1. 创始时间与作者
2. 官方资源
W3C官方规范:https://www.w3.org/XML/
XML 1.0规范:https://www.w3.org/TR/xml/
Python xml模块文档:https://docs.python.org/3/library/xml.html
3. 核心功能
4. 应用场景
1. 配置文件解析
import xml.etree.ElementTree as ET# 解析XML配置文件tree = ET.parse('config.xml')root = tree.getroot()# 读取配置值database_host = root.find('database/host').textdatabase_port = root.find('database/port').textapp_settings = {elem.tag: elem.text for elem in root.find('settings')}print(f"数据库: {database_host}:{database_port}")print(f"应用设置: {app_settings}")# config.xml 示例:"""<config> <database> <host>localhost</host> <port>3306</port> </database> <settings> <debug>true</debug> <log_level>INFO</log_level> </settings></config>"""2. Web服务数据交换
import xml.etree.ElementTree as ETimport requests# 创建SOAP请求def create_soap_request():envelope = ET.Element('soap:Envelope')envelope.set('xmlns:soap', 'http://schemas.xmlsoap.org/soap/envelope/')body = ET.SubElement(envelope, 'soap:Body')get_weather = ET.SubElement(body, 'GetWeather')get_weather.set('xmlns', 'http://example.com/weather')city = ET.SubElement(get_weather, 'City')city.text = 'Beijing'return ET.tostring(envelope, encoding='unicode')# 发送SOAP请求soap_request = create_soap_request()response = requests.post('http://example.com/weather/service',data=soap_request,headers={'Content-Type': 'text/xml'})# 解析SOAP响应root = ET.fromstring(response.content)temperature = root.find('.//{http://example.com/weather}Temperature').textprint(f"当前温度: {temperature}°C")3. 数据序列化
import xml.etree.ElementTree as ETfrom dataclasses import dataclassfrom typing import List@dataclassclass Person:name: strage: intemail: strdef persons_to_xml(persons: List[Person]) ->str:"""将Person对象列表转换为XML"""root = ET.Element('Persons')for person in persons:person_elem = ET.SubElement(root, 'Person')name_elem = ET.SubElement(person_elem, 'Name')name_elem.text = person.nameage_elem = ET.SubElement(person_elem, 'Age')age_elem.text = str(person.age)email_elem = ET.SubElement(person_elem, 'Email')email_elem.text = person.emailreturn ET.tostring(root, encoding='unicode', method='xml')# 使用示例persons = [Person("Alice", 30, "alice@example.com"),Person("Bob", 25, "bob@example.com")]xml_data = persons_to_xml(persons)print(xml_data)4. RSS订阅处理
import xml.etree.ElementTree as ETimport requestsfrom datetime import datetimedef parse_rss_feed(url):"""解析RSS订阅源"""response = requests.get(url)root = ET.fromstring(response.content)# RSS 2.0 命名空间ns = {'': ''}channel = root.find('channel')feed_title = channel.find('title').textitems = []for item in channel.findall('item'):items.append({'title': item.find('title').text,'link': item.find('link').text,'description': item.find('description').text,'pubDate': datetime.strptime(item.find('pubDate').text, '%a, %d %b %Y %H:%M:%S %z') })return {'title': feed_title, 'items': items}# 使用示例rss_url = "https://example.com/rss"feed = parse_rss_feed(rss_url)print(f"订阅源: {feed['title']}")for item in feed['items'][:3]: # 显示最新3条print(f"- {item['title']} ({item['pubDate'].strftime('%Y-%m-%d')})")
5. 底层逻辑与技术原理
核心架构
关键技术
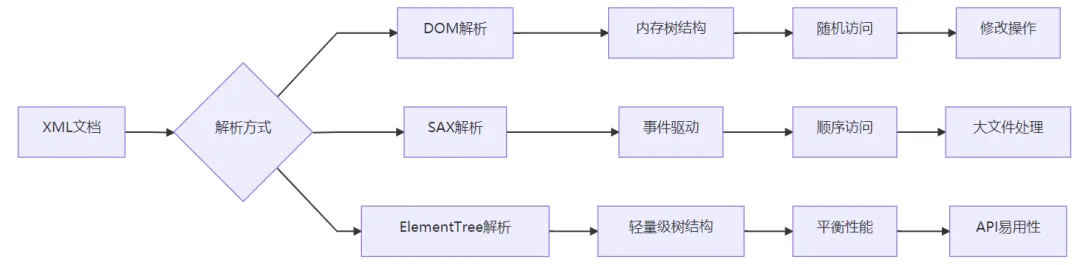
DOM解析:
一次性加载整个XML文档到内存
构建树形结构,支持随机访问
适合小型文档和需要频繁修改的场景
SAX解析:
基于事件驱动的流式解析
逐行读取,内存占用小
适合大型文档和只读操作
ElementTree解析:
Python特有的轻量级解析方式
平衡DOM和SAX的优点
提供简洁的API接口
XML验证:
DTD(文档类型定义)验证
XML Schema验证
支持命名空间处理
6. 安装与配置
安装说明
# xml模块是Python标准库的一部分,无需单独安装# 从Python 1.5+开始内置支持# 检查Python版本python --version# 导入测试python -c"import xml.etree.ElementTree as ET; print('XML模块可用')"可选依赖
# 如果需要额外的XML功能,可以安装以下库:# lxml (高性能XML处理)pip install lxml# xmlschema (XML Schema验证)pip install xmlschema# defusedxml (安全的XML解析)pip install defusedxml
环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|
| Python | 1.5+ | 3.8+ |
| 内存 | 视XML文件大小而定 | 充足内存处理大文件 |
| 性能 | 基础性能 | 无特殊要求 |
版本兼容性
| Python版本 | xml模块功能支持 |
|---|
| 1.5+ | 基本XML解析功能 |
| 2.0+ | 更完善的XML支持 |
| 2.5+ | ElementTree API |
| 3.0+ | 改进的Unicode支持 |
| 3.8+ | 最新的安全增强 |
7. 性能特点
| 解析方式 | 内存使用 | 性能 | 适用场景 |
|---|
| DOM解析 | 高(整个文档加载到内存) | 中等 | 小型文档,需要随机访问 |
| SAX解析 | 低(流式处理) | 高 | 大型文档,只读操作 |
| ElementTree | 中等 | 高 | 大多数应用场景 |
| lxml | 中等 | 非常高 | 高性能需求 |
注:性能特征基于典型使用场景,实际性能受文档结构和硬件影响
8. 高级功能使用
1. 命名空间处理
import xml.etree.ElementTree as ET# 处理带命名空间的XMLxml_data = """<root xmlns:app="http://example.com/app" xmlns:user="http://example.com/user"> <app:settings> <app:timeout>30</app:timeout> </app:settings> <user:info> <user:name>Alice</user:name> <user:age>30</user:age> </user:info></root>"""# 注册命名空间ns = {'app': 'http://example.com/app','user': 'http://example.com/user'}root = ET.fromstring(xml_data)# 使用命名空间查找元素timeout = root.find('app:settings/app:timeout', ns)user_name = root.find('user:info/user:name', ns)print(f"超时: {timeout.text}")print(f"用户名: {user_name.text}")# 创建带命名空间的元素new_settings = ET.Element('{%s}new_settings'%ns['app'])new_settings.set('{%s}version'%ns['app'], '1.0')root.append(new_settings)2. XML验证
from xml.etree.ElementTree import parse, XMLParserfrom xml.parsers.expat import ExpatErrordef validate_xml(xml_file, dtd_file=None):"""验证XML文件的有效性"""try:# 基本XML格式验证parser = XMLParser()tree = parse(xml_file, parser=parser)# 如果有DTD,进行DTD验证if dtd_file:# 需要lxml库进行DTD验证try:from lxml import etreexmlschema_doc = etree.parse(dtd_file)xmlschema = etree.XMLSchema(xmlschema_doc)xml_doc = etree.parse(xml_file)return xmlschema.validate(xml_doc)except ImportError:print("警告: 需要安装lxml库进行DTD验证")return Truereturn Trueexcept ExpatError as e:print(f"XML格式错误: {e}")return Falseexcept Exception as e:print(f"验证错误: {e}")return False# 使用示例is_valid = validate_xml('data.xml', 'schema.dtd')print(f"XML验证结果: {'通过' if is_valid else '失败'}")3. XPath查询
import xml.etree.ElementTree as ET# 加载XML数据tree = ET.parse('books.xml')root = tree.getroot()# 注册命名空间(如果有)ns = {'': ''} # 无命名空间# 使用XPath查询# 查找所有价格大于20的书expensive_books = root.findall(".//book[price>20]")print("昂贵的书籍:")for book in expensive_books:title = book.find('title').textprice = book.find('price').textprint(f"- {title}: ${price}")# 查找特定作者的书author_books = root.findall(".//book[author='J.K. Rowling']")print("\nJ.K. Rowling的书籍:")for book in author_books:title = book.find('title').textprint(f"- {title}")# 使用通配符all_titles = root.findall(".//title")print(f"\n总共找到 {len(all_titles)} 本书")4. 大型XML文件处理
import xml.etree.ElementTree as ETfrom memory_profiler import profile@profiledef process_large_xml(xml_file, output_file):"""处理大型XML文件(内存高效方式)"""# 使用迭代解析context = ET.iterparse(xml_file, events=('start', 'end'))# 转为迭代器context = iter(context)# 获取根元素event, root = next(context)with open(output_file, 'w', encoding='utf-8') as out_f:out_f.write('<?xml version="1.0" encoding="UTF-8"?>\n')out_f.write(f'<{root.tag}>\n')for event, elem in context:if event == 'end' and elem.tag == 'record':# 处理每个记录processed_data = process_record(elem)out_f.write(processed_data+'\n')# 清理已处理元素elem.clear()if elem.getprevious() is not None:del elem.getparent()[0]out_f.write(f'</{root.tag}>\n')# 最后清理根元素root.clear()def process_record(record_elem):"""处理单个记录元素"""# 提取需要的数据data = {}for child in record_elem:data[child.tag] = child.text# 转换为需要的格式return f"<processed>{data['id']}:{data['value']}</processed>"# 使用示例process_large_xml('large_data.xml', 'processed_data.xml')
9. 安全注意事项
XML安全风险
from defusedxml.ElementTree import parse as safe_parseimport xml.etree.ElementTree as ETdef safe_xml_parsing(xml_data):"""安全的XML解析"""try:# 使用defusedxml防止XXE攻击root = safe_parse(xml_data).getroot()return process_xml(root)except Exception as e:print(f"安全解析错误: {e}")return Nonedef dangerous_xml_parsing(xml_data):"""不安全的XML解析(仅用于演示)"""# 可能受到XXE攻击root = ET.fromstring(xml_data)return process_xml(root)# 安全配置解析器def create_secure_parser():"""创建安全的XML解析器"""parser = ET.XMLParser()# 禁用实体解析(防止XXE)parser.entity = {}return parser# 使用安全解析器secure_parser = create_secure_parser()try:tree = ET.parse('data.xml', parser=secure_parser)root = tree.getroot()except ET.ParseError as e:print(f"解析错误: {e}")防御措施
# 1. 使用defusedxml库# pip install defusedxmlfrom defusedxml import defuse_stdlibdefuse_stdlib()# 2. 禁用危险功能parser = ET.XMLParser()parser.entity = {} # 禁用实体parser.target = None# 禁用处理指令# 3. 输入验证和清理def sanitize_xml_input(xml_input):"""清理XML输入"""# 移除危险内容dangerous_patterns = [r'<!ENTITY.*?>',r'<!DOCTYPE.*?>',r'<?xml-stylesheet.*?>' ]for pattern in dangerous_patterns:xml_input = re.sub(pattern, '', xml_input, flags=re.IGNORECASE)return xml_input
10. 实际应用案例
Web服务集成:
# SOAP Web服务客户端import zeep# 使用zeep库处理SOAP(基于XML)client = zeep.Client('http://example.com/soap-service?wsdl')result = client.service.GetData(param1='value1')配置文件管理:
# 应用配置管理class XMLConfig:def __init__(self, config_file):self.tree = ET.parse(config_file)self.root = self.tree.getroot()def get(self, key, default=None):elem = self.root.find(key)return elem.text if elem is not None else defaultdef set(self, key, value):elem = self.root.find(key)if elem is None:elem = ET.SubElement(self.root, key)elem.text = str(value)self.tree.write('config.xml')数据交换格式:
# 与其他系统数据交换def export_to_xml(data, filename):root = ET.Element('DataExport')for item in data:record = ET.SubElement(root, 'Record')for key, value in item.items():field = ET.SubElement(record, key)field.text = str(value)tree = ET.ElementTree(root)tree.write(filename, encoding='utf-8', xml_declaration=True)文档生成:
# 生成XML格式的报表def generate_xml_report(data, template_file):# 使用模板生成标准化的XML报表tree = ET.parse(template_file)root = tree.getroot()# 填充数据fill_template(root, data)# 美化输出indent(root)tree.write('report.xml', encoding='utf-8')
总结
XML是数据交换和存储的重要标准,核心价值在于:
结构化数据:提供清晰的数据结构表示
跨平台兼容:被几乎所有编程语言和平台支持
扩展性强:支持自定义标签和数据结构
标准丰富:拥有完整的生态系统(XSD、XSLT、XPath等)
技术亮点:
文本格式,人类可读
强大的 schema 验证机制
丰富的查询和转换工具
广泛的标准支持
适用场景:
使用方式:
import xml.etree.ElementTree as ET# Python标准库
学习资源:
W3C XML规范:https://www.w3.org/XML/
Python xml文档:https://docs.python.org/3/library/xml.html
XML教程:https://www.w3schools.com/xml/
作为数据交换的标准格式,XML在企业和Web开发中仍然扮演着重要角色。Python的xml模块提供了完整的XML处理能力,遵循Python软件基金会许可证,可免费用于任何Python项目。