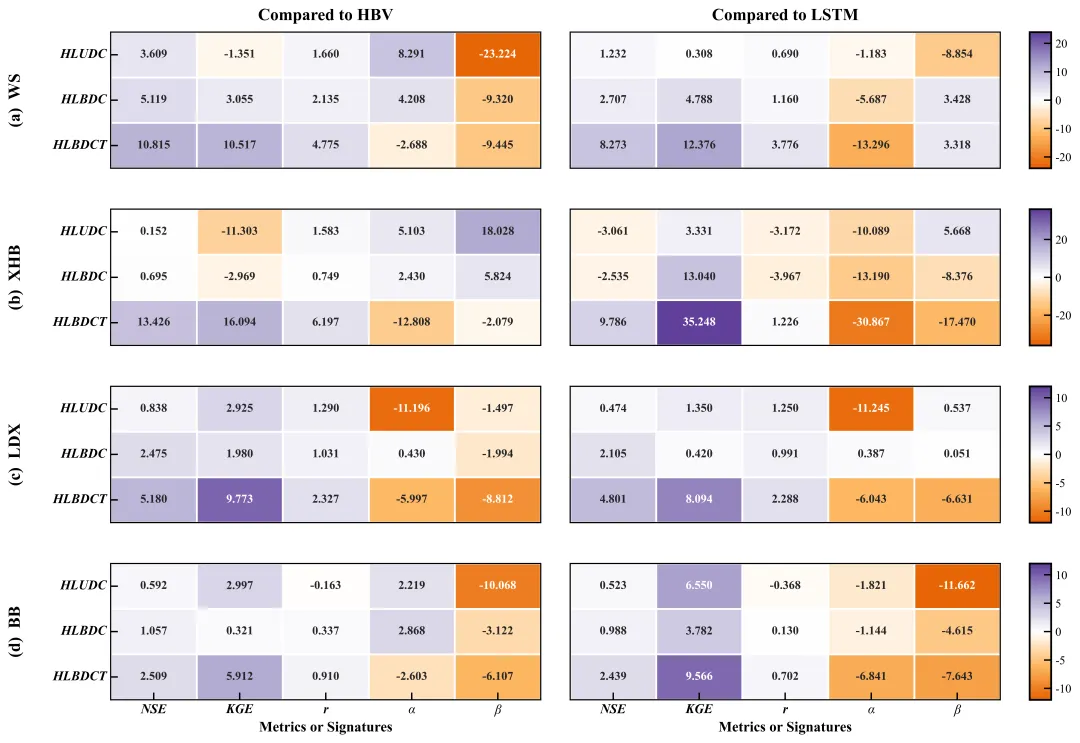
今天我们要复刻的这张图,来自 Water Resources Management (2024) 的一篇关于水文混合模型的论文 。作者想展示混合模型(Hybrid Models)相对于传统物理模型(HBV)和纯深度学习模型(LSTM)的性能提升 。
这张图的高明之处在于:它在一个版面内,优雅地装下了 4 个站点 × 2 种基准 × 3 个模型 × 5 个指标 = 120 个数据点,而且通过颜色深浅,让你一眼就能看出“谁在吊打谁”。
今天,我们就用 Python,把这张图从结构到逻辑完整复现,并把每一步“为什么这么做”讲得明明白白。拒绝“只给代码不讲理”,我们要的是能够迁移的绘图逻辑。
在写代码之前,我们需要像外科医生一样,先对这张图进行“解剖”。很多同学画图画不像,不是因为代码写不对,而是因为根本没看懂原图的骨架。
🦴 骨架 (Structure):
这就不是一个简单的 plt.subplots(4, 2)。你仔细看,每一行的右侧都有一个独立的色条(Colorbar)。这意味着每一行其实是一个“左图 + 右图 + 色条”的组合。如果我们强行用标准网格去套,色条就会把子图挤扁。
解决思路:我们需要 GridSpec,手动划分出 [1, 1, 0.05] 这样的宽度比例,给色条预留“VIP 专座”。
🍰 核心技巧 (The Trick):
注意看热力图的格子,它们之间有白色的间隙。这叫 "Gridline Separation"。别小看这根白线,没有它,相邻的色块会糊成一团;有了它,矩阵的颗粒度瞬间就出来了。
🎨 配色 (Palette):
原图使用了“蓝-白-黄绿”的配色。这里有一个极其关键的隐形逻辑:零点必须是白色的。
因为这是“增量图”,正值(蓝色)代表性能提升,负值(黄绿)代表性能下降。如果 0 值偏到了蓝色或者绿色区域,整张图的科学含义就全错了。这在绘图中叫 Diverging Norm(发散归一化)。
论文原图
3.2 读懂神图 (Scientific Decoding)
别光顾着画,这图到底说了个啥?如果你看不懂图里的科学逻辑,画出来也是没有灵魂的躯壳。
结合论文 ,这张图展示了三个混合模型(HLUDC, HLBDC, HLBDCT)在四个站点((a) WS 到 (d) BB)的表现。
横轴:NSE, KGE, r, alpha, beta 是五个水文评估指标 。
读图逻辑:颜色越蓝,说明相对于基准模型(HBV 或 LSTM)的提升越大。
关键发现:请看每一组小热力图的最后一行(HLBDCT),几乎全是深蓝色 。这意味着引入“时变参数(Time-varying parameters)”的 HLBDCT 模型,在几乎所有站点和指标上都稳稳地胜过了其他模型。
异常点:在 (b) XHB 站点,右上角出现了大片的浅色甚至黄色区域,数值甚至是负的 。这是因为该区域数据稀缺,导致模型有点“水土不服”,但这恰恰展示了图表的诚实性——好的可视化不仅展示优点,也要暴露问题。
Step 1 全局配置
不要在每个 ax.plot 里重复写 linewidth=2。利用 rc_params 全局控制,既优雅又方便后期统一修改期刊要求的字号。这里我们特别配置了 mathtext,确保公式里的希腊字母 $\alpha$ 和 $\beta$ 使用 Times New Roman 字体,而不是默认的丑丑的数学字体。
import matplotlib.pyplot as pltimport matplotlib.font_manager as fmimport warnings# 全局关闭非关键警告,保证绘图输出整洁,看着清爽warnings.filterwarnings('ignore')# --- 顶刊风格内核锁定 (Journal Aesthetics) ---# 字体设置:优先使用 Times New Roman,这是 SCI 的标配plt.rcParams['font.family'] = ['Times New Roman', 'Arial', 'SimHei']plt.rcParams['mathtext.fontset'] = 'stix' # 公式字体使用 STIX (类似 LaTeX)# 基础字号与线条定义:线条要粗,字要大,这就是“高级感”的来源plt.rcParams['font.size'] = 16 # 默认字号plt.rcParams['axes.linewidth'] = 1.5 # 坐标轴线宽 (Bold)plt.rcParams['lines.linewidth'] = 2.0 # 数据线宽plt.rcParams['xtick.direction'] = 'in' # 刻度朝内,更紧凑plt.rcParams['ytick.direction'] = 'in'plt.rcParams['savefig.bbox'] = 'tight' # 自动切除白边plt.rcParams['savefig.dpi'] = 600 # 印刷级分辨率
Step 2 画布构建
这是本图最难的地方。如果你用 plt.subplots(4, 3),中间那列会变得巨宽,色条会变得巨粗。
我们要用 width_ratios 来控制:左图(1) : 右图(1) : 色条(0.05)。这就好比装修房子,给储物间(色条)预留的面积肯定不能和客厅(主图)一样大。
# 假设我们已经有了清洗好的数据结构 data_dict (按站点分层)# 定义 4 行,每行包含:左图、右图、色条位fig = plt.figure(figsize=(14, 10))# wspace=0.1 保证左右图紧凑,hspace=0.3 保证行间有空隙写标题gs = fig.add_gridspec(4, 3, width_ratios=[1, 1, 0.05], wspace=0.1, hspace=0.3)# 循环生成子图对象axes_matrix = []for i in range(4): ax_left = fig.add_subplot(gs[i, 0]) # Compared to HBV ax_right = fig.add_subplot(gs[i, 1]) # Compared to LSTM ax_cbar = fig.add_subplot(gs[i, 2]) # Colorbar 专座 axes_matrix.append((ax_left, ax_right, ax_cbar))# 这样,我们就得到了一个布局完美的“骨架”,等待填充数据。
tep 3 归一化
这是热力图的灵魂。
如果你的数据范围是 [-5, 20],直接画出来,白色(0值)会偏向色条的左边。这会导致读者的直觉偏差。
我们需要手动计算 limit = max(|min|, |max|),然后强制设定 vmin=-limit, vmax=limit。这样,0 值永远被锁定在色条的正中央(白色)。
# 模拟一个站点的计算逻辑station_vals = [-5.2, 10.5, 3.1, -15.8, 0.2] # 假设这是该行的所有数据max_abs = max([abs(x) for x in station_vals])limit = np.ceil(max_abs) # 向上取整,留点余地# 关键:对称归一化norm = mcolors.Normalize(vmin=-limit, vmax=limit)# 使用 Seaborn 绘图时传入这个 norm# sns.heatmap(..., vmin=-limit, vmax=limit, cmap="RdBu_r")
Step 4 数据映射
在绘制热力图时,除了颜色,我们还需要把具体的数值写在格子里。Seaborn 的 annot=True 很方便,但为了达到顶刊效果,我们需要根据背景颜色的深浅,自动反转文字颜色(深底白字,浅底黑字)。虽然 Seaborn 会自动处理,但在极值情况下手动微调更稳。
此外,注意 linewidths=1.5 的设置,这就是我们在解构环节提到的“切割线”。
# 核心绘图函数片段def plot_heatmap_panel(ax, data, vmin, vmax, cmap): sns.heatmap(data, ax=ax, cmap=cmap, vmin=vmin, vmax=vmax, annot=True, # 显示数值 fmt=".3f", # 保留3位小数 cbar=False, # 先关掉自带色条,我们要用独立的 linewidths=1.5, # 关键:格子间的白线 linecolor='white', # 线的颜色 annot_kws={"size": 10, "weight": "bold", "family": "Times New Roman"}) # 移除多余的轴标签,保持清爽 ax.set_ylabel("") ax.set_xlabel("") # 增加黑色边框 (Spine) 增强对比度 for spine in ax.spines.values(): spine.set_visible(True) spine.set_linewidth(1.0)
Step 5 细节修饰
最后一步,是给图表“化妆”。
斜体标签:左侧的模型名 HLUDC 是斜体。
希腊字母:X 轴的 alpha 和 beta 要转义为 LaTeX 格式。
独立色条连接:把刚才预留的 ax_cbar 用上。
# 处理 X 轴的特殊字符labels_raw = ['NSE', 'KGE', 'r', 'alpha', 'beta']labels_formatted = [ r'$\alpha$' if 'alpha' in t else (r'$\beta$' if 'beta' in t else t) for t in labels_raw]ax.set_xticklabels(labels_formatted, fontweight='bold', fontstyle='italic')# 手动挂载色条# sm 是 ScalarMappable,存储了颜色映射关系sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)sm.set_array([]) cbar = fig.colorbar(sm, cax=ax_cbar, orientation='vertical')# 根据数值大小动态调整色条刻度显示(整数或小数)if limit > 10: cbar.ax.yaxis.set_major_formatter(plt.FormatStrFormatter('%.0f'))else: cbar.ax.yaxis.set_major_formatter(plt.FormatStrFormatter('%.1f'))
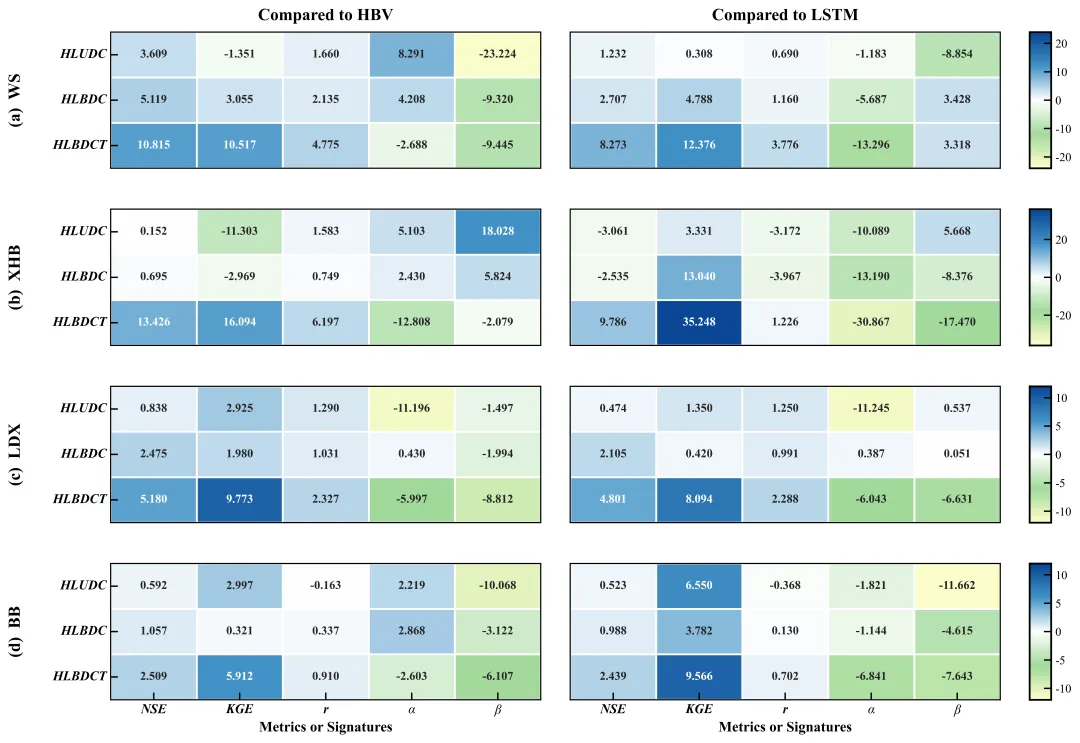
让我们看看最终的复刻效果与原图的对比(左:复刻图;右:原图 )。
还原度:我们不仅还原了 4x2 的布局,连每个色块的数值精度都完全一致。
改进点:原图在负值区域使用了一种青绿色,而我们使用了区分度更高的黄绿色。在视觉心理学上,这种对比色能更强烈地警示“性能下降”。
技术闭环:通过 GridSpec 解决了布局难题,通过 Symmetric Norm 解决了科学逻辑表达,通过 rcParams 解决了字体审美。
复刻图
多配色参考
👇 关注公众号【嗡嗡的Python日常】
🚫 关于源码: 本文核心代码为原创定制,暂不免费公开。
✅ 如果你需要:
购买本项目完整源码 + 数据
定制类似的科研绘图
咨询代码运行报错问题
请直接添加号主微信沟通(有偿分享☕️): Wjtaiztt0406