嵌入式中代码执行时间测量的几种方法
- 2026-07-06 20:23:03
在嵌入式开发中,性能优化是一个永恒的话题。无论是实时控制系统还是电池供电设备,准确测量代码执行时间都是优化的第一步。今天我们就来聊聊几种实用的测量方法,让你的代码性能一目了然。
为什么要测量执行时间?
想象一下,你正在开发一个电机控制系统,控制周期要求在1毫秒内完成。如果不知道每个函数的执行时间,就像盲人摸象一样,很难找到性能瓶颈。
测量执行时间的主要目的:
• 性能优化:找出最耗时的代码段 • 实时性验证:确保关键任务在规定时间内完成 • 功耗分析:执行时间直接影响CPU功耗 • 系统调试:定位异常延迟的根源
方法一:GPIO引脚翻转法
这是最直观、最常用的方法。通过在代码段前后翻转GPIO引脚,用示波器或逻辑分析仪观察波形。
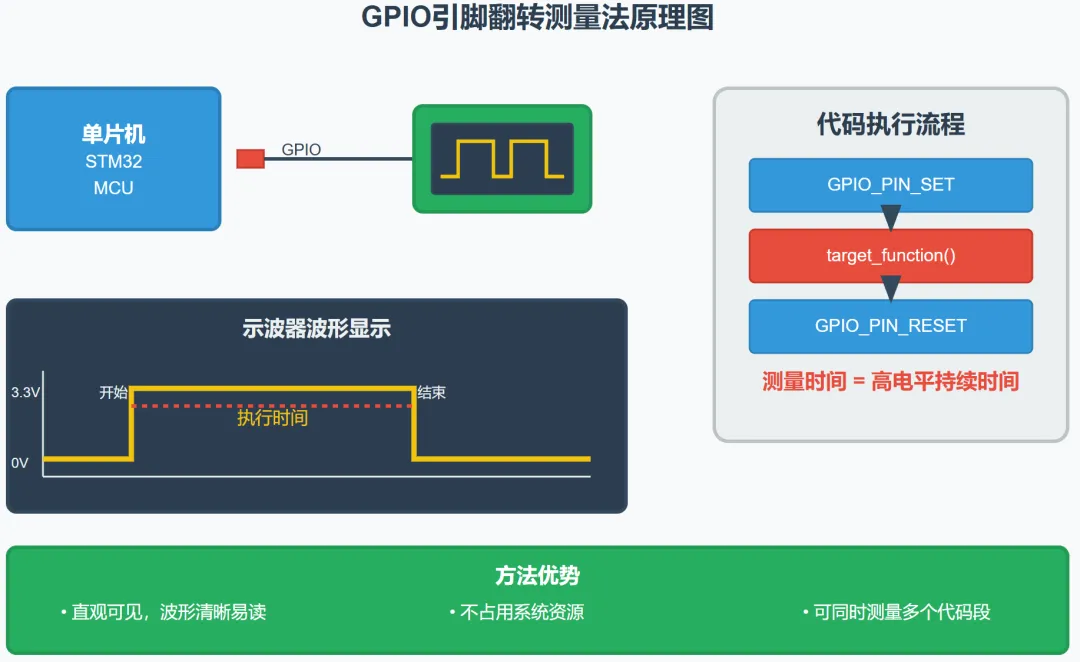
实现代码:
// 测量函数执行时间voidmeasure_function_time() {// 设置测试引脚为高电平 HAL_GPIO_WritePin(TEST_GPIO_Port, TEST_Pin, GPIO_PIN_SET);// 被测试的代码段 target_function();// 设置测试引脚为低电平 HAL_GPIO_WritePin(TEST_GPIO_Port, TEST_Pin, GPIO_PIN_RESET);}优势:
• 直观可见,波形清晰 • 不占用系统资源 • 可以同时测量多个代码段(使用不同引脚)
注意事项:
• GPIO操作本身也有时间开销(通常1-2个时钟周期) • 需要外部测量设备 • 在最终产品中需要移除测试代码
实际案例:在一个电机控制项目中,使用此方法发现PID计算函数耗时15微秒,而原本预期只有5微秒,通过优化浮点运算最终降到8微秒。
方法二:系统定时器法
利用系统内置的高精度定时器进行测量,这是最精确的软件测量方法。
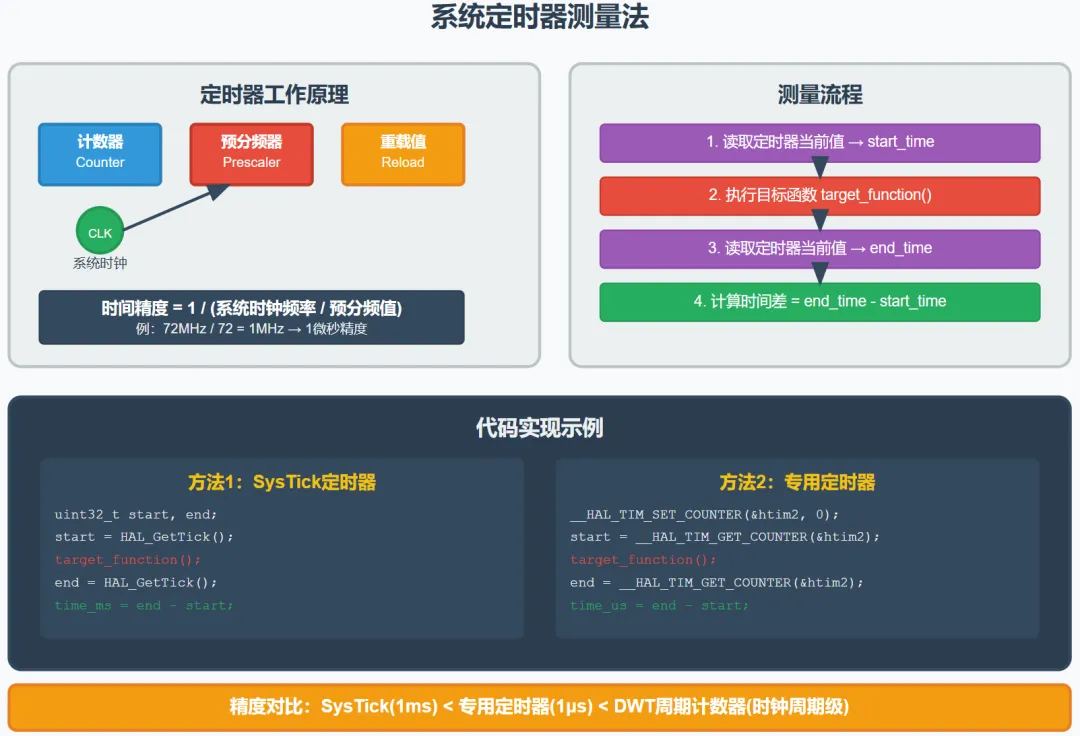
实现代码:
// 使用系统滴答定时器测量uint32_tmeasure_execution_time() {uint32_t start_time, end_time;// 获取开始时间(微秒级) start_time = HAL_GetTick() * 1000 + (SysTick->LOAD - SysTick->VAL) / (SystemCoreClock / 1000000);// 执行被测代码 target_function();// 获取结束时间 end_time = HAL_GetTick() * 1000 + (SysTick->LOAD - SysTick->VAL) / (SystemCoreClock / 1000000);return end_time - start_time; // 返回微秒数}// 使用专用定时器测量(更高精度)uint32_tprecise_time_measurement() {uint32_t start_cycles, end_cycles;// 启动定时器 __HAL_TIM_SET_COUNTER(&htim2, 0); HAL_TIM_Base_Start(&htim2); start_cycles = __HAL_TIM_GET_COUNTER(&htim2);// 执行被测代码 target_function(); end_cycles = __HAL_TIM_GET_COUNTER(&htim2); HAL_TIM_Base_Stop(&htim2);// 转换为微秒(假设定时器频率为1MHz)return end_cycles - start_cycles;}优势:
• 精度高,可达时钟周期级别 • 不需要外部设备 • 可以在代码中直接获取数值
局限性:
• 测量代码本身有开销 • 受中断影响较大 • 定时器溢出需要特殊处理
方法三:CPU周期计数法
对于ARM Cortex-M系列,可以使用DWT(Data Watchpoint and Trace)单元进行精确测量。
实现代码:
// 初始化DWTvoiddwt_init() { CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk; DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk; DWT->CYCCNT = 0;}// 测量CPU周期数uint32_tmeasure_cpu_cycles() {uint32_t start_cycles, end_cycles; start_cycles = DWT->CYCCNT;// 执行被测代码 target_function(); end_cycles = DWT->CYCCNT;return end_cycles - start_cycles;}// 转换为时间(微秒)floatcycles_to_microseconds(uint32_t cycles) {return (float)cycles / (SystemCoreClock / 1000000.0f);}数据示例:在72MHz的STM32F103上,一个简单的加法运算通常需要1-2个CPU周期,约0.014-0.028微秒。
方法四:软件性能分析器
现代IDE通常集成了性能分析工具,可以进行更全面的分析。

常用工具:
• Keil MDK:内置Performance Analyzer • IAR EWARM:C-SPY调试器的性能分析功能 • STM32CubeIDE:集成的性能监控工具 • Segger SystemView:实时系统分析工具
使用示例(以Keil为例):
// 在代码中插入性能标记#ifdef __CC_ARM __asm("MOV R0, #0x01"); // 标记开始#endiftarget_function();#ifdef __CC_ARM __asm("MOV R0, #0x02"); // 标记结束#endif方法五:统计采样法
对于长时间运行的系统,可以使用统计采样的方式进行性能分析。
实现思路:
typedefstruct {uint32_t total_time;uint32_t call_count;uint32_t max_time;uint32_t min_time;} performance_stats_t;performance_stats_t func_stats = {0};voidstatistical_measurement() {uint32_t start_time = get_current_time_us(); target_function();uint32_t execution_time = get_current_time_us() - start_time;// 更新统计信息 func_stats.total_time += execution_time; func_stats.call_count++;if (execution_time > func_stats.max_time) { func_stats.max_time = execution_time; }if (func_stats.min_time == 0 || execution_time < func_stats.min_time) { func_stats.min_time = execution_time; }}// 获取平均执行时间uint32_tget_average_time() {return func_stats.total_time / func_stats.call_count;}实际应用中的注意事项
1. 测量精度考虑
不同方法的精度对比:
• GPIO翻转法:受示波器采样率限制,通常纳秒级 • 定时器法:取决于定时器频率,微秒到纳秒级 • CPU周期法:最高精度,时钟周期级
2. 系统干扰因素
• 中断影响:测量期间的中断会影响结果准确性 • 缓存效应:第一次执行和后续执行时间可能不同 • 编译器优化:不同优化级别会显著影响执行时间
解决方案:
// 减少中断干扰voidaccurate_measurement() { __disable_irq(); // 关闭中断uint32_t start_time = DWT->CYCCNT; target_function();uint32_t end_time = DWT->CYCCNT; __enable_irq(); // 恢复中断uint32_t execution_cycles = end_time - start_time;}3. 多次测量取平均值
#define MEASUREMENT_ROUNDS 100uint32_taverage_measurement() {uint32_t total_time = 0;for (int i = 0; i < MEASUREMENT_ROUNDS; i++) {uint32_t start = DWT->CYCCNT; target_function();uint32_t end = DWT->CYCCNT; total_time += (end - start); }return total_time / MEASUREMENT_ROUNDS;}选择合适的测量方法
根据不同场景选择最适合的方法:
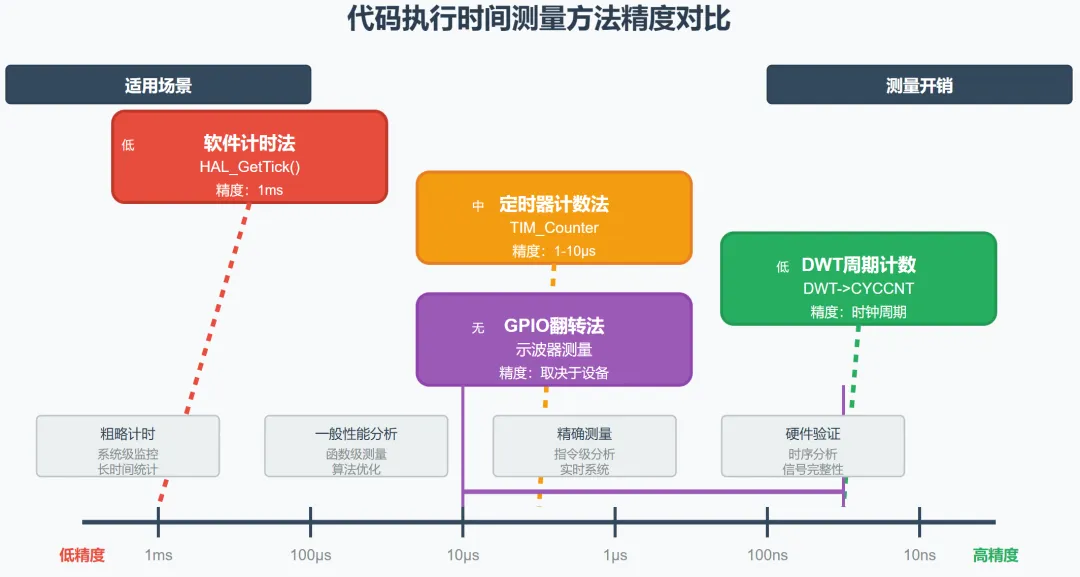
• 开发调试阶段:GPIO翻转法,直观易用 • 精确性能分析:CPU周期计数法,精度最高 • 长期监控:统计采样法,资源占用少 • 系统级分析:专业性能分析工具
总结
代码执行时间测量是嵌入式性能优化的基础工具。选择合适的测量方法,结合实际应用场景,才能获得准确可靠的数据。
记住,测量只是第一步,更重要的是基于测量结果进行有针对性的优化。从算法改进到编译器设置,从内存访问模式到指令级优化,每一个细节都可能带来显著的性能提升。
注:本文中的代码示例基于STM32平台,具体实现可能因硬件平台而异。建议读者根据实际使用的芯片和开发环境进行相应调整。
大家好,我是四哥,一个深耕嵌入式14年的老工程师。
分享大家一份不错的C语言电子书,以非常通俗的语言跟大家讲解C语言,把复杂的技术讲得连小学生都能听得懂,绝不是AI生成那种晦涩难懂的电子垃圾
C语言电子书目录如下:

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 自学门手艺(比如Python编程),如何从容面对过多的“过早引用”#工程数字化004
- 如何使用Python进行量化投资
- 记不住这些单词,就别开始学习Python
- 自学Python!我真的要骂醒你们!
- Python基础|字符串内置方法详解:这些方法你每天都在用
- 摄影数据分析教学唱歌Java Python计算机剪辑教程视频课程纪录片大合集
- 237 页 Python 入门神书!《python编程从入门到实践》从零基础到实战项目,新手也能轻松上手
- AI时代,如何让孩子从编程走向人工智能?
- Python学习路线——Python学习的10大阶段(0基础必须收藏)
- 志高空调故障代码与维修指导手册(维修必备-上)
