1. 从硬件限制到软件抽象
1.1 Linux 内存管理的核心矛盾
Linux 内核的设计目标之一是跨平台兼容性。它不仅要运行在 32 位的 i386 上,还要运行在 64 位的 Alpha、SPARC 等架构上。为了适配这些能够支持巨大地址空间的 64 位 CPU,Linux 在软件架构层面抽象出了一个通用的 三级页表模型:
- 1. PGD (Page Global Directory,页全局目录)
- 2. PMD (Page Middle Directory,页中间目录)
无论底层的硬件实际长什么样,Linux 内核的上层代码(如内存管理、进程调度)都统一默认:“我们拥有三级页表”。这是 Linux 内存管理的逻辑本质。
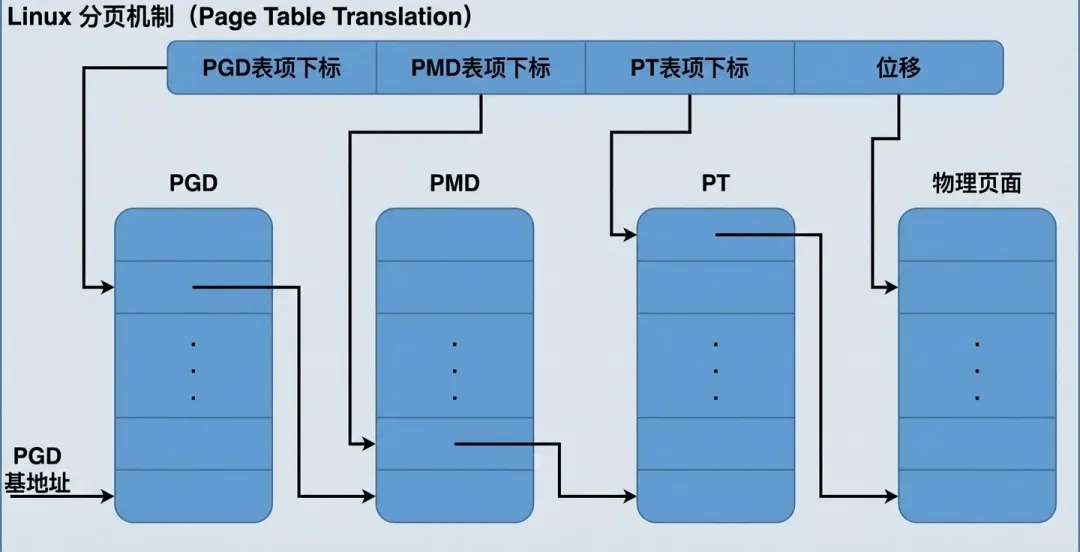
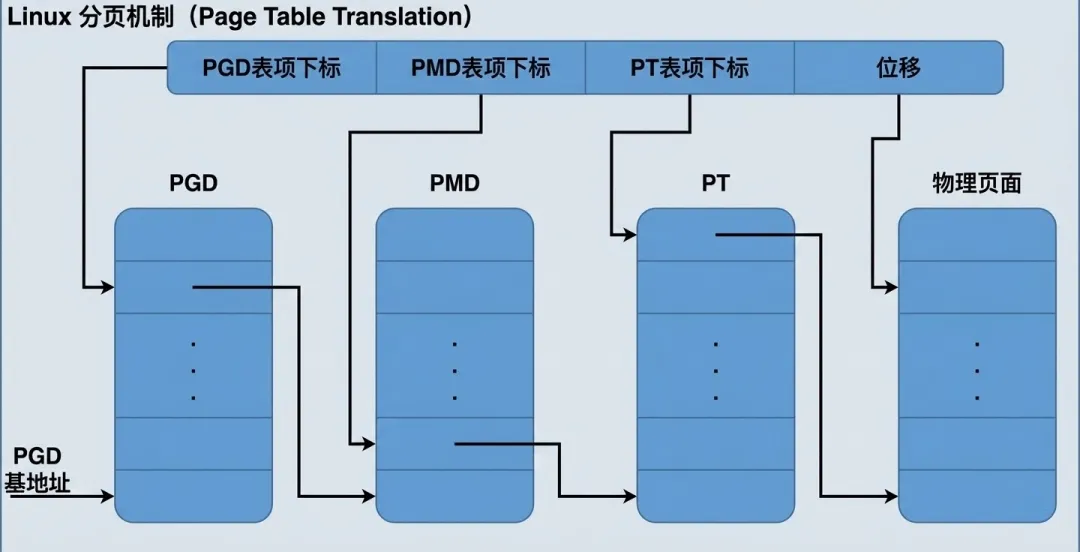
虚拟的 Linux 内存管理单元分成如下四步完成从线性地址到物理地址的映射:
- 1. 用线性地址中最高的那一个位段(图中 PGD 表项下标)为下标在 PGD 中找到相应的表项,该表项指向下一级的中间目录 PMD 地址。
- 2. 用线性地址中的第二个位段(图中 PMD 表项下标)为下标在此 PMD 中找到相应的表项,该表项指向下一级的 PT 地址。
- 3. 用线性地址中的第三个位段(图中 PT 表项下标)作为下标在 PT 中找到相应的表项,该表项中存放的就是指向物理页面的指针(也可以叫做 PFN)。
- 4. 线性地址中的最后位段(图中位移字段)为物理页面内的相对位移量,将此位移量与目标物理页面的起始地址相 加便得到相应的物理地址。
如果看不懂也不要紧,后文有例子讲解。
然而,当我们把目光聚焦到 Intel i386 体系结构时,问题出现了。Intel i386的页式存储的基本思路是通过目录(dir)和页面(page)分两个层次从线性地址和物理地址的映射,这并不符合内核三级映射的规则。
从线性地址到物理地址的映射过程为:
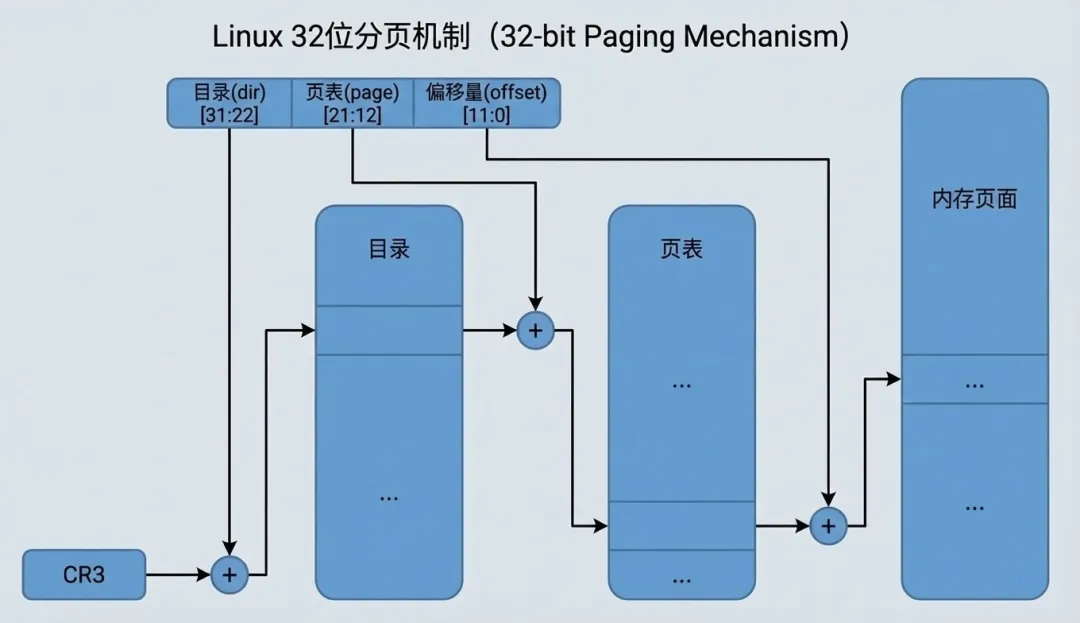
- 2. 以线性地址中的 dir 位段为下标,在目录中取得相应页面表的基地址。
- 3. 以线性地址中的 page 位段为下标,在所得到的页面表中取得相应的页面描述项。将页面描述项 中给出的页面基地址与线性地址中的 offset 位段相加得到物理地址。
为了解决这个问题,Linux 并没有修改上层的通用代码,而是使用了一种称为 “软件折叠 (Software Folding)” 的适配策略。
/* * traditional i386 two-level paging structure: */#define PGDIR_SHIFT 22#define PTRS_PER_PGD 1024/* * the i386 is two-level, so we don't really have any * PMD directory physically. */#define PMD_SHIFT 22#define PTRS_PER_PMD 1#define pgd_page(pgd) \((unsigned long) __va(pgd_val(pgd) & PAGE_MASK))static inline pmd_t * pmd_offset(pgd_t * dir, unsigned long address){ return (pmd_t *) dir;}
我们从代码中可以看到,PGDIR_SHIFT和PMD_SHIFT都为 22,但是PTRS_PER_PMD为1,也就是意味着PMD的长度为0(2的0次方为1)。
当内核调用pmd_offset计算 PMD 时,则直接返回输入进来的 dir。简单来说,当做了一个透传。
32 位地址空间总共 4GB,Linux 内核将其分为两部分:
系统空间:最高的 1GB(虚地址 0xC0000000 至 0xFFFFFFFF),供内核使用。
用户空间:较低的 3GB(虚地址 0x00000000 至 0xBFFFFFFF),供各个进程使用。
理论上,每个进程可以使用 3GB 的用户空间。实际空间大小受物理存储器(包括内存、磁盘交换区或交换文件)的限制。
虽然每个进程拥有独立的 3GB 用户空间,但系统空间由所有进程共享。当进程通过系统调用进入内核时,它就运行在共享的系统空间中,不再有独立空间。
从具体进程的角度看:每个进程都拥有 4GB 的虚存空间——较低的 3GB 是自己的用户空间,最高的 1GB 是与所有进程及内核共享的系统空间。

虽然系统空间占据了每个虚存空间中最高的 1G 字节,在物理的内存中却总是从最低的地址(0)开 始。所以,对于内核来说,其地址的映射是很简单的线性映射,0xC0000000 就是两者之间的位移量。
在代码中将此位移称为 PAGE_OFFSET 而定义在 include/asm-i386/page.h中
/* * This handles the memory map.. We could make this a config * option, but too many people screw it up, and too few need * it. * * A __PAGE_OFFSET of 0xC0000000 means that the kernel has * a virtual address space of one gigabyte, which limits the * amount of physical memory you can use to about 950MB. * * If you want more physical memory than this then see the CONFIG_HIGHMEM4G * and CONFIG_HIGHMEM64G options in the kernel configuration. */#define __PAGE_OFFSET (0xC0000000)#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
也就是说:对于系统空间而言,给定一个虚地址 x,其物理地址是 x - PAGE_OFFSET。相应地。给定一个物理地址 x,其虚拟地址是 x + PAGE_OFFSET。
那么有个问题,既然我们知道虚拟地址转物理地址是由MMU硬件转换的,那__pa()的目的是什么?让我们暂停一下,思考一个看似简单却极具深意的问题:CR3 寄存器里存放的究竟是物理地址还是虚拟地址?
假设 CR3 存放的是 虚拟地址(例如 0xC0001000),当 CPU 需要访问一个内存地址时,MMU 的工作流程将会变成一场灾难:
- 1. CPU 发出指令读取数据,MMU 启动,它需要查阅页目录来寻找映射关系。
- 3. CR3 回答:“在虚拟地址
0xC0001000。” - 4. MMU 愣住了:“等等,这是一个虚拟地址。为了读取这个地址里的内容(也就是页目录),我必须先把它翻译成物理地址。但我得先查页表才能翻译它……”
- 5. MMU 接着问:“那查哪个页表能翻译
0xC0001000 呢?” - 6. CR3 回答:“还是我指向的这个页目录……”
结果就是MMU陷入了死循环,因此这里下一级页表的基地址必须采用物理地址。由此,我们可以推断出CR3的值应该是物理地址。从代码中,我们也可以验证这个猜测
#define load_cr3(pgdir) \ asm volatile("movl %0,%%cr3": :"r" (__pa(pgdir)));
1.2 地址空间的“谎言”与“真相”
在比i386更早的时代,也就是8086/80286 时代,当时寄存器只有 16 位,无法直接寻址 20 位的内存空间(1MB)。为了解决这个问题,Intel 发明了“段基址 + 偏移量”的方式(段地址 << 4 + 偏移量)来计算物理地址。
也就是说线性地址 = 段基址 (Base) + 逻辑地址 (Offset)
到了 80386,Intel 终于实现了 32 位架构,并引入了更先进的页式管理。但是,为了保持与以前的处理器(8086/286)兼容,Intel 不能直接扔掉“段式管理”这套逻辑。80386 的硬件电路被固化为:逻辑地址 -> [分段单元] -> 线性地址 -> [分页单元] -> 物理地址。这个顺序是硬件写死的,操作系统无法改变,只能服从。
既然不能关闭段机制,Linux 就在初始化阶段(arch/i386/kernel/head.S)实施了一个骚操作:**它把所有段(内核代码段、用户数据段等)的基地址(Base Address)全部设为 0。**这样就线性地址 = 0 (Base) + 逻辑地址 (Offset),实现了线性地址 = 逻辑地址。也就是说硬件依然勤勤恳恳地做了加法运算,但结果没有改变。
当 Linux 得到线性地址后,才开始真正的进入了页式映射的过程。
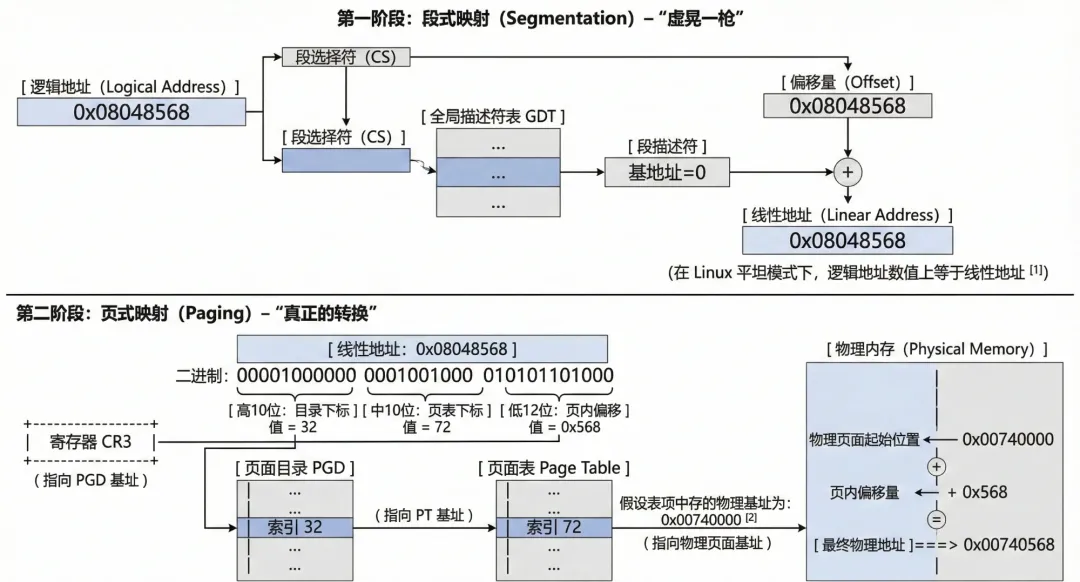
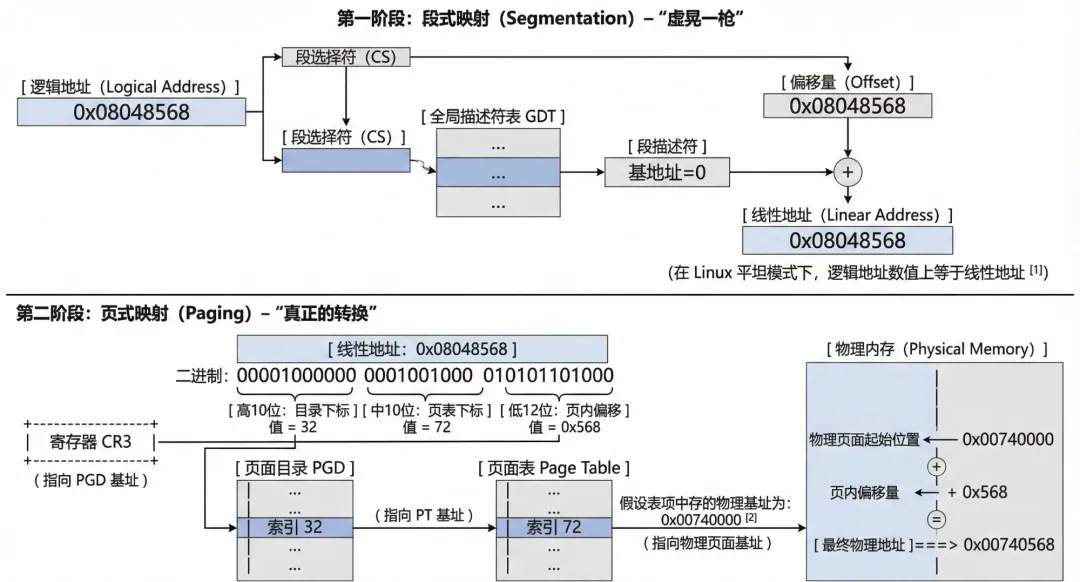
为了更好的理解这一个过程,我们举一个真实的例子,假设应用层有一个变量存储在0x08048568 地址中,通过分段单元转换为线性地址,值依然为0x08048568 。将线性地址转换为二进制:
`0000 1000 0000 0100 1000 0101 0110 1000`
按照三级(其中PMD为0)页表的定位,在进行整理:
`0000100000` (32) | `0001001000` (72) | `0x568`
即:PGD表项下标为32,PMD表项下标为0(参考上文软件折叠设计,直接返回了pgd_t ,即pgd_t == pmd_t ),PT表项下标为72,offset 为 0x568。
我们在上一节提到,每个进程拥有独立的 3GB 用户空间。这意味着,虽然大家的虚拟地址可能都是 0x8048000,但因为每个进程的 CR3 寄存器(页目录基址) 不同,它们会被映射到完全不同的物理页面上。每当进程切换时,内核会将新进程的页目录物理地址填入 CR3。从此,MMU 拿着这个 CR3,根据线性地址查找页表,完成从虚到实的最终一跃。
2. 描述虚实的 C 语言模型
2.1 内存管理的宏
如果你阅读过内核源码,特别是关于内存的部分,你会发现经常打交道的宏为:pgd_t,pmd_t,pte_t 。如果在怀着好奇之心点开这些宏的定义
typedefstruct { unsigned long pte_low; } pte_t;typedefstruct { unsigned long pmd; } pmd_t;typedefstruct { unsigned long pgd; } pgd_t
实际上就是长整型数据,之所以不直接定义成长整数的原因在于这样可以让 gcc 在编译时加以严格的类型检查。这句话似乎也有点拗口,我们尝试翻译为代码:
typedefstruct { unsigned long pte_low; } pte_t; typedefstruct { unsigned long pmd; } pmd_t; void use_pte(pte_t p); void use_pmd(pmd_t p); pte_t pte; pmd_t pmd; use_pte(pte); // 正确 use_pmd(pmd); // 正确 use_pte(pmd); // 编译期就会报类型不匹配 // 如果它们都是 unsigned long: typedef unsigned long pte_t; typedef unsigned long pmd_t; void use_pte(pte_t p); void use_pmd(pmd_t p); unsigned long x; use_pte(x); // 能编译 use_pmd(x); // 也能编译
既然变量特殊定义,那么获取方式也是用宏定义了:
#define pmd_val(x) ((x).pmd)#define pgd_val(x) ((x).pgd)
作为 PT 的下标,只需要用到高20位(物理页面是4K对齐,低12位永远为0),也就是说 pte_t 的低12位,用于描述页面属性。在内核代码中,通过pgprot_t来描述:
typedefstruct { unsigned long pgprot; } pgprot_t;#define pgprot_val(x) ((x).pgprot)
为什么单独使用pgprot_t 来描述物理页面呢?而不是放在pte_t结构体中?
其核心目的还是为了解耦,在内存管理中,“物理页面在哪(地址)”和“该页面允许什么操作(属性)”往往是两个独立的信息来源。
这句话似乎也比较难理解,我们尝试通过几个例子来解释下:
例1:mmap 创建内存映射
当在程序中调用 mmap 申请一块内存区域时,内核首先创建vm_area_struct 结构体来代表这块虚拟内存,而不是立即分配物理内存。
在vm_area_struct 中,内核会根据传入的参数(如 PROT_READ、PROT_WRITE),计算出这块区域对应的页面保护属性,并保存在 vm_page_prot 字段中(类型为 pgprot_t)。
struct vm_area_struct {struct vm_area_struct *vm_next; pgprot_t vm_page_prot; // [1] 这里存储了该区域的访问权限和保护属性 unsigned long vm_flags;};
例子2:写时复制(COW)
当父进程 fork 子进程时,子进程会继承父进程的页表。为了效率,Linux 不会立即复制物理内存,而是让父子进程共享同一个物理页,但把权限改为“只读”。如果任意进程尝试写这个页,CPU触发缺页异常,分配新的物理页面,把旧数据拷过去,然后用新的物理页地址 + 可写的属性(pgprot_t)生成一个新的 pte_t 填回去。
那么我们知晓了pgprot_t 是单独描述页面属性的,那么又是什么时候将pgprot_t 写回到pte_t 中。我们回到例子1和例子2中,当访问了地址,这个地址缺没有被分配物理地址,此时就进入缺页异常,在缺页异常中,会分配物理页面,调用宏 mk_pte,将“物理页的序号”和“保护属性”组合在一起,生成最终填入页表的 pte_t 值。
#define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))
内核又封装了部分宏来获取pgprot中的属性,用于判断物理页的状态,比如:
static inline int pte_read(pte_t pte) { return (pte).pte_low & _PAGE_USER; }static inline int pte_exec(pte_t pte) { return (pte).pte_low & _PAGE_USER; }static inline int pte_dirty(pte_t pte) { return (pte).pte_low & _PAGE_DIRTY; }static inline int pte_young(pte_t pte) { return (pte).pte_low & _PAGE_ACCESSED; }static inline int pte_write(pte_t pte) { return (pte).pte_low & _PAGE_RW; }
2.2 物理世界的档案
系统启动时,内核会根据探测到的物理内存大小,申请一个巨大的 struct page 数组,名叫 mem_map 。每个page数据结构代表着一个物理页面,整个数组就代表着系统中的全部物理页面。
回到上一章节,PTE 高20位对于软件而已,就是mem_map的下标。在内核中,可以通过virt_to_page 找到具体的物理页面。
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))
接下来是一些管理物理页面的结构体,在原理中,这一段描述极其容易混淆,梳理好久才理清关系。
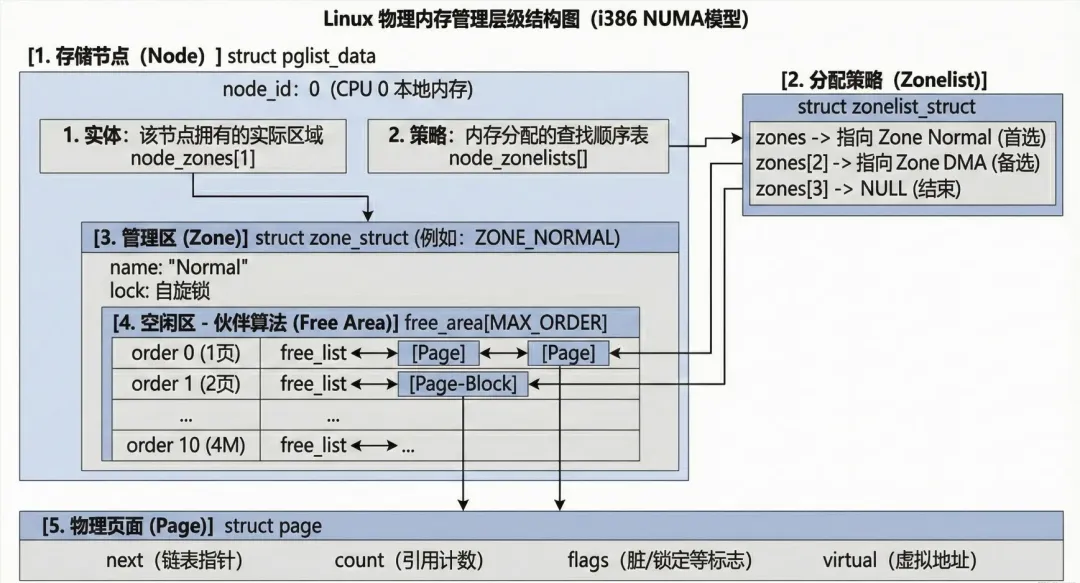
我们按照层级关系来划分:节点 (pglist_data) -> 分配策略链表 (zonelist_struct)——>管理区 (zone_struct) -> 空闲区 (free_area_t) -> **物理页面 (struct page)。**我们逐级拆分
第一层:存储节点 (pglist_data)
为了支持 NUMA(多处理器非均质存储结构)而引入的概念。NUMA的结构参考下图:
在此之前为UMA,结构图如下:
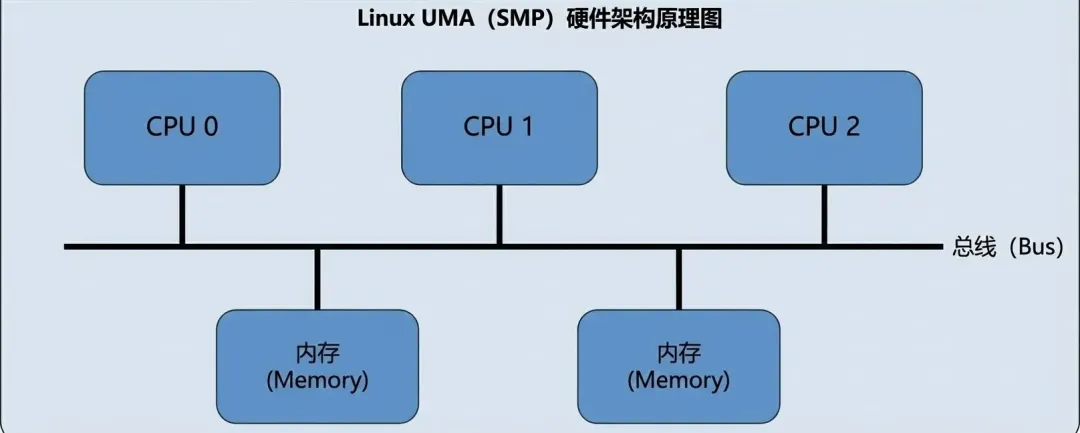
pglist_data 是物理内存管理的最高层级容器。
与其他结构的关系:
typedefstruct pglist_data { zone_t node_zones[MAX_NR_ZONES]; // 用于定义页面分配的策略(例如先在哪个区分配,不够再去哪个区) zonelist_t node_zonelists[NR_GFPINDEX]; // 存放该节点下的管理区(zone_t)struct page *node_mem_map; // 管理该节点的物理内存} pg_data_t
第二层:分配策略链表 (zonelist_struct)
它规定了分配页面时的尝试次序。例如:先试 ZONE_DMA,如果不够了,再试 ZONE_NORMAL。这就构成了一种分配策略。
与其他结构的关系:
typedefstruct zonelist_struct { zone_t * zones [MAX_NR_ZONES+1]; // 一个指针,指向pglist_data.node_zones int gfp_mask; // 分配策略}
初始化的时候参考
// 节点0的GFP_KERNEL分配策略node0_zonelists[GFP_KERNEL] = { .zones = { &node0.node_zones[ZONE_NORMAL], // 优先级1:本节点普通内存 &node0.node_zones[ZONE_DMA], // 优先级2:本节点DMA内存 &node1.node_zones[ZONE_NORMAL], // 优先级3:远程节点普通内存 &node1.node_zones[ZONE_DMA], // 优先级4:远程节点DMA内存 NULL // 结束标记 }};// 节点0的GFP_DMA分配策略node0_zonelists[GFP_DMA] = { .zones = { &node0.node_zones[ZONE_DMA], // 优先级1:本节点DMA内存 &node1.node_zones[ZONE_DMA], // 优先级2:远程节点DMA内存 NULL // 不包括NORMAL zone }};
第三层:管理区 zone_struct (或 zone_t)
由于硬件限制(如 DMA 只能访问低端内存),一个节点内的物理内存被划分为不同的区域,通常是
#define ZONE_DMA 0 // ISA设备可访问的内存 (0-16MB) #define ZONE_NORMAL 1 // 内核直接映射的内存 (16MB-896MB) #define ZONE_HIGHMEM 2 // 高端内存,需要动态映射 (>896MB)#define MAX_NR_ZONES 3
与其他结构的关系:
typedefstruct zone_struct { free_area_t free_area[MAX_ORDER]; // 用来管理该区内的空闲页面块 unsigned long offset; // 表示该管理区在全局 mem_map 数组中的起始页面号struct page *zone_mem_map; // zone_mem_map = pglist_data->node_mem_map + offsetstruct pglist_data *zone_pgdat; // 指回它所属的 pglist_data 节点}
第三层:空闲区 free_area_t
这是为了实现“伙伴算法(Buddy System)”而设立的结构。
在每个管理区内,空闲页面并不是杂乱无章的,而是按照连续块的大小(1页、2页、4页...直到 1024页)分别管理的。
free_area[0]: 管理大小为 2^0 = 1 个页面的块free_area[1]: 管理大小为 2^1 = 2 个页面的块free_area[2]: 管理大小为 2^2 = 4 个页面的块free_area[3]: 管理大小为 2^3 = 8 个页面的块...free_area[10]: 管理大小为 2^10 = 1024 个页面的块
那么系统需要6个页面,就从 free_area[3] 中取出8个页面,再将剩余的两个页面放入 free_area[1]中。
与其他结构的关系:
typedefstruct free_area_struct {struct list_head free_list; // 这是一个双向链表头,链接着所有大小相同的空闲物理页面(struct page) unsigned int *map; // 用作位图(Bitmap)以辅助伙伴算法(Buddy System)}
伙伴算法的细节还挺多,后续单开一篇文章来讲解。
第四层:物理页面 struct page (或 mem_map_t)
这是内存管理的最小单位。系统中的每一个物理页面(4KB)都有一个对应的 page 结构体,它们构成了一个巨大的数组 mem_map。
与其他结构的关系:
typedefstruct page {struct list_head list; // 通过这个成员,页面可以被链入 free_area_t 的空闲队列中struct zone_struct *zone; // 指向该页面所属的 管理区 (zone_struct)}
如果把内存管理比作连锁酒店:
- 1. pglist_data (节点):某一家分店。
- 2. zonelist_struct (分配策略):前台的“客房安排规则表”。
◦ 这就好比前台有一本手册,针对不同级别的客人有不同的查找顺序。
◦ 规则 A(普通客人):先看“标准房区”,没有了再看“商务房区”。
◦ 规则 B(VIP客人):先看“VIP 专区”,没有了再看“标准房区”。
◦ 这个结构体告诉系统:“按什么顺序去搜寻房间”。
- 3. zone_struct (管理区):具体的楼层或区域(VIP区、标准区)。
- 4. free_area_t (空闲区):该区域的空房登记本。
- 5. struct page (物理页面):具体的房间。
我们在通过一个小例子把几个结构体联系起来
// 内存分配请求void *ptr = kmalloc(4096, GFP_KERNEL);// 内核执行流程:1. 确定当前CPU所在的NUMA节点 (pglist_data)——>先找到分店2. 根据传入的 GFP_KERNEL 标志,在节点的 node_zonelists 数组中找到对应的策略列表(**zonelist_t**)——>查阅操作手册3. 按**zonelist**中的优先级顺序尝试各个zone,首先检查 ZONE_NORMAL——>参考指南查房进行查房4. 在选中的zone中寻找空闲的page结构体(free_area_t)——>去查看空闲登记本,并拿取钥匙5. 标记page为已分配状态,返回物理地址——>拿到钥匙,进入房间
最后在附上一张全景图
2.3 虚拟世界的蓝图
与物理空间不同的是,虚拟空间的管理是以线程为单位,即该线程需要哪些内存。
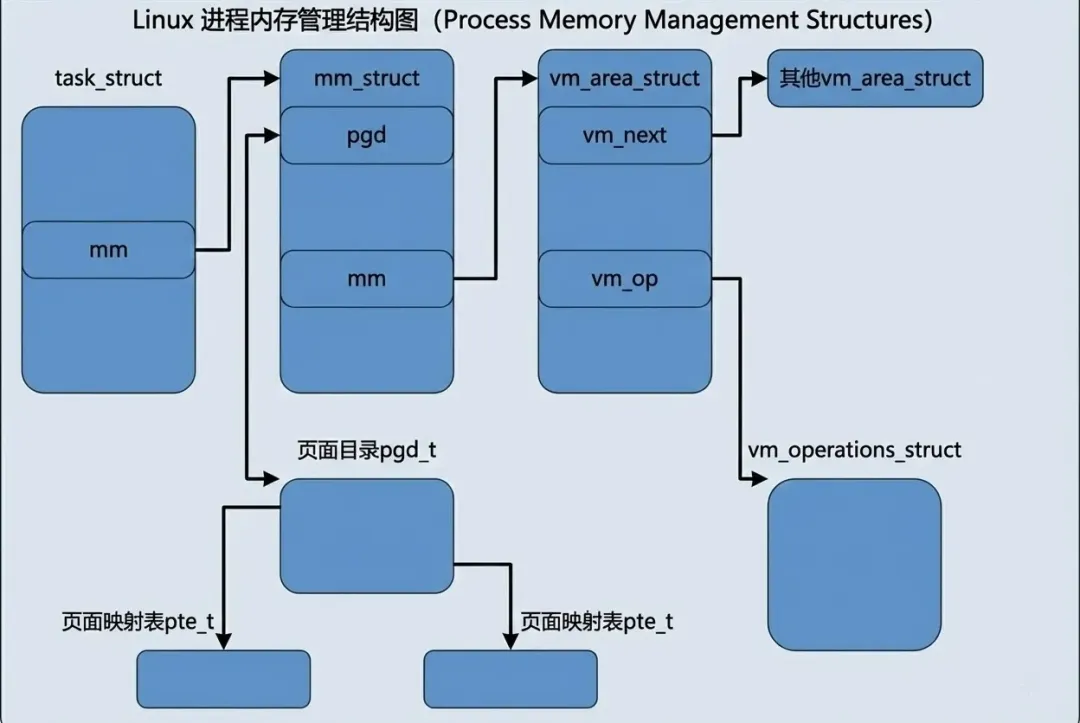
对于虚拟内存管理来说,最重要的结构体之一就是 vm_area_struct ,定义如下:
struct vm_area_struct {struct mm_struct * vm_mm; unsigned long vm_start; unsigned long vm_end;struct vm_area_struct *vm_next; pgprot_t vm_page_prot; ....}
其中 vm_mm 指向整个进程的用户空间,vm_start~vm_end 表示了该虚拟内存的地址范围,需要注意的是[vm_start, vm_end),地址中包含了 vm_start 但是不包含 vm_end,vm_next 指向下一个虚拟地址的指针,vm_page_prot 表示虚拟内存段的属性。
属于同一个进程的所有区间都要按虚存地址的高低次序链接在一起,结构中的 vm_next 指针就是用于这个目的。
低地址 ↓[代码段] vm_area_struct_1 → 0x08048000-0x08049000 (可读可执行) ↓ vm_next[数据段] vm_area_struct_2 → 0x08049000-0x0804a000 (可读可写) ↓ vm_next[堆 区] vm_area_struct_3 → 0x0804b000-0x0806b000 (可读可写) ↓ vm_next[共享库] vm_area_struct_4 → 0x40000000-0x40015000 (可读可执行) ↓ vm_next[栈 区] vm_area_struct_5 → 0xbfffe000-0xc0000000 (可读可写) ↓ vm_next NULL ↑高地址
由于区间的划分并不仅仅取决于地址的连续性,一个进程的虚存(用户)空间很可能会被划分成大量的区间。内核中给定一个虚拟地址而要找出其所属的区间是一个频繁用到的操作,如果每次都要顺着 vm_next 在链中作线性搜索的话,势必会显著地影响到内核的效率。所以,除了通过 vm_next 指针把所有区加串成一个线性队列以外,还可以在区间数量较大时为之建立一个 AVL(Adelson_Velskii and Landis)树。AVL树相关资料比较复杂,不适合在本章节讲解,感兴趣的读者可以自行了解。
当我们对 vm_area_struct 基本了解后,我们思考两个问题:
- 1. 这段虚拟内存里的数据是从哪里来的?是程序运行时凭空产生(如
malloc 的堆),还是磁盘上某个文件的‘镜像’(如 .exe 代码段)?内核如何区分这两者? - 2. 当进程访问这段内存发生缺页异常(Page Fault)时,内核该怎么办?是应该去磁盘读文件?还是去 Swap 交换区捞数据?或者是直接分配一个全零的物理页?内核如何针对不同的内存区域,执行截然不同的恢复操作?
针对第一个问题,Linux 在 VMA 中设计了 struct file *vm_file 指针。
- • 有背景(File-backed):如果指针非空,说明这段内存是有“靠山”的,它与磁盘上的文件建立了映射关系。当你读写内存时,实际上是在与文件系统打交道。
- • 没背景(Anonymous):如果指针为空,说明这是匿名的内存区域(如堆栈),它的数据只存在于 RAM(或 Swap)中,与具体文件无关。
针对第二个问题,Linux 引入了面向对象的设计思想。它不搞一堆 if-else 来硬编码处理逻辑,而是给每个 VMA 绑定了一组“锦囊妙计” —— struct vm_operations_struct *vm_ops。
- • 这是一组函数指针(如
nopage, open, close)。 - • 当缺页发生时,内核不再犹豫,直接调用
vma->vm_ops->nopage()。 - • 如果是文件映射,这个函数就会去读磁盘;如果是设备映射,它可能去读显存。
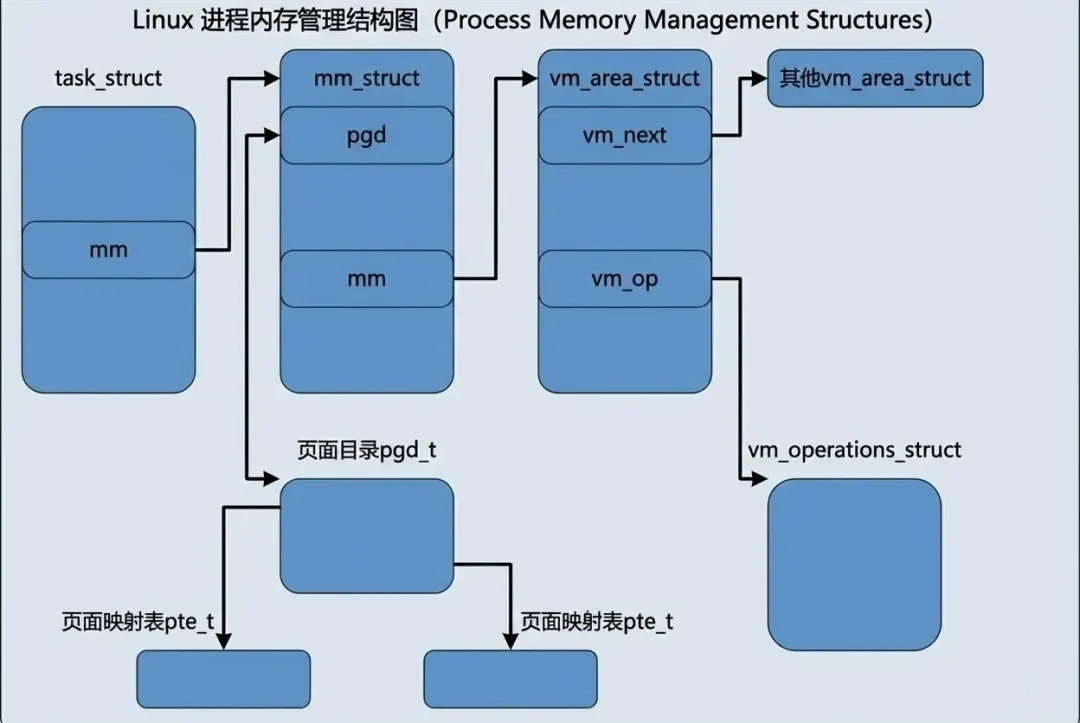
最后,我们再来看mm_struct的结构体,这是比 vm_area_struct 更高层次上使用的数据结构。每个进程只有一个 mm_struct 结构,类比为物理内存中的 pglist_data。
struct mm_struct {struct vm_area_struct * mmap; /* list of VMAs */ rb_root_t mm_rb;struct vm_area_struct * mmap_cache; /* last find_vma result */ pgd_t * pgd; atomic_t mm_users; /* How many users with user space? */ atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */ int map_count; /* number of VMAs */struct rw_semaphore mmap_sem; spinlock_t page_table_lock; /* Protects task page tables and mm->rss */struct list_head mmlist; /* List of all active mm's. These are globally strung * together off init_mm.mmlist, and are protected * by mmlist_lock */ unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; unsigned long rss, total_vm, locked_vm; unsigned long def_flags; unsigned long cpu_vm_mask; unsigned long swap_address; unsigned dumpable:1; /* Architecture-specific MM context */ mm_context_t context;};
打开 include/linux/sched.h,会发现 struct mm_struct 非常庞大。如果逐行阅读,很容易陷入细节的泥潭。
我们不妨转换视角:如果把 mm_struct 看作是掌管进程内存的“CEO”,它需要处理哪些维度的事务?
- 1. 管理虚拟空间
核心问题:进程拥有哪些虚拟内存区域(VMA)?
struct mm_struct {struct vm_area_struct * mmap; rb_root_t mm_rb; atomic_t mm_count; }
如上所说,一个进程的虚拟空间被切分为多个 VMA。
- •
mmap :管理该进程所有的 VMA 的链表。 - •
mm_rb:为了加快遍历速度而引入的 AVL 树。
- 2. 对接物理内存
核心问题:CPU 怎么知道这些虚拟地址对应的物理地址在哪?
struct mm_struct { pgd_t * pgd; mm_context_t context;}
pgd 是最核心的成员,指向了硬件页表的根节点。当进程调度发生时,内核会将这个变量里的物理地址填入 CR3 寄存器,没有它,MMU 就无法工作。
- 3. 统计进程资源
核心问题:进程到底占用了多少资源?
struct mm_struct { unsigned long rss, total_vm, locked_vm;}
通过对比这两个变量,就能体现出 Linux 按需分配 (Demand Paging) 的特性(通常 total_vm >> rss)。
- •
total_vm :进程要用多大空间(所有 VMA 大小之和),不一定有分配物理内存。
- 4. 保护内存安全
核心问题:多线程同时修改内存布局怎么办?
struct mm_struct {struct rw_semaphore mmap_sem;}
在多线程环境下(Linux 线程本质是共享 mm_struct 的进程),如果一个线程在读内存映射,另一个线程在 munmap 释放这块内存,就会出大乱子。
因此,Linux 在 mm_struct 中使用**读写信号量(Read-Write Semaphore)**来协调:多个线程可以同时读,但写操作独占。
我们通过一张图来总览全局
(比如 PID 1 的 init 进程),看看它的内存总管 mm_struct 到底在管理些什么。
crash> task 1 PID: 1 TASK: c1598000 CPU: 0 COMMAND: "init"struct task_struct { ... mm = 0xdfe0fee0, ... }
我们拿到了 init 进程的 mm_struct 地址:0xdfe0fee0。 接下来我们在查看mm_struct的成员,我们按照之前的四个维度进行划分
crash>struct mm_struct 0xdfe0fee0 struct mm_struct { /* 管理虚拟空间 */ mmap = 0xdfe0df00, mm_rb = { rb_node = 0xdfe0ddf8 }, map_count = 0x12, /* 对接物理内存 */ pgd = 0xdfe0e000, /* 统计进程资源(单位是页) */ rss = 0x9a, total_vm = 0x1b9, locked_vm = 0x0, /* 保护内存安全 */ mmap_sem = { count = 0x0, wait_lock = { lock = 0x1 }, wait_list = { next = 0xdfe0ff04, prev = 0xdfe0ff04 } }, }
- •
pgd:我们看到了它指向了内核的页目录基址(对于 init 进程,它可能与 idle 共享,或者有自己独立的,这里验证了它持有通往硬件的钥匙)。 - •
mmap:指向了第一个虚拟内存区域(VMA)。 - •
rss vs total_vm:可以看到 rss (0x9a) 远小于 total_vm (0x1b9),完美验证了 Linux 按需分配 (Demand Paging) 的策略。
同样的,我们也可以通过/proc/[pid]/status 查看到rss和total_vm值
hyper:~# cat /proc/1/status Name: init VmSize: 1764 kB VmRSS: 616 kB
在查看VMA:
crash> vm 1 PID: 1 TASK: c1598000 CPU: 0 COMMAND: "init" MM PGD RSS TOTAL_VM dfe0fee0 dfe0e000 616k 1764k VMA START END FLAGS FILE dfe0df00 8048000 8050000 1875 /sbin/init dfe0dea0 8050000 8051000 1873 /sbin/init dfe0d8a0 8051000 8071000 77 dfe0de40 40000000 40015000 875 /lib/ld-2.3.6.so dfe0dde0 40015000 40017000 873 /lib/ld-2.3.6.so dfe0dd80 40017000 40019000 73 dfe0dcc0 4001b000 40051000 75 /lib/libsepol.so.1 dfe0dc00 40051000 40052000 73 /lib/libsepol.so.1 dfe0dba0 40052000 4005c000 73 dfe0dc60 4005c000 4006f000 75 /lib/libselinux.so.1 dfe0db40 4006f000 40071000 73 /lib/libselinux.so.1 dfe0dae0 40071000 40182000 75 /lib/libc-2.3.6.so dfe0d900 40182000 40187000 71 /lib/libc-2.3.6.so dfe0da20 40187000 40189000 73 /lib/libc-2.3.6.so dfe0d9c0 40189000 4018c000 73 dfe0da80 4018c000 4018e000 75 /lib/libdl-2.3.6.so dfe0d960 4018e000 40190000 73 /lib/libdl-2.3.6.so dfe0df60 bfffe000 c0000000 177
可以看到,每个VMA的地址或者属性都是不相同,也印证了上文所提到的属于同一个进程的所有区间都要按虚存地址的高低次序链接在一起。
3.总结
至此,我们已经拆解了 Linux 内存管理的框架:
- • 物理线:从 Node 到 Zone 再到 Page,内核为每一寸物理内存都建立了详尽的档案。
- • 虚拟线:通过
mm_struct 和 VMA,内核为每个进程编织了一个 3GB 的平坦梦境。
我们最后通过一个例子彻底打通 虚拟地址 -> 线性地址 -> 物理地址 -> 物理页 的全链路。
#include <stdio.h> #include <unistd.h> int main() { // 使用 volatile 防止编译器优化掉它 volatile int stack_var = 0xDEADBEEF; // 2. 打印进程 PID 和变量的虚拟地址 printf("========================================\n"); printf("Process PID: %d\n", getpid()); printf("Stack Var Virtual Address: %p\n", &stack_var); printf("Value: 0x%X\n", stack_var); printf("========================================\n"); printf("Program is sleeping... Now go to crash!\n"); printf("Press ENTER to exit...\n"); // 3. 暂停,保持现场,等待 Crash 检查 while(1); return 0; }
在 qemu 里面执行
======================================== Process PID: 273 Stack Var Virtual Address: 0xbffffdf4 Value: 0xDEADBEEF ======================================== Program is sleeping... Now go to crash! Press ENTER to exit..
进入 crash 中查看信息。
切换上下文到目标进程:
crash> set 273 PID: 273 COMMAND: "stack_val" TASK: df800000 CPU: 0 STATE: TASK_RUNNING
虚拟地址转物理地址:
使用 vtop 命令,输入程序打印的虚拟地址:
crash> vtop 0xbffffdf4 VIRTUAL PHYSICAL bffffdf4 1f7cfdf4 PAGE DIRECTORY: df814000 **PGD**: df814bfc => 1faf6067 **PMD**: df814bfc => 1faf6067 **PTE**: 1faf6ffc => 1f7cf067 **PAGE**: 1f7cf000 PTE PHYSICAL FLAGS 1f7cf067 1f7cf000 (PRESENT|RW|USER|ACCESSED|DIRTY) VMA START END FLAGS FILE dfaf5300 bffff000 c0000000 177 PAGE PHYSICAL MAPPING INDEX CNT FLAGS c15697b0 1f7cf000 0 0 1 1000040
crash 会自动帮你查页表(PGD -> PT -> Phys),告诉你物理地址是 0x1f7cfdf4。 ****
读取物理内存验证数据:
现在我们绕过所有虚拟内存机制,直接读取物理内存条上的数据,看看是不是我们写的 0xDEADBEEF:
crash> rd -p 0x1f7cfdf4 1f7cfdf4: deadbeef ....
在物理内存中看到了 deadbeef。这证明了虚拟地址到物理地址的映射是真实存在的。
通过 Crash,我们亲眼见证了虚拟地址 0xbffffdf4 是如何一步步变成物理地址 0x1f7cfdf4 的。至此,静态的内存映射架构已经搭建完毕。但如果进程访问了一个‘不存在’的地址会发生什么? 这就是连接这两条平行线的桥梁 —— 缺页异常 (Page Fault)。我们将在下一篇文章中,深入动态的内存分配过程。
内核考古2001:Linux 内存管理(一):基础架构与地址映射的虚实之道
1. 从硬件限制到软件抽象
1.1 Linux 内存管理的核心矛盾
Linux 内核的设计目标之一是跨平台兼容性。它不仅要运行在 32 位的 i386 上,还要运行在 64 位的 Alpha、SPARC 等架构上。为了适配这些能够支持巨大地址空间的 64 位 CPU,Linux 在软件架构层面抽象出了一个通用的 三级页表模型:
- 1. PGD (Page Global Directory,页全局目录)
- 2. PMD (Page Middle Directory,页中间目录)
无论底层的硬件实际长什么样,Linux 内核的上层代码(如内存管理、进程调度)都统一默认:“我们拥有三级页表”。这是 Linux 内存管理的逻辑本质。
虚拟的 Linux 内存管理单元分成如下四步完成从线性地址到物理地址的映射:
- 1. 用线性地址中最高的那一个位段(图中 PGD 表项下标)为下标在 PGD 中找到相应的表项,该表项指向下一级的中间目录 PMD 地址。
- 2. 用线性地址中的第二个位段(图中 PMD 表项下标)为下标在此 PMD 中找到相应的表项,该表项指向下一级的 PT 地址。
- 3. 用线性地址中的第三个位段(图中 PT 表项下标)作为下标在 PT 中找到相应的表项,该表项中存放的就是指向物理页面的指针(也可以叫做 PFN)。
- 4. 线性地址中的最后位段(图中位移字段)为物理页面内的相对位移量,将此位移量与目标物理页面的起始地址相 加便得到相应的物理地址。
如果看不懂也不要紧,后文有例子讲解。
然而,当我们把目光聚焦到 Intel i386 体系结构时,问题出现了。Intel i386的页式存储的基本思路是通过目录(dir)和页面(page)分两个层次从线性地址和物理地址的映射,这并不符合内核三级映射的规则。
从线性地址到物理地址的映射过程为:
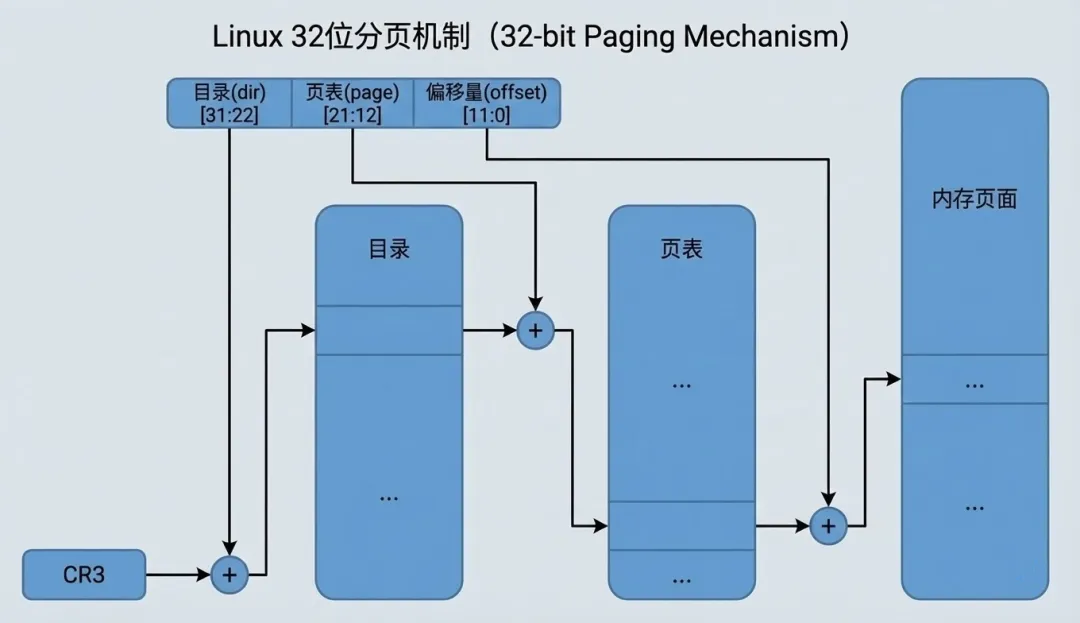
- 2. 以线性地址中的 dir 位段为下标,在目录中取得相应页面表的基地址。
- 3. 以线性地址中的 page 位段为下标,在所得到的页面表中取得相应的页面描述项。将页面描述项 中给出的页面基地址与线性地址中的 offset 位段相加得到物理地址。
为了解决这个问题,Linux 并没有修改上层的通用代码,而是使用了一种称为 “软件折叠 (Software Folding)” 的适配策略。
/* * traditional i386 two-level paging structure: */#define PGDIR_SHIFT 22#define PTRS_PER_PGD 1024/* * the i386 is two-level, so we don't really have any * PMD directory physically. */#define PMD_SHIFT 22#define PTRS_PER_PMD 1#define pgd_page(pgd) \((unsigned long) __va(pgd_val(pgd) & PAGE_MASK))static inline pmd_t * pmd_offset(pgd_t * dir, unsigned long address){ return (pmd_t *) dir;}
我们从代码中可以看到,PGDIR_SHIFT和PMD_SHIFT都为 22,但是PTRS_PER_PMD为1,也就是意味着PMD的长度为0(2的0次方为1)。
当内核调用pmd_offset计算 PMD 时,则直接返回输入进来的 dir。简单来说,当做了一个透传。
32 位地址空间总共 4GB,Linux 内核将其分为两部分:
系统空间:最高的 1GB(虚地址 0xC0000000 至 0xFFFFFFFF),供内核使用。
用户空间:较低的 3GB(虚地址 0x00000000 至 0xBFFFFFFF),供各个进程使用。
理论上,每个进程可以使用 3GB 的用户空间。实际空间大小受物理存储器(包括内存、磁盘交换区或交换文件)的限制。
虽然每个进程拥有独立的 3GB 用户空间,但系统空间由所有进程共享。当进程通过系统调用进入内核时,它就运行在共享的系统空间中,不再有独立空间。
从具体进程的角度看:每个进程都拥有 4GB 的虚存空间——较低的 3GB 是自己的用户空间,最高的 1GB 是与所有进程及内核共享的系统空间。

虽然系统空间占据了每个虚存空间中最高的 1G 字节,在物理的内存中却总是从最低的地址(0)开 始。所以,对于内核来说,其地址的映射是很简单的线性映射,0xC0000000 就是两者之间的位移量。
在代码中将此位移称为 PAGE_OFFSET 而定义在 include/asm-i386/page.h中
/* * This handles the memory map.. We could make this a config * option, but too many people screw it up, and too few need * it. * * A __PAGE_OFFSET of 0xC0000000 means that the kernel has * a virtual address space of one gigabyte, which limits the * amount of physical memory you can use to about 950MB. * * If you want more physical memory than this then see the CONFIG_HIGHMEM4G * and CONFIG_HIGHMEM64G options in the kernel configuration. */#define __PAGE_OFFSET (0xC0000000)#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
也就是说:对于系统空间而言,给定一个虚地址 x,其物理地址是 x - PAGE_OFFSET。相应地。给定一个物理地址 x,其虚拟地址是 x + PAGE_OFFSET。
那么有个问题,既然我们知道虚拟地址转物理地址是由MMU硬件转换的,那__pa()的目的是什么?让我们暂停一下,思考一个看似简单却极具深意的问题:CR3 寄存器里存放的究竟是物理地址还是虚拟地址?
假设 CR3 存放的是 虚拟地址(例如 0xC0001000),当 CPU 需要访问一个内存地址时,MMU 的工作流程将会变成一场灾难:
- 1. CPU 发出指令读取数据,MMU 启动,它需要查阅页目录来寻找映射关系。
- 3. CR3 回答:“在虚拟地址
0xC0001000。” - 4. MMU 愣住了:“等等,这是一个虚拟地址。为了读取这个地址里的内容(也就是页目录),我必须先把它翻译成物理地址。但我得先查页表才能翻译它……”
- 5. MMU 接着问:“那查哪个页表能翻译
0xC0001000 呢?” - 6. CR3 回答:“还是我指向的这个页目录……”
结果就是MMU陷入了死循环,因此这里下一级页表的基地址必须采用物理地址。由此,我们可以推断出CR3的值应该是物理地址。从代码中,我们也可以验证这个猜测
#define load_cr3(pgdir) \ asm volatile("movl %0,%%cr3": :"r" (__pa(pgdir)));
1.2 地址空间的“谎言”与“真相”
在比i386更早的时代,也就是8086/80286 时代,当时寄存器只有 16 位,无法直接寻址 20 位的内存空间(1MB)。为了解决这个问题,Intel 发明了“段基址 + 偏移量”的方式(段地址 << 4 + 偏移量)来计算物理地址。
也就是说线性地址 = 段基址 (Base) + 逻辑地址 (Offset)
到了 80386,Intel 终于实现了 32 位架构,并引入了更先进的页式管理。但是,为了保持与以前的处理器(8086/286)兼容,Intel 不能直接扔掉“段式管理”这套逻辑。80386 的硬件电路被固化为:逻辑地址 -> [分段单元] -> 线性地址 -> [分页单元] -> 物理地址。这个顺序是硬件写死的,操作系统无法改变,只能服从。
既然不能关闭段机制,Linux 就在初始化阶段(arch/i386/kernel/head.S)实施了一个骚操作:**它把所有段(内核代码段、用户数据段等)的基地址(Base Address)全部设为 0。**这样就线性地址 = 0 (Base) + 逻辑地址 (Offset),实现了线性地址 = 逻辑地址。也就是说硬件依然勤勤恳恳地做了加法运算,但结果没有改变。
当 Linux 得到线性地址后,才开始真正的进入了页式映射的过程。
为了更好的理解这一个过程,我们举一个真实的例子,假设应用层有一个变量存储在0x08048568 地址中,通过分段单元转换为线性地址,值依然为0x08048568 。将线性地址转换为二进制:
`0000 1000 0000 0100 1000 0101 0110 1000`
按照三级(其中PMD为0)页表的定位,在进行整理:
`0000100000` (32) | `0001001000` (72) | `0x568`
即:PGD表项下标为32,PMD表项下标为0(参考上文软件折叠设计,直接返回了pgd_t ,即pgd_t == pmd_t ),PT表项下标为72,offset 为 0x568。
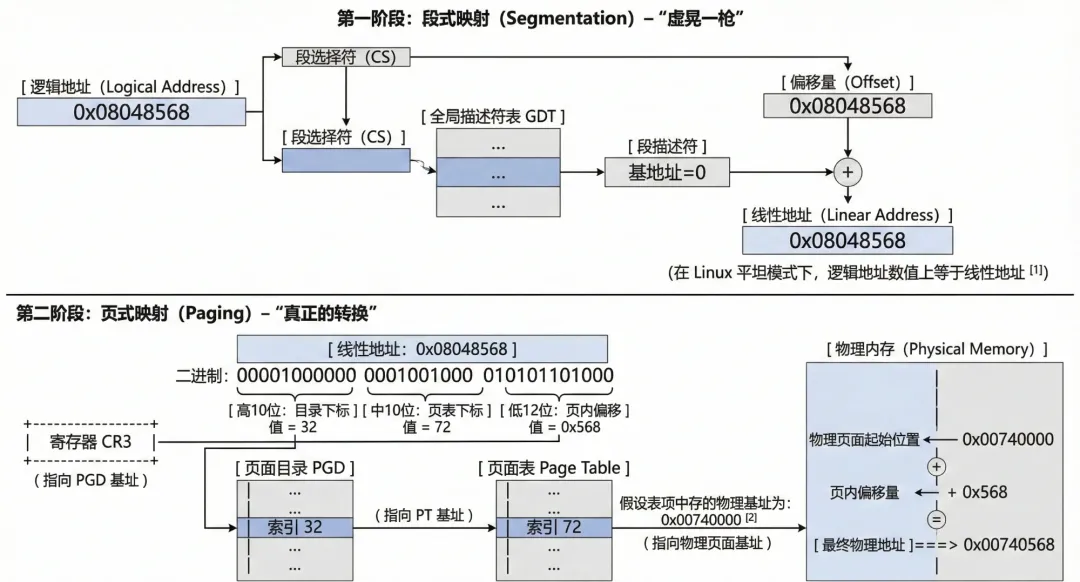
我们在上一节提到,每个进程拥有独立的 3GB 用户空间。这意味着,虽然大家的虚拟地址可能都是 0x8048000,但因为每个进程的 CR3 寄存器(页目录基址) 不同,它们会被映射到完全不同的物理页面上。每当进程切换时,内核会将新进程的页目录物理地址填入 CR3。从此,MMU 拿着这个 CR3,根据线性地址查找页表,完成从虚到实的最终一跃。
2. 描述虚实的 C 语言模型
2.1 内存管理的宏
如果你阅读过内核源码,特别是关于内存的部分,你会发现经常打交道的宏为:pgd_t,pmd_t,pte_t 。如果在怀着好奇之心点开这些宏的定义
typedefstruct { unsigned long pte_low; } pte_t;typedefstruct { unsigned long pmd; } pmd_t;typedefstruct { unsigned long pgd; } pgd_t
实际上就是长整型数据,之所以不直接定义成长整数的原因在于这样可以让 gcc 在编译时加以严格的类型检查。这句话似乎也有点拗口,我们尝试翻译为代码:
typedefstruct { unsigned long pte_low; } pte_t; typedefstruct { unsigned long pmd; } pmd_t; void use_pte(pte_t p); void use_pmd(pmd_t p); pte_t pte; pmd_t pmd; use_pte(pte); // 正确 use_pmd(pmd); // 正确 use_pte(pmd); // 编译期就会报类型不匹配 // 如果它们都是 unsigned long: typedef unsigned long pte_t; typedef unsigned long pmd_t; void use_pte(pte_t p); void use_pmd(pmd_t p); unsigned long x; use_pte(x); // 能编译 use_pmd(x); // 也能编译
既然变量特殊定义,那么获取方式也是用宏定义了:
#define pmd_val(x) ((x).pmd)#define pgd_val(x) ((x).pgd)
作为 PT 的下标,只需要用到高20位(物理页面是4K对齐,低12位永远为0),也就是说 pte_t 的低12位,用于描述页面属性。在内核代码中,通过pgprot_t来描述:
typedefstruct { unsigned long pgprot; } pgprot_t;#define pgprot_val(x) ((x).pgprot)
为什么单独使用pgprot_t 来描述物理页面呢?而不是放在pte_t结构体中?
其核心目的还是为了解耦,在内存管理中,“物理页面在哪(地址)”和“该页面允许什么操作(属性)”往往是两个独立的信息来源。
这句话似乎也比较难理解,我们尝试通过几个例子来解释下:
例1:mmap 创建内存映射
当在程序中调用 mmap 申请一块内存区域时,内核首先创建vm_area_struct 结构体来代表这块虚拟内存,而不是立即分配物理内存。
在vm_area_struct 中,内核会根据传入的参数(如 PROT_READ、PROT_WRITE),计算出这块区域对应的页面保护属性,并保存在 vm_page_prot 字段中(类型为 pgprot_t)。
struct vm_area_struct {struct vm_area_struct *vm_next; pgprot_t vm_page_prot; // [1] 这里存储了该区域的访问权限和保护属性 unsigned long vm_flags;};
例子2:写时复制(COW)
当父进程 fork 子进程时,子进程会继承父进程的页表。为了效率,Linux 不会立即复制物理内存,而是让父子进程共享同一个物理页,但把权限改为“只读”。如果任意进程尝试写这个页,CPU触发缺页异常,分配新的物理页面,把旧数据拷过去,然后用新的物理页地址 + 可写的属性(pgprot_t)生成一个新的 pte_t 填回去。
那么我们知晓了pgprot_t 是单独描述页面属性的,那么又是什么时候将pgprot_t 写回到pte_t 中。我们回到例子1和例子2中,当访问了地址,这个地址缺没有被分配物理地址,此时就进入缺页异常,在缺页异常中,会分配物理页面,调用宏 mk_pte,将“物理页的序号”和“保护属性”组合在一起,生成最终填入页表的 pte_t 值。
#define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))
内核又封装了部分宏来获取pgprot中的属性,用于判断物理页的状态,比如:
static inline int pte_read(pte_t pte) { return (pte).pte_low & _PAGE_USER; }static inline int pte_exec(pte_t pte) { return (pte).pte_low & _PAGE_USER; }static inline int pte_dirty(pte_t pte) { return (pte).pte_low & _PAGE_DIRTY; }static inline int pte_young(pte_t pte) { return (pte).pte_low & _PAGE_ACCESSED; }static inline int pte_write(pte_t pte) { return (pte).pte_low & _PAGE_RW; }
2.2 物理世界的档案
系统启动时,内核会根据探测到的物理内存大小,申请一个巨大的 struct page 数组,名叫 mem_map 。每个page数据结构代表着一个物理页面,整个数组就代表着系统中的全部物理页面。
回到上一章节,PTE 高20位对于软件而已,就是mem_map的下标。在内核中,可以通过virt_to_page 找到具体的物理页面。
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))
接下来是一些管理物理页面的结构体,在原理中,这一段描述极其容易混淆,梳理好久才理清关系。
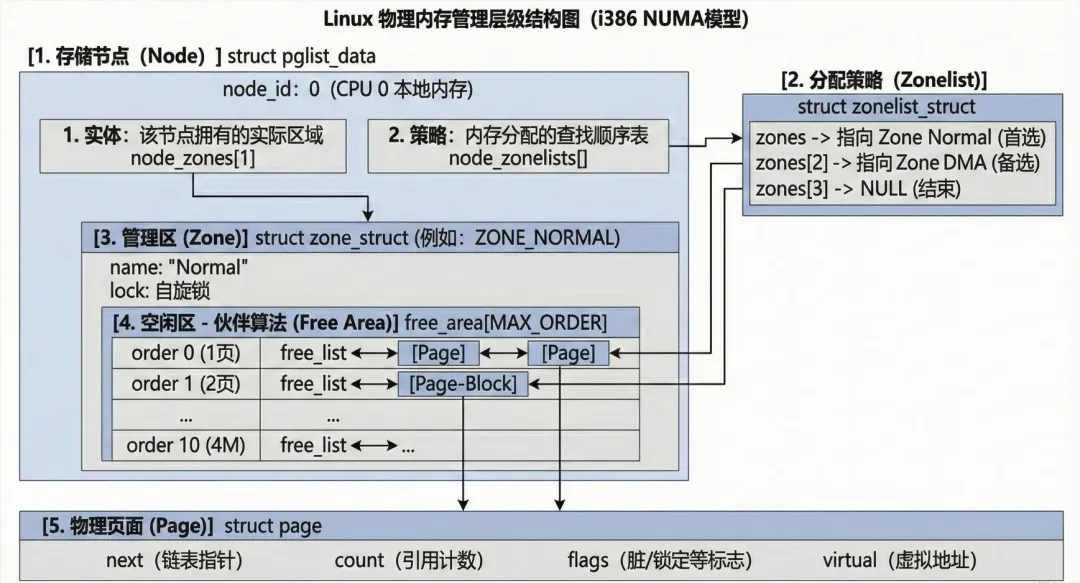
我们按照层级关系来划分:节点 (pglist_data) -> 分配策略链表 (zonelist_struct)——>管理区 (zone_struct) -> 空闲区 (free_area_t) -> **物理页面 (struct page)。**我们逐级拆分
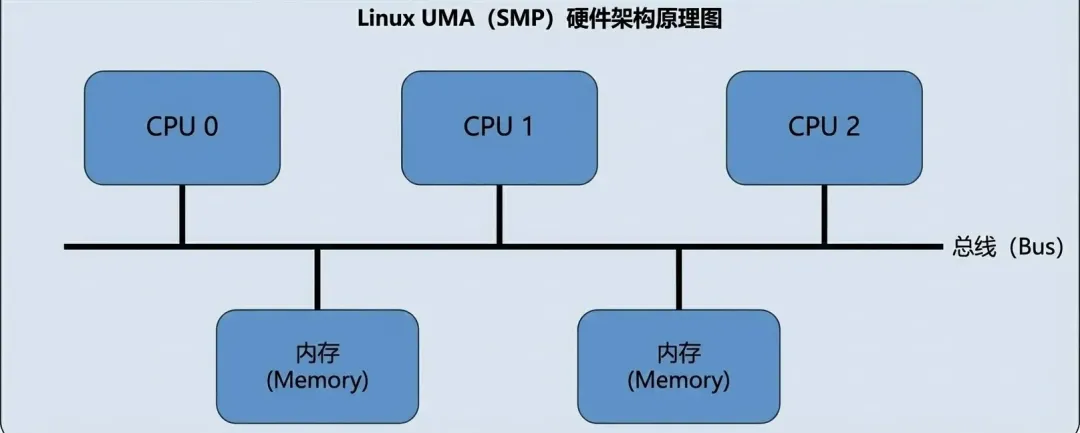
第一层:存储节点 (pglist_data)
为了支持 NUMA(多处理器非均质存储结构)而引入的概念。NUMA的结构参考下图:
在此之前为UMA,结构图如下:
pglist_data 是物理内存管理的最高层级容器。
与其他结构的关系:
typedefstruct pglist_data { zone_t node_zones[MAX_NR_ZONES]; // 用于定义页面分配的策略(例如先在哪个区分配,不够再去哪个区) zonelist_t node_zonelists[NR_GFPINDEX]; // 存放该节点下的管理区(zone_t)struct page *node_mem_map; // 管理该节点的物理内存} pg_data_t
第二层:分配策略链表 (zonelist_struct)
它规定了分配页面时的尝试次序。例如:先试 ZONE_DMA,如果不够了,再试 ZONE_NORMAL。这就构成了一种分配策略。
与其他结构的关系:
typedefstruct zonelist_struct { zone_t * zones [MAX_NR_ZONES+1]; // 一个指针,指向pglist_data.node_zones int gfp_mask; // 分配策略}
初始化的时候参考
// 节点0的GFP_KERNEL分配策略node0_zonelists[GFP_KERNEL] = { .zones = { &node0.node_zones[ZONE_NORMAL], // 优先级1:本节点普通内存 &node0.node_zones[ZONE_DMA], // 优先级2:本节点DMA内存 &node1.node_zones[ZONE_NORMAL], // 优先级3:远程节点普通内存 &node1.node_zones[ZONE_DMA], // 优先级4:远程节点DMA内存 NULL // 结束标记 }};// 节点0的GFP_DMA分配策略node0_zonelists[GFP_DMA] = { .zones = { &node0.node_zones[ZONE_DMA], // 优先级1:本节点DMA内存 &node1.node_zones[ZONE_DMA], // 优先级2:远程节点DMA内存 NULL // 不包括NORMAL zone }};
第三层:管理区 zone_struct (或 zone_t)
由于硬件限制(如 DMA 只能访问低端内存),一个节点内的物理内存被划分为不同的区域,通常是
#define ZONE_DMA 0 // ISA设备可访问的内存 (0-16MB) #define ZONE_NORMAL 1 // 内核直接映射的内存 (16MB-896MB) #define ZONE_HIGHMEM 2 // 高端内存,需要动态映射 (>896MB)#define MAX_NR_ZONES 3
与其他结构的关系:
typedefstruct zone_struct { free_area_t free_area[MAX_ORDER]; // 用来管理该区内的空闲页面块 unsigned long offset; // 表示该管理区在全局 mem_map 数组中的起始页面号struct page *zone_mem_map; // zone_mem_map = pglist_data->node_mem_map + offsetstruct pglist_data *zone_pgdat; // 指回它所属的 pglist_data 节点}
第三层:空闲区 free_area_t
这是为了实现“伙伴算法(Buddy System)”而设立的结构。
在每个管理区内,空闲页面并不是杂乱无章的,而是按照连续块的大小(1页、2页、4页...直到 1024页)分别管理的。
free_area[0]: 管理大小为 2^0 = 1 个页面的块free_area[1]: 管理大小为 2^1 = 2 个页面的块free_area[2]: 管理大小为 2^2 = 4 个页面的块free_area[3]: 管理大小为 2^3 = 8 个页面的块...free_area[10]: 管理大小为 2^10 = 1024 个页面的块
那么系统需要6个页面,就从 free_area[3] 中取出8个页面,再将剩余的两个页面放入 free_area[1]中。
与其他结构的关系:
typedefstruct free_area_struct {struct list_head free_list; // 这是一个双向链表头,链接着所有大小相同的空闲物理页面(struct page) unsigned int *map; // 用作位图(Bitmap)以辅助伙伴算法(Buddy System)}
伙伴算法的细节还挺多,后续单开一篇文章来讲解。
第四层:物理页面 struct page (或 mem_map_t)
这是内存管理的最小单位。系统中的每一个物理页面(4KB)都有一个对应的 page 结构体,它们构成了一个巨大的数组 mem_map。
与其他结构的关系:
typedefstruct page {struct list_head list; // 通过这个成员,页面可以被链入 free_area_t 的空闲队列中struct zone_struct *zone; // 指向该页面所属的 管理区 (zone_struct)}
如果把内存管理比作连锁酒店:
- 1. pglist_data (节点):某一家分店。
- 2. zonelist_struct (分配策略):前台的“客房安排规则表”。
◦ 这就好比前台有一本手册,针对不同级别的客人有不同的查找顺序。
◦ 规则 A(普通客人):先看“标准房区”,没有了再看“商务房区”。
◦ 规则 B(VIP客人):先看“VIP 专区”,没有了再看“标准房区”。
◦ 这个结构体告诉系统:“按什么顺序去搜寻房间”。
- 3. zone_struct (管理区):具体的楼层或区域(VIP区、标准区)。
- 4. free_area_t (空闲区):该区域的空房登记本。
- 5. struct page (物理页面):具体的房间。
我们在通过一个小例子把几个结构体联系起来
// 内存分配请求void *ptr = kmalloc(4096, GFP_KERNEL);// 内核执行流程:1. 确定当前CPU所在的NUMA节点 (pglist_data)——>先找到分店2. 根据传入的 GFP_KERNEL 标志,在节点的 node_zonelists 数组中找到对应的策略列表(**zonelist_t**)——>查阅操作手册3. 按**zonelist**中的优先级顺序尝试各个zone,首先检查 ZONE_NORMAL——>参考指南查房进行查房4. 在选中的zone中寻找空闲的page结构体(free_area_t)——>去查看空闲登记本,并拿取钥匙5. 标记page为已分配状态,返回物理地址——>拿到钥匙,进入房间
最后在附上一张全景图
2.3 虚拟世界的蓝图
与物理空间不同的是,虚拟空间的管理是以线程为单位,即该线程需要哪些内存。
对于虚拟内存管理来说,最重要的结构体之一就是 vm_area_struct ,定义如下:
struct vm_area_struct {struct mm_struct * vm_mm; unsigned long vm_start; unsigned long vm_end;struct vm_area_struct *vm_next; pgprot_t vm_page_prot; ....}
其中 vm_mm 指向整个进程的用户空间,vm_start~vm_end 表示了该虚拟内存的地址范围,需要注意的是[vm_start, vm_end),地址中包含了 vm_start 但是不包含 vm_end,vm_next 指向下一个虚拟地址的指针,vm_page_prot 表示虚拟内存段的属性。
属于同一个进程的所有区间都要按虚存地址的高低次序链接在一起,结构中的 vm_next 指针就是用于这个目的。
低地址 ↓[代码段] vm_area_struct_1 → 0x08048000-0x08049000 (可读可执行) ↓ vm_next[数据段] vm_area_struct_2 → 0x08049000-0x0804a000 (可读可写) ↓ vm_next[堆 区] vm_area_struct_3 → 0x0804b000-0x0806b000 (可读可写) ↓ vm_next[共享库] vm_area_struct_4 → 0x40000000-0x40015000 (可读可执行) ↓ vm_next[栈 区] vm_area_struct_5 → 0xbfffe000-0xc0000000 (可读可写) ↓ vm_next NULL ↑高地址
由于区间的划分并不仅仅取决于地址的连续性,一个进程的虚存(用户)空间很可能会被划分成大量的区间。内核中给定一个虚拟地址而要找出其所属的区间是一个频繁用到的操作,如果每次都要顺着 vm_next 在链中作线性搜索的话,势必会显著地影响到内核的效率。所以,除了通过 vm_next 指针把所有区加串成一个线性队列以外,还可以在区间数量较大时为之建立一个 AVL(Adelson_Velskii and Landis)树。AVL树相关资料比较复杂,不适合在本章节讲解,感兴趣的读者可以自行了解。
当我们对 vm_area_struct 基本了解后,我们思考两个问题:
- 1. 这段虚拟内存里的数据是从哪里来的?是程序运行时凭空产生(如
malloc 的堆),还是磁盘上某个文件的‘镜像’(如 .exe 代码段)?内核如何区分这两者? - 2. 当进程访问这段内存发生缺页异常(Page Fault)时,内核该怎么办?是应该去磁盘读文件?还是去 Swap 交换区捞数据?或者是直接分配一个全零的物理页?内核如何针对不同的内存区域,执行截然不同的恢复操作?
针对第一个问题,Linux 在 VMA 中设计了 struct file *vm_file 指针。
- • 有背景(File-backed):如果指针非空,说明这段内存是有“靠山”的,它与磁盘上的文件建立了映射关系。当你读写内存时,实际上是在与文件系统打交道。
- • 没背景(Anonymous):如果指针为空,说明这是匿名的内存区域(如堆栈),它的数据只存在于 RAM(或 Swap)中,与具体文件无关。
针对第二个问题,Linux 引入了面向对象的设计思想。它不搞一堆 if-else 来硬编码处理逻辑,而是给每个 VMA 绑定了一组“锦囊妙计” —— struct vm_operations_struct *vm_ops。
- • 这是一组函数指针(如
nopage, open, close)。 - • 当缺页发生时,内核不再犹豫,直接调用
vma->vm_ops->nopage()。 - • 如果是文件映射,这个函数就会去读磁盘;如果是设备映射,它可能去读显存。
最后,我们再来看mm_struct的结构体,这是比 vm_area_struct 更高层次上使用的数据结构。每个进程只有一个 mm_struct 结构,类比为物理内存中的 pglist_data。
struct mm_struct {struct vm_area_struct * mmap; /* list of VMAs */ rb_root_t mm_rb;struct vm_area_struct * mmap_cache; /* last find_vma result */ pgd_t * pgd; atomic_t mm_users; /* How many users with user space? */ atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */ int map_count; /* number of VMAs */struct rw_semaphore mmap_sem; spinlock_t page_table_lock; /* Protects task page tables and mm->rss */struct list_head mmlist; /* List of all active mm's. These are globally strung * together off init_mm.mmlist, and are protected * by mmlist_lock */ unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; unsigned long rss, total_vm, locked_vm; unsigned long def_flags; unsigned long cpu_vm_mask; unsigned long swap_address; unsigned dumpable:1; /* Architecture-specific MM context */ mm_context_t context;};
打开 include/linux/sched.h,会发现 struct mm_struct 非常庞大。如果逐行阅读,很容易陷入细节的泥潭。
我们不妨转换视角:如果把 mm_struct 看作是掌管进程内存的“CEO”,它需要处理哪些维度的事务?
- 1. 管理虚拟空间
核心问题:进程拥有哪些虚拟内存区域(VMA)?
struct mm_struct {struct vm_area_struct * mmap; rb_root_t mm_rb; atomic_t mm_count; }
如上所说,一个进程的虚拟空间被切分为多个 VMA。
- •
mmap :管理该进程所有的 VMA 的链表。 - •
mm_rb:为了加快遍历速度而引入的 AVL 树。
- 2. 对接物理内存
核心问题:CPU 怎么知道这些虚拟地址对应的物理地址在哪?
struct mm_struct { pgd_t * pgd; mm_context_t context;}
pgd 是最核心的成员,指向了硬件页表的根节点。当进程调度发生时,内核会将这个变量里的物理地址填入 CR3 寄存器,没有它,MMU 就无法工作。
- 3. 统计进程资源
核心问题:进程到底占用了多少资源?
struct mm_struct { unsigned long rss, total_vm, locked_vm;}
通过对比这两个变量,就能体现出 Linux 按需分配 (Demand Paging) 的特性(通常 total_vm >> rss)。
- •
total_vm :进程要用多大空间(所有 VMA 大小之和),不一定有分配物理内存。
- 4. 保护内存安全
核心问题:多线程同时修改内存布局怎么办?
struct mm_struct {struct rw_semaphore mmap_sem;}
在多线程环境下(Linux 线程本质是共享 mm_struct 的进程),如果一个线程在读内存映射,另一个线程在 munmap 释放这块内存,就会出大乱子。
因此,Linux 在 mm_struct 中使用**读写信号量(Read-Write Semaphore)**来协调:多个线程可以同时读,但写操作独占。
我们通过一张图来总览全局
(比如 PID 1 的 init 进程),看看它的内存总管 mm_struct 到底在管理些什么。
crash> task 1 PID: 1 TASK: c1598000 CPU: 0 COMMAND: "init"struct task_struct { ... mm = 0xdfe0fee0, ... }
我们拿到了 init 进程的 mm_struct 地址:0xdfe0fee0。 接下来我们在查看mm_struct的成员,我们按照之前的四个维度进行划分
crash>struct mm_struct 0xdfe0fee0 struct mm_struct { /* 管理虚拟空间 */ mmap = 0xdfe0df00, mm_rb = { rb_node = 0xdfe0ddf8 }, map_count = 0x12, /* 对接物理内存 */ pgd = 0xdfe0e000, /* 统计进程资源(单位是页) */ rss = 0x9a, total_vm = 0x1b9, locked_vm = 0x0, /* 保护内存安全 */ mmap_sem = { count = 0x0, wait_lock = { lock = 0x1 }, wait_list = { next = 0xdfe0ff04, prev = 0xdfe0ff04 } }, }
- •
pgd:我们看到了它指向了内核的页目录基址(对于 init 进程,它可能与 idle 共享,或者有自己独立的,这里验证了它持有通往硬件的钥匙)。 - •
mmap:指向了第一个虚拟内存区域(VMA)。 - •
rss vs total_vm:可以看到 rss (0x9a) 远小于 total_vm (0x1b9),完美验证了 Linux 按需分配 (Demand Paging) 的策略。
同样的,我们也可以通过/proc/[pid]/status 查看到rss和total_vm值
hyper:~# cat /proc/1/status Name: init VmSize: 1764 kB VmRSS: 616 kB
在查看VMA:
crash> vm 1 PID: 1 TASK: c1598000 CPU: 0 COMMAND: "init" MM PGD RSS TOTAL_VM dfe0fee0 dfe0e000 616k 1764k VMA START END FLAGS FILE dfe0df00 8048000 8050000 1875 /sbin/init dfe0dea0 8050000 8051000 1873 /sbin/init dfe0d8a0 8051000 8071000 77 dfe0de40 40000000 40015000 875 /lib/ld-2.3.6.so dfe0dde0 40015000 40017000 873 /lib/ld-2.3.6.so dfe0dd80 40017000 40019000 73 dfe0dcc0 4001b000 40051000 75 /lib/libsepol.so.1 dfe0dc00 40051000 40052000 73 /lib/libsepol.so.1 dfe0dba0 40052000 4005c000 73 dfe0dc60 4005c000 4006f000 75 /lib/libselinux.so.1 dfe0db40 4006f000 40071000 73 /lib/libselinux.so.1 dfe0dae0 40071000 40182000 75 /lib/libc-2.3.6.so dfe0d900 40182000 40187000 71 /lib/libc-2.3.6.so dfe0da20 40187000 40189000 73 /lib/libc-2.3.6.so dfe0d9c0 40189000 4018c000 73 dfe0da80 4018c000 4018e000 75 /lib/libdl-2.3.6.so dfe0d960 4018e000 40190000 73 /lib/libdl-2.3.6.so dfe0df60 bfffe000 c0000000 177
可以看到,每个VMA的地址或者属性都是不相同,也印证了上文所提到的属于同一个进程的所有区间都要按虚存地址的高低次序链接在一起。
3.总结
至此,我们已经拆解了 Linux 内存管理的框架:
- • 物理线:从 Node 到 Zone 再到 Page,内核为每一寸物理内存都建立了详尽的档案。
- • 虚拟线:通过
mm_struct 和 VMA,内核为每个进程编织了一个 3GB 的平坦梦境。
我们最后通过一个例子彻底打通 虚拟地址 -> 线性地址 -> 物理地址 -> 物理页 的全链路。
#include <stdio.h> #include <unistd.h> int main() { // 使用 volatile 防止编译器优化掉它 volatile int stack_var = 0xDEADBEEF; // 2. 打印进程 PID 和变量的虚拟地址 printf("========================================\n"); printf("Process PID: %d\n", getpid()); printf("Stack Var Virtual Address: %p\n", &stack_var); printf("Value: 0x%X\n", stack_var); printf("========================================\n"); printf("Program is sleeping... Now go to crash!\n"); printf("Press ENTER to exit...\n"); // 3. 暂停,保持现场,等待 Crash 检查 while(1); return 0; }
在 qemu 里面执行
======================================== Process PID: 273 Stack Var Virtual Address: 0xbffffdf4 Value: 0xDEADBEEF ======================================== Program is sleeping... Now go to crash! Press ENTER to exit..
进入 crash 中查看信息。
切换上下文到目标进程:
crash> set 273 PID: 273 COMMAND: "stack_val" TASK: df800000 CPU: 0 STATE: TASK_RUNNING
虚拟地址转物理地址:
使用 vtop 命令,输入程序打印的虚拟地址:
crash> vtop 0xbffffdf4 VIRTUAL PHYSICAL bffffdf4 1f7cfdf4 PAGE DIRECTORY: df814000 **PGD**: df814bfc => 1faf6067 **PMD**: df814bfc => 1faf6067 **PTE**: 1faf6ffc => 1f7cf067 **PAGE**: 1f7cf000 PTE PHYSICAL FLAGS 1f7cf067 1f7cf000 (PRESENT|RW|USER|ACCESSED|DIRTY) VMA START END FLAGS FILE dfaf5300 bffff000 c0000000 177 PAGE PHYSICAL MAPPING INDEX CNT FLAGS c15697b0 1f7cf000 0 0 1 1000040
crash 会自动帮你查页表(PGD -> PT -> Phys),告诉你物理地址是 0x1f7cfdf4。 ****
读取物理内存验证数据:
现在我们绕过所有虚拟内存机制,直接读取物理内存条上的数据,看看是不是我们写的 0xDEADBEEF:
crash> rd -p 0x1f7cfdf4 1f7cfdf4: deadbeef ....
在物理内存中看到了 deadbeef。这证明了虚拟地址到物理地址的映射是真实存在的。
通过 Crash,我们亲眼见证了虚拟地址 0xbffffdf4 是如何一步步变成物理地址 0x1f7cfdf4 的。至此,静态的内存映射架构已经搭建完毕。但如果进程访问了一个‘不存在’的地址会发生什么? 这就是连接这两条平行线的桥梁 —— 缺页异常 (Page Fault)。我们将在下一篇文章中,深入动态的内存分配过程。

