假如我们进入这样一个web页面,大概如下
我们想要看完整的内容,页面弹窗。不注册看不了全部。出于个人信息保护,我想部分人士只想以游客身份浏览。
这时候,我们按F12或选择查看源码。内容大概如下。

把我们要的节点拷贝,并用python处理,部分代码如下。
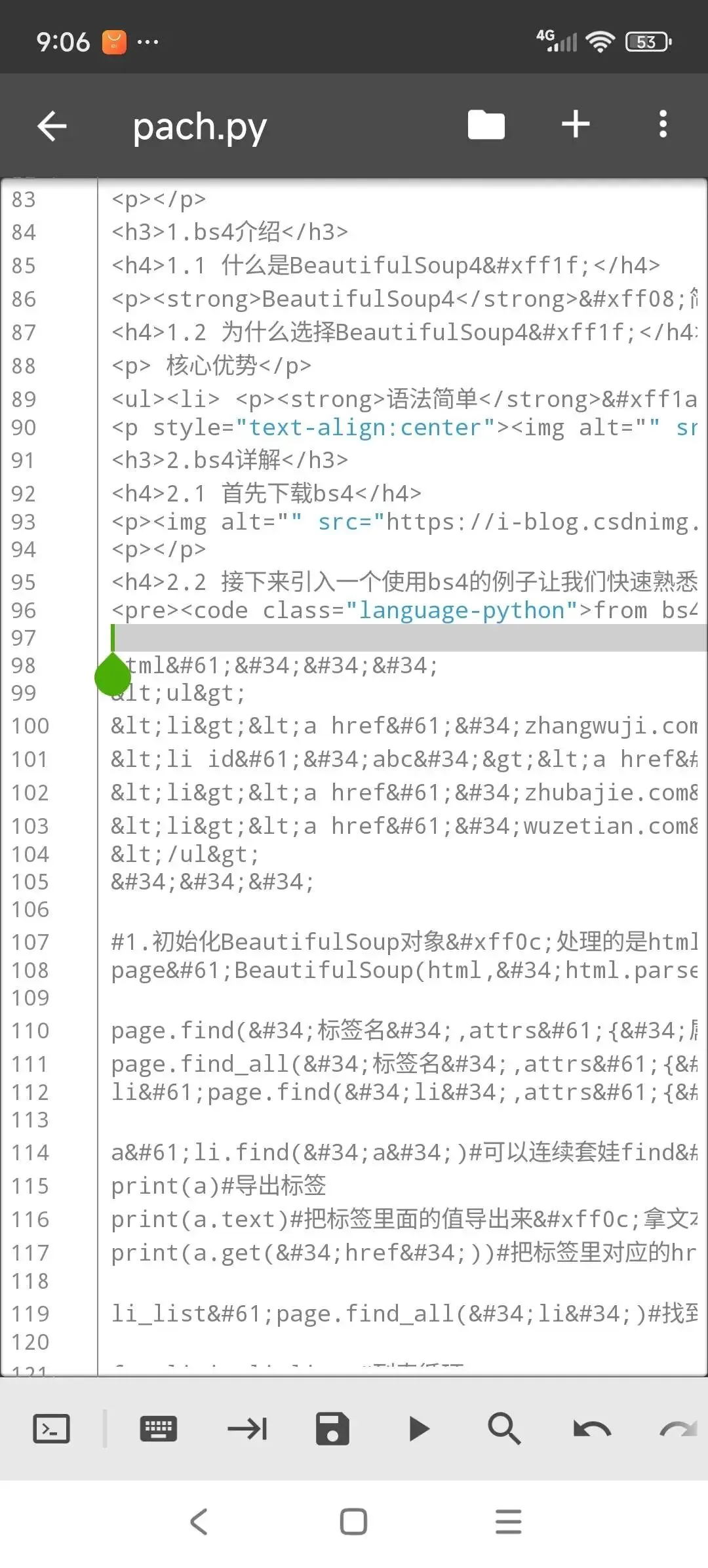
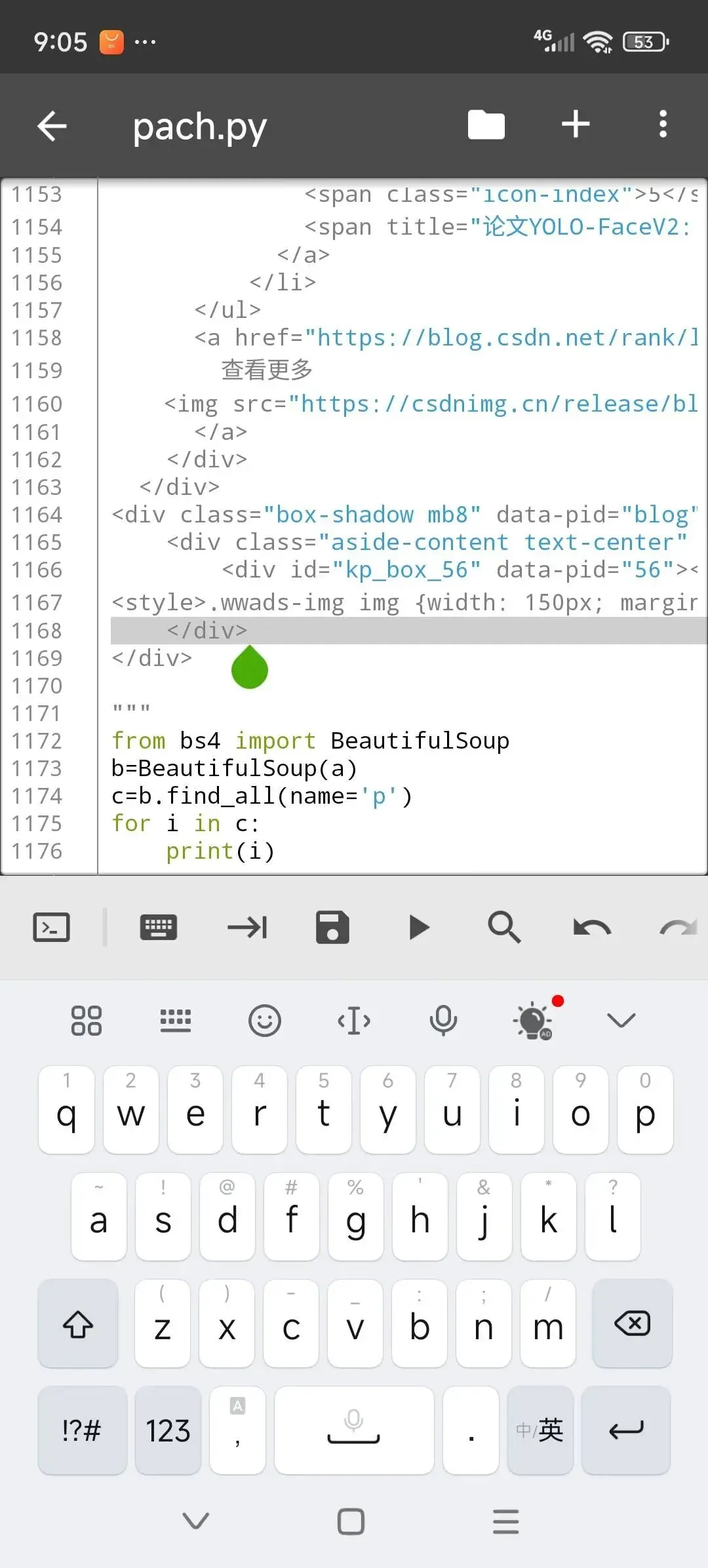
如果我们要提取的信息,格式比较乱,soup.find_all这一块会复杂一些。
我们运行后,部分结果如下
将其拷贝到markdown,或者写入html。
这里我用markdown处理
部分内容如下

运行后,部分界面如下

完美跳过注册的限制,实现精准阅读。

