引言:后来居上的"巨蟒"
如果说 R 语言是生物信息学的"原住民",那么 Python 就是那个带着重型武器闯入的"外来者"。
十年前,做生信主要靠 Perl (处理文本) 和 R (统计绘图)。Python?那时候它可能只是某些极客的玩具。但今天,当你打开任何一个顶刊的生物信息学论文,无论是 AlphaFold 预测蛋白质结构,还是 scGPT 进行单细胞大模型训练,背后站着的都是 Python。
从一个"胶水语言"到 AI 时代的绝对霸主,Python 到底做对了什么?
今天,我们来复盘 Python 在生物信息学领域的逆袭之路。
🐍 创世纪:Guido 的圣诞礼物 (1989-2000)
那个无聊的圣诞节
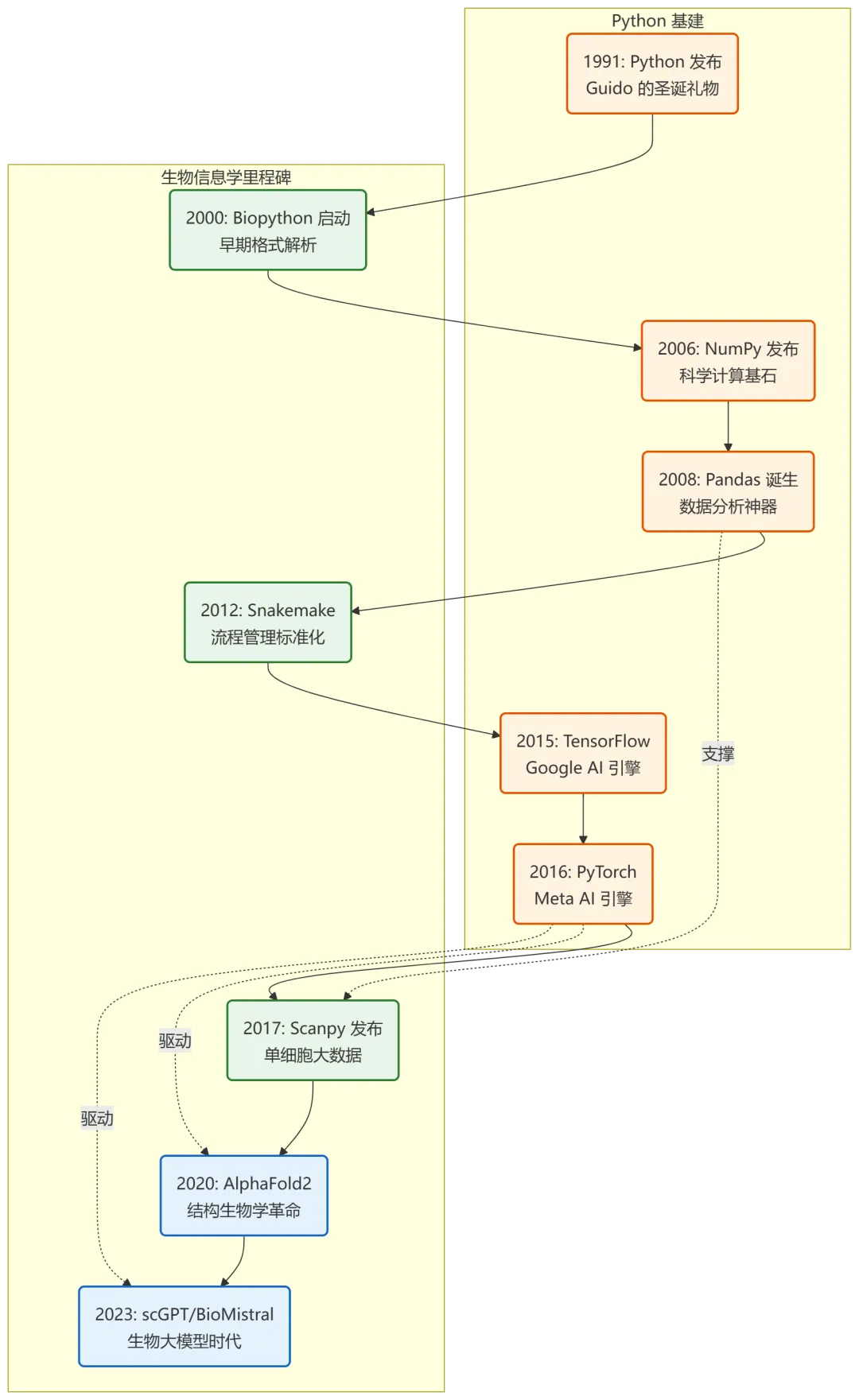
1989 年圣诞节,荷兰程序员 Guido van Rossum 为了打发假期时间,决定写一个新的脚本解释器。因为他是《蒙提·派森的飞行马戏团》(Monty Python's Flying Circus) 的粉丝,所以给这个语言起名 Python。
胶水语言的诞生
Python 的初衷很简单:优雅、易读。它就像强力胶水,能轻松地把 C/C++ 写的底层模块"粘"在一起。这为它日后在科学计算领域的爆发埋下了伏笔——用 Python 写逻辑,用 C 写算法,既快又好写。
🧬 萌芽期:Biopython 的努力 (2000-2010)
当 R 语言的 Bioconductor 搞得风生水起时,Python 社区也没闲着。
2000 年,Biopython 项目启动。虽然早期功能不如 Bioconductor 完善,但它解决了一个最痛的问题:文件格式解析。FASTA, GenBank, BLAST 结果……Biopython 让生物学家终于可以从繁琐的字符串处理中解脱出来。
但这个时候,Python 在生信圈的地位还很尴尬:"写脚本比 Perl 慢,画图比 R 丑"。
🏗️ 基建期:科学计算栈的崛起 (2010-2015)
Python 真正的转折点,是 NumPy, SciPy 和 Pandas 的成熟。
- NumPy:让 Python 拥有了处理大规模矩阵的能力,性能直逼 C 语言。
- Pandas:提供了类似 R Dataframe 的数据结构,让表格处理变得无比丝滑。
- Matplotlib/Seaborn:虽然语法有点啰嗦,但终于能画出像样的图了。
这一时期,Python 开始在基因组变异检测 (GATK 流程很多是用 Python 串起来的) 和流程管理 (Snakemake) 中占据一席之地。
🧠 爆发期:AI 与单细胞的共舞 (2015-至今)
2015 年之后,两个核弹级的技术引爆了 Python 生态:深度学习 和 单细胞测序。
1. 深度学习的垄断
随着 TensorFlow 和 PyTorch 的横空出世,Python 成了 AI 的代名词。生物学问题越来越变成一个预测问题:
- scGPT:用大模型理解单细胞。在 AI Bio 领域,Python 没有对手。
2. 单细胞的逆袭:Scanpy
在单细胞分析领域,R 语言的 Seurat 本来是一统天下的。但是,随着细胞数量从几千激增到百万级,R 的内存管理开始捉襟见肘。
这时,基于 Python 的 Scanpy 出现了。它利用 AnnData 格式和高效的算法,轻松处理百万级细胞数据。如今,"R 做小数据,Python 做大数据" 已经成为很多课题组的共识(虽然共识如此,但其实是Seurat的锅,而不是R)。
📈 一图看懂:Python 生信进化史
🚀 R vs Python:该学哪个?
这是一个永恒的争论。我的建议是:小孩子才做选择,成年人全都要。
- 如果你是统计学背景,做差异分析、画精美的图表:R (Tidyverse + ggplot2) 依然是王者。
- 如果你是计算机背景,做深度学习、处理百万级单细胞数据、开发算法:Python 是必须掌握的。
未来的生物信息学家,大概率是 "左手 R,右手 Python" 的双刀流战士。R 负责统计推断和可视化,Python 负责海量数据清洗和 AI 建模。
毕竟,工具是为了解决问题服务的,而不是为了站队。
互动话题:你的第一个 Python 程序是用来做什么的?是 print("Hello World") 还是处理 FASTA 文件?欢迎在评论区分享!