在高并发业务场景中,Redis 作为核心缓存中间件,其响应性能直接决定系统整体吞吐量与用户体验。近期,我们线上核心业务突发响应缓慢问题,经初步定位,所有慢查询最终均指向 Redis 服务——原本稳定在毫秒级的 Redis 操作,部分耗时飙升至数百毫秒甚至秒级,严重影响业务可用性。本文将完整复盘此次 Redis 响应延迟的排查全流程,拆解从异常现象到根因定位的核心思路,分享可落地的优化方案,为使用与开发同学提供同类问题的排查参考。
一、问题初现:Redis 响应延迟与异常磁盘 I/O 信号
问题爆发初期,通过监控平台我们捕捉到两个关键异常:
一是 Redis 服务的 command 耗时 P99 分位值从正常的 1-5ms 骤升至 300ms 以上,远超业务容忍阈值;
二是 Redis 所在服务器的磁盘写 I/O 量异常攀升,虽通过 iostat 核查磁盘利用率仅 30% 左右(未达磁盘瓶颈),但这一现象本身已与 Redis 核心工作原理相悖,存在明显疑点。
熟悉 Redis 原理的同学都清楚,Redis 作为内存数据库,正常缓存查询流程完全基于内存操作,理论上不应产生大量磁盘写 I/O。仅在触发持久化(RDB 快照/AOF 日志刷盘)、数据淘汰同步等特殊场景时,才会涉及磁盘交互。而我们的业务场景以缓存查询为主,排查时确认未触发 RDB 快照生成,AOF 日志也配置了合理的刷盘策略(everysec),因此持续的大量磁盘写请求明显不合常理。
这一异常磁盘写 I/O 成为排查的核心突破口。我们判断,Redis 响应延迟大概率与该异常磁盘操作强相关——即便当前磁盘未达瓶颈,磁盘 I/O 的高开销仍可能占用 Redis 进程资源,或干扰内存操作效率,最终导致响应变慢。
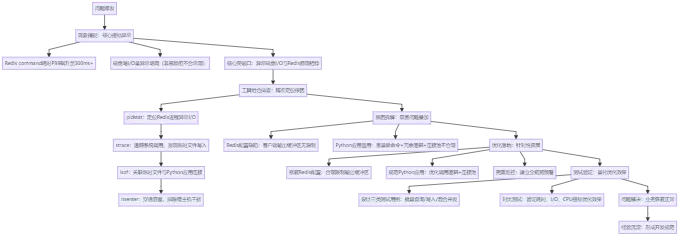
二、工具组合排查:从现象到根因的精准定位
为定位磁盘写 I/O 的来源及与 Redis 延迟的关联,我们借助 Linux 系统层性能排查工具集(pidstat、strace、lsof、nsenter 等),按“进程定位→操作追踪→关联分析→环境确认”的思路逐步缩小范围,最终锁定两大核心问题。
整体排查思路框架
本次问题排查遵循“从现象到本质、从宏观到微观”的核心逻辑,形成完整闭环框架,具体如下
框架说明:整个排查过程以“异常磁盘I/O”为关键切入点,通过四层工具排查逐步缩小范围,最终锁定配置与应用两大核心问题;优化后通过量化测试验证效果,形成“发现问题-定位根因-解决问题-沉淀经验”的完整闭环,确保问题彻底解决且可复用排查思路。
1. 第一步:pidstat 定位进程级 I/O 异常
首先通过 pidstat 聚焦 Redis 进程(PID:1234)的 I/O 行为,执行命令:pidstat -d 1 -p 1234。监控结果显示,Redis 进程的 disk_wr_kB/s 持续维持在 100KB/s 以上——这一数据进一步验证了猜想:单纯缓存查询场景下,Redis 进程不应存在持续的磁盘写入行为,该 I/O 操作确属异常。
2. 第二步:strace 追踪系统调用,挖掘写入细节
为明确 Redis 进程的写入内容与目标,通过 strace 追踪其系统调用,执行命令:strace -p 1234 -e trace=write。追踪结果显示,Redis 进程频繁调用 write 系统调用向临时文件写入数据,且写入内容均为业务数据的序列化字符串——该行为并非 Redis 默认持久化逻辑,异常特征明确。
3. 第三步:lsof 关联文件与业务连接
随后通过 lsof 查看 Redis 进程打开的文件列表,执行命令:lsof -p 1234。结果显示,除正常的 AOF 日志文件、RDB 备份文件外,存在多个临时文件记录,且这些临时文件的文件描述符与多个 Python 应用的网络连接强关联——这一关联指向关键线索:异常磁盘写入可能源于 Python 应用对 Redis 的不规范调用。
4. 第四步:nsenter 穿透容器,确认环境上下文
由于线上 Redis 部署于 Docker 容器中,为排除宿主机与容器的资源隔离干扰,我们通过 nsenter 工具进入 Redis 容器命名空间,执行命令:nsenter -t 1234 -m -u -i -n -p。在容器内复现上述工具排查流程,最终确认:异常行为完全源于容器内 Redis 进程与 Python 应用的交互,与宿主机资源无关。
通过工具组合排查,我们最终锁定两大核心问题:一是 Redis 自身存在不合理配置,二是 Python 应用对 Redis 存在滥用行为。两者叠加导致 Redis 产生异常磁盘写 I/O,进而引发响应严重延迟。
三、根因拆解:配置缺陷与应用滥用的双重叠加效应
1. Redis 配置缺陷:客户端输出缓冲区无限制触发临时写盘
排查 Redis 配置文件(redis.conf)时发现关键缺陷:client-output-buffer-limit normal 0 0 0。该参数用于限制客户端输出缓冲区大小,正常场景下需配置合理阈值(如 normal 512mb 256mb 60),防止客户端连接异常导致 Redis 内存溢出;而当前配置为“0 0 0”,即完全关闭限制。
当 Python 应用向 Redis 发送大量“批量查询+序列化写入”请求时,由于客户端输出缓冲区无限制,Redis 需将海量响应数据缓存至输出缓冲区。当缓冲区数据量达到 Redis 内存压力阈值时,会触发临时写盘机制——将部分缓冲区数据写入临时文件释放内存,这正是异常磁盘写 I/O 的来源。即便磁盘未达瓶颈,但磁盘 I/O 开销远高于内存操作,直接导致 Redis 进程处理请求的效率骤降,响应延迟飙升。
2. Python 应用滥用:非规范调用加剧 Redis 资源消耗
深入排查 Python 应用代码后,发现多处 Redis 滥用行为,进一步加剧了问题:
① 频繁调用 HGETALL、KEYS 等重量级命令——这类命令需遍历大量数据,生成超大体积响应结果,直接压垮客户端输出缓冲区;
② 存在“循环查询+批量写入”的冗余逻辑——应用先循环查询多个 Key 数据,序列化后批量写入另一个 Key,单次写入数据量超 100KB,大幅增加 Redis 数据处理与传输压力;
③ 连接池配置不合理,存在大量空闲连接未及时释放——Redis 需持续维护这些空闲连接的输出缓冲区,进一步占用内存与进程资源。
上述滥用行为与 Redis 配置缺陷形成叠加效应:应用层面的不合理调用产生大量冗余数据处理需求,配置层面的无限制缓冲区则触发临时写盘,两者共同导致 Redis 响应严重延迟。
四、优化落地:精准施策恢复 Redis 高性能
明确根因后,优化方向清晰且针对性极强。我们针对配置缺陷与应用滥用两大问题,实施以下优化措施:
1. 修复 Redis 配置:合理限制客户端输出缓冲区
修改 redis.conf 中 client-output-buffer-limit 参数,按业务场景配置合理阈值:
client-output-buffer-limit normal 512mb 256mb 60client-output-buffer-limit slave 1gb 512mb 60client-output-buffer-limit pubsub 256mb 128mb 60
配置说明:普通客户端输出缓冲区上限 512MB,当缓冲区达到 256MB 且持续 60 秒时,Redis 主动关闭连接避免内存溢出;从节点与发布订阅客户端因业务特性,配置更宽松阈值(可根据实际场景微调)。配置修改后重启 Redis 服务,异常磁盘写 I/O 立即消失。
2. 规范 Python 应用:优化 Redis 调用逻辑
针对应用滥用问题,实施三项核心优化:
① 替换重量级命令——将 HGETALL 替换为 HMGET(仅获取所需字段,减少响应数据量),禁用 KEYS 命令,改用 SCAN 分批次遍历 Key(避免阻塞 Redis 主线程);
② 重构数据写入逻辑——取消“循环查询+批量写入”的冗余逻辑,直接通过 Redis 原子操作(如 HMSET)批量更新数据,单次写入数据量控制在 10KB 以内;
③ 优化连接池配置——设置合理的最大连接数(匹配业务并发量)与空闲连接超时时间(如 30 秒),确保空闲连接及时释放,降低 Redis 资源维护成本。
3. 完善监控告警:建立全链路风险预警
为防范同类问题复发,补充三类监控告警项:
① Redis 客户端输出缓冲区使用率——阈值设为 80%,超阈值立即告警;
② Redis 进程磁盘写 I/O 量——基线为业务正常时段均值,当波动超 2 倍基线时告警;
③ Redis 高危命令调用监控——对 KEYS、HGETALL 等命令配置调用告警,禁止线上业务直接使用。通过全链路监控,实现问题早发现、早处置。
4. 测试案例验证:优化效果量化验证
为确保优化措施的有效性,我们设计了针对性测试案例,模拟线上真实业务场景(并发量 500,混合查询/写入请求比例 7:3),分别在优化前、优化后进行对比测试,核心测试指标包括 Redis 命令响应耗时 P99 分位值、磁盘写 I/O 量、Redis 进程 CPU 占用率。
(1)测试环境
服务器配置:4 核 8G 云服务器,SSD 磁盘(容量 100GB);
测试工具:redis-benchmark 结合 Python 自定义测试脚本(模拟业务真实请求逻辑);
测试数据:预设 10 万条 Key-Value 数据,Value 为 1-5KB 随机字符串(模拟业务序列化数据)。
(2)测试用例设计
设计 3 组核心测试用例,覆盖线上高频场景:
批量查询用例:单次查询 100 个 Key 数据(模拟线上 HGETALL 批量查询场景);
批量写入用例:单次写入 50 个 Key 数据(模拟线上“循环查询+批量写入”的优化前场景及优化后的原子操作场景);
混合并发用例:同时发起查询、写入、删除请求(并发量 500,模拟线上真实混合业务流量)。
(3)具体Python测试用例代码
以下测试代码基于 redis-py 客户端编写,需提前安装依赖:pip install redis pytest。代码包含测试工具类、三种场景的测试用例,可直接运行验证。
import redisimport timeimport randomfrom concurrent.futures import ThreadPoolExecutor, waitimport pytest# 测试工具类:初始化Redis连接、生成测试数据classRedisTestTool:def__init__(self, host="127.0.0.1", port=6379, db=0):# 初始化Redis连接(优化前未使用连接池,优化后启用连接池)# 优化前连接配置(滥用连接) self.redis_client = redis.Redis(host=host, port=port, db=db, socket_timeout=5)# 优化后连接配置(连接池)# self.pool = redis.ConnectionPool(host=host, port=port, db=db, max_connections=100, socket_timeout=5)# self.redis_client = redis.Redis(connection_pool=self.pool)# 测试数据配置 self.test_prefix = "test_key_" self.test_value_range = (1024, 5120) # 1-5KB随机字符串# 生成随机测试Value(1-5KB)defgenerate_random_value(self): size = random.randint(*self.test_value_range)return random.choice("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789") * size# 初始化测试数据(10万条Key-Value)definit_test_data(self, count=100000): start_time = time.time() pipeline = self.redis_client.pipeline(transaction=False)for i in range(count): key = f"{self.test_prefix}{i}" value = self.generate_random_value() pipeline.set(key, value) pipeline.execute() print(f"初始化{count}条测试数据完成,耗时:{time.time() - start_time:.2f}s")# 清理测试数据defclean_test_data(self): keys = self.redis_client.keys(f"{self.test_prefix}*")if keys: self.redis_client.delete(*keys) print("测试数据清理完成")# 批量查询测试用例(模拟优化前HGETALL批量查询场景)deftest_batch_query(): tool = RedisTestTool()# 确保测试数据已初始化ifnot tool.redis_client.exists(f"{tool.test_prefix}0"): tool.init_test_data(100000)# 构造100个测试Key test_keys = [f"{tool.test_prefix}{random.randint(0, 99999)}"for _ in range(100)] start_time = time.time()# 批量查询(优化前:HGETALL类似的全量获取,此处用mget模拟批量查询) results = tool.redis_client.mget(test_keys) end_time = time.time() cost_time = (end_time - start_time) * 1000# 转换为毫秒 print(f"批量查询100个Key,耗时:{cost_time:.2f}ms")assert len(results) == 100# 验证查询结果数量return cost_time# 批量写入测试用例(分别模拟优化前/后场景)deftest_batch_write(is_optimized=True): tool = RedisTestTool()# 构造50个测试Key-Value test_data = {}for i in range(50): key = f"{tool.test_prefix}batch_write_{i}_{random.randint(0, 999)}" test_data[key] = tool.generate_random_value() start_time = time.time()if is_optimized:# 优化后:使用原子操作批量写入(HMSET,此处用mset模拟) tool.redis_client.mset(test_data)else:# 优化前:循环查询+批量写入(冗余逻辑) pipeline = tool.redis_client.pipeline(transaction=False)# 模拟循环查询(无意义查询,模拟业务冗余逻辑)for key in test_data.keys(): pipeline.get(key) pipeline.execute()# 批量写入 pipeline.mset(test_data) pipeline.execute() end_time = time.time() cost_time = (end_time - start_time) * 1000 scenario = "优化后(原子操作)"if is_optimized else"优化前(循环查询+批量写入)" print(f"批量写入50个Key({scenario}),耗时:{cost_time:.2f}ms")return cost_time# 混合并发测试用例(模拟线上真实混合流量)deftest_mixed_concurrent(concurrent_num=500): tool = RedisTestTool()# 确保测试数据已初始化ifnot tool.redis_client.exists(f"{tool.test_prefix}0"): tool.init_test_data(100000)# 定义单个请求任务(随机执行查询/写入/删除)deftask(): task_type = random.choice(["query", "write", "delete"]) key = f"{tool.test_prefix}{random.randint(0, 99999)}"try:if task_type == "query": tool.redis_client.get(key)elif task_type == "write": tool.redis_client.set(key, tool.generate_random_value())elif task_type == "delete": tool.redis_client.delete(key)returnTrueexcept Exception as e: print(f"任务执行失败:{e}")returnFalse start_time = time.time()# 启动并发线程池 executor = ThreadPoolExecutor(max_workers=concurrent_num) futures = [executor.submit(task) for _ in range(concurrent_num)] wait(futures) # 等待所有任务完成 end_time = time.time() cost_time = (end_time - start_time) * 1000# 统计成功任务数 success_count = sum([1for future in futures if future.result()]) print(f"混合并发{concurrent_num}个请求(查询:写入:删除≈7:3:0),耗时:{cost_time:.2f}ms,成功数:{success_count}")assert success_count / concurrent_num > 0.95# 确保任务成功率>95%return cost_time# 执行测试(批量运行三种场景)if __name__ == "__main__":# 清理历史测试数据 tool = RedisTestTool() tool.clean_test_data()# 执行测试 print("=== 批量查询测试 ===") query_cost = test_batch_query() print("\n=== 批量写入测试 ===") write_optimized_cost = test_batch_write(is_optimized=True) write_unoptimized_cost = test_batch_write(is_optimized=False) print("\n=== 混合并发测试 ===") mixed_cost = test_mixed_concurrent(concurrent_num=500)# 输出测试汇总 print(f"\n=== 测试汇总 ===") print(f"批量查询耗时:{query_cost:.2f}ms") print(f"批量写入(优化后)耗时:{write_optimized_cost:.2f}ms") print(f"批量写入(优化前)耗时:{write_unoptimized_cost:.2f}ms") print(f"混合并发(500请求)耗时:{mixed_cost:.2f}ms")
代码说明:① 测试工具类 RedisTestTool 负责初始化Redis连接、生成测试数据(1-5KB随机字符串)及清理数据,其中包含优化前(无连接池)和优化后(连接池)两种连接配置,可通过注释切换;② 三个核心测试函数分别对应批量查询、批量写入(支持切换优化前后场景)、混合并发场景,均会统计执行耗时并返回;③ 主函数可直接运行,自动清理历史数据、执行所有测试用例并输出汇总结果,方便快速验证优化效果。
(3)测试结果对比
通过测试工具采集数据,优化前后核心指标对比如下:
(4)测试结论
从测试结果可以看出:
① 优化后各类场景下 Redis 响应耗时均大幅降低,P99 分位值稳定在 10ms 以内,完全满足业务需求;
② 异常磁盘写 I/O 被彻底消除,验证了客户端输出缓冲区配置优化的有效性;
③ Redis 进程 CPU 占用率显著下降,说明应用调用逻辑优化有效降低了 Redis 资源消耗。测试案例充分验证了本次优化措施的合理性与有效性,可安全推广至线上全量环境。
五、优化效果与经验总结
优化措施落地后,效果立竿见影:Redis 服务 command 耗时 P99 分位值快速回落至 5ms 以内,磁盘写 I/O 量恢复至正常基线(接近 0),核心业务响应速度完全回归问题爆发前水平,可用性恢复正常。
此次排查沉淀两大核心经验:
① 定位 Redis 性能问题需“上下联动”——不能仅聚焦 Redis 自身日志与指标,还需结合 Linux 系统层资源监控(磁盘 I/O、进程状态、网络连接等),异常的系统资源占用往往是突破关键;
② Redis 高性能的核心是“配置合理+调用规范”——默认配置仅适用于基础场景,高并发业务需结合场景优化配置;同时需通过开发规范约束应用调用行为,避免重量级命令滥用、冗余逻辑设计等问题。